Doirs Routine Load
本文来深入、详细地介绍一下 Apache Doris 的 Routine Load 功能。这是 Doris 中实现持续、自动化数据导入的核心特性,尤其适用于从 Kafka 等消息系统中实时摄取数据。
一、什么是 Routine Load?
Routine Load 是一种基于 MySQL 协议提交的常驻数据导入任务。用户通过创建一个 Routine Load 作业,向 Doris 描述数据源(如 Kafka)、消费进度、数据格式以及数据与目标表的映射关系。Doris 会自动地、持续地从数据源中拉取数据,并将数据导入到指定的表中。
核心特点:
-
持续消费:一旦作业创建,Doris 会作为一个消费者持续不断地消费数据,无需人工干预。
-
近实时:数据从产生到可查询,延迟可低至秒级。
-
Exactly-Once 语义:通过内部机制保证数据不丢不重(在大多数正常场景下)。
-
自动容错:能够自动处理网络异常、Broker 重启等故障,并支持断点续传。
-
水平扩展:导入任务可以并行运行,性能可随集群规模线性扩展。
二、核心工作原理与架构
1. 角色分工
-
FE (Frontend):
-
Job Scheduler:负责创建、调度、暂停、恢复和停止 Routine Load 作业。它将一个作业拆分成多个并行的 Task。
-
元数据管理:存储作业的元信息(如消费的 Kafka offset)。
-
-
BE (Backend):
-
Task Executor:是任务的实际执行者。每个 BE 都可以执行导入 Task。Task 负责从 Kafka 拉取一批数据,并将其导入到 Doris 的存储引擎中。
-
2. 工作流程
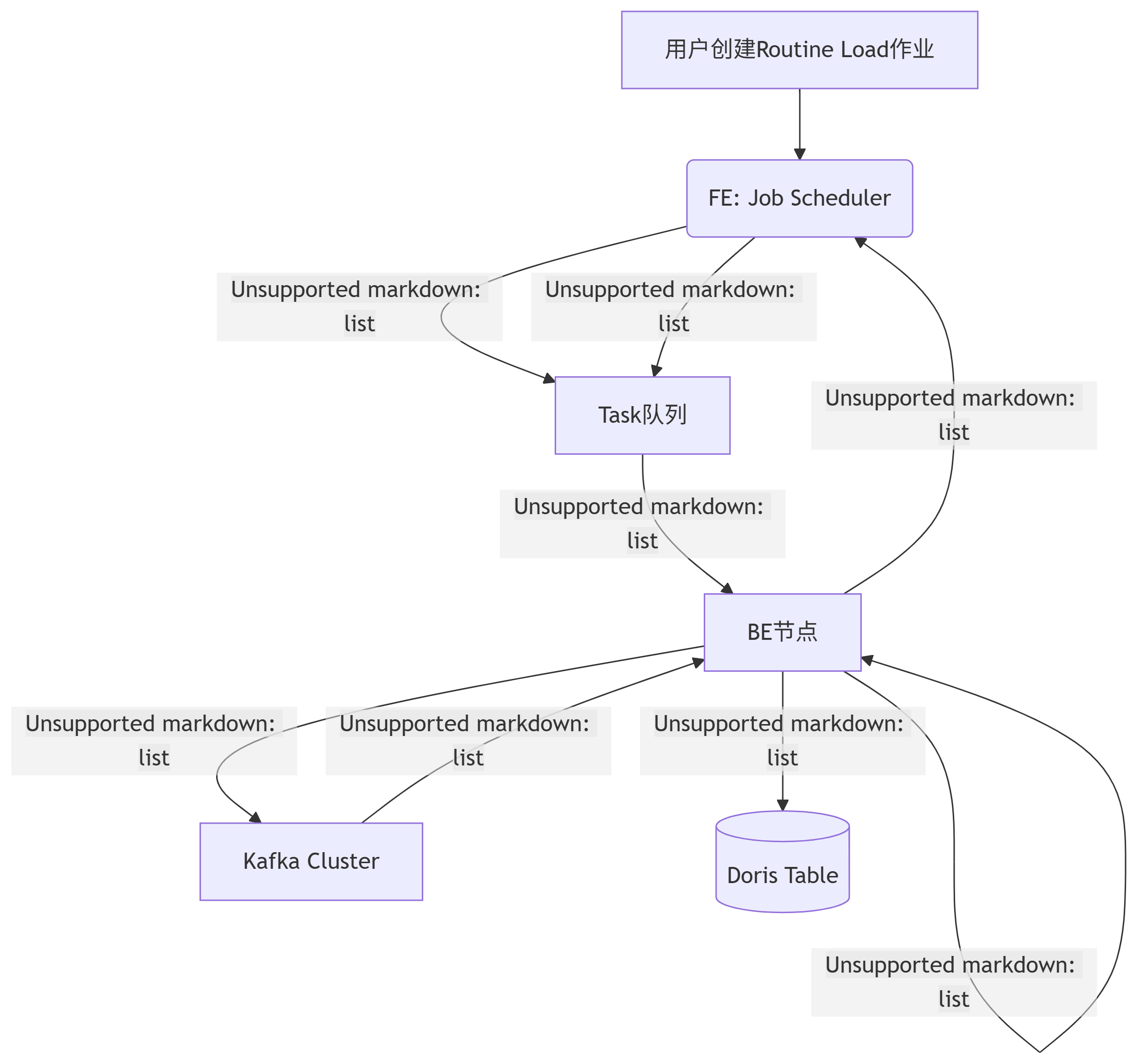
流程详解:
-
作业创建与拆分:FE 接收用户提交的作业请求,并根据
desired_concurrent_number和 Kafka Topic 的分区情况,将作业拆分成多个 Task。 -
任务分配:FE 的调度器将 Task 分配给负载较低的 BE 节点执行。
-
数据拉取与导入:每个 BE 上的 Task 作为 Kafka Consumer,从指定的 Partition 拉取一批数据(大小由
max_batch_rows/size控制)。 -
数据处理:BE 根据作业中定义的格式(如 CSV/JSON)、列映射和转换规则处理数据。
-
数据写入:处理后的数据被写入到目标 Doris 表中。
-
提交偏移量:一个 Task 成功后,BE 会向 FE 汇报,并由 FE 异步地 向 Kafka 提交消费偏移量 (Offset)。这是保证 At-Least-Once 的基础。
-
循环往复:一个 Task 完成后,FE 会立即生成一个新的 Task,继续消费下一个批次的数据,从而实现持续导入。
三、详细参数解析与配置
创建 Routine Load 的 SQL 语句包含多个部分,每个部分都至关重要。
1. 数据映射与转换 (COLUMNS 和 WHERE)
这是最灵活的部分,允许你在导入时对数据进行清洗和转换。
-
列映射:指定 Kafka 消息中的字段如何映射到 Doris 表的列。
sql
COLUMNS TERMINATED BY ",", -- 对于CSV: 指定列分隔符 COLUMNS (k1, k2, tmpk3, k4) -- 指定Kafka消息中的字段顺序
这里
tmpk3是消息中的一个字段,但目标表可能没有这个列,它可以被用于后续计算。 -
列转换与过滤:
sql
-- 在COLUMNS列表中,你可以使用函数进行计算 COLUMNS (user_id, item_id, event_time, price = tmp_price * 100, -- 计算: 将元数据中的tmp_price乘以100后导入price列region = "China", -- 填充常量值dt = FROM_UNIXTIME(event_time) -- 函数计算: 将时间戳转换为日期时间格式), -- 使用WHERE子句进行过滤 WHERE event_time > 1630000000 -- 只导入event_time大于此时间戳的数据
2. 作业属性 (PROPERTIES)
控制作业的行为、容错和性能。
-
并发控制:
-
"desired_concurrent_number" = "3":期望的并发任务数。这是最重要的性能参数。建议设置为 Kafka Topic 的分区数,以实现最大并行度。FE 会尽力满足此期望值,但实际并发数可能受 BE 节点数量或资源限制。
-
-
批处理设置(控制一个 Task 处理的数据量):
-
"max_batch_interval" = "20":每个 Task 的最大执行间隔(秒)。即使数据量没达到max_batch_rows/size,也会在这个时间后提交。 -
"max_batch_rows" = "200000":每个 Task 最多消费的行数。 -
"max_batch_size" = "104857600":每个 Task 最多消费的数据量(字节,此处为 100MB)。通常这个参数是主要限制因素。
-
-
容错与错误处理:
-
"max_error_number" = "1000":在整个作业生命周期内,允许的最大错误数据行数。达到此限制,作业会自动 PAUSE。需要手动检查原因并RESUME。 -
"strict_mode" = "false":是否开启严格模式。开启后,对于列类型转换(如非数字字符串转 INT)失败的行,会视为错误。
-
3. 数据源定义 (FROM KAFKA)
定义 Kafka 集群和 Topic 信息。
-
"kafka_broker_list" = "broker1:9092,broker2:9092":Kafka Broker 的地址列表。 -
"kafka_topic" = "your_topic":要消费的 Topic 名称。 -
"property.group.id" = "doris_group":消费组 ID。Doris 用它来管理消费偏移量。强烈建议为每个作业设置唯一的 group.id。 -
"property.security.protocol" = "SASL_PLAINTEXT":如果 Kafka 启用了认证,需要配置这些属性。 -
"kafka_partitions" = "0,1,2"和"kafka_offsets" = "1000,1000,1000":可选项。用于精确指定从哪些分区的哪个 Offset 开始消费。如果不指定,默认从当前消费组已提交的 Offset 开始。
四、高级特性与最佳实践
-
Exactly-Once 保证:
-
Doris 通过 “先导入,后提交Offset” 的机制来保证。
-
如果一批数据成功导入 Doris 但 Offset 提交失败,Doris 会重试这个 Task。由于数据已写入,重试时会有内置的去重机制(通过 Label)来避免重复数据。
-
因此,在非极端故障下,可以提供 Exactly-Once 语义。
-
-
多表导入:
-
一个 Routine Load 作业只能导入一张表。
-
如果需要导入多张表,需要为每张表创建独立的 Routine Load 作业。这些作业可以消费同一个 Kafka Topic,通过
WHERE条件或 JSON 路径过滤出各自需要的数据。
-
-
动态分区与预聚合:
-
Routine Load 常与 Dynamic Partitioning 和 Rollup 结合使用。
-
数据导入后,Doris 会自动地将其分布到相应的分区中,并自动触发预聚合操作,使得数据立即可查且查询性能最优。
-
-
性能调优:
-
增加并发度:确保
desired_concurrent_number<= Kafka 分区数。 -
调整批次大小:增加
max_batch_size(如 200MB-500MB)和max_batch_interval(如 30s-60s)可以让每个 Task 处理更多数据,减少开销,提高吞吐。 -
监控 BE 资源:使用
SHOW BACKENDS\G查看 CPU、IO 和网络负载,确保不是资源瓶颈。
-
五、常用管理命令总结
-
查看作业状态:
SHOW ROUTINE LOAD FOR your_job_name\G(关注State,Lag,Progress) -
查看作业错误:
SHOW ROUTINE LOAD ERROR WHERE JobName = 'your_job_name' -
暂停作业:
PAUSE ROUTINE LOAD FOR your_job_name; -
恢复作业:
RESUME ROUTINE LOAD FOR your_job_name; -
停止作业:
STOP ROUTINE LOAD FOR your_job_name;(不可逆)
总结
Routine Load 是 Doris 构建实时数据管道的心脏。它将 Kafka 等流式数据源与 Doris 的高性能分析能力无缝衔接,提供了声明式的配置方式、强大的数据处理能力和稳定可靠的运维体验。理解其工作原理和参数细节,是高效使用 Doris 至关重要的一步。