不只是关键词匹配:AI如何像人类一样‘听懂‘你在说什么
文章目录
- AI真的能“听懂”人话吗?
- 语言里的“坑”到底有多深?
- 很久很久以前:AI的“语法书”时代
- 现代AI的玩法:不说教,让它自己“悟”!
- 第一步:拆解 (Tokenization - 文本切分)
- 第二步:翻译 (Embedding - 词嵌入)
- 第三步:联系上下文 (The Transformer & Attention Mechanism - 核心处理)
- 实战演练:当你说“帮我找个附近便宜的川菜馆”
- 最后总结
AI真的能“听懂”人话吗?
你有没有想过,当你对手机说“嘿 Siri,明天早上7点叫我起床”,或者在谷歌翻译里输入一长串外语时,这些机器到底是怎么“听懂”我们的话的?
它们没有耳朵,没有大脑(至少不是我们人类那种),但却能准确地捕捉到我们的意图,甚至还能理解我们那些奇奇怪怪的口头禅和打错的字。这背后难道有什么魔法吗?
其实,这并非魔法,而是一系列精妙绝伦的技术在悄悄工作。今天,就让我们像剥洋葱一样,一层一层地揭开这个秘密,让你彻底明白AI是如何理解我们的自然语言的。
语言里的“坑”到底有多深?
在我们开始之前,得先聊聊我们人类的语言有多“坑”。对于计算机来说,理解语言的第一大难题就是歧义。
举个例子,当你说“我去买个苹果”时,你指的是:
- 水果“苹果”?
- 还是“苹果公司”的手机?
我们人类可以根据上下文(比如你正在逛水果店还是数码城)轻松判断。但对机器来说,这就很头疼。
再比如这句话:“我看见那个男人在山上用望远镜。”
到底是“我用望远镜看见了山上的男人”,还是“我看见了那个正在用望远镜的男人”?你看,是不是有点绕?
除了歧义,还有我们的讽刺、幽默、双关语……这些都给机器的理解带来了巨大的挑战。早期的程序员试图用“规则”来解决这个问题。
很久很久以前:AI的“语法书”时代
最早期的AI语言理解,就像是给机器一本厚厚的、写满了规则的“语法书”。
程序员会手动输入成千上万条规则,比如:
- 如果一句话里有“天气”和“怎么样”,那就去查天气预报。
- 如果一句话以“谁是”开头,那就去搜索人物信息。
这种方法在处理简单的、固定的命令时还行。但它非常“死板”,只要你换个说法,比如把“今天天气怎么样”说成“外面天儿如何啊?”,它可能就立刻“懵圈”了。而且,要手动写下涵盖所有语言现象的规则,几乎是不可能的任务。
显然,这条路走不通。于是,一个更聪明的想法诞生了。
现代AI的玩法:不说教,让它自己“悟”!
现代AI不再依赖那本死板的“语法书”,而是像一个婴儿学习语言一样——通过大量的实例来学习。
我们不再告诉它“主谓宾”结构是什么,而是把海量的文章、书籍、网页、对话(基本上是半个互联网)都“喂”给它。它会自己去阅读、分析,并从中找出规律。
这就好比你听了无数遍“吃饭”,也看到了无数次吃饭的场景,你自然就明白了“吃饭”这个词的含义和用法。AI也是如此,它通过“阅读”上亿个句子,逐渐“悟”出了语言的门道。
那么,它具体是怎么“悟”的呢?这里有三个关键步骤。
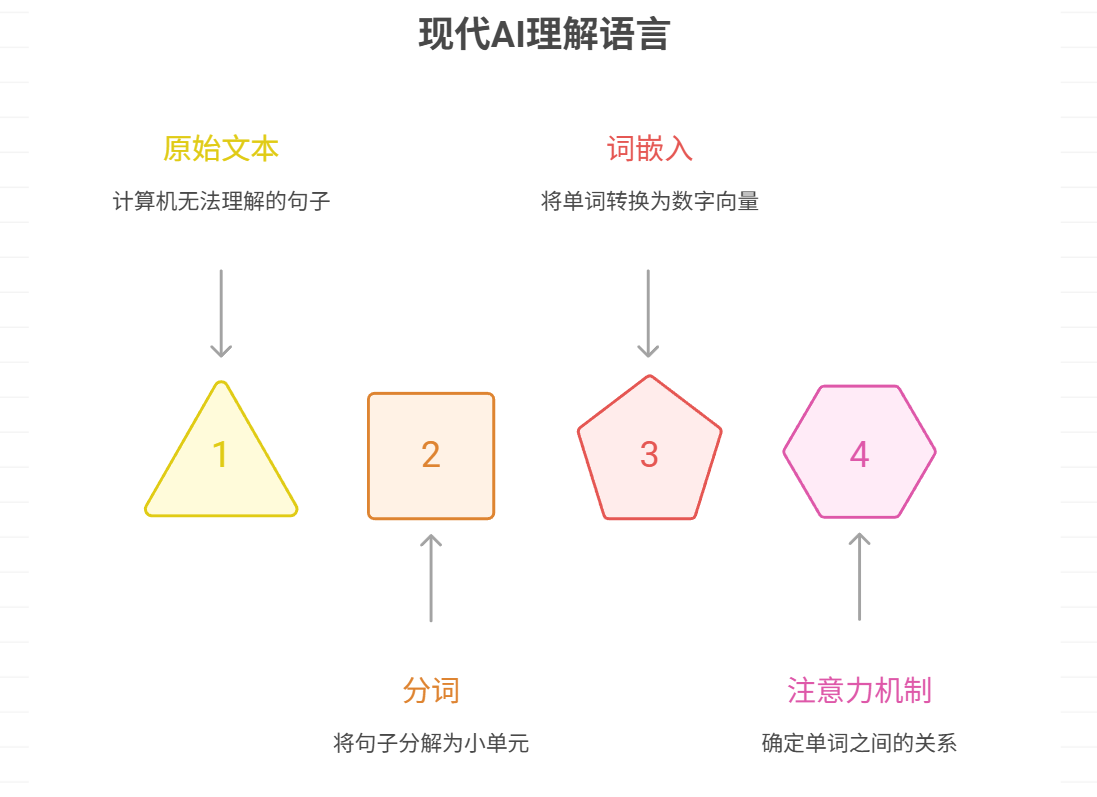
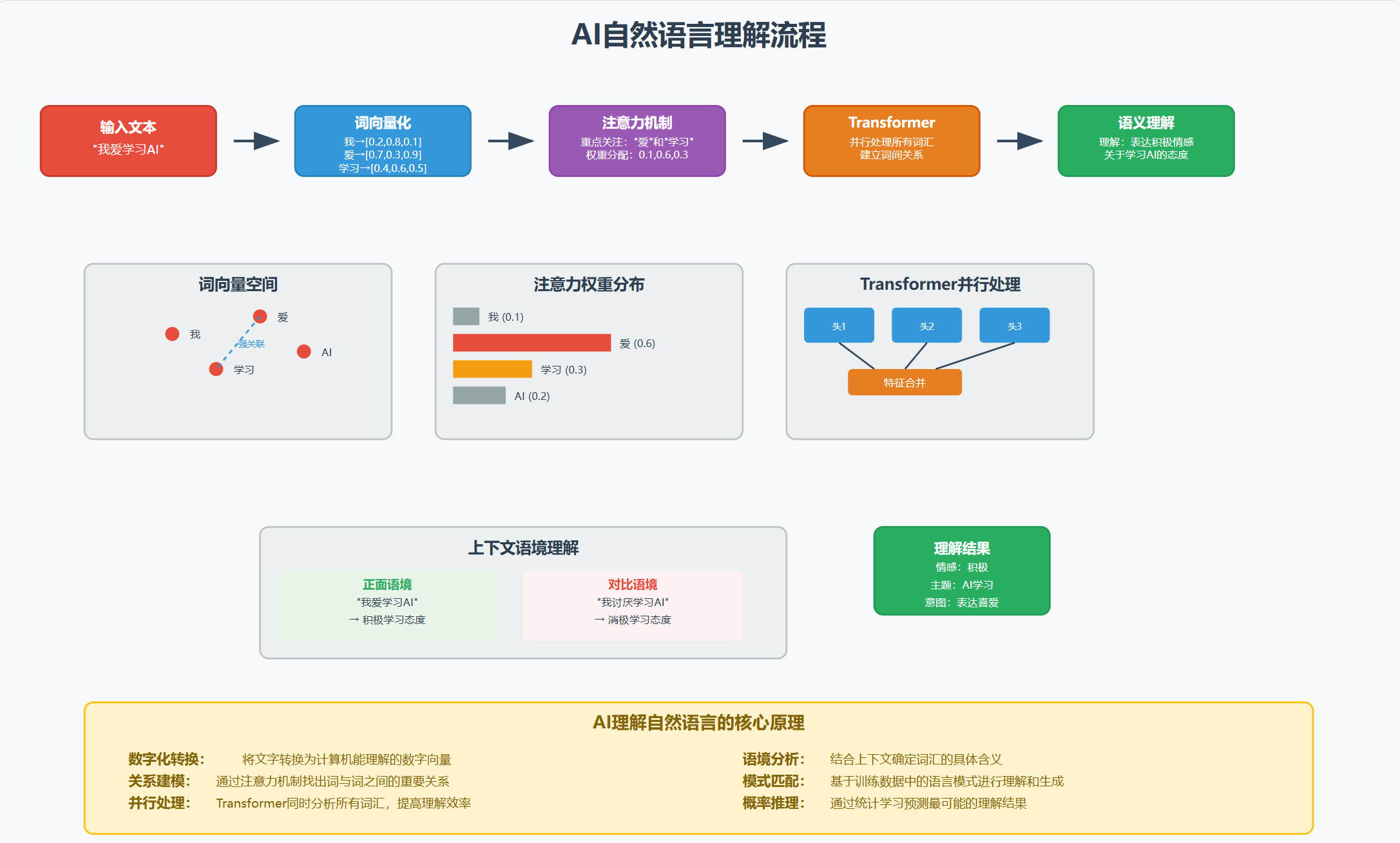
第一步:拆解 (Tokenization - 文本切分)
计算机无法直接处理“句子”这种概念,它只能处理数字。因此,第一步就是要把我们输入的句子打碎成一个个它能处理的小单元,这个过程叫做“分词”或“Tokenization”。
这些小单元(Tokens)可以是单词,也可以是更小的“子词”(subword)。
- 英文例子: “AI understands language” ->
["AI", "understands", "language"] - 中文例子: “人工智能理解语言” ->
["人工", "智能", "理解", "语言"] - 更复杂的例子: “unbelievably” ->
["un", "believe", "ably"](切分成子词,有助于模型理解词根和词缀,从而推断生僻词的含义)
可以把它想象成: 把一句完整的话拆成一个个乐高积木块。这是让计算机能够开始处理文本的第一步。
第二步:翻译 (Embedding - 词嵌入)
拆解成零散的积木块(Tokens)后,下一步是把这些文字积木块“翻译”成计算机能进行数学运算的数字。这个关键步骤就是词嵌入 (Word Embedding)。
每个 Token 都会被映射成一个包含数百甚至数千个数字的列表,这个列表被称为向量 (Vector)。这个向量代表了该 Token 在一个巨大的、多维“语义空间”中的坐标地址。
这个语义空间非常奇妙,它具备以下特点:
- 语义相近,距离相近: “猫”和“狗”的向量在空间中的距离会非常近,而“猫”和“汽车”的向量距离就会很远。
- 关系可计算: 向量之间甚至可以进行数学运算,来表达词语间的关系。最经典的例子是:
"国王"的向量 - "男人"的向量 + "女人"的向量 ≈ "女王"的向量。这表明模型捕捉到了“性别”和“皇室”这两个维度的关系。
可以把它想象成: 一个巨大无比的宇宙图书馆。每一个词都在这个图书馆里有一个精确的位置(坐标/向量)。相关的词(比如“医生”、“护士”、“医院”)会被放在同一个星系里,而不相关的词则相隔遥远。通过查询一个词的坐标,AI 就能知道它和其他所有词的亲疏关系。
像 OpenAI、Google 等公司都有专门的模型来做这项工作,它们是把文字精准“翻译”成数字的专家。
比如OpenAI的
text-embedding-ada-002这个模型就是专门做这一步工作的专家。
第三步:联系上下文 (The Transformer & Attention Mechanism - 核心处理)
如果说前两步只是准备工作,那么这一步才是 AI 真正“理解”语言的核心。模型需要弄清楚在一个具体的句子中,各个词语是如何相互作用,从而构成完整含义的。实现这一点的革命性技术是 Transformer 架构,其核心是注意力机制 (Attention Mechanism)。
在处理一个句子时,注意力机制会动态地计算句子中每个词对于其他词的“重要性”或“关注度”。
举个例子,在处理下面这句话时:
“苹果公司的股价今天上涨了,我下午想吃一个苹果。”
- 当模型处理第一个“苹果”时,注意力机制会分析整个句子,发现“公司”、“股价”这些词与它关系密切。于是模型会给这些词更高的“注意力权重”,从而判断这个“苹果”指的是那个科技巨头。
- 当模型处理第二个“苹果”时,它会更关注“吃”、“一个”这些词,从而判断这里指的是一种水果。
可以把它想象成: 一位经验丰富的厨师在阅读菜谱。他不会对“盐”、“糖”、“油”等每个字都给予同等的关注。当他看到“煎牛排”这个步骤时,他的注意力会高度集中在“黄油”、“火候”、“时间”上;而当他看到“做沙拉”时,他的注意力则会转移到“蔬菜”、“沙拉酱”上。注意力机制就是让 AI 模型在处理不同任务时,能够动态地聚焦于当前最重要的信息。
实战演练:当你说“帮我找个附近便宜的川菜馆”
理论说了这么多,是不是有点晕?别急,让我们马上进入一个真实场景,看看这三步流程在现实中是如何协同工作的。
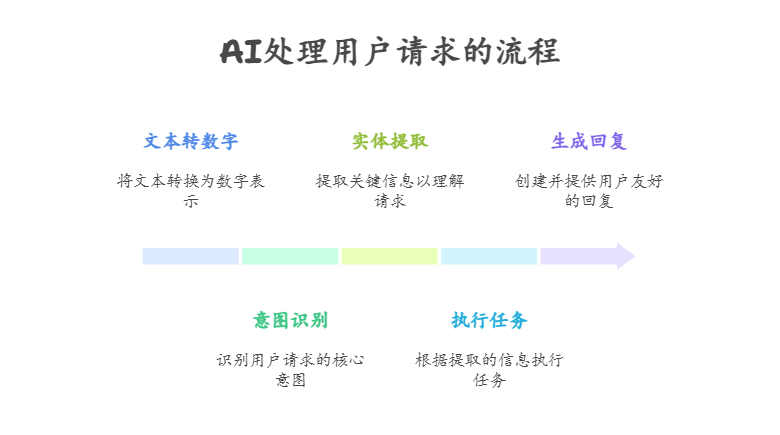
现在,让我们把所有知识点串起来,看看AI是如何处理你这个日常请求的:
- 文本转数字:你的这句话首先会被打散成一个个词(“帮我”、“找个”、“附近”、“便宜的”、“川菜馆”),然后通过“词嵌入”技术,把每个词都转换成它在“词语地图”上的数字坐标。
- 理解意图 (Intent Recognition):AI通过分析整句话的数字序列,尤其是注意到“找个”、“餐馆”这些词,它会判断出你的核心意图是“寻找餐厅”。
- 提取关键信息 (Entity Extraction):接着,注意力机制开始工作。
- 它注意到“附近”,把它标记为【地点】。
- 它注意到“便宜的”,把它标记为【价格】。
- 它注意到“川菜”,把它标记为【菜系】。
- 执行任务:现在,AI已经把你的自然语言指令,转换成了一个结构化的、清晰的命令:
操作:寻找餐厅;条件:地点=附近,价格=便宜,菜系=川菜。 - 生成回复:最后,AI系统会拿着这个清晰的命令去调用地图API或餐厅数据库,找到结果后,再用自然流畅的语言把结果告诉你:“好的,已为您找到3家附近的平价川菜馆……”
最后总结
综合以上描述,AI 的“理解”可以总结为:
- 它不是人类的体验式理解,而是数学化的关系理解。 它不知道什么是“快乐”,但它从数万亿的文本中学到,“快乐”这个词经常和“生日”、“派对”、“好消息”一起出现,而很少和“葬礼”、“失败”一起出现。
- 它的核心是预测。 所有这些复杂处理的最终目的,是让模型能够极其准确地预测下一个最有可能出现的词是什么。一个能完美预测下文的模型,在某种程度上就可以说它“理解”了上文。
- 它的知识来源于数据。 模型的全部“知识”都来自于它所“阅读”过的海量文本和代码。它的回答和行为,都是从这些数据中学习到的模式的再现和组合。
所以,当我们问 AI 一个问题时,它并不是真的“思考”并给出一个答案。而是将我们的问题进行拆解和翻译,然后在它的高维语义空间中,通过注意力机制联系上下文,最终计算出一个概率最高的、最符合它学到的语言模式的词语序列作为回答。