Java内存对象实现聚合查询
文章目录
- 什么是聚合查询
- excel表格演示
- 插入透视表
- 透视表操作
- sql聚合查询
- 创建表和插入数据
- 按照国家业务类型设备类型统计总销量
- 按设备类型统计总销量
- Java内存对象聚合查询
- 普通对象方式
- 创建对象
- 聚合查询条件
- 查询方法
- 调用方式
- 结果
- Record对象方式
- Recor对象
- 创建对象
- 聚合查询条件
- 查询方法
- 调用方法
- 结果
- 完整代码示例
- DynamicAggregationDemo5.java
- SalesStats.java
- QueryReq
- 相关jar包
什么是聚合查询
聚合查询的核心是对数据集进行分组,然后对每个分组应用聚合函数,最终得到汇总结果。
在数据类开发中经常用到。
excel表格演示
举一个最为常见的excel例子
有一份统计报表如下图所示
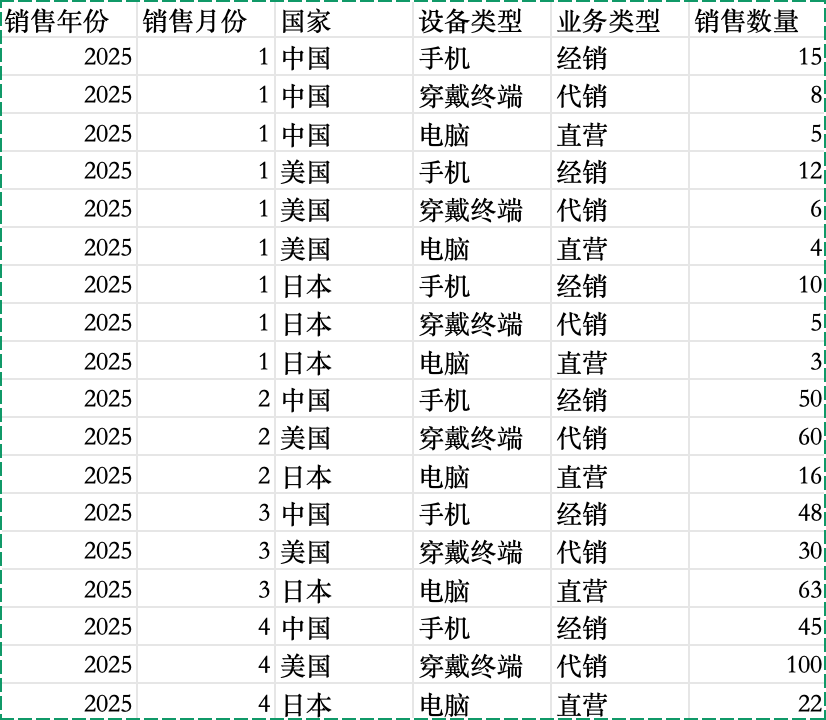
csv文件内容如下
销售年份,销售月份,国家,设备类型,业务类型,销售数量
2025,1,中国,手机,经销,15
2025,1,中国,穿戴终端,代销,8
2025,1,中国,电脑,直营,5
2025,1,美国,手机,经销,12
2025,1,美国,穿戴终端,代销,6
2025,1,美国,电脑,直营,4
2025,1,日本,手机,经销,10
2025,1,日本,穿戴终端,代销,5
2025,1,日本,电脑,直营,3
2025,2,中国,手机,经销,50
2025,2,美国,穿戴终端,代销,60
2025,2,日本,电脑,直营,16
2025,3,中国,手机,经销,48
2025,3,美国,穿戴终端,代销,30
2025,3,日本,电脑,直营,63
2025,4,中国,手机,经销,45
2025,4,美国,穿戴终端,代销,100
2025,4,日本,电脑,直营,22插入透视表
插入透视表,不显示分类汇总,以表格形式展示
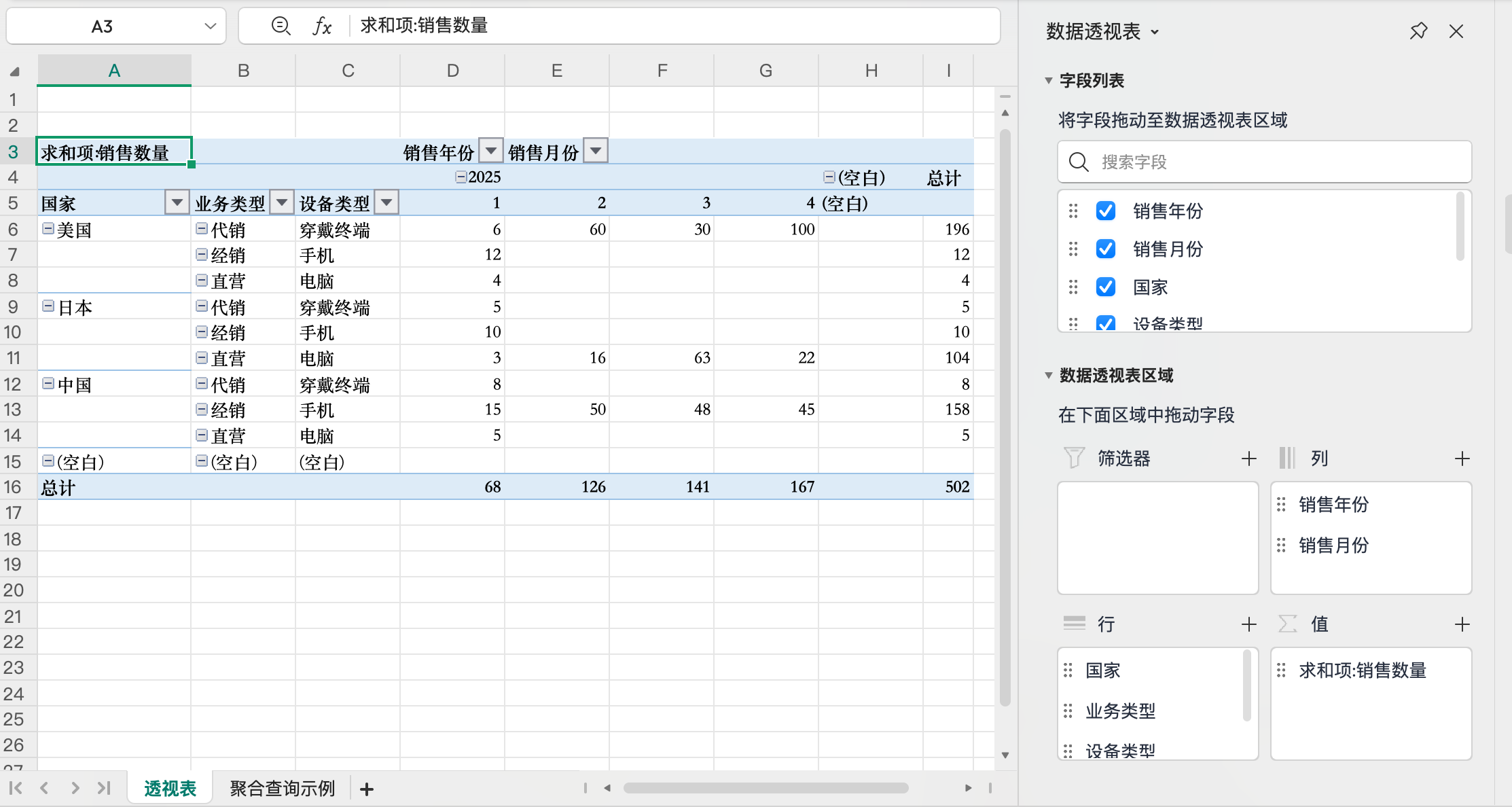
就能很清晰的看到每个分组的销量。
透视表操作
顺序和分组聚合可以任意调整。
比如交换分组顺序
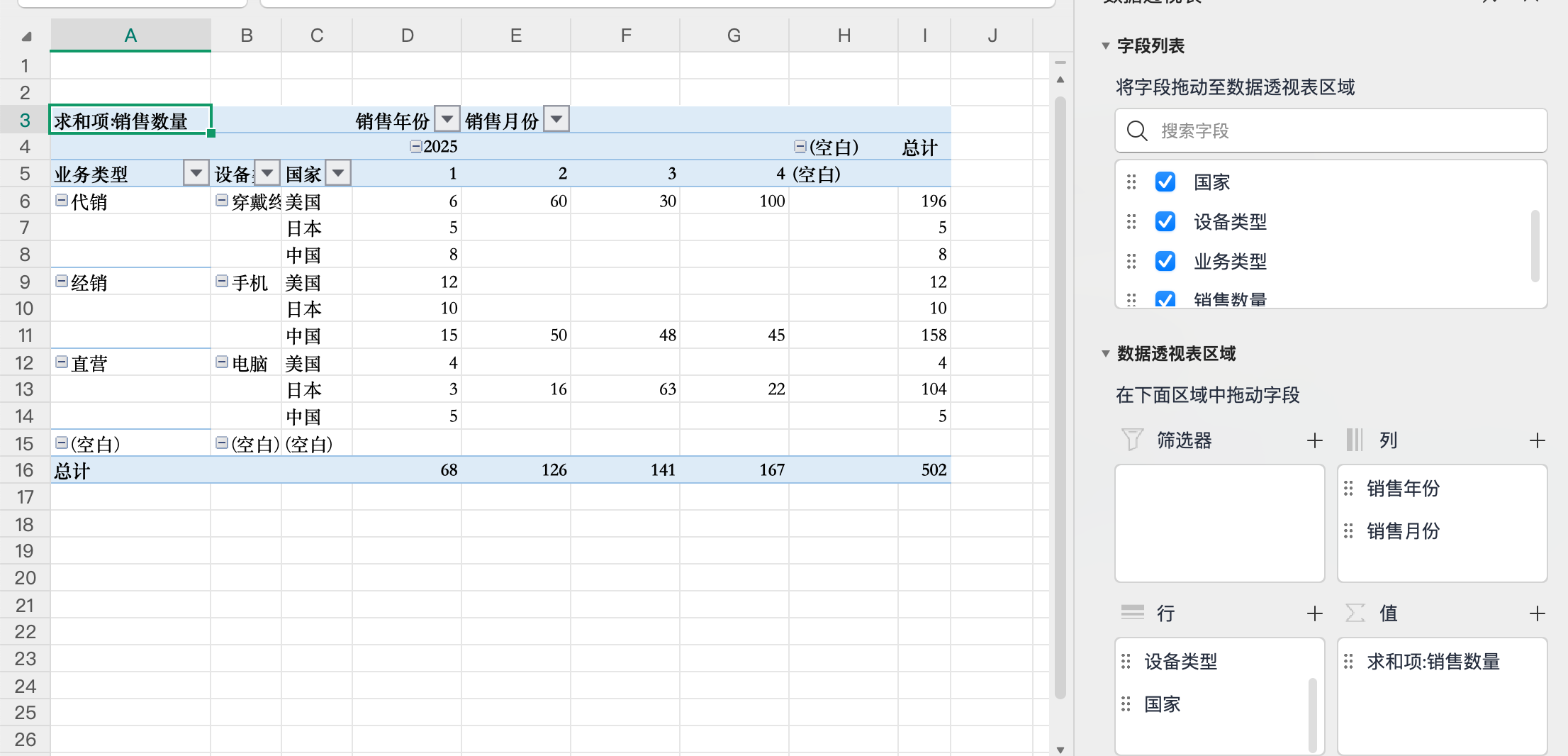
比如只用设备类型分组。
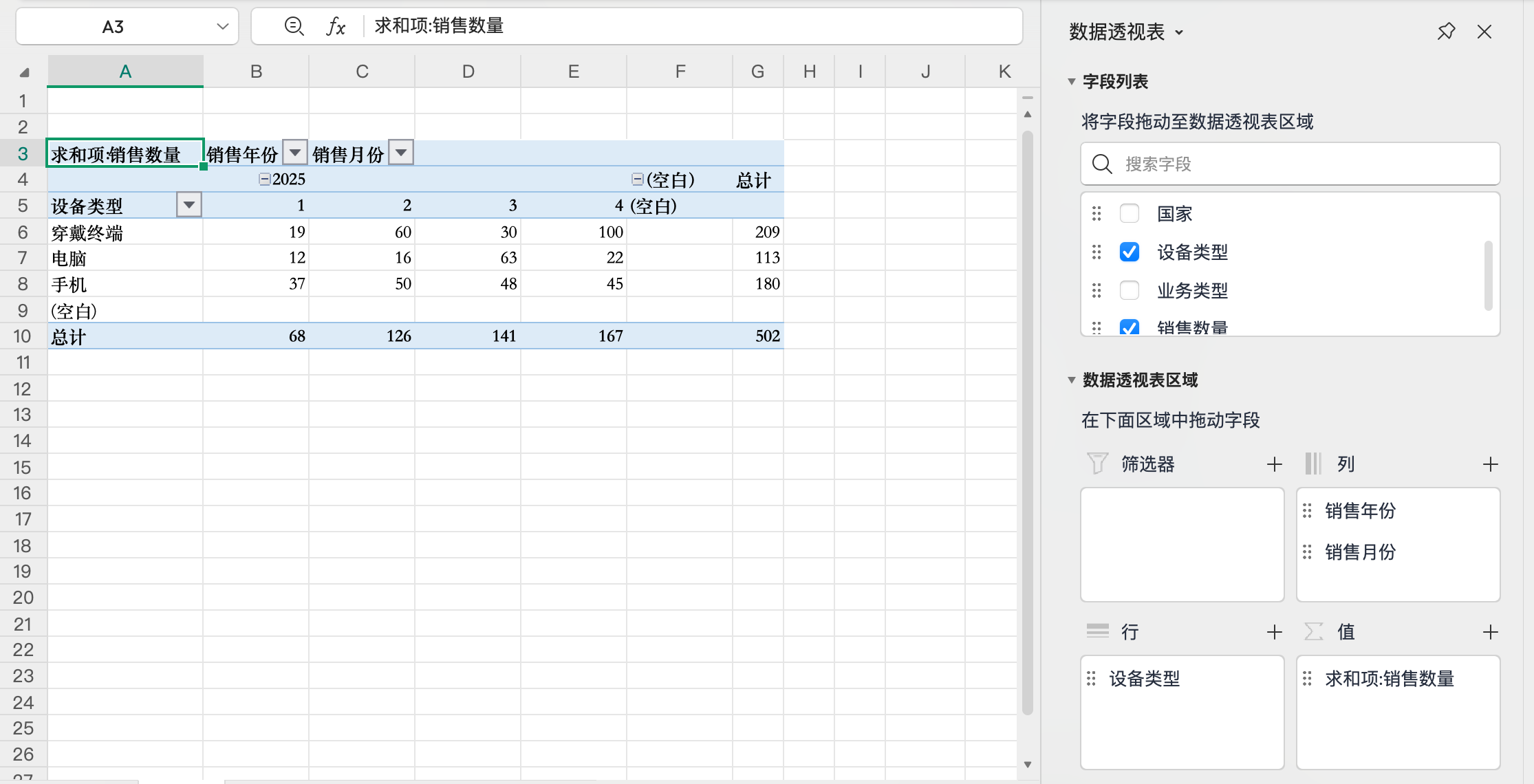
sql聚合查询
创建表和插入数据
-- 创建销售统计表
CREATE TABLE salesStats ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键ID', defaultYear INT NOT NULL COMMENT '销售年份', defaultMon INT NOT NULL COMMENT '销售月份', country VARCHAR(50) NOT NULL COMMENT '国家', deviceFamilyName VARCHAR(50) NOT NULL COMMENT '设备类型', erpBusinessType VARCHAR(50) NOT NULL COMMENT '业务类型', amount INT NOT NULL COMMENT '销售数量', INDEX idx_year_month (defaultYear, defaultMon) COMMENT '年份月份联合索引', INDEX idx_country (country) COMMENT '国家索引', INDEX idx_device (deviceFamilyName) COMMENT '设备类型索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='销售统计表'; -- 插入销售统计数据
INSERT INTO salesStats (defaultYear, defaultMon, country, deviceFamilyName, erpBusinessType, amount) VALUES (2025, 1, '中国', '手机', '经销', 15),
(2025, 1, '中国', '穿戴终端', '代销', 8),
(2025, 1, '中国', '电脑', '直营', 5),
(2025, 1, '美国', '手机', '经销', 12),
(2025, 1, '美国', '穿戴终端', '代销', 6),
(2025, 1, '美国', '电脑', '直营', 4),
(2025, 1, '日本', '手机', '经销', 10),
(2025, 1, '日本', '穿戴终端', '代销', 5),
(2025, 1, '日本', '电脑', '直营', 3), (2025, 2, '中国', '手机', '经销', 50),
(2025, 2, '美国', '穿戴终端', '代销', 60),
(2025, 2, '日本', '电脑', '直营', 16), (2025, 3, '中国', '手机', '经销', 48),
(2025, 3, '美国', '穿戴终端', '代销', 30),
(2025, 3, '日本', '电脑', '直营', 63), (2025, 4, '中国', '手机', '经销', 45),
(2025, 4, '美国', '穿戴终端', '代销', 100),
(2025, 4, '日本', '电脑', '直营', 22);
上面的两个查询就可以表示为
按照国家业务类型设备类型统计总销量
-- 按照国家业务类型设备类型统计总销量
SELECT country as '国家', deviceFamilyName AS '设备类型', erpBusinessType as '业务类型', SUM(amount) AS '销量'
FROM salesStats
WHERE 1 = 1
GROUP BY country,erpBusinessType,deviceFamilyName
ORDER BY country,erpBusinessType,deviceFamilyName;# 中国,电脑,直营,5
# 中国,手机,经销,158
# 日本,穿戴终端,代销,5
# 日本,电脑,直营,104
# 日本,手机,经销,10
# 美国,穿戴终端,代销,196
# 美国,电脑,直营,4
# 美国,手机,经销,12
按设备类型统计总销量
-- 2. 按设备类型统计总销量
SELECT deviceFamilyName AS '设备类型', SUM(amount) AS '总销量'
FROM salesStats
GROUP BY deviceFamilyName
ORDER BY SUM(amount) DESC; # 穿戴终端,209
# 手机,180
# 电脑,113但是sql实现方法存在一定局限性。
如果数据对象还需要经过清洗和其他关系映射等复杂的业务逻辑sql就很难用。
如果需要对一批数据频繁查询就会造成数据库的压力,而且不能保留聚合的过程数据。
好在使用java内存对象聚合查询就可以覆盖上述场景。
Java内存对象聚合查询
普通对象方式
创建对象
package org.example.aggquery; import lombok.Data; @Data
public class SalesStats { /** 设备类型 */ private String deviceFamilyName; /** 国家 */ private String country; /** 数量 */ private Integer amount; /** 销售日期年 */ private Integer defaultYear; /** 销售日期月 */ private Integer defaultMon; /** 业务类型 */ private String erpBusinessType; // 构造方法 public SalesStats(int defaultYear,int defaultMon, String country, String deviceFamilyName, String erpBusinessType, int amount) { this.defaultYear = defaultYear; this.defaultMon = defaultMon; this.country = country; this.deviceFamilyName = deviceFamilyName; this.erpBusinessType = erpBusinessType; this.amount = amount; } }
聚合查询条件
@Data
public class QueryReq { List<String> groupByDim ;
}
查询方法
public List<Map<String, Object>> aggQueryByObj(QueryReq req) { List<SalesStats> dataList = mockObjData(); if (req.getGroupByDim() == null || req.getGroupByDim().size() == 0) { // 无聚合条件,只按年月聚合 Map<String, Double> result = dataList.stream() .collect(Collectors.groupingBy( it -> it.getDefaultYear() * 100 + it.getDefaultMon() + "", Collectors.summingDouble(SalesStats::getAmount) )); return Collections.singletonList(new DynamicAggregationDemo5.AggregationResult(result).toMap()); } // 定义分组条件 List<Collector<SalesStats, ?, ?>> collectors = new ArrayList<>(); for (String dim : req.getGroupByDim()) { if (dim.equals("country")) { collectors.add(Collectors.groupingBy(SalesStats::getCountry)); } if (dim.equals("deviceFamilyName")) { collectors.add(Collectors.groupingBy(SalesStats::getDeviceFamilyName)); } // 修改点4 if (dim.equals("erpBusinessType")) { collectors.add(Collectors.groupingBy(SalesStats::getDeviceFamilyName)); } } // 动态构建分组 Collector<SalesStats, ?, Map<String, Map<String, Double>>> groupedCollector = Collectors.groupingBy( data -> { List<String> keys = new ArrayList<>(); if (req.getGroupByDim().contains("country")) { keys.add(data.getCountry()); } if (req.getGroupByDim().contains("deviceFamilyName")) { keys.add(data.getDeviceFamilyName()); } // 修改点5 if (req.getGroupByDim().contains("erpBusinessType")) { keys.add(data.getErpBusinessType()); } return String.join("|", keys); }, Collectors.groupingBy( it -> it.getDefaultYear() * 100 + it.getDefaultMon() + "", Collectors.summingDouble(SalesStats::getAmount) ) ); // 执行分组 Map<String, Map<String, Double>> groupedData = dataList.stream() .collect(groupedCollector); // 转换为结果格式 return groupedData.entrySet().stream() .map(entry -> { String[] keys = entry.getKey().split("\\|"); DynamicAggregationDemo5.AggregationResult result = new DynamicAggregationDemo5.AggregationResult(entry.getValue()); int keyIndex = 0; if (req.getGroupByDim().contains("country")) { result.setCountry(keys[keyIndex++]); } if (req.getGroupByDim().contains("deviceFamilyName")) { result.setDeviceFamilyName(keys[keyIndex++]); } // 修改点6 if (req.getGroupByDim().contains("erpBusinessType")) { result.setErpBusinessType(keys[keyIndex++]); } return result.toMap(); }) .collect(Collectors.toList()); }// 聚合结果类
static class AggregationResult { private Map<String, Double> monthlyAmounts; private String country; private String deviceFamilyName; // 修改点1 private String erpBusinessType; public AggregationResult(Map<String, Double> monthlyAmounts) { this.monthlyAmounts = monthlyAmounts; } public void setCountry(String country) { this.country = country; } public void setDeviceFamilyName(String deviceFamilyName) { this.deviceFamilyName = deviceFamilyName; } // 修改点2 public void setErpBusinessType(String erpBusinessType) { this.erpBusinessType = erpBusinessType; } public Map<String, Object> toMap() { Map<String, Object> result = new LinkedHashMap<>(); result.putAll(monthlyAmounts); if (country != null) { result.put("country", country); } if (deviceFamilyName != null) { result.put("deviceFamilyName", deviceFamilyName); } // 修改点3 if (erpBusinessType != null) { result.put("erpBusinessType", erpBusinessType); } return result; }
}private static String assemblyObjResp(List<Map<String, Object>> resultDetail) { // 模拟jrpc 返回结果 Map<String, Object> result = new HashMap<>(); result.put("jsonrpc", 2.0); result.put("id", "5691388858018585"); Map<String, Object> resultData = new HashMap<>(); resultData.put("total", resultDetail.size()); resultData.put("data", resultDetail); result.put("result", resultData); String jsonString = JSONObject.toJSONString(result); return jsonString;
}调用方式
public static void main(String[] args) { DynamicAggregationDemo5 dynamicAggregationDemo5 = new DynamicAggregationDemo5(); QueryReq req = new QueryReq(); // 修改这里的顺序和元素就可以动态聚合查询req.setGroupByDim(Arrays.asList("erpBusinessType", "country", "deviceFamilyName")); // 对象方式 List<Map<String, Object>> resultDetailByObj = dynamicAggregationDemo5.aggQueryByObj(req); String jsonObj = assemblyObjResp(resultDetailByObj); System.out.println(jsonObj);
}
结果
json格式化后
{ "result": { "total": 9, "data": [ { "202501": 12, "country": "美国", "deviceFamilyName": "手机", "erpBusinessType": "经销" }, { "202501": 3, "202502": 16, "202503": 63, "202504": 22, "country": "日本", "deviceFamilyName": "电脑", "erpBusinessType": "直营" }, { "202501": 6, "202502": 60, "202503": 30, "202504": 100, "country": "美国", "deviceFamilyName": "穿戴终端", "erpBusinessType": "代销" }, { "202501": 5, "country": "日本", "deviceFamilyName": "穿戴终端", "erpBusinessType": "代销" }, { "202501": 10, "country": "日本", "deviceFamilyName": "手机", "erpBusinessType": "经销" }, { "202501": 5, "country": "中国", "deviceFamilyName": "电脑", "erpBusinessType": "直营" }, { "202501": 15, "202502": 50, "202503": 48, "202504": 45, "country": "中国", "deviceFamilyName": "手机", "erpBusinessType": "经销" }, { "202501": 4, "country": "美国", "deviceFamilyName": "电脑", "erpBusinessType": "直营" }, { "202501": 8, "country": "中国", "deviceFamilyName": "穿戴终端", "erpBusinessType": "代销" } ] }, "id": "5691388858018585", "jsonrpc": 2
}
Record对象方式
普通对象方式还是存在以下问题
1.需要六个改动点才能新增出一个聚合属性
2.每次都需要新增一个统计对象类,如果项目这类查询对象很多会造成太多类需要维护。
那么有没有更灵活一点的方法呢?
有的兄弟,有的。
Recor对象
对象源码如下所示
public class Record implements Map<String, Object>, Serializable, Cloneable, Comparable<Record> { private static final long serialVersionUID = -7753504263747912181L; protected static Callable<Record> factory; // 属性所在位置private Map<String, Object> map = new LinkedHashMap(); private List<String> keys = new ArrayList();// ...略
}
我之前有写过一篇 [[一文告诉你如何做数据库技术选型#一、对象的本质 —— 内存中]]有这类对象的介绍。
这里再简单重复一下。
所有java对象其实都可以看做一个固定key值的Map,
public class Order {private int orderId;private String orderName;
}
Order order = new Order();
order.setOrdreId(1);
order.setOrderName("订单A");
如果key值也不固定,key的数量也不固定他会变成,一个纯粹的Map键值对。
Map<String, Object> orde = new HashMap<>();
order.put("orderId", 1);
order.put("orderName", "订单A");
这就是Record对象原理,使用这个对象需要再pom文件引入如下依赖
<dependency> <groupId>org.nutz</groupId> <artifactId>nutz</artifactId> <version>1.r.70-SNAPSHOT</version>
</dependency>
创建对象
直接new Record();
聚合查询条件
@Data
public class QueryReq { List<String> groupByDim ;
}
查询方法
public List<Record> aggQueryByRecord(QueryReq req) { List<Record> records = mockRecordData(); List<String> groupByDim = req.getGroupByDim(); Map<String, List<Record>> collect = new LinkedHashMap<>(); collect = records.stream().collect(Collectors.groupingBy(e -> { String key = ""; for (String dim : groupByDim) { key = key + "&" + e.getString(dim); } return key; } )); // 多线程处理分组后的数据 List<Future<List<Record>>> future = new ArrayList<>(); // 多线程处理分组后的数据 for (String dim : collect.keySet()) { List<Record> recordsByDim = collect.get(dim); future.add(threadPoolExecutor.submit(() -> { List<Record> oneCake = dealProcess(req, recordsByDim, dim); return oneCake; })); } List<Record> result = new ArrayList<>(); // 获取结果 for (Future<List<Record>> listFuture : future) { try { result.addAll(listFuture.get()); } catch (Exception e) { throw new RuntimeException("计算异常,原因:" + e.getMessage()); } } return result;
}private List<Record> dealProcess(QueryReq req, List<Record> recordsByDim, String dim) { List<Record> resultAll = new ArrayList<>(); Map<String, Double> collect = recordsByDim.stream().collect( Collectors.groupingBy( record -> record.getInt("defaultyear") * 100 + record.getInt("defaultmon") + "", // 分组键 LinkedHashMap::new, // 使用LinkedHashMap保持顺序 Collectors.summingDouble(record -> record.getDouble("amount")) // 求和操作 ) ); Set<String> keys = collect.keySet(); Record item = new Record(); for (String key : keys) { // records 按月聚合 item.put(key, collect.getOrDefault(key, 0.0)); // 补充分组数据用于前端聚合 List<String> groupByDim = req.getGroupByDim(); String[] split = dim.split("&"); // 补充分组数据用于前端聚合 for (int i = 0; i < groupByDim.size(); i++) { item.put(groupByDim.get(i), split[i + 1]); } } resultAll.add(item); return resultAll;
}private static String assemblyRecordResp(List<Record> resultDetail) { // 模拟jrpc 返回结果 Map<String, Object> result = new HashMap<>(); result.put("jsonrpc", 2.0); result.put("id", "5691388858018585"); Map<String, Object> resultData = new HashMap<>(); resultData.put("total", resultDetail.size()); resultData.put("data", resultDetail); result.put("result", resultData); String jsonString = JSONObject.toJSONString(result); return jsonString;
}
调用方法
public static void main(String[] args) { DynamicAggregationDemo5 dynamicAggregationDemo5 = new DynamicAggregationDemo5(); QueryReq req = new QueryReq(); // 修改这里的顺序和元素就可以动态聚合查询 req.setGroupByDim(Arrays.asList("erpBusinessType", "country", "deviceFamilyName")); // Record方式 List<Record> resultDetailByRecord = dynamicAggregationDemo5.aggQueryByRecord(req); String jsonRecord = assemblyRecordResp(resultDetailByRecord); System.out.println(jsonRecord);
}
结果
{ "result": { "total": 9, "data": [ { "202501": 5, "erpbusinesstype": "代销", "country": "日本", "devicefamilyname": "穿戴终端" }, { "202501": 8, "erpbusinesstype": "代销", "country": "中国", "devicefamilyname": "穿戴终端" }, { "202501": 4, "erpbusinesstype": "直营", "country": "美国", "devicefamilyname": "电脑" }, { "202501": 6, "202502": 60, "202503": 30, "202504": 100, "erpbusinesstype": "代销", "country": "美国", "devicefamilyname": "穿戴终端" }, { "202501": 3, "202502": 16, "202503": 63, "202504": 22, "erpbusinesstype": "直营", "country": "日本", "devicefamilyname": "电脑" }, { "202501": 10, "erpbusinesstype": "经销", "country": "日本", "devicefamilyname": "手机" }, { "202501": 15, "202502": 50, "202503": 48, "202504": 45, "erpbusinesstype": "经销", "country": "中国", "devicefamilyname": "手机" }, { "202501": 5, "erpbusinesstype": "直营", "country": "中国", "devicefamilyname": "电脑" }, { "202501": 12, "erpbusinesstype": "经销", "country": "美国", "devicefamilyname": "手机" } ] }, "id": "5691388858018585", "jsonrpc": 2
}
完整代码示例
DynamicAggregationDemo5.java
package org.example.aggquery; import com.alibaba.fastjson.JSONObject;
import org.nutz.dao.entity.Record; import java.util.*;
import java.util.concurrent.Future;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collector;
import java.util.stream.Collectors; /** * 聚合查询 */
public class DynamicAggregationDemo5 { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(4, 10, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(50), new ThreadPoolExecutor.CallerRunsPolicy()); public List<Map<String, Object>> aggQueryByObj(QueryReq req) { List<SalesStats> dataList = mockObjData(); if (req.getGroupByDim() == null || req.getGroupByDim().size() == 0) { // 无聚合条件,只按年月聚合 Map<String, Double> result = dataList.stream() .collect(Collectors.groupingBy( it -> it.getDefaultYear() * 100 + it.getDefaultMon() + "", Collectors.summingDouble(SalesStats::getAmount) )); return Collections.singletonList(new DynamicAggregationDemo5.AggregationResult(result).toMap()); } // 定义分组条件 List<Collector<SalesStats, ?, ?>> collectors = new ArrayList<>(); for (String dim : req.getGroupByDim()) { if (dim.equals("country")) { collectors.add(Collectors.groupingBy(SalesStats::getCountry)); } if (dim.equals("deviceFamilyName")) { collectors.add(Collectors.groupingBy(SalesStats::getDeviceFamilyName)); } // 修改点4 if (dim.equals("erpBusinessType")) { collectors.add(Collectors.groupingBy(SalesStats::getDeviceFamilyName)); } } // 动态构建分组 Collector<SalesStats, ?, Map<String, Map<String, Double>>> groupedCollector = Collectors.groupingBy( data -> { List<String> keys = new ArrayList<>(); if (req.getGroupByDim().contains("country")) { keys.add(data.getCountry()); } if (req.getGroupByDim().contains("deviceFamilyName")) { keys.add(data.getDeviceFamilyName()); } // 修改点5 if (req.getGroupByDim().contains("erpBusinessType")) { keys.add(data.getErpBusinessType()); } return String.join("|", keys); }, Collectors.groupingBy( it -> it.getDefaultYear() * 100 + it.getDefaultMon() + "", Collectors.summingDouble(SalesStats::getAmount) ) ); // 执行分组 Map<String, Map<String, Double>> groupedData = dataList.stream() .collect(groupedCollector); // 转换为结果格式 return groupedData.entrySet().stream() .map(entry -> { String[] keys = entry.getKey().split("\\|"); DynamicAggregationDemo5.AggregationResult result = new DynamicAggregationDemo5.AggregationResult(entry.getValue()); int keyIndex = 0; if (req.getGroupByDim().contains("country")) { result.setCountry(keys[keyIndex++]); } if (req.getGroupByDim().contains("deviceFamilyName")) { result.setDeviceFamilyName(keys[keyIndex++]); } // 修改点6 if (req.getGroupByDim().contains("erpBusinessType")) { result.setErpBusinessType(keys[keyIndex++]); } return result.toMap(); }) .collect(Collectors.toList()); } public List<Record> aggQueryByRecord(QueryReq req) { List<Record> records = mockRecordData(); List<String> groupByDim = req.getGroupByDim(); Map<String, List<Record>> collect = new LinkedHashMap<>(); collect = records.stream().collect(Collectors.groupingBy(e -> { String key = ""; for (String dim : groupByDim) { key = key + "&" + e.getString(dim); } return key; } )); // 多线程处理分组后的数据 List<Future<List<Record>>> future = new ArrayList<>(); // 多线程处理分组后的数据 for (String dim : collect.keySet()) { List<Record> recordsByDim = collect.get(dim); future.add(threadPoolExecutor.submit(() -> { List<Record> oneCake = dealProcess(req, recordsByDim, dim); return oneCake; })); } List<Record> result = new ArrayList<>(); // 获取结果 for (Future<List<Record>> listFuture : future) { try { result.addAll(listFuture.get()); } catch (Exception e) { throw new RuntimeException("计算异常,原因:" + e.getMessage()); } } return result; } public static void main(String[] args) { DynamicAggregationDemo5 dynamicAggregationDemo5 = new DynamicAggregationDemo5(); QueryReq req = new QueryReq(); req.setGroupByDim(Arrays.asList("erpBusinessType", "country", "deviceFamilyName")); // 对象方式 List<Map<String, Object>> resultDetailByObj = dynamicAggregationDemo5.aggQueryByObj(req); String jsonObj = assemblyObjResp(resultDetailByObj); System.out.println(jsonObj); // Record方式 List<Record> resultDetailByRecord = dynamicAggregationDemo5.aggQueryByRecord(req); String jsonRecord = assemblyRecordResp(resultDetailByRecord); System.out.println(jsonRecord); } private static String assemblyRecordResp(List<Record> resultDetail) { // 模拟jrpc 返回结果 Map<String, Object> result = new HashMap<>(); result.put("jsonrpc", 2.0); result.put("id", "5691388858018585"); Map<String, Object> resultData = new HashMap<>(); resultData.put("total", resultDetail.size()); resultData.put("data", resultDetail); result.put("result", resultData); String jsonString = JSONObject.toJSONString(result); return jsonString; } private static String assemblyObjResp(List<Map<String, Object>> resultDetail) { // 模拟jrpc 返回结果 Map<String, Object> result = new HashMap<>(); result.put("jsonrpc", 2.0); result.put("id", "5691388858018585"); Map<String, Object> resultData = new HashMap<>(); resultData.put("total", resultDetail.size()); resultData.put("data", resultDetail); result.put("result", resultData); String jsonString = JSONObject.toJSONString(result); return jsonString; } private List<Record> dealProcess(QueryReq req, List<Record> recordsByDim, String dim) { List<Record> resultAll = new ArrayList<>(); Map<String, Double> collect = recordsByDim.stream().collect( Collectors.groupingBy( record -> record.getInt("defaultyear") * 100 + record.getInt("defaultmon") + "", // 分组键 LinkedHashMap::new, // 使用LinkedHashMap保持顺序 Collectors.summingDouble(record -> record.getDouble("amount")) // 求和操作 ) ); Set<String> keys = collect.keySet(); Record item = new Record(); for (String key : keys) { // records 按月聚合 item.put(key, collect.getOrDefault(key, 0.0)); // 补充分组数据用于前端聚合 List<String> groupByDim = req.getGroupByDim(); String[] split = dim.split("&"); // 补充分组数据用于前端聚合 for (int i = 0; i < groupByDim.size(); i++) { item.put(groupByDim.get(i), split[i + 1]); } } resultAll.add(item); return resultAll; } public static List<SalesStats> mockObjData() { return generateSalesStats(); } public static List<Record> mockRecordData() { return generateSalesStatsRecord(); } public static List<SalesStats> generateSalesStats() { List<SalesStats> statsList = new ArrayList<>(); // 中国数据 statsList.add(new SalesStats(2025, 1, "中国", "手机", "经销", 15)); statsList.add(new SalesStats(2025, 1, "中国", "穿戴终端", "代销", 8)); statsList.add(new SalesStats(2025, 1, "中国", "电脑", "直营", 5)); // 美国数据 statsList.add(new SalesStats(2025, 1, "美国", "手机", "经销", 12)); statsList.add(new SalesStats(2025, 1, "美国", "穿戴终端", "代销", 6)); statsList.add(new SalesStats(2025, 1, "美国", "电脑", "直营", 4)); // 日本数据 statsList.add(new SalesStats(2025, 1, "日本", "手机", "经销", 10)); statsList.add(new SalesStats(2025, 1, "日本", "穿戴终端", "代销", 5)); statsList.add(new SalesStats(2025, 1, "日本", "电脑", "直营", 3)); statsList.add(new SalesStats(2025, 2, "中国", "手机", "经销", 50)); statsList.add(new SalesStats(2025, 2, "美国", "穿戴终端", "代销", 60)); statsList.add(new SalesStats(2025, 2, "日本", "电脑", "直营", 16)); statsList.add(new SalesStats(2025, 3, "中国", "手机", "经销", 48)); statsList.add(new SalesStats(2025, 3, "美国", "穿戴终端", "代销", 30)); statsList.add(new SalesStats(2025, 3, "日本", "电脑", "直营", 63)); statsList.add(new SalesStats(2025, 4, "中国", "手机", "经销", 45)); statsList.add(new SalesStats(2025, 4, "美国", "穿戴终端", "代销", 100)); statsList.add(new SalesStats(2025, 4, "日本", "电脑", "直营", 22)); return statsList; } public static List<Record> generateSalesStatsRecord() { List<Record> statsList = new ArrayList<>(); statsList.add(newRecord(2025, 1, "中国", "手机", "经销", 15)); statsList.add(newRecord(2025, 1, "中国", "穿戴终端", "代销", 8)); statsList.add(newRecord(2025, 1, "中国", "电脑", "直营", 5)); statsList.add(newRecord(2025, 1, "美国", "手机", "经销", 12)); statsList.add(newRecord(2025, 1, "美国", "穿戴终端", "代销", 6)); statsList.add(newRecord(2025, 1, "美国", "电脑", "直营", 4)); statsList.add(newRecord(2025, 1, "日本", "手机", "经销", 10)); statsList.add(newRecord(2025, 1, "日本", "穿戴终端", "代销", 5)); statsList.add(newRecord(2025, 1, "日本", "电脑", "直营", 3)); statsList.add(newRecord(2025, 2, "中国", "手机", "经销", 50)); statsList.add(newRecord(2025, 2, "美国", "穿戴终端", "代销", 60)); statsList.add(newRecord(2025, 2, "日本", "电脑", "直营", 16)); statsList.add(newRecord(2025, 3, "中国", "手机", "经销", 48)); statsList.add(newRecord(2025, 3, "美国", "穿戴终端", "代销", 30)); statsList.add(newRecord(2025, 3, "日本", "电脑", "直营", 63)); statsList.add(newRecord(2025, 4, "中国", "手机", "经销", 45)); statsList.add(newRecord(2025, 4, "美国", "穿戴终端", "代销", 100)); statsList.add(newRecord(2025, 4, "日本", "电脑", "直营", 22)); return statsList; } private static Record newRecord(int defaultYear, int defaultMon, String country, String deviceFamilyName, String erpBusinessType, int amount) { Record record = new Record(); record.put("defaultyear", defaultYear); record.put("defaultmon", defaultMon); record.put("amount", amount); record.put("country", country); record.put("deviceFamilyName", deviceFamilyName); record.put("erpBusinessType", erpBusinessType); return record; } // 聚合结果类 static class AggregationResult { private Map<String, Double> monthlyAmounts; private String country; private String deviceFamilyName; // 修改点1 private String erpBusinessType; public AggregationResult(Map<String, Double> monthlyAmounts) { this.monthlyAmounts = monthlyAmounts; } public void setCountry(String country) { this.country = country; } public void setDeviceFamilyName(String deviceFamilyName) { this.deviceFamilyName = deviceFamilyName; } // 修改点2 public void setErpBusinessType(String erpBusinessType) { this.erpBusinessType = erpBusinessType; } public Map<String, Object> toMap() { Map<String, Object> result = new LinkedHashMap<>(); result.putAll(monthlyAmounts); if (country != null) { result.put("country", country); } if (deviceFamilyName != null) { result.put("deviceFamilyName", deviceFamilyName); } // 修改点3 if (erpBusinessType != null) { result.put("erpBusinessType", erpBusinessType); } return result; } } }
SalesStats.java
package org.example.aggquery; import lombok.Data; @Data
public class SalesStats { /** 设备类型 */ private String deviceFamilyName; /** 国家 */ private String country; /** 数量 */ private Integer amount; /** 销售日期年 */ private Integer defaultYear; /** 销售日期月 */ private Integer defaultMon; /** 业务类型 */ private String erpBusinessType; // 构造方法 public SalesStats(int defaultYear,int defaultMon, String country, String deviceFamilyName, String erpBusinessType, int amount) { this.defaultYear = defaultYear; this.defaultMon = defaultMon; this.country = country; this.deviceFamilyName = deviceFamilyName; this.erpBusinessType = erpBusinessType; this.amount = amount; } }
QueryReq
package org.example.aggquery; import lombok.Data; import java.util.List; @Data
public class QueryReq { List<String> groupByDim ;
}
相关jar包
<dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.62</version>
</dependency>
<!-- Record对象需引入 -->
<dependency> <groupId>org.nutz</groupId> <artifactId>nutz</artifactId> <version>1.r.70-SNAPSHOT</version>
</dependency>