ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning

🧠 一、论文背景:为什么需要 ReSearch?
🌍 大语言模型(LLM)的问题:
尽管 GPT、Claude、Qwen 等 LLMs 在推理上取得了巨大进展,但它们仍面临几个关键挑战:
- 信息孤岛:模型知识固定于预训练阶段,无法访问最新信息;
- 复杂推理难题:多跳推理(multi-hop QA)要求模型一步步查找信息、推理中间结论,再得出最终答案;
- 传统 RAG 的局限:
- Retrieval-Augmented Generation(RAG)方法通过外部检索补充知识,但:
- 多步检索依赖人工 prompt 设计;
- 很难自动控制何时检索、检索什么;
- 不具备「交互式推理+检索」的一体化策略。
- Retrieval-Augmented Generation(RAG)方法通过外部检索补充知识,但:
🔁 二、核心思想:Reason with Search + Reinforcement Learning
📌 ReSearch 做了什么?
目标:训练一个 LLM 学会「何时思考、何时搜索、如何使用搜索结果继续思考」,而不是硬编码流程。
🧩 关键设计:
| 组成 | 内容 |
|---|---|
| 🔍 外部搜索 | 模型可自由调用 Wikipedia 检索(通过 <search> 标签) |
| 🧠 内部推理 | 每一步生成 <think> 推理内容 |
| 📦 强化学习 | 不依赖人工标注,仅用奖励引导模型学习出推理-搜索交互行为 |
| 🎯 GRPO 策略 | Group-based 强化学习优化搜索与推理策略,避免训练不稳定 |
🤖 核心组件:
-
推理链格式(如
<think>,<search>,<result>,<answer>):- 统一格式使得模型知道何时检索、如何控制流程;
- 类似编程语言中的「控制流」。
-
奖励设计:
- 正确答案奖励(F1);
- 格式合规奖励(必须出现 boxed 答案)。
🔬 三、方法细节总结
🔍 图 2(a):GRPO 强化学习训练流程(整体架构)

(Figure 2)展示了 ReSearch 框架的训练流程,分为两个部分:
🧩 (a) GRPO Pipeline:基于强化学习的整体训练框架
这是 ReSearch 所用的 Group Relative Policy Optimization (GRPO) 策略训练流程。
流程解释:
-
Question 输入:用户提出一个多跳问题 (x),例如“Who was president of the United States in the year that Citibank was founded?”
-
LLM Policy + Search Module:
- 模型在生成过程中可以选择执行
<search>...</search>操作。 - 这些搜索指令会被送到搜索模块(如 Wikipedia 检索系统),返回
<result>...</result>。 - 这种生成与搜索交替进行,形成完整的推理轨迹(rollout)( y_1, y_2, …, y_G )。
- 模型在生成过程中可以选择执行
-
Reward Calculation:每个生成的 rollout 会通过奖励函数进行评分 ( r_1, …, r_G ),包括:
- ✅ 答案是否正确(Answer Reward)
- 🧩 格式是否合规(Format Reward)
-
Reference Model + KL Penalty:
- 使用参考模型对比当前策略,计算 KL 散度,防止训练过度偏移。
-
Group Computation:
- 使用 GRPO 策略,根据组内 rollout 的相对优势 ( A_1, …, A_G ) 来更新 LLM 策略,优化方向是产生更高奖励的策略。
🔁 (b) Rollout Generation 过程:一个具体推理示例
这个部分详细展示了 ReSearch 如何逐步交替生成思考与搜索操作。
示例任务:
“Who was president of the United States in the year that Citibank was founded?”
步骤说明:
-
Step ①: Generate till
<search>or<eos>- 模型首先生成内部思考
<think>:
“To answer this question, I need… I will start by searching for the founding year of Citibank.” - 然后生成
<search>:
“when was Citibank founded”
- 模型首先生成内部思考
-
Step ②: Retrieve Search Result
- 检索模块处理查询,返回
<result>:
“Citibank was founded in 1812…”
- 检索模块处理查询,返回
-
Step ③: Concat then Continue
- 将检索结果与已有文本拼接,模型继续生成下一轮
<think>+<search>,直到得出最终答案。
- 将检索结果与已有文本拼接,模型继续生成下一轮
最终输出:
- 包含多轮
<think>、<search>和<result>的推理链。 - 答案位于
<answer>\boxed{James Madison}</answer>中,格式统一、便于评分。
🧠 图标/模块说明:
| 图标/模块 | 含义 |
|---|---|
| 🔄 LLM Policy | 当前策略模型,负责生成推理链 |
| 🔍 Search | 触发外部搜索(如 Wikipedia) |
| 🧊 Reference Model | 旧模型,用于 KL 约束参考 |
| 🧮 Reward Calculation | 答案+格式评估,决定奖励值 |
| 🧑⚖️ Group Computation | GRPO 策略,基于 group 计算相对优势 |
🧠 <think> | 模型思考内容 |
🔍 <search> | 搜索查询 |
📚 <result> | 搜索返回内容 |
✅ <answer> | 最终输出答案 |
🧪 四、实验表现
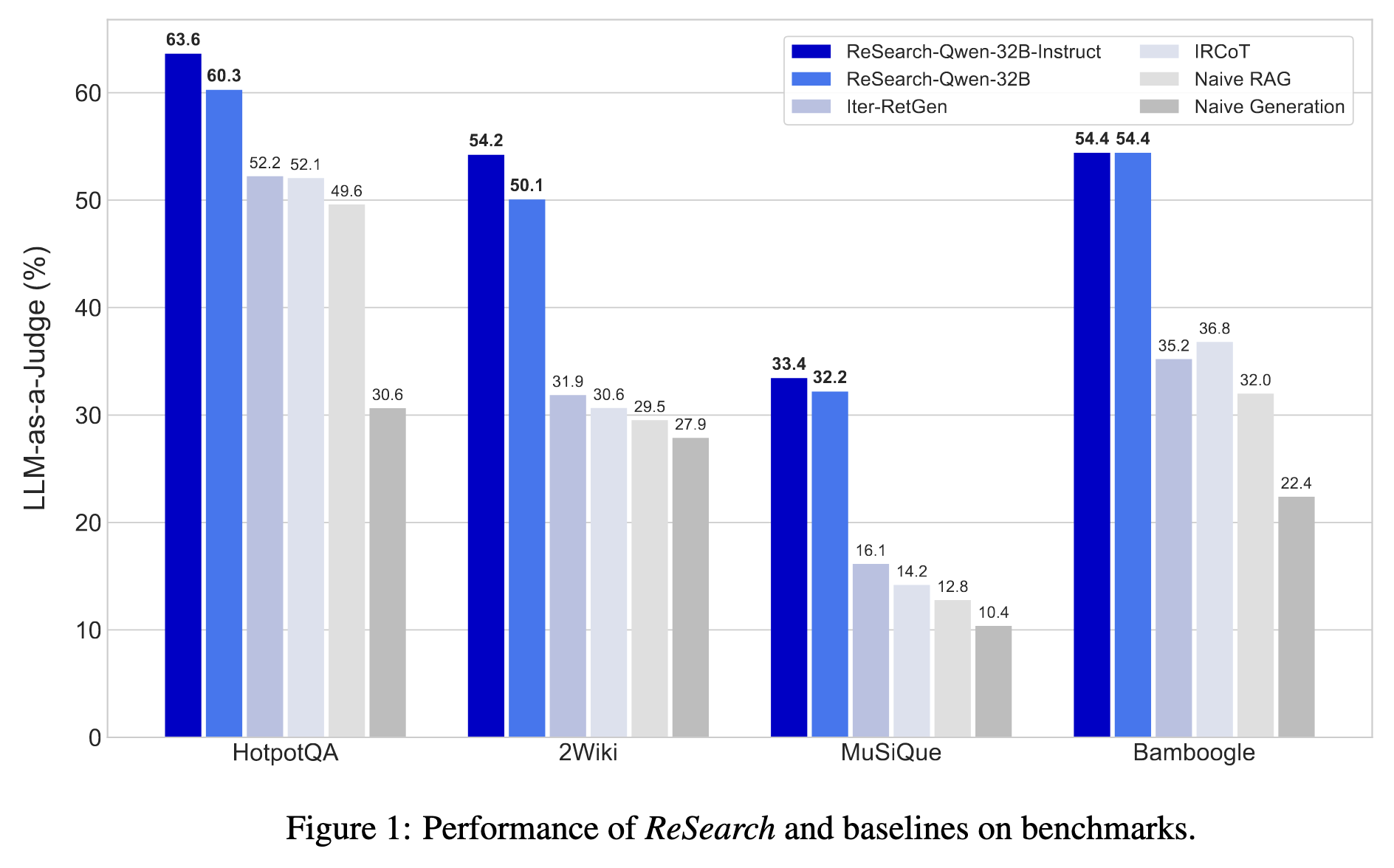
Figure 1展示了 ReSearch 框架在四个多跳问答基准数据集上的性能对比,使用了 LLM-as-a-Judge 作为评估指标(越高越好)。
📊 图表结构解析
Y轴:
- LLM-as-a-Judge (%):由 GPT-4 等高质量语言模型自动判断回答是否正确的比例。
X轴:
- 四个多跳问答数据集:
- HotpotQA
- 2Wiki
- MuSiQue
- Bamboogle
柱状图颜色(方法):
| 颜色 | 方法 |
|---|---|
| 深蓝 | ReSearch-Qwen-32B-Instruct(最强) |
| 蓝 | ReSearch-Qwen-32B(无 Instruct 微调) |
| 中蓝 | Iter-RetGen:基于检索-生成交替 |
| 浅蓝 | IRCoT:检索-推理交错的提示法 |
| 浅灰 | Naive RAG:直接拼接搜索结果 |
| 深灰 | Naive Generation:完全不检索,只靠 LLM 生成 |
🧠 总结图像的价值:
这张图直观体现出:
| 方法类型 | 是否可控推理 | 表现(平均) | 特点 |
|---|---|---|---|
| ReSearch | ✅ 强化学习 + 搜索推理链 | ★★★★★ | 无需监督标签,RL 训练 |
| IRCoT / Iter-RetGen | ❌ 提示策略(提示工程) | ★★ | 依赖 prompt 工程设计 |
| Naive | ❌ 无推理能力 | ★ | 无法处理复杂任务 |
📈 性能结果:
相比 Naive Generation / RAG / IRCoT 等基线方法,ReSearch 有 8.9%~22.4% 的大幅提升,并且:
- 泛化强:只在 MuSiQue 上训练,也能迁移到其他任务;
- 模型规模敏感:32B 指令微调模型效果最好。
🧠 五、与其他方法对比
| 方法 | 特点 | 局限 |
|---|---|---|
| Naive RAG | 检索+拼接 | 无推理链、不可控 |
| IRCoT | 交替的 CoT + 检索 | 依赖 prompt 工程 |
| ReSearch | 自动学会何时检索与推理 | 无需监督标注 |
🌟 六、创新点总结
| 创新点 | 描述 |
|---|---|
| ✅ 推理+搜索结合 | 搜索被当作推理链一部分处理,而非外部操作 |
| ✅ 无需监督数据 | 使用强化学习激发推理结构与搜索调用策略 |
| ✅ 结构化格式 | 统一 <think>、<search> 等标签格式 |
| ✅ 自我反思能力 | 模型在搜索失败后能“意识到错误”并自我修正(见 case study) |