架构性能优化三板斧:从10秒响应到毫秒级的演进之路

目录
- 前言:从龟速响应到极速体验的血泪史
- 第一板斧:缓存战略——让数据插上翅膀
- 第二板斧:数据库优化——从"慢如蜗牛"到"快如闪电"
- 第三板斧:架构重构——分布式的艺术
- 实战案例:某电商平台的性能逆袭之路
- 总结:性能优化的核心思想
前言:从龟速响应到极速体验的血泪史
各位同行们,还记得那些年被慢系统支配的恐惧吗?用户点击一个按钮,去泡杯茶回来页面还在转圈圈;数据库查询一跑就是十几秒,仿佛在演示什么叫"慢工出细活"。
今天就来聊聊如何用"三板斧"彻底治愈这些性能顽疾。这套方法论已经帮助无数团队完成了从10秒响应到毫秒级的华丽转身,堪称性能优化界的"九阴真经"。
别担心,我们不会满嘴跑火车。在高并发的分布式的系统中,缓存是必不可少的一部分。没有缓存对系统的加速和阻挡大量的请求直接落到系统的底层,系统是很难撑住高并发的冲击,这套优化策略已经在实际项目中验证过无数次了。
第一板斧:缓存战略——让数据插上翅膀
缓存的三重境界
缓存就像是数据的"任意门",让原本需要跋山涉水才能获取的数据,瞬间就能送到用户面前。但缓存可不是简单的"复制粘贴",它有着严格的层次结构。
上图展示了一个经典的三级缓存架构。用户请求首先命中本地缓存(通常是应用内存),如果没有找到数据,就去分布式缓存(如Redis)中查找,最后才会访问数据库。这种层层递进的策略,能够将大部分请求拦截在前端,避免对后端数据库造成压力。
缓存策略的精髓
Cache-Aside模式是最常用的缓存模式,应用程序直接管理缓存和数据库之间的同步:
这个序列图清晰地展示了Cache-Aside模式的工作流程。当缓存未命中时,应用程序负责从数据库获取数据,并主动将数据写入缓存,确保下次相同请求能够快速响应。
分布式缓存的架构设计
现代高并发系统中,单机缓存已经无法满足需求,KrakenD 是一个面向 Kubernetes 的 API 网关,专注于高性能和低延迟,旨在优化微服务之间的 API 调用,类似的高性能组件都在向分布式架构演进。
这个架构图展示了一个典型的Redis主从架构配合Sentinel哨兵机制的部署方案。主节点负责写入操作,从节点负责读取操作,而Sentinel负责监控和故障转移,确保系统的高可用性。
第二板斧:数据库优化——从"慢如蜗牛"到"快如闪电"
索引优化:数据库的高速公路
索引就像是图书馆的目录卡片,没有它,查找一条记录就像在茫茫书海中大海捞针。但索引也不是万能药,用错了反而会拖慢系统。
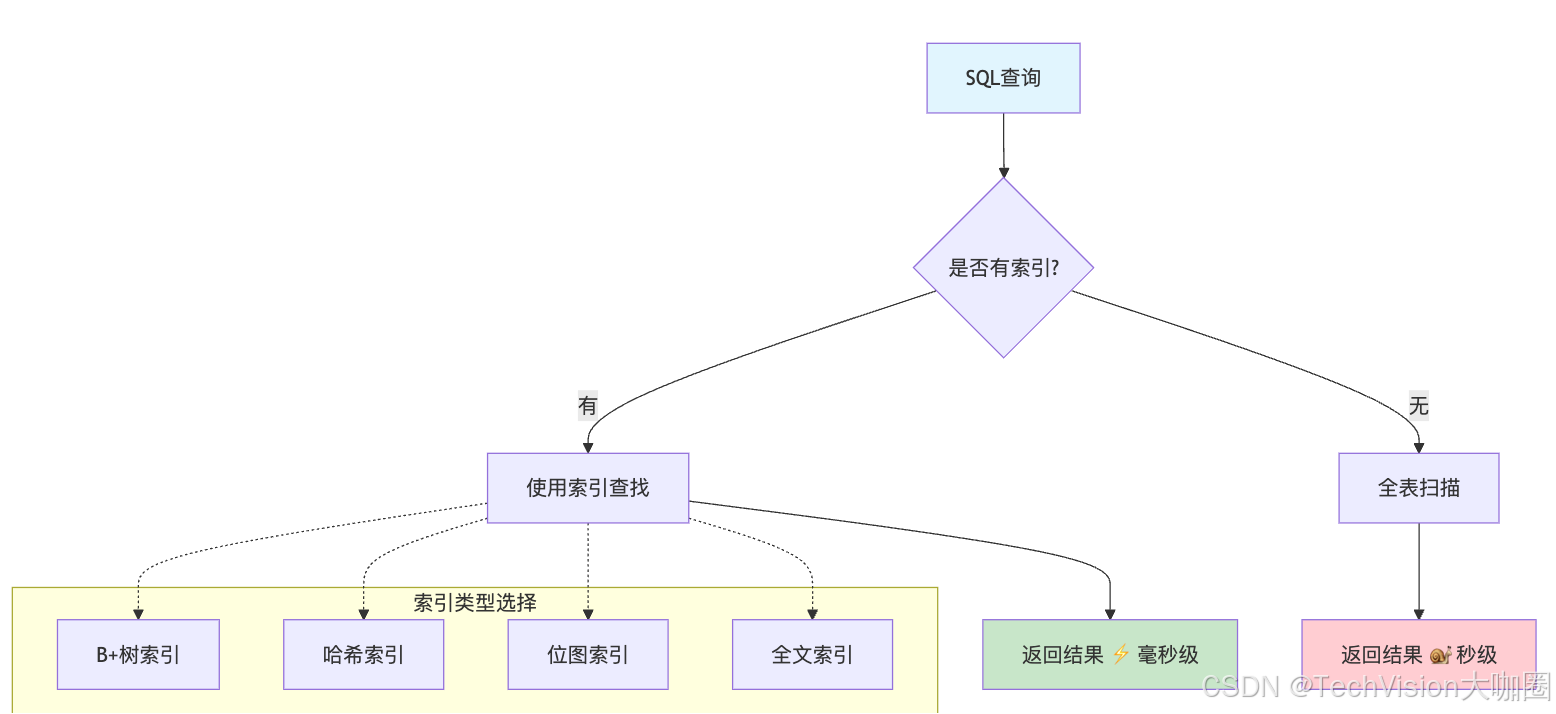
上图生动地展示了索引对查询性能的巨大影响。有索引的查询能在毫秒级返回结果,而全表扫描可能需要几秒甚至更长时间。不同类型的索引适用于不同的场景,B+树索引适合范围查询,哈希索引适合精确查找。
读写分离:让数据库各司其职
读写分离是数据库优化的经典招式,就像是专业分工——让擅长读的专门负责读,擅长写的专门负责写。
这个架构图展示了读写分离的核心思想:通过数据库代理层智能路由,将写操作定向到主库,读操作分散到多个从库,既提升了读取性能,又降低了主库的压力。
分库分表:化整为零的艺术
当单表数据量达到千万级别时,就需要考虑分库分表了。这就像是把一个巨大的仓库拆分成多个小仓库,每个仓库管理一部分货物。
分库分表的核心是合理的分片策略,如按用户ID哈希、按时间范围等。上图展示了按用户ID范围进行水平分片的方案,通过路由层将不同用户的数据分散到不同的数据库实例中。
第三板斧:架构重构——分布式的艺术
从单体到微服务:大象的华丽转身
单体应用就像一头大象,虽然强壮,但转身困难。微服务架构则像一群蚂蚁,单个虽小,但协作起来能搬动比自己重几十倍的物品。
这个微服务架构图展现了现代分布式系统的典型构成:API网关负责统一入口和路由,各个微服务独立部署和扩展,服务注册中心管理服务发现,配置中心统一管理配置,监控中心提供全链路监控。
消息队列:异步处理的魔法棒
在高并发场景下,同步处理就像是在高峰期的单行道上开车,而异步处理则像是修建了高速公路的多车道。
消息队列的引入实现了系统的解耦和异步处理。生产者将消息发送到队列后立即返回,不需要等待消费者处理完成,大大提升了系统的响应速度和吞吐量。
负载均衡:流量的智能分发
负载均衡器就像是一个超级智能的交通警察,能够根据实时路况将车流引导到最合适的道路上。
负载均衡器通过多种算法智能分配请求,如轮询、加权轮询、最小连接数等。图中可以看到不同服务器的CPU使用率,负载均衡器会优先将请求分发给负载较轻的服务器。
实战案例:某电商平台的性能逆袭之路
让我们来看一个真实的案例。某电商平台在双11前夕面临巨大挑战:
优化前的痛点:
- 商品详情页响应时间:8-12秒
- 数据库CPU使用率:90%+
- 用户投诉率:居高不下
三板斧改造方案:
优化效果:
- 商品详情页响应时间:降至200ms以内
- 数据库CPU使用率:降至30%
- 系统吞吐量:提升15倍
总结:性能优化的核心思想
经过这三板斧的洗礼,我们的系统已经脱胎换骨。但性能优化不是一锤子买卖,需要遵循以下原则:
优化的黄金法则
- 测量先行:没有测量就没有优化,盲目优化等于浪费时间
- 找准瓶颈:优化应该从最大的瓶颈开始,小步快跑
- 渐进式改进:大爆炸式重构风险太大,渐进式改进更稳妥
- 持续监控:优化不是一劳永逸,需要持续监控和调整
技术选型的权衡
不同的业务场景需要不同的技术选型:
未来展望
聚焦大模型技术最前沿突破,汇聚学术界与工业界专家学者,深度解读 2024-2025 年度 AI 领域里程碑式论文、前沿技术框架与产业级实践报告,随着AI技术的发展,未来的性能优化将更加智能化:
- AI驱动的性能调优:机器学习算法自动优化参数配置
- 预测性扩容:基于历史数据预测流量峰值,提前扩容
- 智能缓存策略:AI算法动态调整缓存策略,提升命中率
性能优化是一门艺术,也是一门科学。希望这三板斧能够帮助大家在性能优化的道路上少走弯路,早日实现从龟速到闪电的华丽转身!
记住,好的架构不是设计出来的,而是演化出来的。保持持续改进的心态,你的系统终将成为业界标杆!
关于作者
资深架构师,专注于高性能系统设计与优化,曾主导多个千万级用户系统的架构升级改造。