大数据架构选型分析
选择依据
1.业务需求与技术要求
用户需要根据自己的业务需求来选择架构,如果业务对于Hadoop、Spark、Strom等关键技术有强制性依赖,选择Lambda架构可能较为合适;如果处理数据偏好于流式计算,又依赖Flink计算引擎,那么选择Kappa架构可能更为合适。
2.复杂度
如果项目中需要频繁地对算法模型参数进行修改,Lambda架构需要反复修改两套代码,则显然不如Kappa架构简单方便。同时,如果算法模型支持同时执行批处理和流式计算,或者希望用一份代码进行数据处理,那么可以选择Kappa架构。
在某些复杂的案例中,其实时处理和离线处理的结果不能统一,比如某些机器学习的预测模型,需要先通过离线批处理得到训练模型,再交由实时流式处理进行验证测试,那么这种情况下,批处理层和流处理层不能进行合并,因此应该选择Lambda架构。
3.开发维护成本
Lambda架构需要有一定程度的开发维护成本,包括两套系统的开发、部署、测试、维护,适合有足够经济、技术和人力资源的开发者。而Kappa架构只需要维护一套系统,适合不希望在开发维护上投入过多成本的开发者。
4.历史数据处理能力
有些情况下,项目会频繁接触海量数据集进行分析,比如过往十年内的地区降水数据等,这种数据适合批处理系统进行分析,应该选择Lambda架构。如果始终使用小规模数据集,流处理系统完全可以使用,则应该选择Kappa架构。
Kappa架构
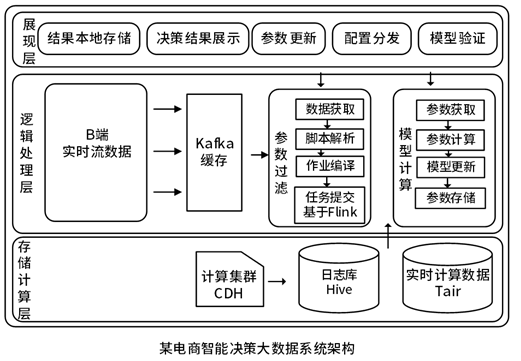
实时智能决策大数据平台基于Kappa架构,使用统一的数据处理引擎Flink可实时处理流数据,并将其存储到Hive与Tair中,以供后续决策服务的使用。实时处理的过程如下:
一是数据采集,即B端系统会实时收集用户的点击,下单以及广告的曝光和出价数据并输出到Kafka缓存。
二是数据的清洗与聚合,即基于大数据计算集群Flink计算框架,实时读取Kafka中的实时流数据,过滤出需要参与计算的字段,根据业务需求,聚合指定时间段的数据并转换成指标。
三是数据存储,即将Flink计算得到数据存储到Hive日志库中,需要参与模型计算的字段存储到Tair分布式缓存中。当需要进行模型计算时,决策服务会从Tair中读取数据,进行模型的计算,得到新的决策参数和模型。决策服务可以基于微服务架构,客户端部署在业务方系统中,服务端主要用于计算决策参数和模型,当服务端计算得到新的参数,此时会通过分布式任务协调程序(如Zookeeper)通知部署到业务方系统的客户端,客户端此时会拉取新的参数并存储到本地,并且客户端提供了获取参数的接口,业务方可以无感知调用。