第十三章:LLM 应用质量保证:评估体系、工具与实战
章节引导:经过前面章节的学习,我们已经能够运用 LangChain、LlamaIndex、LangGraph、AutoGen、CrewAI 等框架构建出功能强大的 RAG 和 Agent 应用。但是,“能跑起来”距离一个真正“好用”、可靠、能在生产环境中为用户创造价值的应用还有很长的路要走。如何衡量我们构建的应用的效果?如何发现潜在的问题和风险?如何指导后续的迭代优化方向?本章,我们将聚焦于 LLM 应用开发中至关重要的环节——质量保证与评估。我们将探讨评估的关键维度、策略与挑战,并深入实践主流的评估工具(如 RAGAs)、理解 Agent 基准测试的方法论,以及掌握人工评估和 A/B 测试等关键实践,为你构建一个完善的、能够驱动持续改进的应用评估体系。
核心理念: 评估不是一次性的验收,而是贯穿于 LLM 应用整个生命周期的、持续迭代优化循环的关键驱动力。
13.1 LLM 应用评估:为何评?评什么?怎么评?
为何评估至关重要?
对 LLM 应用进行系统性评估是必不可少的,原因在于:
- 迭代优化: 没有量化指标,优化就无从谈起。“感觉更好”是不可靠的。
- 风险控制: LLM 可能产生不准确、有偏见、有害甚至捏造的信息(幻觉)。评估有助于识别和控制风险。
- 效果验证: 向用户或管理层证明应用价值,需要客观数据支撑。
- 用户满意度: 构建用户喜欢并能有效使用的应用是最终目标。
- 成本效益分析: 评估有助于平衡效果与成本(API 调用、计算资源)。
评什么?关键维度与指标

评估 LLM 应用需从多维度考量:
- 任务效果 (Task Performance):
- 准确性 (Accuracy): 答案正确的比例。
- 相关性 (Relevancy): 输出与查询的相关度。
- 任务完成率 (Task Success Rate): Agent 能否成功完成目标。
- 内容质量 (Content Quality):
- 流畅度 (Fluency): 语言是否自然通顺。
- 一致性 (Coherence/Consistency): 逻辑是否一致,多轮对话是否连贯。
- 忠实度 (Faithfulness/Groundedness): (核心) 答案是否忠实于上下文 (RAG) 或事实。衡量“幻觉”。
- 安全性与可靠性 (Safety & Reliability):
- 偏见 (Bias): 是否存在不公平偏见。
- 毒性 (Toxicity): 是否生成有害内容。
- 鲁棒性 (Robustness): 对抗性或微小变化的输入下表现是否稳定。
- 效率 (Efficiency):
- 延迟 (Latency): 请求响应时间。
- 成本 (Cost): API 费用、Token 消耗、计算资源。
- 用户体验 (User Experience):
- 满意度评分 (User Satisfaction): 用户直接评分。
- 易用性 (Usability): 应用是否易于操作。
选择哪些维度和指标取决于应用类型和核心目标。
怎么评?评估策略概览
评估方法多样:
- 离线评估 (Offline) vs. 在线评估 (Online):
- 离线: 使用预设数据集,无需真实用户。速度快、可重复,适合开发迭代。常用自动化指标、人工评估。
- 在线: 部署后收集真实用户数据(A/B 测试、反馈)。反映真实表现,但实施复杂。
- 自动化评估 (Automated) vs. 人工评估 (Human):
- 自动化: 算法或模型(如 RAGAs)计算指标。高效、低成本、可规模化。可能无法捕捉主观感受,评估模型本身也可能存偏见。
- 人工: 人类根据指南打分或比较。能评估细微差别和主观质量,是黄金标准。但成本高、速度慢、主观性强,需保证评估者一致性。
- 组件级评估 (Component-level) vs. 端到端评估 (End-to-end):
- 组件级: 单独评估检索器、生成器、工具调用等。有助于定位瓶颈。
- 端到端: 评估整个应用完成任务的最终效果。更接近用户体验。
面临的挑战:
- 缺乏标准答案 (Ground Truth): 开放式任务答案多样。
- 评估成本高: 人工和自动化评估都需要资源。
- 指标设计难: 设计既反映需求又可量化的指标不易。
- 结果波动性: LLM 输出有随机性。
因此,通常需要结合多种方法和指标,构建综合评估体系。
13.2 RAG 评估利器:RAGAs 深度实践与解读
RAGAs (Retrieval-Augmented Generation Assessment) 是流行的 RAG 评估框架,它利用 LLM 本身来评估 RAG 管道,大部分核心指标不依赖人工标准答案。
回顾与深化: 本节侧重于使用 RAGAs 进行诊断和优化。
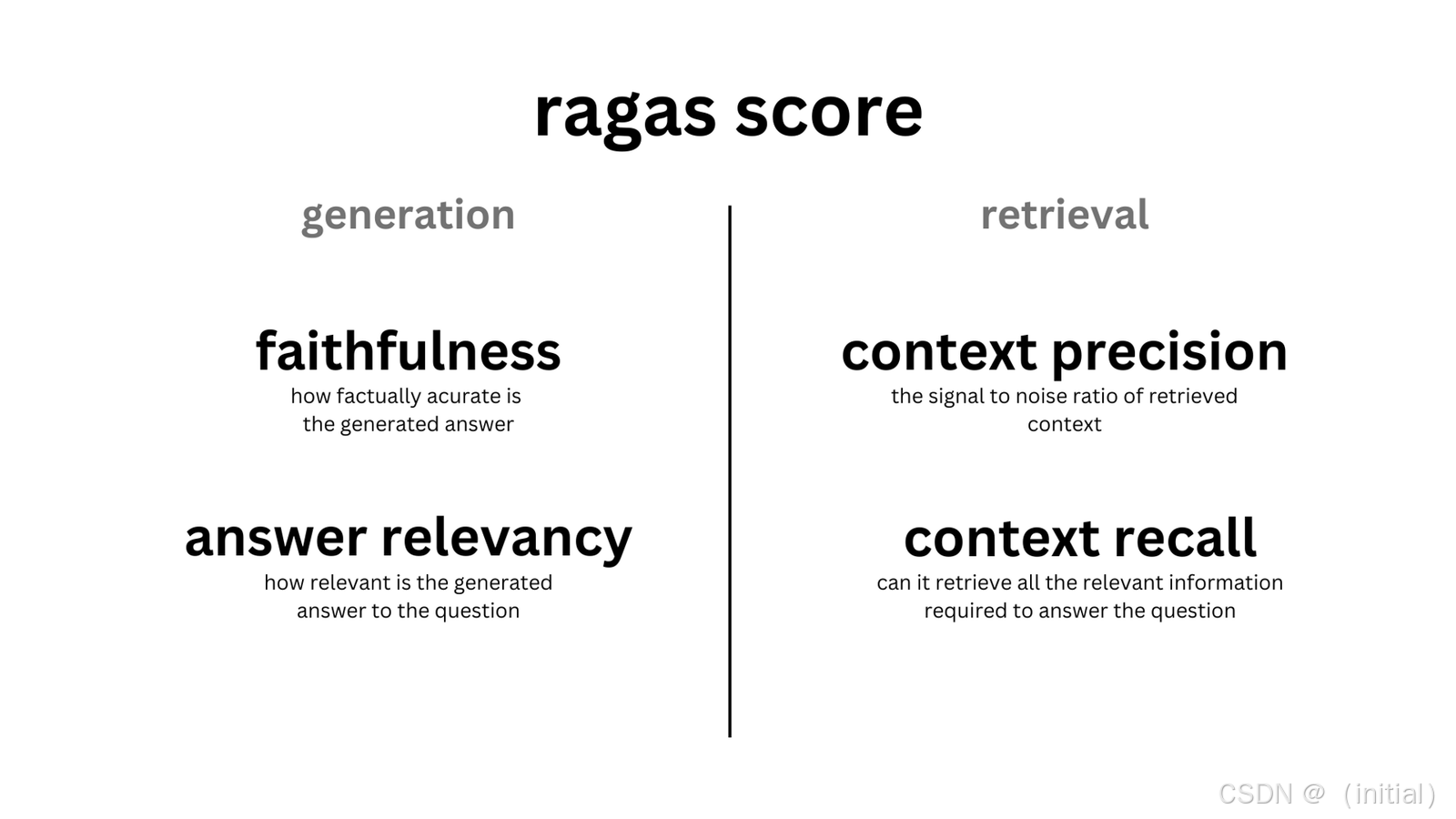
核心指标再理解:
- 生成端 (Generation):
faithfulness(忠实度): (核心) 答案陈述是否基于上下文?(衡量幻觉)answer_relevancy(答案相关性): 答案与问题是否相关?(衡量跑题)
- 检索端 (Retrieval):
context_precision(上下文精确率): 上下文中相关部分的比例?(衡量信噪比)context_recall(上下文召回率): 上下文是否包含回答所需的所有信息?(衡量遗漏)
- 其他指标:
answer_correctness(需 Ground Truth),aspect_critique(自定义标准) 等。
实战演练:评估 RAG 策略 (可运行示例)
# 确保已安装: pip install ragas pandas datasets openai python-dotenv tiktoken
import os
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import (faithfulness,answer_relevancy,context_precision,context_recall,answer_correctness # 需要 ground_truth
)
from dotenv import load_dotenv
import pandas as pd # 用于更好地显示结果# 加载环境变量 (需要包含 OPENAI_API_KEY)
load_dotenv()# --- 准备一个极小的示例数据集 ---
# 在实际应用中,你需要用你的 RAG 系统处理一批问题来生成这个数据
data_samples = {'question': ["What is the capital of France?","Who wrote 'Hamlet'?","When did the first man land on the moon?" # Example where context might be less direct],'answer': [ # These are the answers generated by YOUR RAG system"The capital of France is Paris, known for the Eiffel Tower.","William Shakespeare wrote 'Hamlet'.","The first manned moon landing was achieved by NASA's Apollo 11 mission."],'contexts': [ # List[str] retrieved by YOUR RAG system for each question["France is a country in Western Europe.", "Paris is its capital city and a major global center for art and culture.", "The Eiffel Tower is an iconic landmark in Paris."],["'Hamlet' is a famous tragedy written by the English playwright William Shakespeare around 1600.", "Shakespeare's works include comedies, tragedies, and histories."],["NASA's Apollo program aimed to land humans on the Moon.", "Apollo 11 was the spaceflight that first landed humans on the Moon on July 20, 1969.", "Neil Armstrong was the first person to step onto the lunar surface."]],'ground_truth': [ # Optional: The factual correct answer"Paris is the capital of France.","William Shakespeare wrote 'Hamlet'.","The first manned moon landing occurred on July 20, 1969."]
}
eval_dataset = Dataset.from_dict(data_samples)# --- 配置评估指标 ---
# 注意:answer_correctness 需要 'ground_truth' 列
metrics_to_use = [faithfulness,answer_relevancy,context_precision,context_recall,answer_correctness,
]print("\n--- Running RAGAs Evaluation (on small sample) ---")
# RAGAs 内部会调用 LLM (默认 OpenAI) 和 Embedding (默认 OpenAI)
# 确保 OpenAI API Key 有效且有额度
try:# 运行评估# 对于 notebook 环境或需要更多调试信息,设置 is_async=Falseresult = evaluate(dataset=eval_dataset,metrics=metrics_to_use,# llm=ChatOpenAI(model="gpt-4o"), # 可以指定评估用的 LLM# embeddings=OpenAIEmbeddings(model="text-embedding-3-small") # 可以指定 embeddingraise_exceptions=False # Don't stop evaluation if one row fails)print("\nRAGAs Evaluation Result (Aggregated Scores):")print(result)# 转换为 Pandas DataFrame 查看每行的详细分数eval_df = result.to_pandas()print("\nEvaluation DataFrame (Detailed Scores per Row):")pd.set_option('display.max_colwidth', None) # 显示完整列内容print(eval_df)except Exception as e:print(f"\nError during RAGAs evaluation: {e}")print("Please ensure your OpenAI API key is set correctly in environment variables.")print("Check API rate limits, model access permissions, and required libraries (tiktoken).")
结果解读与诊断:
- 对比不同管道: 运行不同 RAG 策略(基础、重排序、自查询等)生成的
eval_dataset,比较它们在各项指标上的得分差异。 - 诊断瓶颈:
- 低
context_recall/precision: 检索端问题。优化:分块、嵌入模型、检索算法。 - 低
faithfulness/relevancy: 生成端问题。优化:Prompt、更强 LLM、检查上下文质量。 - 低
answer_correctness: 对比faithfulness,如果 Faithfulness 高但 Correctness 低,说明检索到的上下文本身可能有误。
- 低
机制探讨:LLM as a Judge
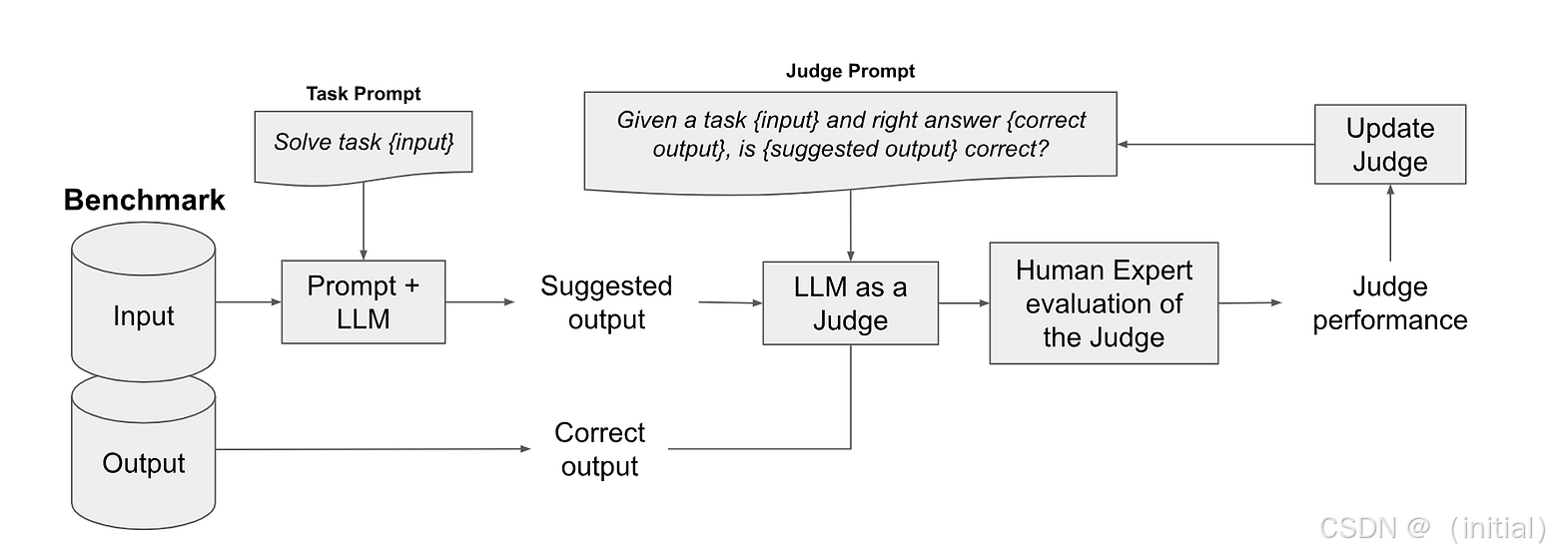
RAGAs 的许多指标依赖让 LLM 扮演“评委”。
- 优势: 无需人工标注,自动化评估语义。
- 局限: 评委 LLM 可能存偏见、位置偏差;有 API 成本;评分可能不完全一致。
尽管有局限,LLM as a Judge 仍是极有价值的评估方法。
13.3 Agent 能力评估:理解基准与简化实践
评估 Agent 的规划、推理、工具使用能力比评估 RAG 更复杂。
挑战: 任务开放、成功标准难定义、执行路径动态、需模拟环境。
理解主流基准 (AgentBench / ToolBench):
完整运行这些大型基准可能复杂,但理解其设计思想很有价值:
- 任务设计: 测试特定能力,如 OS 操作 (AgentBench)、调用真实 API (ToolBench)、Web 浏览 (WebArena)、复杂推理 (GAIA)。
- 环境模拟: 提供可靠的测试环境(模拟 OS、Web、真实 API 调用沙箱)。
- 成功标准与指标: 任务成功率 (Success Rate)、步骤效率 (Efficiency)、工具调用准确率 (Tool Call Accuracy) 等。
- 解读公开报告: 了解 SOTA 模型或框架在这些基准上的表现和能力差异。
简化版实践探索:
在项目中进行初步 Agent 评估:
- 设计特定、可控任务: 如“用 CRM 工具查询用户订单历史”。
- 定义明确成功标准: 如“成功调用工具,返回正确订单列表”。
- 手动或脚本评估: 运行 Agent,记录关键步骤(工具调用参数、返回值),检查:
- 工具是否被调用?名称是否正确?
- 参数是否符合预期?
- 工具是否成功执行?
- 最终任务是否达成?
- 计算指标: 工具调用成功率、参数准确率、端到端任务成功率等。
示例:评估天气工具调用参数准确性 (伪代码/思路)
# 假设 agent_executor 是你的 Agent
# 假设 get_tool_calls_from_log_or_langsmith(tool_name) 能获取最近一次调用信息test_cases = [{"query": "Weather in London?", "expected_city": "London", "expected_unit": "celsius"},{"query": "Tokyo temp in fahrenheit?", "expected_city": "Tokyo", "expected_unit": "fahrenheit"},# ... more cases
]correct_calls = 0
tool_called_count = 0 # Count how many times the specific tool was calledfor case in test_cases:print(f"Running case: {case['query']}")try:agent_executor.invoke({"input": case["query"]})# --- 从日志或 LangSmith 获取工具调用信息 ---logged_calls = get_tool_calls_from_log_or_langsmith("get_weather_robust") # Placeholderif logged_calls:tool_called_count += 1actual_params = logged_calls[0] # Assuming first call is the relevant one# Check if parameters match expected values (handle default unit)city_match = actual_params.get("city") == case["expected_city"]unit_match = actual_params.get("unit", "celsius") == case["expected_unit"]if city_match and unit_match:correct_calls += 1print(" Result: Correct Parameters")else:print(f" Result: Incorrect Parameters. Got: {actual_params}, Expected: {case}")else:print(" Result: Tool 'get_weather_robust' not called.")except Exception as e:print(f" Result: Agent execution error: {e}")# --- 计算准确率 ---
if tool_called_count > 0:parameter_accuracy = (correct_calls / tool_called_count) * 100print(f"\nTool Call Parameter Accuracy: {parameter_accuracy:.2f}% ({correct_calls}/{tool_called_count} correct calls)")
else:print("\nTool 'get_weather_robust' was not called in any test case.")# --- Placeholder ---
def get_tool_calls_from_log_or_langsmith(tool_name):# Implement logic to parse logs or use LangSmith SDK to get actual tool call argumentsprint(f"[Placeholder] Checking logs/LangSmith for calls to '{tool_name}'...")# Return empty list for this placeholder examplereturn []
注意:这种简化评估无法替代大型基准,但为内部迭代提供了有价值的反馈。
13.4 人工评估:设计、执行与最佳实践
自动化指标无法捕捉所有细微差别,人工评估 (Human Evaluation) 仍是黄金标准。
为何需要人工评估? 评估主观质量(流畅度、创造性)、发现细微错误、评估安全性/偏见、了解用户偏好。
流程设计:
- 明确评估目标。
- 设计评估任务与界面。
- 制定清晰的评估指南 (Rubrics): (核心!)
- 最佳实践: 具体、客观、可操作、包含正反例。
- 招募与培训评估员。
- 执行评估。
- 计算评估者一致性 (IAA): (重要!) 使用 Kappa 系数等衡量一致性。低 IAA 意味着指南不清或培训不足。
- 分析结果。
标注平台: Label Studio (开源), Scale AI, Appen, SageMaker Ground Truth 等。
13.5 在线评估:A/B 测试的实践与挑战
最终检验效果需依靠真实用户数据,A/B 测试是标准方法。
核心思想: 用户随机分组,一组用旧版 (A),一组用新版 (B),比较核心业务指标差异。
关键要素:
- 明确假设。
- 核心业务指标 (转化率、满意度等)。
- 用户随机分流。
- 足够运行时间。
- 统计显著性分析。
LLM 应用的特定挑战:
- 结果不易复现(随机性)。
- 需设计能反映 LLM 质量的业务指标。
- 伦理考量(避免负面体验)。
- 新奇效应。
工具/框架: Optimizely, VWO, LaunchDarkly 或自建系统。
13.6 总结:构建持续优化的评估闭环
LLM 应用质量保证是一个持续、多维度的过程,需要构建评估闭环:
评估体系全景图:
- 开发阶段: 自动化指标 (RAGAs) + 单元测试快速迭代。
- 测试阶段: 人工评估 (主观质量、边界) + 理解基准方法。
- 上线阶段: A/B 测试验证真实效果和业务影响。
- 运维阶段: 持续监控指标和用户反馈。
评估的最终目的, 不是得分,而是驱动应用的持续改进,提升质量、用户满意度和业务价值。评估是优化循环的起点。