Ascend的aclgraph(五)PrimTorch TorchInductor
1 PrimTorch
参照文章:Torch.compile()流程解析——4. PrimTorch & TorchInductor
在上一篇Ascend的aclgraph(四)AOT Autograd构建joint graph的时候提及过op执行的时候,通过ProxyTorchDispatchMode的torch_dispatch对op进行decompose,具体流程是:
-
调用
maybe_handle_decomp()函数在CURRENT_DECOMPOSITION_TABLE(一个Aten op映射表)中查找op对应的函数实现并返回,若未实现则进入b; -
若不是则调用
decompose()函数继续进行拆解,decompose()实现逻辑如下:
# decompose()函数实现
# path:/torch/_ops.py
def decompose(self, *args, **kwargs):dk = torch._C.DispatchKey.CompositeImplicitAutogradif dk in self.py_kernels:# NB: This branch is not too necessary anymore, because we can# apply Python CompositeImplicitAutograd *before* tracing# using Python dispatcher (also taking advantage of the autograd# formula). But it's included for completenessreturn self.py_kernels[dk](*args, **kwargs)elif torch._C._dispatch_has_kernel_for_dispatch_key(self.name(), dk):return self._op_dk(dk, *args, **kwargs)else:return NotImplemented
从而实现high level op一步步拆解到Aten op的过程。总的来说,PrimTorch是一种规定,将所有的op拆解为一个约定的op规范集合,并作为开发者和硬件厂商之间的一种中间桥梁,Pytorch前端将op拆解映射到PrimTorch,而硬件厂商针对这些特定的op进行优化即可。
2 TorchInductor
TorchInductor 是 PyTorch 的一个高性能编译后端,专注于将优化后的计算图转换为高效的、针对特定硬件(如 CPU、GPU)的内核代码。它利用多种优化技术,包括内存优化、并行化和低层次的代码生成,以最大化计算性能。
aot_dispatch_autograd()函数在拿到前反向的FX Graph后,分别调用fw_compiler、bw_compiler对前反向图进行编译,这里的fw_compiler和bw_compiler可以是不同的compiler(npu就是自定义的),在inductor的默认实现中调用的是compile_fx_inner,而其中的核心函数是fx_codegen_and_compile(),负责对FX Graph进行图优化、Triton内核代码生成等。
TorchInductor的核心实现逻辑如下,感兴趣的小伙伴也可以看看后面的代码解析部分
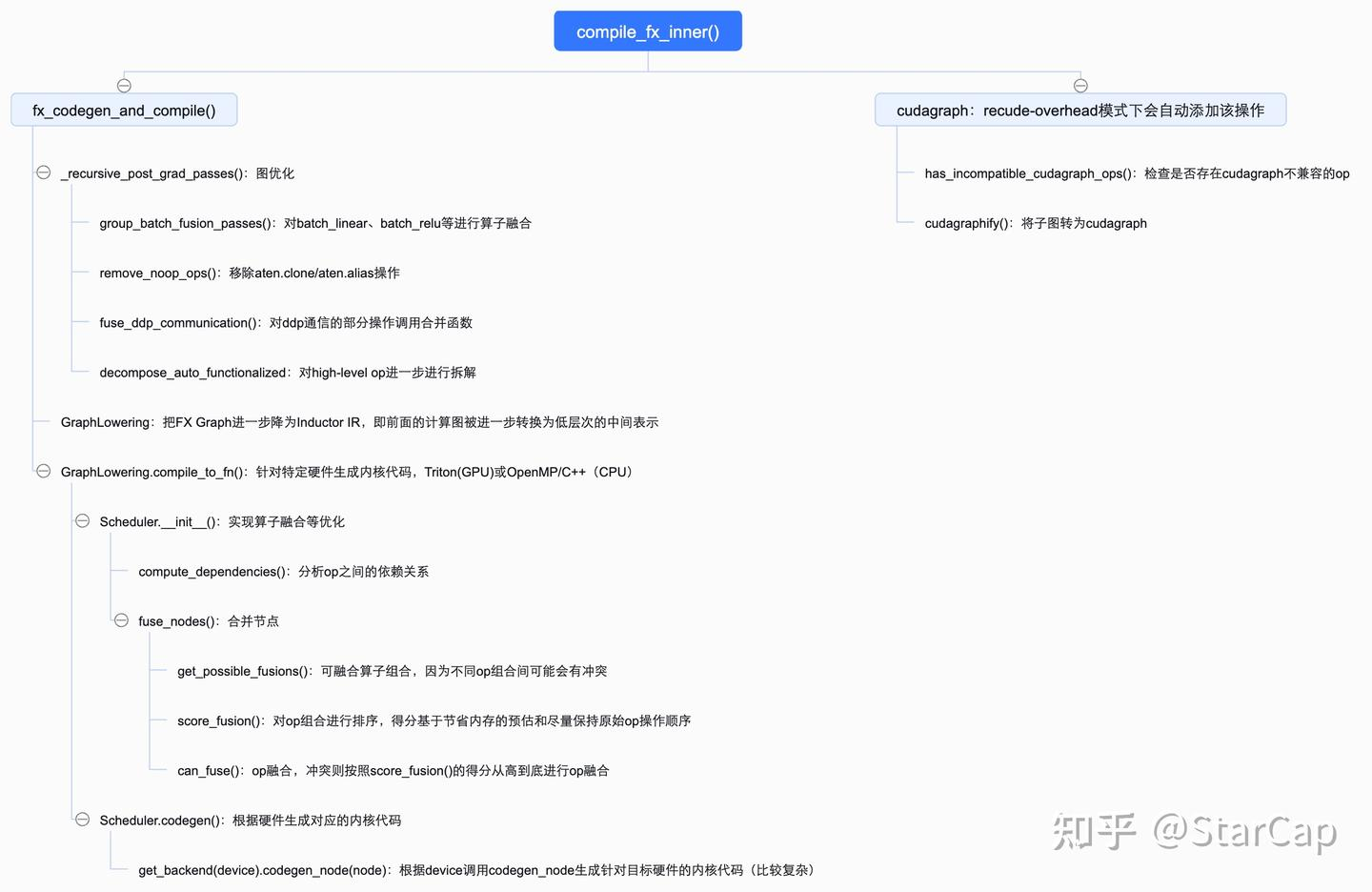
2.1 TorchInductor函数调用
fx_codegen_and_compile()中比较重要的三个函数是:
-
_recursive_post_grad_passes:负责对计算图进一步的优化,包括:group_batch_fusion_passes:对batch_linear、batch_relu、batch_sigmoid等归一化操作进行算子融合,根据融合规则,然后以BFS的方式查找符合规则的op进行融合。remove_noop_ops:移除图形中本质上是 aten.clone 和aten.alias的操作。fuse_ddp_communication:对ddp通信的部分操作调用合并函数进行融合。decompose_auto_functionalized:对high-level op进一步进行拆解(因为前面进行算子融合那些操作可能会引入新的high level op所以这里再操作一遍),将高层次的操作逐步转换为更低层次的实现。
-
GraphLowering:把FX Graph进一步降为Inductor IR,即前面的计算图被进一步转换为低层次的中间表示。这一表示更加接近最终的机器代码,并且适合进一步的代码生成和优化。 -
GraphLowering.compile_to_fn():负责对前面生成的IR表示转换为针对目标硬件低层次代码,GPU上会生成Triton,CPU上会生成OpenMP/C++,npu上是?后续解答,同时可能会利用 SIMD 指令和多线程并行化来加速计算,是inductor中一个核心的实现。
2.2 compile_to_fn()——内核代码生成
compile_to_fn()在Scheduler类中实现内核代码编译的核心功能。而Scheduler的两个函数值得关注:
-
Scheduler.init():实现算子融合等优化,基本流程为:compute_dependencies():分析op之间的依赖关系;fuse_nodes():合并节点,核心逻辑是通过get_possible_fusions获取可融合算子组合(这里只是先选出可融合的,因为可能op之间有交集,所以并未直接执行融合,而是筛出可融合的组合并排序再进行按序融合),然后再调用can_fuse()进一步检查是否可融合,最后进行融合,其中两个重要的函数是can_fuse()检查两个op融合是否合法,score_fusion()对给定的融合op排一个优先级(当融合op组合冲突时以排序分数高的先融合,排序得分基于<1>节省的内存操作的估计,<2> 尽量保持原始操作顺序);
-
Scheduler.codegen():(比较复杂,目前没看懂怎么生成的。。。)codegen_extern_call():是对部分kernel决策进行就地更改并记录决策(没看明白什么操作)self.get_backend(device).codegen_node(node):根据device调用codegen_node生成针对目标硬件的内核代码,如在/usr/local/lib/python3.9/dist-packages/torch/_inductor/codegen/cuda_combined_scheduling.py::codegen_node中实现了生成Triton内核代码。
回到compile_to_module(),将前面生成内核代码以.py文件方式(triton实现)保存到PyCodeCache中,最后调用PyCodeCache.load_by_key_path()获得编译后的module(这个module包含triton代码的临时文件路径),返回到fx_codegen_and_compile()函数中将进一步封装成CompiledFxGraph。
最后回到compile_fx_inner函数中,若支持cudagraph还会对编译后的图进行cudagraph编译优化(torch.compile的recude-overhead模式下会自动添加 CUDA Graph 来减小运行时开销)。读到这里,以为aclgraph中的recude-overhead是专为npu添加,原来是来自于这里。
cudagraph优化具体流程为:
has_incompatible_cudagraph_ops():检查是否存在与cudagraph不兼容的opcudagraphify():将子图转为cudagraph进行优化
到此完成TorchInductor的编译部分,返回一个Triton内核代码实现的CompiledFxGraph,最后一路返回到compile_fx()即inductor的入口,又回到了调用call_user_compiler处,继续进行后续的操作(Ascend的aclgraph(三)TorchDynamo)完成整个流程。
# Inductor核心函数实现
def fx_codegen_and_compile(gm: torch.fx.GraphModule,example_inputs: List[torch.Tensor],cudagraphs: Optional[BoxedBool] = None,static_input_idxs: Optional[List[int]] = None,is_backward: bool = False,graph_id: Optional[int] = None,cpp_wrapper: bool = False,aot_mode: bool = False,is_inference: bool = False,# Use a dict with None value rather than a set for deterministic# iteration order just in case.user_visible_outputs: Optional[Dict[str, None]] = None,layout_opt: Optional[bool] = None,extern_node_serializer: Optional[Callable[[List[ExternKernelNode]], Any]] = None,
) -> Union[CompiledFxGraph, str]:# 省略中间...V.debug.fx_graph(gm, example_inputs)shape_env = _shape_env_from_inputs(example_inputs)view_to_reshape(gm)with torch.no_grad():fake_mode = fake_tensor_prop(gm, example_inputs)with V.set_fake_mode(fake_mode):# has some issues with memory in training_recursive_post_grad_passes(gm, is_inference=is_inference) # 优化计算图,包括group_batch_fusion、remove_noop_ops(拷贝别名处理)、fuse_ddp_communication等V.debug.fx_graph_transformed(gm, example_inputs)post_grad_graphs_log.debug("%s",lazy_format_graph_code("AFTER POST GRAD", gm, include_stride=True, include_device=True),)trace_structured("inductor_post_grad_graph",payload_fn=lambda: gm.print_readable(print_output=False, include_stride=True, include_device=True),)if config.is_fbcode():log_optimus_to_scuba(extra_logging={"pt2_configs": str(get_patched_config_dict())})with V.set_fake_mode(fake_mode), maybe_disable_comprehensive_padding(example_inputs):const_output_index = Noneconst_graph = Noneconst_code = Noneif aot_mode and config.aot_inductor.use_runtime_constant_folding:const_gm, const_output_index = split_const_gm(gm)const_graph = GraphLowering(const_gm,example_inputs=[],shape_env=shape_env,graph_id=graph_id,cpp_wrapper=cpp_wrapper,aot_mode=aot_mode,user_visible_outputs=user_visible_outputs,extern_node_serializer=extern_node_serializer,is_inference=is_inference,is_const_graph=True,)with V.set_graph_handler(const_graph):assert cpp_wrapper, "AOT mode only supports C++ wrapper"const_graph.run()const_code, _ = const_graph.codegen_with_cpp_wrapper()# 降为inductor IR以进一步的优化graph = GraphLowering(gm,# example_inputs will be used by AOTInductor to dry-run the generated code for Triton kernel tuning.# For the forward pass, we have the real inputs to be used as example_inputs. For the backward pass,# we currently use fake tensors and defake them later.example_inputs=example_inputs,shape_env=shape_env,graph_id=graph_id,cpp_wrapper=cpp_wrapper,aot_mode=aot_mode,user_visible_outputs=user_visible_outputs,extern_node_serializer=extern_node_serializer,is_inference=is_inference,const_output_index=const_output_index,const_code=const_code,const_module=const_graph,)metrics_helper = metrics.CachedMetricsHelper()with V.set_graph_handler(graph):graph.run(*example_inputs)output_strides: List[Optional[Tuple[int, ...]]] = []if graph.graph_outputs is not None:# We'll put the output strides in the compiled graph so we# can later return them to the caller via TracingContextfor out in graph.graph_outputs:if (hasattr(out, "layout")and len(free_unbacked_symbols(out.layout.stride)) == 0):output_strides.append(tuple(V.graph.sizevars.size_hint(s) for s in out.layout.stride))else:output_strides.append(None)_check_triton_bf16_support(graph)compiled_fn = graph.compile_to_fn() # 生成对应的后端内核代码,GPU为Triton,CPU为C++/OpenMP# 省略中间代码...# 将编译后代码封装成CompiledFxGraph并返回compiled_graph = CompiledFxGraph(compiled_fn,graph,output_strides,V.graph.disable_cudagraphs_reason,metrics_helper.get_deltas(),)return compiled_graph
到此梳理完了torch.compile()函数的整体流程,解析了从TorchDynamo捕获计算图、再到AOTAutograd捕获前反向计算图并进行算子decompose、以及最后在TorchInductor中完成算子融合和kernel代码生成的实现逻辑,后续再对其中的部分实现细节进行深入分析。