2025年五一杯数学建模竞赛赛题浅析-助攻快速选题
本文为了能够帮助大家快速的上手五一杯数学建模题目,将从涉及背景、解题所需模型、 求解算法、实际求解中可能遇到的问题等详细进行描述,以便大家可以快速完成选题。
初步预估
选题人数 A:B:C=5.0:4.0:3.8
赛题难度 A:B:C=1.0:2.0:3.0
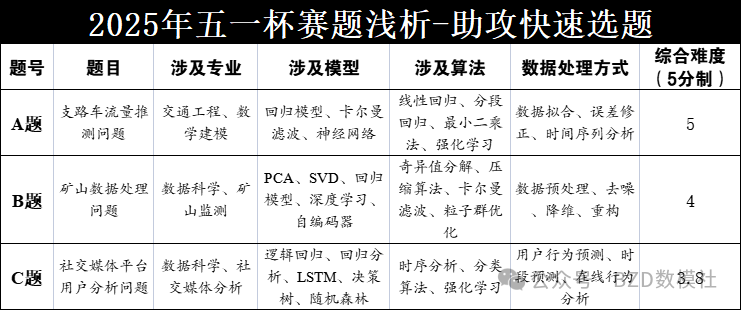
A 题:支路车流量推测问题
问题1:支路1与支路2车流量推测
问题简介: 本问题要求根据主路车流量数据推测各支路(支路1和支路2)的车流量。给 定主路的数据和支路的历史趋势信息,利用合适的数学模型推算出支路的车流量。
求解思路:
分析主路车流量数据与支路车流量的关系,利用主路车流量作为总和信息,通过历史数 据推测各支路车流量的变化趋势。
设定合适的函数模型(如线性、二次或分段函数),利用最小二乘法等拟合方法推算出 各支路的车流量。
可能使用的模型:
●线性回归模型:用于支路车流量变化规律(线性增长、线性减少)的拟合。
●二次回归或分段线性函数:处理支路车流量先增长后减少或其他非线性趋势。
●卡尔曼滤波:用于修正数据中的噪声或误差,提供更平稳的车流量估计。
问题2:主路5的车流量推测
问题简介:本问题要求根据主路车流量数据推测各支路(支路1到支路4)的车流量。特别 是支路2、3、4的车流量具有不同的变化趋势,且需要考虑车流量的时延。
求解思路:
根据主路数据与支路历史车流量数据的关系,采用适当的函数形式推测各支路车流量 的变化。使用数据拟合方法(如多项式回归、分段线性回归)来建模车流量随时间的变化。 可能使用的模型:
●回归模型:使用线性回归、二次回归或分段回归对支路车流量进行拟合。
●时延模型:考虑车流从支路到达主路的延时效应,使用动态系统模型描述。
●时间序列分析:如ARIMA 模型或 LSTM 模型,用于处理车流量随时间的动态变化。
问题3:主路4车流量推测
问题简介: 本问题要求根据主路车流量数据推测支路1、支路2和支路3的车流量。特别 是支路3受到交通信号灯控制,车流量的变化需要考虑绿灯与红灯的周期性变化。
求解思路:
采用分段模型处理支路1和支路2的车流量变化,并通过信号灯控制周期性变化来描述 支路3的车流量。对于支路3,建立基于交通信号灯的周期性函数模型,推测其车流量。
可能使用的模型:
●周期性函数模型:用于建模交通信号灯的影响,如正弦函数或脉冲函数。
●分段回归:用于处理支路车流量的不同阶段(如增长、稳定、减少等)。
●动态系统建模:结合控制理论建模车流量的变化趋势。
问题4:数据误差推测
问题简介: 该问题要求在车流量监测设备产生误差的情况下,根据主路的错误数据推测真 实的支路车流量。
求解思路:
通过误差修正方法,如最小二乘法、卡尔曼滤波或贝叶斯推断,修正车流量数据中的噪 声或设备误差。基于历史数据的趋势和设备的错误模型,推测各支路的真实车流量。
可能使用的模型:
●卡尔曼滤波:用于动态修正噪声和设备误差,得到平稳的车流量估计。
●贝叶斯推断:用于考虑误差的先验分布和后验更新,从而提供更可靠的车流量预测。
●神经网络:可用于通过误差修正网络来推测真实车流量。
问题5:主路监测时刻选择
问题简介:本问题要求根据车流量的变化趋势,确定主路监测设备应记录的关键时刻,以 推测支路车流量的函数表达式。
求解思路:
通过分析车流量的变化规律,选择关键时刻记录数据,以便推算出支路车流量的变化规 律。利用时间序列分析方法,选择监测时刻,减少监测点的数量,但保证精度。
可能使用的模型:
●时序分析模型:如ARIMA 模型、LSTM 神经网络,处理车流量的时间序列数据。
●最优采样算法:根据车流量变化的趋势,选择关键时间点进行数据采样,确保数据精度。
●信息理论模型:通过信息熵、采样定理等方法确定监测时刻。
B 题:矿山数据处理问题
问题1:数据变换与误差分析
问题简介: 本问题要求对矿山监测数据进行变换,目的是使得变换后的数据与原始数据尽 可能接近。同时,需要计算变换后的结果与原始数据之间的误差,并分析误差来源。
求解思路:
对数据进行适当的变换,比如对数变换、标准化或正则化,以减少数据的偏差和噪声。 计算变换后的数据与原始数据之间的误差,使用均方误差(MSE) 或其他误差度量来量化误差。 分析误差的来源,可能的误差来源包括数据噪声、模型偏差或采样误差等。
可能使用的模型:
●数据变换方法:对数变换、 Z-score标准化、最小-最大规范化等。
●误差计算:均方误差(MSE), 绝对误差(Mean Absolute Error,MAE)。
●误差源分析:基于误差度量的回归模型或模型诊断方法,分析误差来源。
问题2:数据压缩与还原
问题简介: 本问题要求通过降维处理对矿山监测数据进行压缩,并对降维后的数据进行还 原,评估压缩效率和还原效果。
求解思路:
采用降维技术(如PCA、SVD 等)将高维数据压缩到低维空间,计算压缩比(即降维后 所需的存储空间与原始数据所需存储空间之比)。在降维的基础上,使用逆变换还原数据, 并计算还原数据与原始数据之间的误差。目标是在压缩效率和数据质量之间找到平衡,保证 压缩比的同时,确保还原数据的准确度满足要求(如MSE不高于0.005)。
可能使用的模型:
●主成分分析 (PCA): 将数据降到低维空间并选择主要成分进行表示。
●奇异值分解 (SVD): 用于数据降维和矩阵的压缩。
●压缩感知:基于信号重建的压缩方法,进一步提升数据压缩效果。
●神经网络(Autoencoder): 利用自编码器对数据进行降维,并进行还原。
问题3:数据去噪与标准化
问题简介:本问题要求对矿山监测数据进行去噪和标准化处理,并建立数学模型描述数据 之间的关系,计算模型的拟合优度,并进行统计检验。
求解思路:
首先使用去噪方法(如小波变换、卡尔曼滤波等)去除数据中的噪声,然后进行数据标 准 化(Z-score 标准化或最小最大规范化)。根据标准化后的数据建立回归模型(如线性回归、 支持向量机回归等)描述数据间的关系。使用拟合优度(如R²值、均方误差等)和统计检 验 ( 如F检验、 t 检验)来评估模型的效果。
可能使用的模型:
●小波变换:用于多尺度去噪。
●卡尔曼滤波:动态去噪和数据平滑。
●回归模型:线性回归、岭回归、 LASSO 回归。
●统计检验: F 检验、t 检验、模型拟合优度R²。
问题4:自适应参数调整
问题简介:本问题要求在矿山监测数据中建立X 与Y 之间的数学模型,并设计自适应调整 算法,优化模型参数以提高拟合优度。
求解思路:
根据数据建立X与 Y之间的回归模型(如线性回归、非线性回归)。设计自适应参数调
整算法(如自适应梯度下降),动态优化模型参数。使用交叉验证和模型评估方法(如均方 误差、平均绝对误差)评估模型的稳定性和适用性。
可能使用的模型:
●线性回归或非线性回归:描述X 与 Y 之间的关系。
● 自适应梯度下降:优化回归模型的参数。
●交叉验证:评估模型的稳定性和泛化能力。
问题5:高维数据降维与重构
问题简介: 本问题要求对矿山监测的高维数据进行降维处理,并建立降维后的数据与原始 数据之间的重构模型,评估模型的效果。
求解思路:
使用PCA 或其他降维方法对高维数据进行降维,减少数据的维度。根据降维后的数据, 建立一个重构模型,将低维数据恢复到原始数据空间。评估重构后的数据与原始数据的相似 度,计算误差,确保数据的主要特征得到保留。
可能使用的模型:
●主成分分析 (PCA): 对数据进行降维处理。
● 自动编码器 (Autoencoder): 使用神经网络模型进行降维和重构。
●奇异值分解(SVD): 用于降维和数据压缩。
C题:社交媒体平台用户分析问题
问题1:预测新增关注数
问题简介:本问题要求根据用户与博主历史的交互数据(观看、点赞、评论、关注)预测 博主在指定日期(2024年7月21日)的新增关注数。
求解思路:
基于历史交互数据,分析用户的行为特征,并建立预测模型。使用回归分析或机器学习 模型(如决策树、随机森林等)来预测新增关注数。
可能使用的模型:
●回归模型:用于预测博主的新增关注数,特别是基于历史关注数据的线性回归。
●随机森林:用于处理多变量之间的非线性关系,预测新增关注数。
●XGBoost: 一种强大的提升方法,适用于特征较多的数据集。
问题2:预测新关注行为
问题简介: 该问题要求结合历史数据预测用户在某一天的新关注行为。
求解思路:
根据用户历史行为,分析其关注行为的模式。使用分类模型(如逻辑回归、决策树)预 测用户是否会在指定日期关注博主。
可能使用的模型:
●逻辑回归:用于二分类问题,预测用户是否新关注某博主。
●支持向量机(SVM): 适用于高维数据和复杂模式的分类任务。
●决策树或随机森林:用于多类分类任务,预测用户的关注行为。
问题3:预测用户是否在线及互动数
问题简介:本问题要求预测用户是否在指定日期在线,并进一步预测用户与博主的互动数。
求解思路:
基于历史数据预测用户的在线行为,并使用多元回归或分类模型预测互动数。
可能使用的模型:
●逻辑回归:预测用户是否在线。
●回归分析模型:预测在线时段的互动数。
● 深度学习:如LSTM 用于处理时序数据,预测用户行为。
问题4:预测用户在线时段与互动数
问题简介: 本问题要求预测用户在指定日期的在线时段,并进一步预测用户与博主的互动 数 。
求解思路:
结合用户的历史行为模式,使用时序分析模型预测用户的在线时段。使用回归模型或神 经网络预测每个时段的互动数。
可能使用的模型:
● LSTM: 长短期记忆网络,适用于时序数据的预测。
● 回归模型:预测每个时段的互动数。
●强化学习:优化推荐时段与互动数量的匹配。