《深入理解双向链表:增删改查及销毁操作》
目录
一. 链表分类
1.1 单向和双向
1.2 带头和不带头
1.3 循环和不循环
二. 双向链表
2.1 双向链表的代码定义
2.2 双向链表的初始化
3.3 哨兵位
三. 双向链表的增删改查与销毁
3.1 新节点的申请以及初始化
3.2 尾插
3.3 头插
3.4 尾删
3.5 头删
3.6 查找
3.7 指定位置后插入
3.8 指定位置删除
3.9 销毁
3.10 打印函数
一. 链表分类
链表从结构特点可以分为是否带头结点 是否是循环链表 是否是双向链表
因此可分为8类
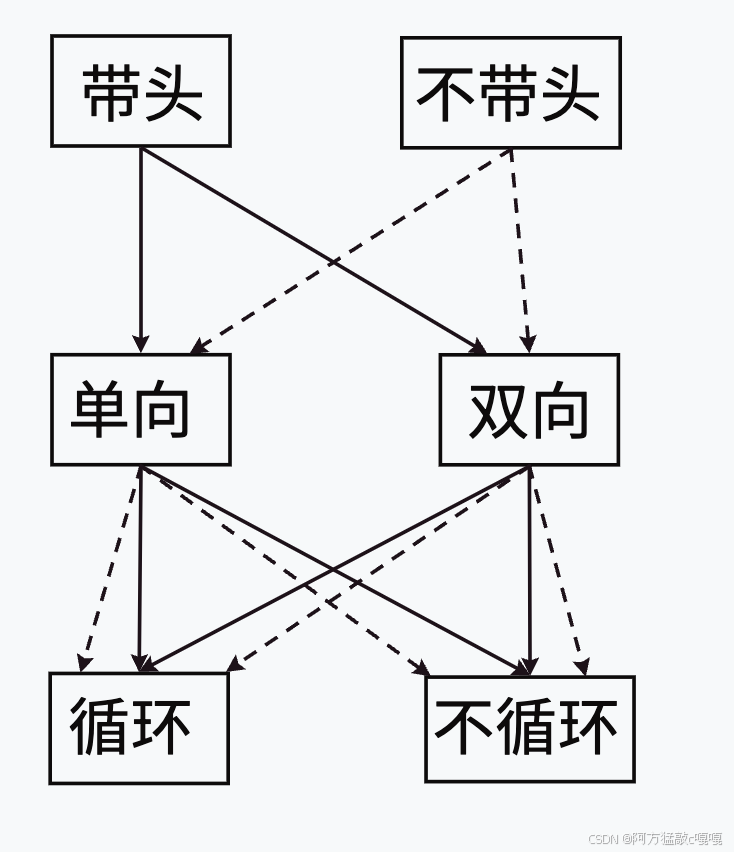
其中双向链表就是 带头双向循环链表
1.1 单向和双向
单向链表
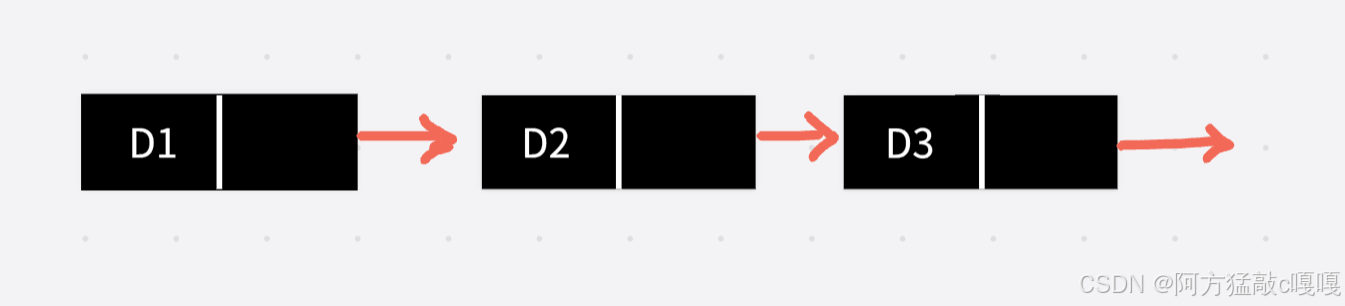
- 单向链表:每个节点只包含两个部分,即数据域和指向下一个节点的指针域 。这意味着节点之间的连接是单向的,只能从一个节点访问到它的下一个节点,链表的最后一个节点的指针指向空(通常用
null表示)。
双向链表

- 双向链表:每个节点除了数据域外,还包含两个指针域,一个指针指向前一个节点(前驱节点),另一个指针指向后一个节点(后继节点) 。因此,双向链表的节点可以同时访问它的前驱和后继节点,在链表两端,头节点的前驱指针和尾节点的后继指针通常指向空(非循环双向链表)。
1.2 带头和不带头
不带头链表
- 不带头链表:没有额外的特殊头节点,链表的第一个节点就直接存储数据。在单链表中,第一个节点的指针指向第二个节点,最后一个节点指针为空;双向链表中,第一个节点前驱指针为空,后继指针指向第二个节点 。
带头链表

- 带头链表:存在一个特殊的头节点,这个头节点通常不存储实际的数据 ,它的主要作用是作为链表的起始标志。在单链表中,头节点的指针指向第一个真正存储数据的节点;在双向链表中,头节点的后继指针指向第一个数据节点,前驱指针可以指向空(单链表改造的双向链表)或者指向尾节点(循环双向链表)。
1.3 循环和不循环
不循环链表
- 不循环链表:也就是常规链表,链表的最后一个节点的指针指向空(
null) ,标志着链表的结束,节点之间的连接没有形成环状。
循环链表

- 循环链表:链表中最后一个节点的指针不是指向空(
null),而是指向链表的头节点,从而形成一个环形结构。它可以基于单链表形成循环单链表,也可以基于双向链表形成循环双向链表。在循环双向链表中,不仅尾节点的后继指针指向头节点,头节点的前驱指针还会指向尾节点 。
实际中最常用的其实还是两种:单链表(不带头单向不循环链表)和双向链表(带头双向循环链表)
二. 双向链表
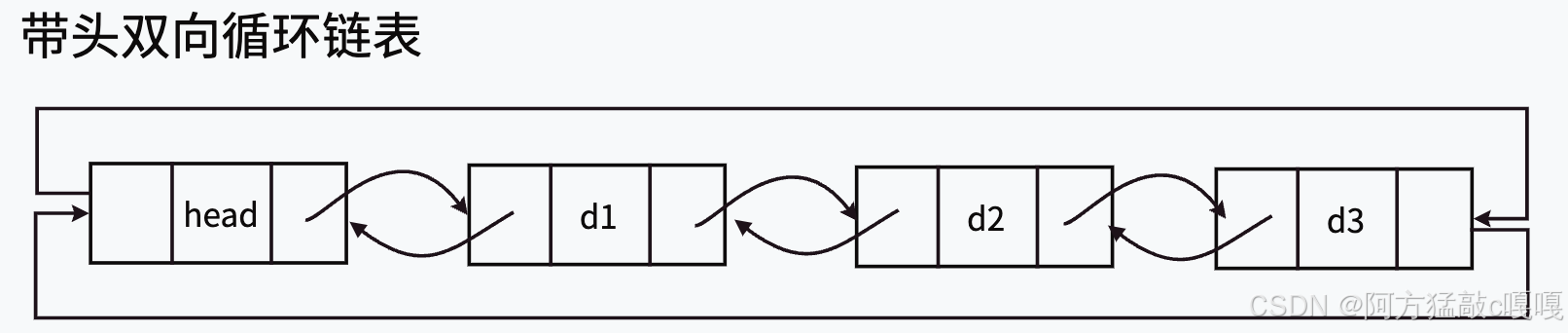
结构特点
双向链表的每个节点除了存储数据元素外,还包含两个指针域:
- 前驱指针(prev):用于指向该节点的前一个节点。
- 后继指针(next):用于指向该节点的后一个节点 。
在双向链表的开头有一个头节点,头节点的前驱指针通常为空(如果不是循环双向链表);在链表末尾有一个尾节点,尾节点的后继指针为空(同样在非循环双向链表中 )。而循环双向链表中,头节点的前驱指针指向尾节点,尾节点的后继指针指向头节点。
2.1 双向链表的代码定义
typedef int LTDataType;
typedef struct ListNode
{LTDataType data;//前驱指针,指向前一个指针struct ListNode* prev;//后继指针,指向后一个指针struct ListNode* next;
}ListNode;2.2 双向链表的初始化
//头节点初始化
void LTInit(ListNode** pphead)
{ListNode* ph = (ListNode*)malloc(sizeof(ListNode));if (ph==NULL){perror("malloc fail!");exit(1);}*pphead = ph;(*pphead)->data = -1;//任意取值(*pphead)->prev = *pphead;(*pphead)->next = *pphead;
}我们称呼双向链表的头节点为哨兵位 下面我来向大家解释一下哨兵位的作用和意义
3.3 哨兵位
在数据结构(尤其是链表)中,哨兵位(Sentinel Node) 是一个不存储实际数据的节点,通常作为链表的 “占位符” 存在于链表的头部(或尾部),用于简化链表的操作逻辑,避免边界条件的特殊处理。
核心作用:消除边界判断
没有哨兵位时,操作链表(如插入、删除)需要额外判断 “链表是否为空”“操作的是不是头节点 / 尾节点” 等边界情况,逻辑复杂。
哨兵位的存在让链表在空状态和非空状态下的操作逻辑统一,无需特殊判断。
举例说明(双向链表)
以带头节点的双向链表为例,哨兵位即 “头节点”:
哨兵位本身不存储有效数据,仅作为链表的固定起点。
空链表时,哨兵位的
prev和next指向NULL(普通链表)或自身(循环链表)。非空链表时,哨兵位的
next指向第一个有效节点,最后一个有效节点的prev指向哨兵位(循环链表)。
优势对比
| 操作场景 | 无哨兵位 | 有哨兵位(哨兵节点) |
|---|---|---|
| 插入第一个节点 | 需要判断头指针是否为 | 直接插入到哨兵位之后,无需判断 |
| 删除最后一个节点 | 需要判断是否只剩一个节点 | 直接修改指针,逻辑统一 |
| 遍历边界 | 需判断 | 循环链表中可通过哨兵位终止遍历 |
注:参数是二级指针而非一级指针的原因
LTInit 函数需要改变外部头指针变量本身的指向(从 NULL 变为指向新创建的哨兵位节点),而 C 语言中函数参数是值传递,因此必须通过二级指针才能实现对外部指针变量的修改。如果使用一级指针,无法将初始化后的节点地址 “传回” 给外部,导致初始化失败。
三. 双向链表的增删改查与销毁
在学习双向链表的增删查改之前 我们需要封装ListNode* LTBuyNode(LTDataType x)函数 用于申请新的节点 以及初始化新的节点
3.1 新节点的申请以及初始化
ListNode* ByeLTNode(LTDataType x)
{ListNode* newcode = (ListNode*)malloc(sizeof(ListNode));newcode->data = x;newcode->next = newcode;newcode->prev = newcode;return newcode;
}3.2 尾插
// 3.1 尾插:在链表尾部插入节点
void LTPushBack(ListNode* phead, LTDataType x) {assert(phead); // 哨兵位不能为空ListNode* newNode = BuyLTNode(x);ListNode* tail = phead->prev; // 尾节点是哨兵位的前驱// 调整指针关系tail->next = newNode;newNode->prev = tail;newNode->next = phead;phead->prev = newNode;
}- 找到当前尾节点(哨兵位的
prev) - 新节点插入到尾节点和哨兵位之间
- 时间复杂度:O (1)(无需遍历找尾)
3.3 头插
// 3.2 头插:在链表头部(哨兵位后)插入节点
void LTPushFront(ListNode* phead, LTDataType x) {assert(phead);ListNode* newNode = BuyLTNode(x);ListNode* first = phead->next; // 第一个有效节点// 调整指针关系phead->next = newNode;newNode->prev = phead;newNode->next = first;first->prev = newNode;
}- 找到当前第一个有效节点(哨兵位的
next) - 新节点插入到哨兵位和第一个有效节点之间
- 时间复杂度:O (1)
3.4 尾删
// 3.3 尾删:删除链表尾部节点
void LTPopBack(ListNode* phead) {assert(phead);assert(phead->next != phead); // 链表不能为空(只有哨兵位)ListNode* tail = phead->prev; // 要删除的尾节点ListNode* prevTail = tail->prev; // 尾节点的前驱// 调整指针关系prevTail->next = phead;phead->prev = prevTail;free(tail);tail = NULL; // 避免野指针
}- 找到尾节点和尾节点的前驱
- 断开尾节点与前后节点的连接并释放
- 时间复杂度:O (1)
3.5 头删
void LTPopFront(ListNode* phead) {assert(phead);assert(phead->next != phead); // 链表不能为空ListNode* first = phead->next; // 要删除的第一个节点ListNode* second = first->next; // 第二个节点// 调整指针关系phead->next = second;second->prev = phead;free(first);first = NULL;
}- 找到第一个有效节点和第二个有效节点
- 断开第一个节点与前后节点的连接并释放
- 时间复杂度:O (1)
3.6 查找
// 4.1 查找:查找值为x的节点,返回第一个找到的节点指针,找不到返回NULL
ListNode* LTFind(ListNode* phead, LTDataType x) {assert(phead);ListNode* cur = phead->next; // 从第一个有效节点开始查找while (cur != phead) { // 循环结束条件:回到哨兵位if (cur->data == x) {return cur; // 找到,返回节点指针}cur = cur->next;}return NULL; // 未找到
}- 从第一个有效节点开始遍历,直到回到哨兵位
- 找到目标值时返回对应节点指针,未找到返回 NULL
- 时间复杂度:O (n),需要遍历链表
3.7 指定位置后插入
// 4.2 指定位置后插入:在pos节点之后插入新节点
void LTInsertAfter(ListNode* pos, LTDataType x) {assert(pos); // pos不能为NULLListNode* newNode = BuyLTNode(x);ListNode* nextNode = pos->next; // 记录pos的下一个节点// 调整指针关系pos->next = newNode;newNode->prev = pos;newNode->next = nextNode;nextNode->prev = newNode;
}- 在给定节点
pos的后面插入新节点 - 只需调整
pos、新节点和pos下一个节点的指针关系 - 时间复杂度:O (1),已知位置时无需遍历
- 注意:
pos不能是 NULL,需要通过断言确保
3.8 指定位置删除
void LTErase(ListNode* pos) {assert(pos); // pos不能为NULLListNode* prevNode = pos->prev; // pos的前一个节点ListNode* nextNode = pos->next; // pos的后一个节点// 调整指针关系,跳过pos节点prevNode->next = nextNode;nextNode->prev = prevNode;// 释放pos节点内存free(pos);pos = NULL; // 避免野指针
}- 直接删除
pos指向的节点 - 通过
pos->prev和pos->next找到前后节点,调整它们的指针关系 - 释放
pos节点的内存,避免内存泄漏 - 时间复杂度:O (1),已知位置时无需遍历
3.9 销毁
void LTDestroy(ListNode** pphead) {assert(pphead && *pphead); // 链表必须存在ListNode* cur = (*pphead)->next;ListNode* next = NULL;// 遍历释放所有有效节点while (cur != *pphead) {next = cur->next; // 先记录下一个节点free(cur);cur = next;}// 释放哨兵位free(*pphead);*pphead = NULL; // 避免野指针
}- 需要使用二级指针,因为要将外部的头指针置为 NULL
- 先遍历释放所有有效节点,再释放哨兵位
- 确保所有动态分配的内存都被释放,避免内存泄漏
- 时间复杂度:O (n),需要遍历整个链表
3.10 打印函数
// 打印链表(用于测试)
void LTPrint(ListNode* phead) {assert(phead);ListNode* cur = phead->next;printf("哨兵位 -> ");while (cur != phead) {printf("%d -> ", cur->data);cur = cur->next;}printf("哨兵位\n");
}以上就是全部内容 希望能为了提供些许帮助 谢谢