类神经网络训练失败怎么办?
1.optimization fails
可能是我们陷入了local minima, saddle point(鞍点)
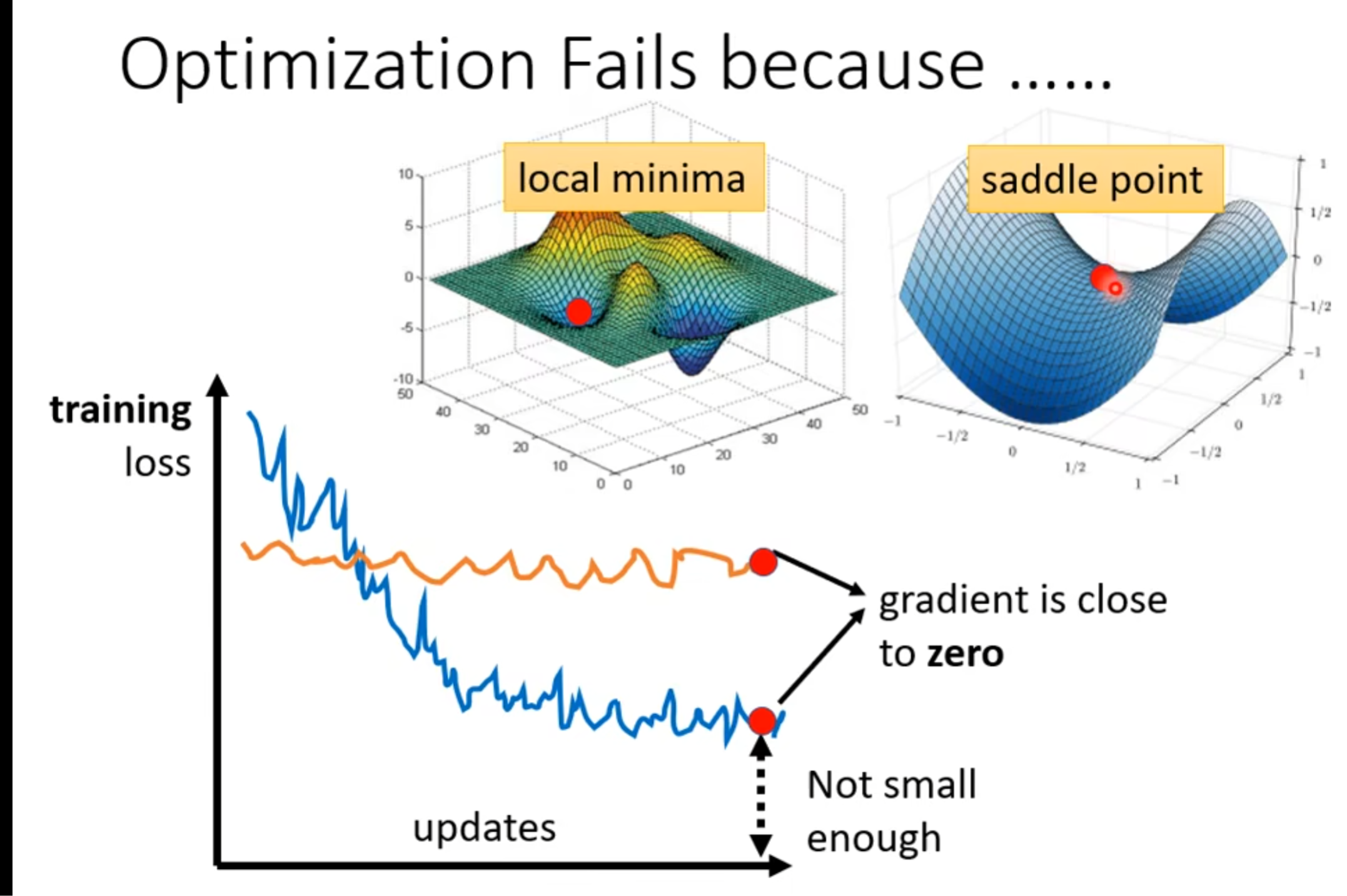
也可以说卡在critical point.
如果我们卡在saddle point的话,我们有办法可以突破
这个loss function是结合了泰勒展开和海森矩阵的式子
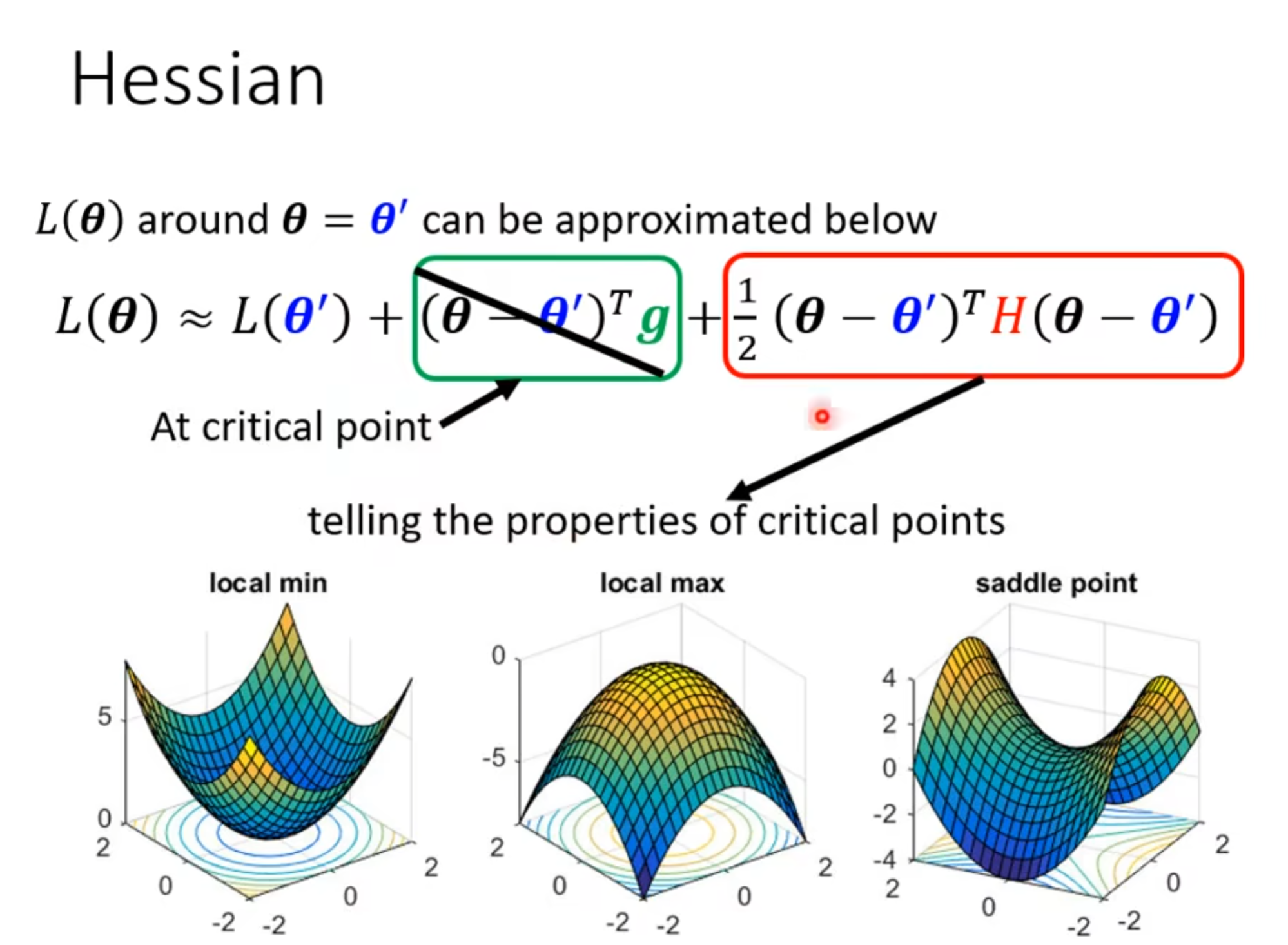 具体是怎么判断的呢,我们知道二阶导其实就是凹凸性,我们就可以根据这个来进行critical points的判断,结合矩阵的特征值 :
具体是怎么判断的呢,我们知道二阶导其实就是凹凸性,我们就可以根据这个来进行critical points的判断,结合矩阵的特征值 :

在我们判断了这个critical points 后,如果是saddle point, 我们可以找到负的特征值,然后找到特征向量,朝着这个方向,可以减少loss 我们可能会疑惑:local minima和saddle point哪个更常见呢,其实我们可以通过升维来进行降维打击,比如说,在二维中看起来像local minimum,但是我们升到三维,它就有可能是saddle point,所以local minimum并没有我们想象的那么多
我们可能会疑惑:local minima和saddle point哪个更常见呢,其实我们可以通过升维来进行降维打击,比如说,在二维中看起来像local minimum,但是我们升到三维,它就有可能是saddle point,所以local minimum并没有我们想象的那么多
2.batch and momentum
我们为什么要用batch,假如我们没有设置batch(full batch), 那么我们的batch size 就是n,我们的model 需要一次性看完所有data才会update一次参数,而设置了batch,我们就可以每一个batch就update 一次参数,但是设置batch相对不准,不设置batch需要运行的时间会长,当然,实际运算的时候,不一定full batch的时间会更长: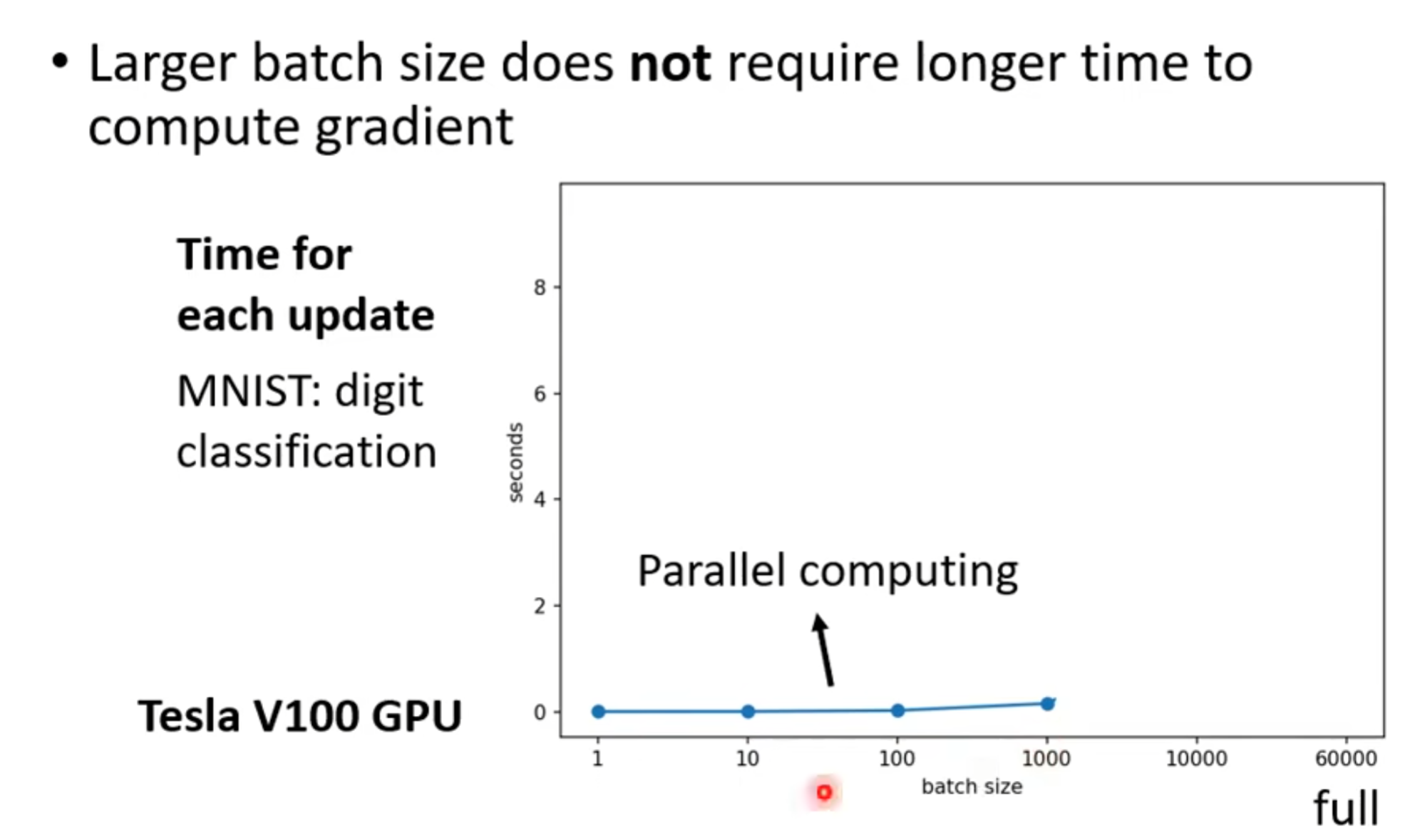
我们有gpu做平行运算 ,这些data会被平行计算,但还是会增长,full batch的size如果很大,那么需要的时间就会长很多,但是,不代表每个epoch的速度会慢,因为batch越小,有越多的update,就要花更多的时间去update
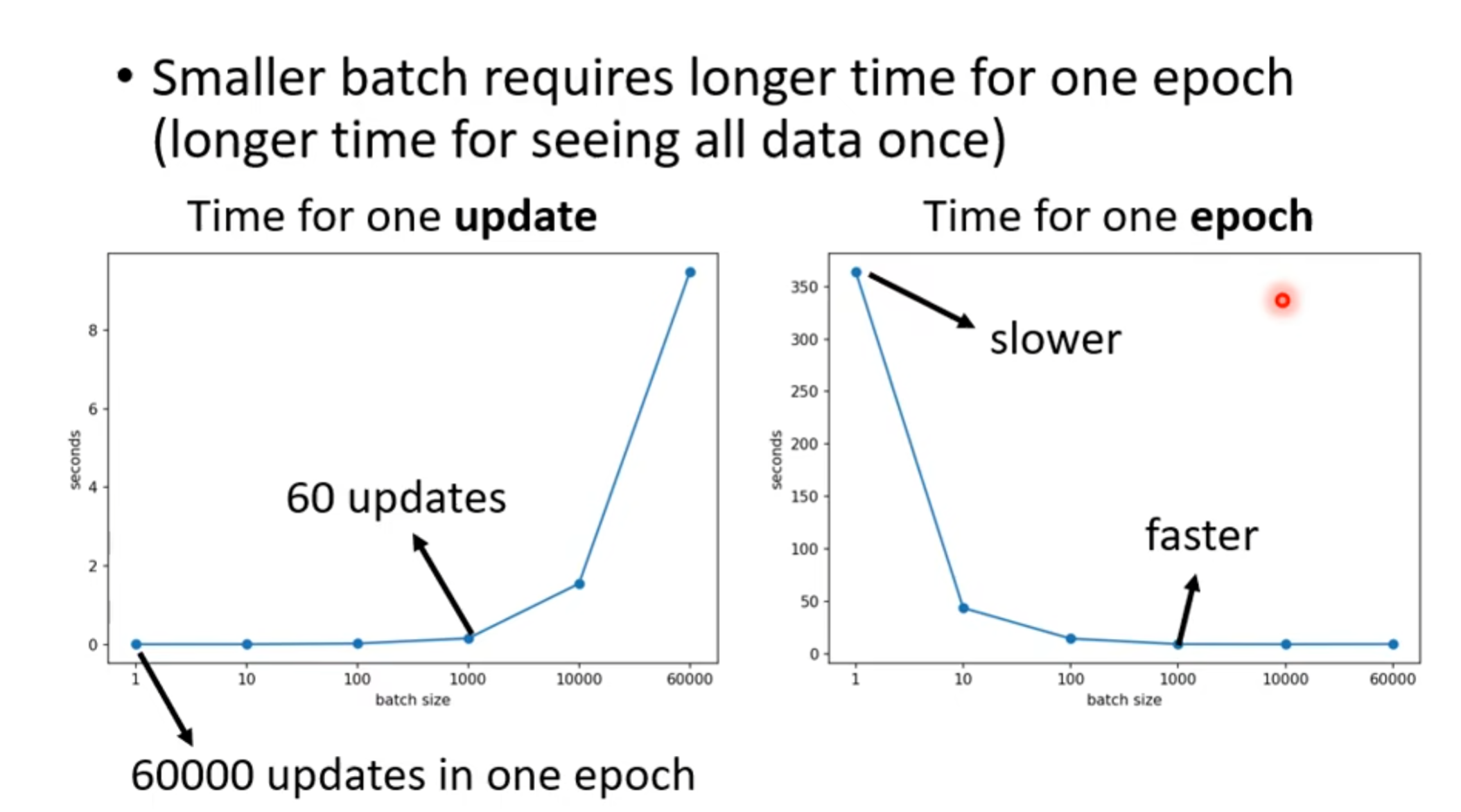
当然这是在运行速度方面来看,如果显存大,我们可以用空间换时间,来让运行速度加快,但从结果来看,却不一定: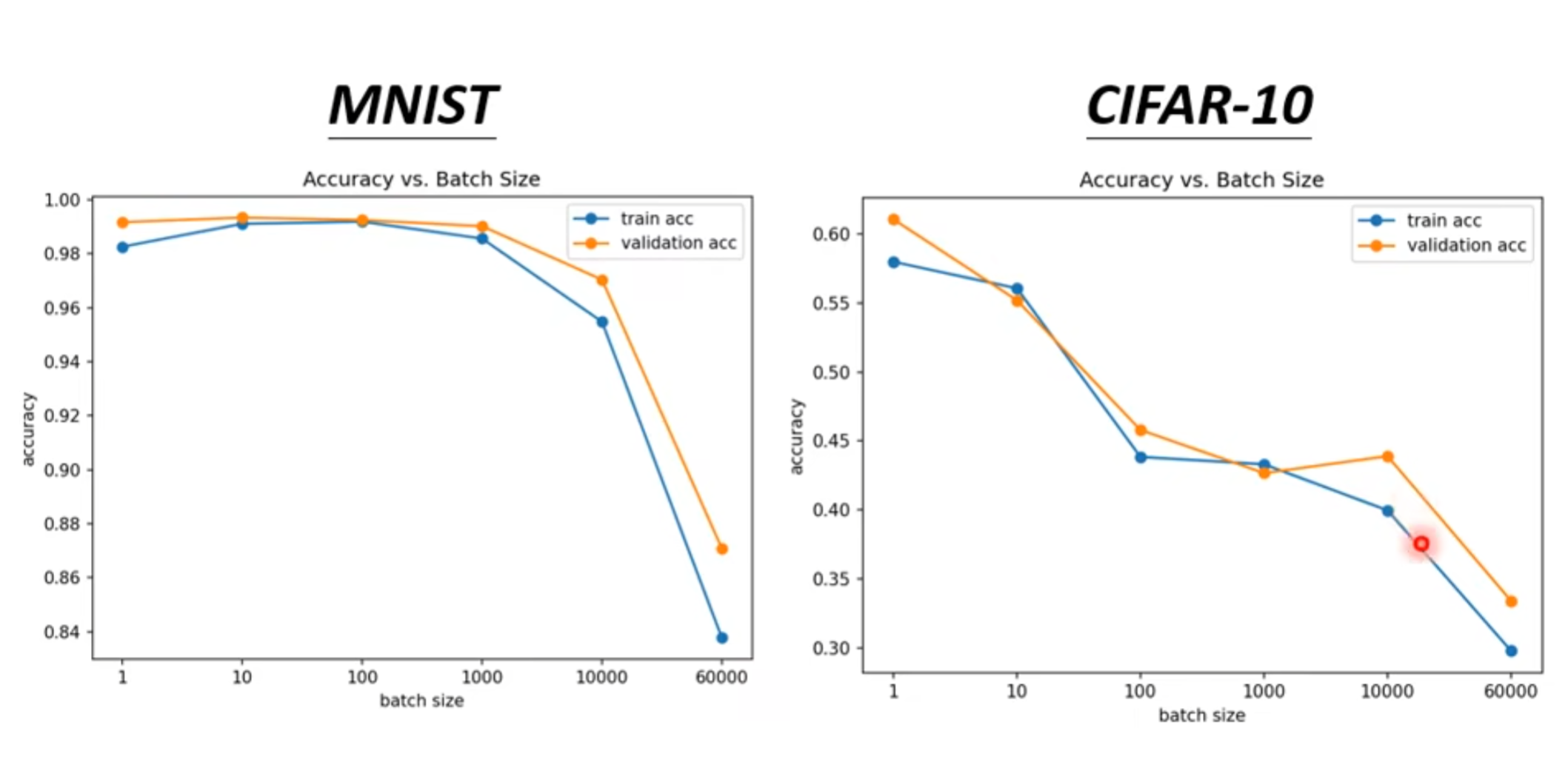
虽然说batch小的话,产生的结果可能会noisy,但从整体上看,竟然是相反的 ,为什么会这样呢: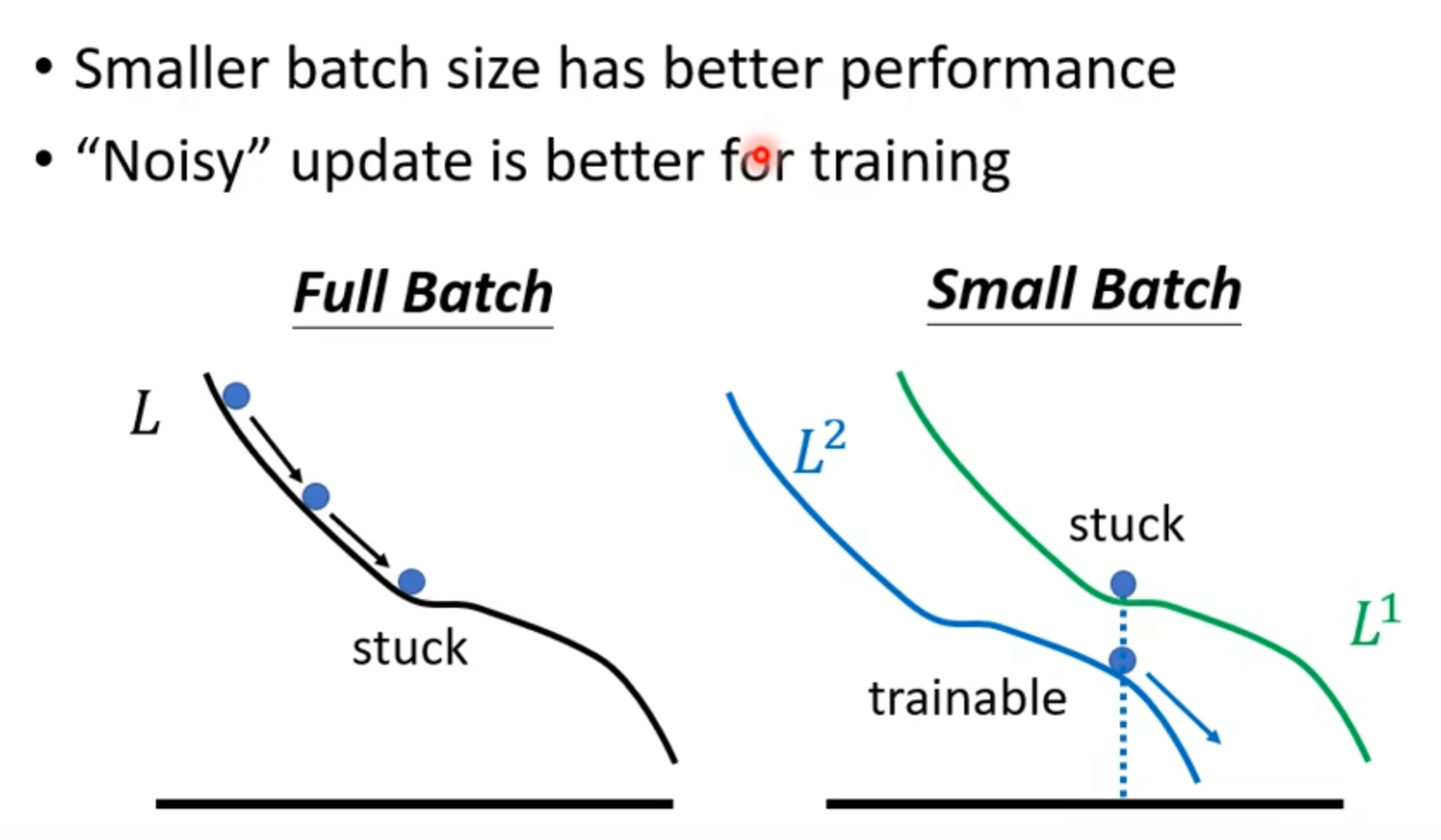
batch不一样后,输入数据不一样,也可以有效避免stuck ,就算training的效果差不多,test的表现还是小batch好: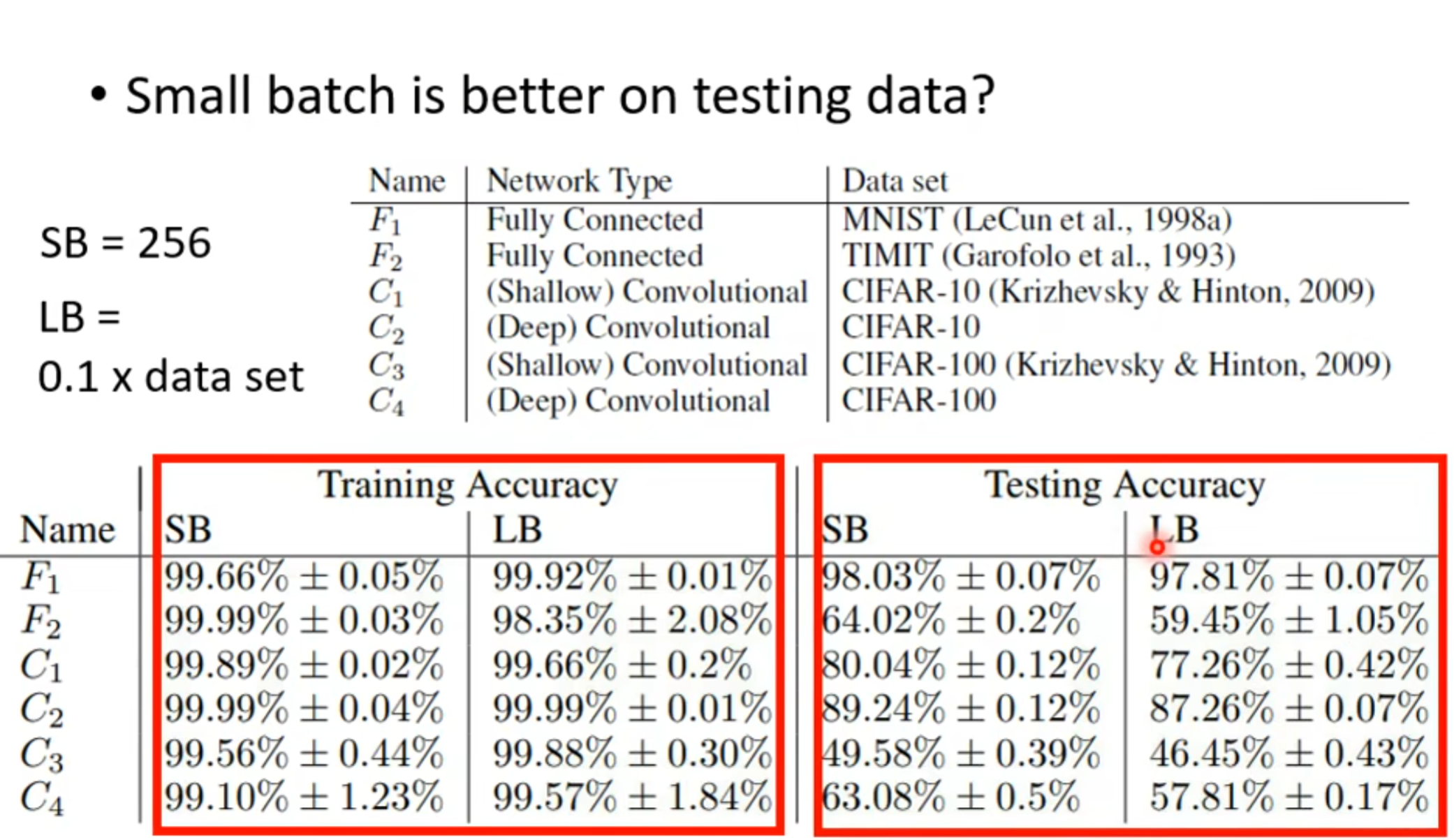
大的batchsize会倾向于走到bad minima: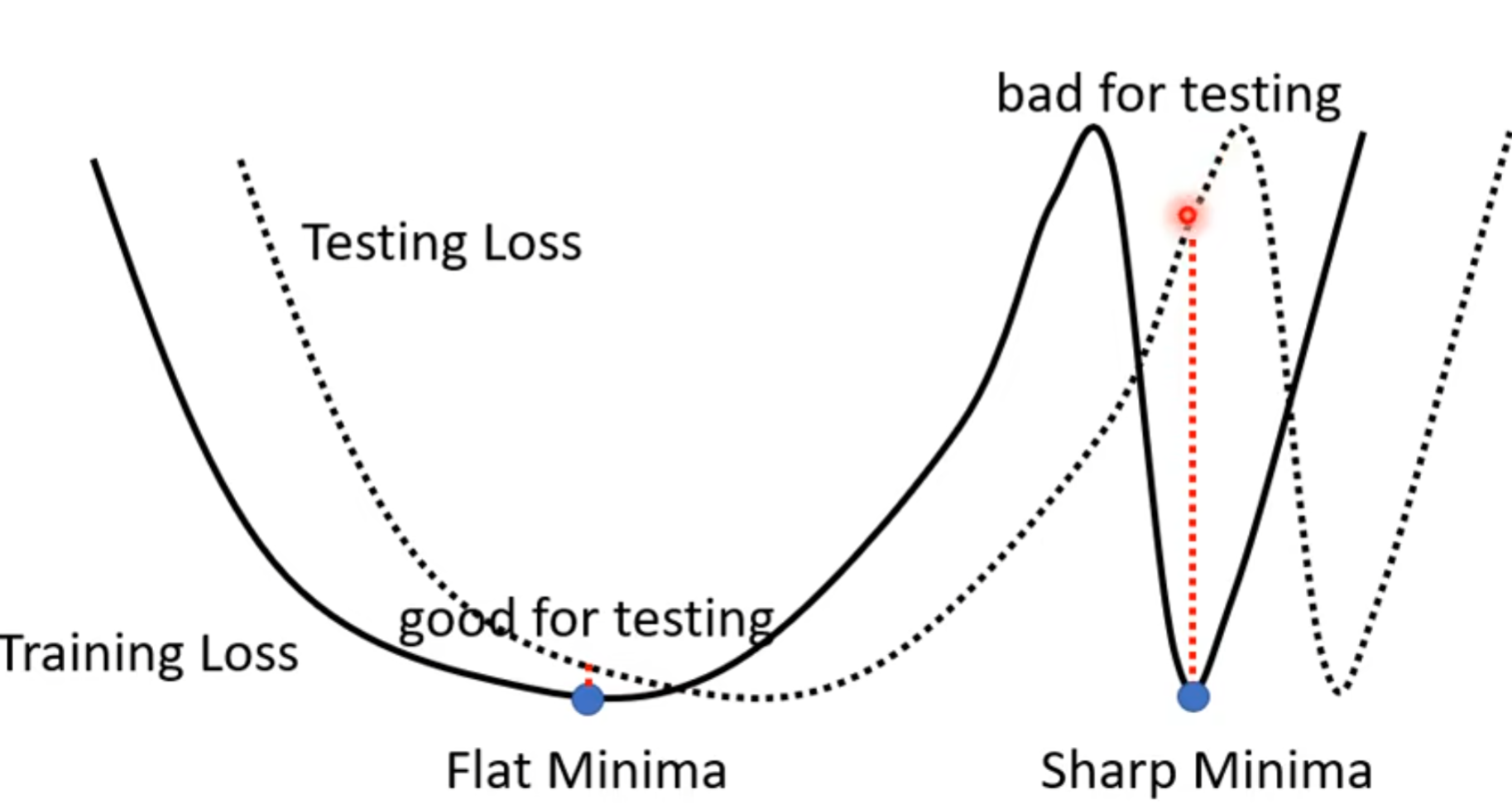
batch size选择: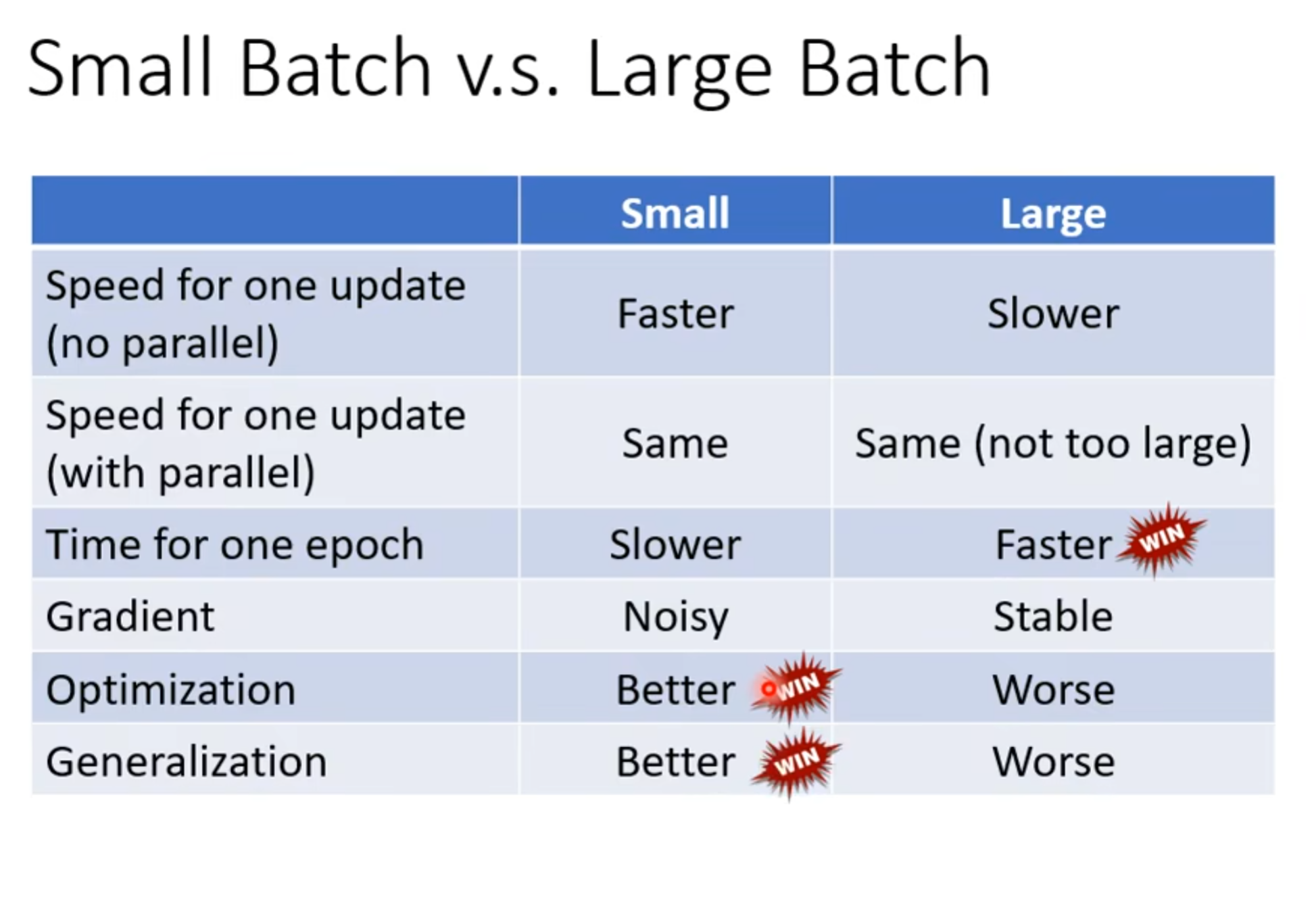
对于momentum,我们可以引入这么一个例子:在现实世界中,因为惯性,小球会冲出这个local minima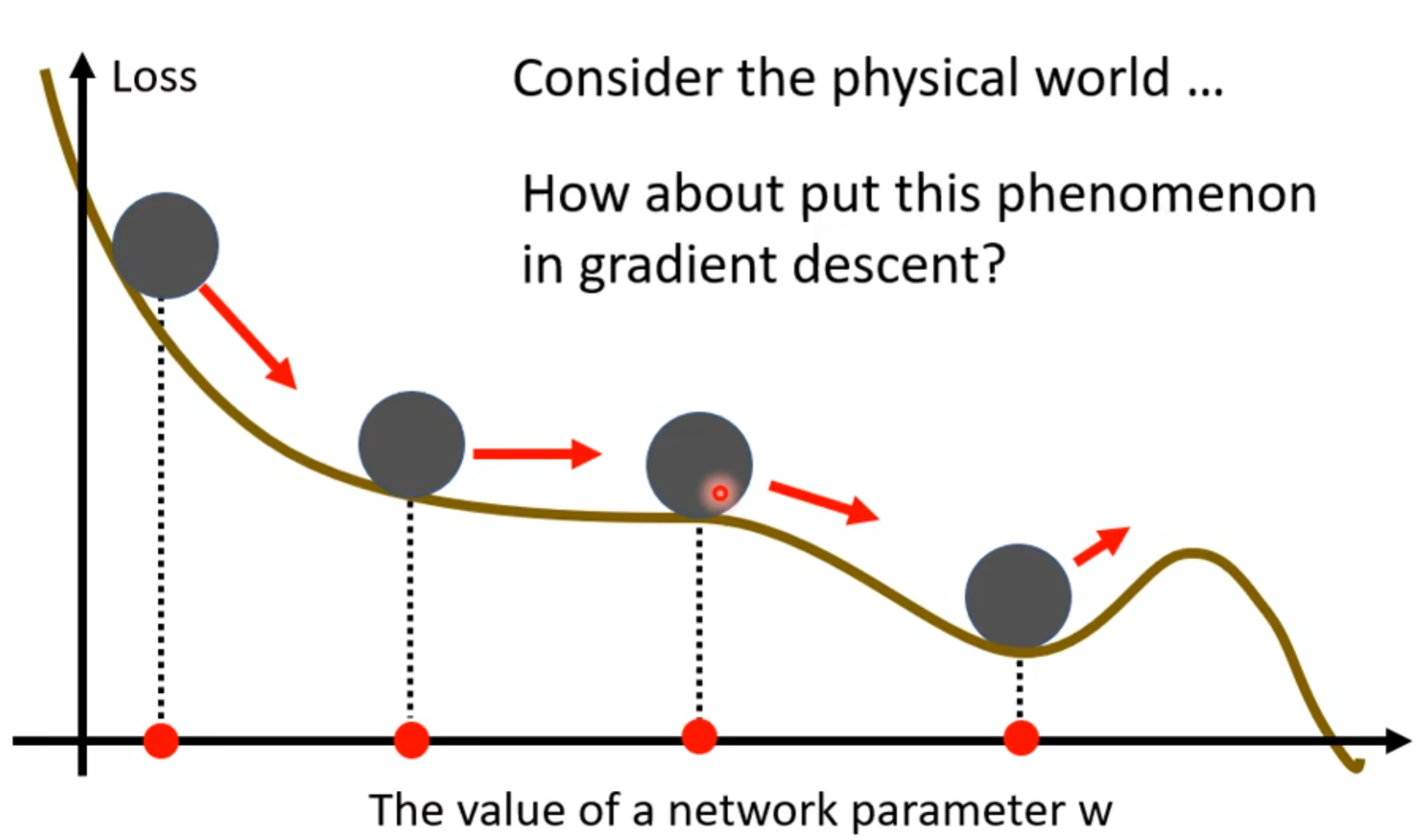
然后是这么实现的,根据前一步的movement和本身的这个gradient方向: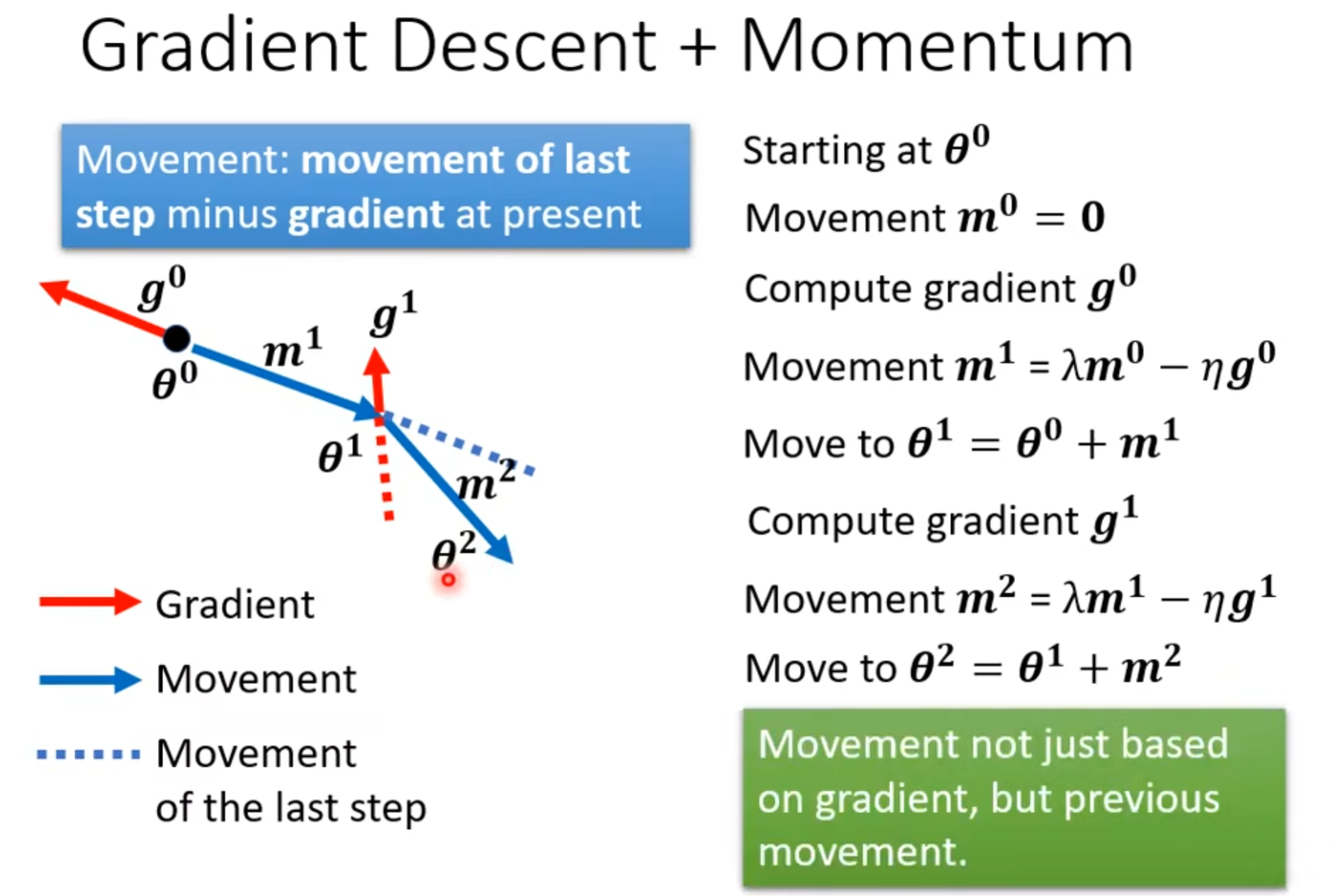
增加了跳过minima的概率