EchoMimic 阿里开源数字人项目的复现过程
EchoMimic 是一个由阿里巴巴蚂蚁集团开发的开源AI 数字人项目,通过可编辑地标调节实现逼真的音频驱动肖像动画,它能够将静态图像转化为具有动态语音和表情的数字人像。
今天咱们来复现下,看看有哪些坑,再看看数字人效果如何。
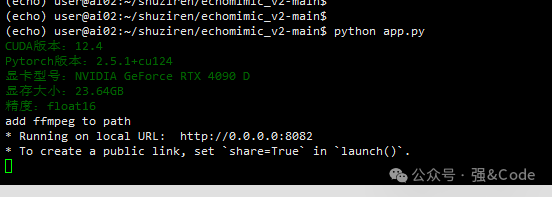
先来看下本地环境,跑起来项目后会有如下输出。
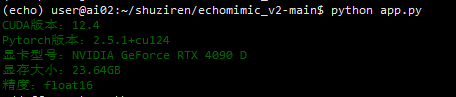
1、clone代码
git clone https://github.com/antgroup/echomimic_v2cd echomimic_v2
2、conda创建环境。首先要安装conda,后台回复"conda"可获取Ubuntu安装包,直接安装即可。
conda create -n echomimic python=3.10conda activate echomimic
3、开始安装环境,根据自己实际的cuda版本安装,附pytorch地址:https://pytorch.ac.cn/get-started/previous-versions/。我的cuda版本是12.4
pip install pip -Upip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 xformers==0.0.28.post3 --index-url https://download.pytorch.org/whl/cu124pip install torchao --index-url https://download.pytorch.org/whl/nightly/cu124pip install -r requirements.txtpip install --no-deps facenet_pytorch==2.6.0
整个过程在安装requirements.txt时出点问题,因为当时安装不上clip了,我就先把这句注释了,手动下载,传导服务器上面安装了下。

安装整个过程还比较顺利。
4、下载ffmpeg-static
export FFMPEG_PATH=/path/to/ffmpeg-4.4-amd64-static5、整个安装过程结束了就,我就试着运行了下
python app.py毫无意外报错了,如图:
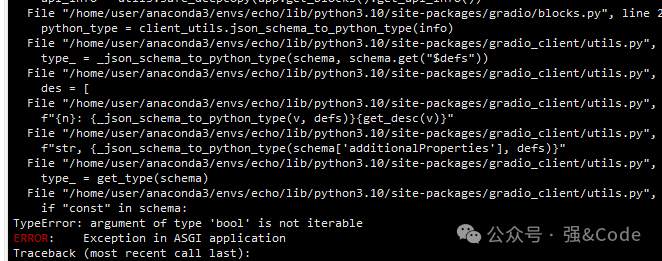
这是gradio版本太低了,需要升级下
pip install --upgrade gradio6、升级好后接着再跑下试试
打开如图:
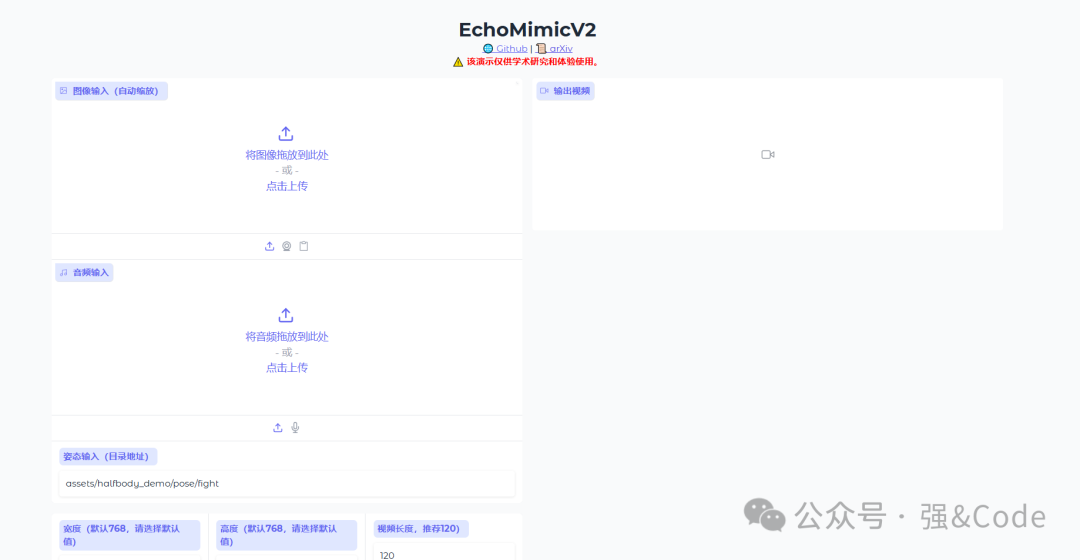
用自带的形象试试。点击生成视频报错了。

没有模型文件,哦忘记下载模型文件了。下载模型文件,按照下图目录放进去。
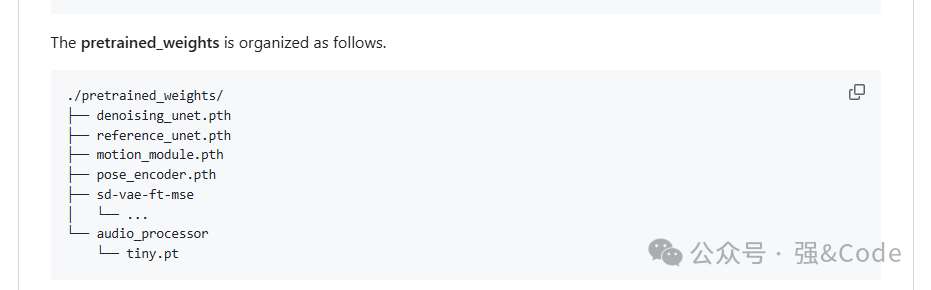
然后再启动试下。
7、点击生成视频,等待了七分钟左右终于成功了。显存使用情况如下:
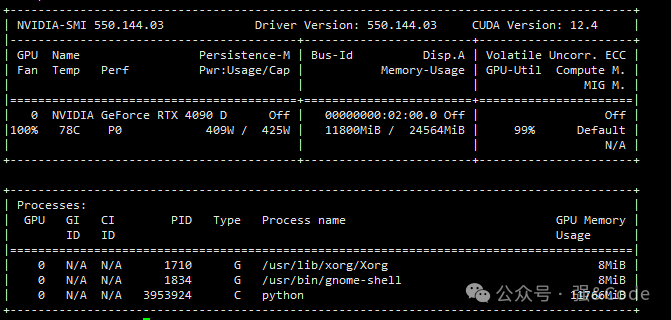
生成视频效果还是很不错的。
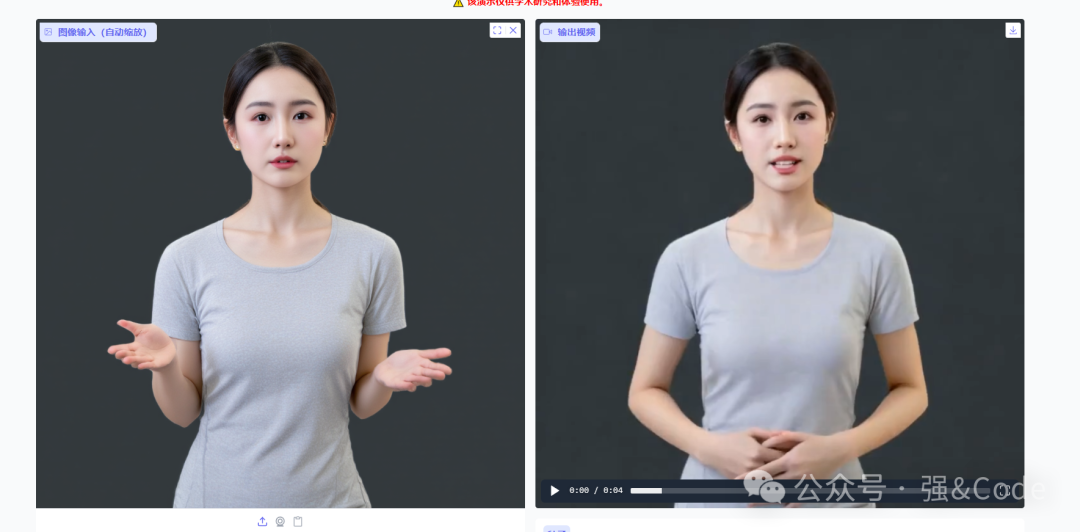
8、这既然支持自定义数字人,我自己上传个人物图像试试。
效果不是很理想,有时候没上传带手的人物形象,但是还生成了个手,有点不忍直视。我就不贴视频了。
这就是我的整个的搭建的过程。后台回复“EchoMimic”获取项目代码,模型文件,ffmpeg-static下载链接
大家在搭建或者使用的过程中有遇到什么问题,欢迎大家关注留言。大家一起来讨论学习。