机器学习Day15 LightGBM算法
浅谈LightGBM算法:我们之前讲的集成学习算法分为三要素吧,就是形式,损失函数,优化方法,但是LightGBM算法并没有固定的形式,它主要是针对具体算法给出一些优化,它更像是前向分步算法一样,像一个框架。在我们讲过以后,大家自然会明白:
1.基于直方图的决策树算法:
与一般算法不同的是(我们拿xgboost算法对比),我们并不是遍历所有特征所有取值,而是去构造一个直方图,将这个直方图的离散值进行遍历,这样的话不同于xgboost算法需要遍历一个特征的所有值,这样就需要进行一个预排序,预排序就是导致算法速度慢,内存需求大的主要原因,但是如果选取直方图的离散值作为遍历点,只需要遍历响应数量即可,大大简化计算量。

就是每次我们只选取一个特征来进行直方图的构造。来看一个案例 来方便理解:

就是做了直方图以后去遍历这些节点,然后通过增益去选取这一个直方图(对应一个特征)的最优分割节点(注意直方图的点) ,然后我们每个直方图都有一个最优的点,然后我们看全局最大增益去选择一个特征的一个直方图点进行划分节点。。注意这个问题:

2.叶子节点的作差加速:显然作为一个二叉树,一个子树的直方图可以由父节点的直方图减去另一个子节点的直方图得到 ,这样会让速度很快。
3.带深度限制的Leaf-wise生长策略:
一般的算法要对每一层的每一个节点进行分裂,但事实上有许多节点的分裂增益很小,对它进行划分会显得没有意义,所以这个算法的策略就是只是选择最大的增益叶子结点进行分列:
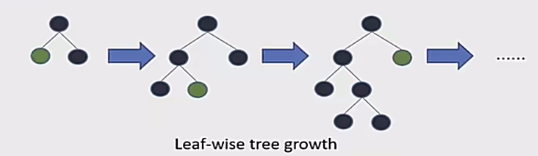
但缺点就是会造成较深的决策树,产生过拟合,所以会加上一个深度限制。
4支持类别特征,很显然因为在直方图中我们可以直接用类别来作为一个组进行统计并且计算增益。
5.高效并行
5.1特征并行
我们可以把特征做一个分割后去分配给每个机器,比如说我把100个特征按10个10个分组打包给10个机器,由每个机器对于每个特征去进行直方图统计,每个特征会产生一个最优的增益分割点,这样的话每个机器会产生一个最优增益特征分割点,然后把每个机器的进行比较,得到最优的特征的直方图分割点,然后按照这个进行划分即可
5.2数据并行
我们可以把数据做一个分割后去分配给每个机器,但是注意每个机器上只是单纯去统计所有特征的直方图,然后会进行所有直方图的绘汇总,得到一个总体的直方图,然后区别进行计算增益。
5.3投票并行
注意投票并行不是单纯的把特征并行和数据并行结合在一起,它是在数据并行的基础上进行的二次投票:比如我们先进行数据划分,分配机器,然后每个机器会在所有特征值的基础上得到前K个使得自己增益最大的划分特征和特征点(这个过程可以采用特征并行去做),这时总体会对这些点进行合并去重,并且重新分配所有这些点给每台机器去计算左右的信息。比如说最后有20个点,比如说第一个点,每台机器会分别计算左右的信息,然后总体会把每台机器的左边加起来,右边加起来,再去计算信息增益。这样就会产生20个增益,然后我们去找一个做大的作为划分节点。这就是投票机制

6.单边梯度采样GOSS
回忆在GBDT算法中,通过负梯度方向进行数据权重的改变,负梯度就数据的权重,在LightGBM算法里,梯度大的样本对于信息增益影响更大,就是通过梯度去进行数据的取舍,但同时要减少梯度小的数据被舍弃带来的影响所以要对小梯度样本加权。

但注意的是如果我们选取的是GBDT算法的增益,确实梯度很有用,但是如果我们选取的是XGboost类似的增益,XGboost并不是用梯度要进行数据权重的修正。其实更重要的是二阶,所以原论文中如果使用的是和XGboost一样的增益,这时候GOSS会对二阶梯度进行一个加权来修正。事实上原论文中有讨论使用一阶梯度的精度。


7.互斥特征捆绑(EFB)
其实这个就是对特征维度进行的处理,因为大数据情况下,数据很多特征是一个洗漱矩阵,因此我们可以把互斥度高的特征捆绑在一起。这样会降低特征维度,但是信息损失很小。其实就类似由于某些减少特征的方法,这个并不是这个算法特有的,我们可以把它作为特征工程的一种方法。

冲突率就是表示的越互斥就是冲突率越小,我们希望把互斥程度高的捆绑,就是把冲突率低的特征捆绑。所以去计算两两之前的冲突率,找一个阈值,做一个冲突图,大于阈值就画一条直接连接的边。
 之后我们使用图着色算法,这个算法要求:每个颜色对应一个捆绑,所以我们希望互斥的捆绑在一起。就是冲突率低的捆绑,就是没有直接连接边的捆绑在一起;并且直接连接(相邻)节点颜色尽量不同。
之后我们使用图着色算法,这个算法要求:每个颜色对应一个捆绑,所以我们希望互斥的捆绑在一起。就是冲突率低的捆绑,就是没有直接连接边的捆绑在一起;并且直接连接(相邻)节点颜色尽量不同。
之后就把捆绑特征作为一个特征使用即可,值就是这个组非零特征的值。
8.算法总体看法:lightgmb算法并不是一个固定的算法,更像是一个框架,因为我们可以使用不同的增益去构造树,对应的损失也不同,你比如说是使用xgboost的一个增益的话,损失就是带有正则化的一般损失;对应不同的树的构建对应不同的损失
