视频判重需求:别为同一内容花两次钱!
背景
运营团队提出需求,对视频进行判重,有三个诉求
- 避免重复采买费用重复支出
- 赋能运营人员人工短剧判重,提效、增加准确率
- 对于免费合作的短剧入库,避免重复入库影响用户体验
需求确认
通过沟通,技术团队明确了三个需求场景
- 场景1:视频文件内容、大小等完全一致,表现为文件签名md5一致
- 场景2:视频文件内容一致,存在字幕、调色、后期等方面影响,文件大小一般不一致
- 场景3:同一个剧本,演员不一样,讲述的内容大致相同
通过目标对齐,我们致力于解决上述场景1、场景2的情况,场景3不考虑
实现方案确认
通过调研,结合我们自身情况,发现有如下方案
- 阿里云视频DNA服务,通过识别视频DNA来判重
- 华为云视频指纹服务,通过视频指纹判重
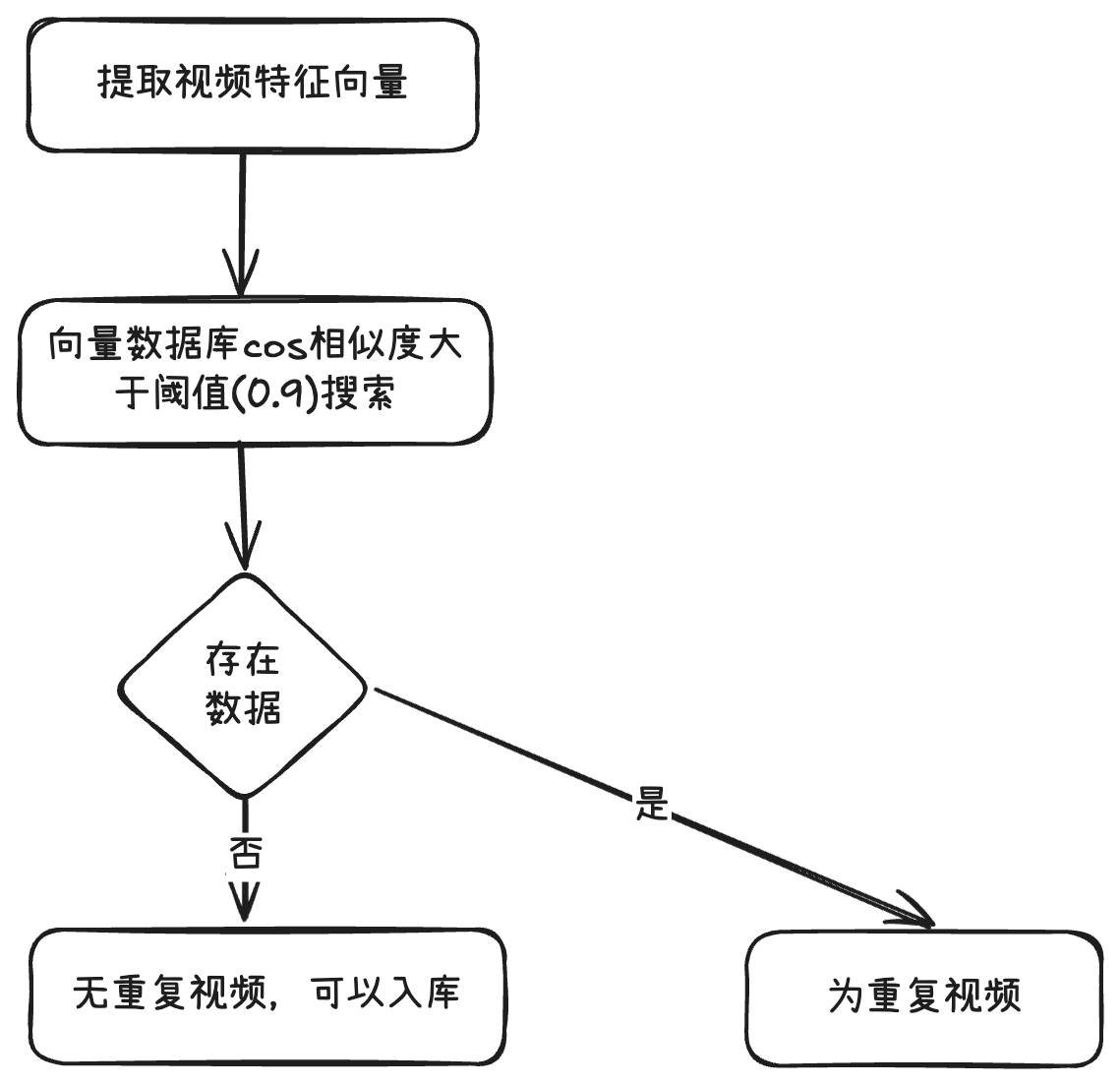
- 自研视频特征向量提取与相似度判定,相似度超过预设阈值,表明内容相同
情况实测
- 阿里云视频DNA服务,场景1识别ok,场景2识别率不高
- 华为云视频指纹服务,相关页面存在,找不到功能,通过与其工作人员沟通,反馈服务已下线
- 自研视频特征向量提取与相似度判定,场景1识别ok,场景2识别ok
自研实现思路
- 使用ResNet50 模型作为核心的特征提取器
- 利用颜色直方图比较相邻帧的差异,使用 Bhattacharyya 距离衡量帧间变化,当差异超过阈值时认为是关键帧
- 对每帧图像进行预处理(缩放、裁剪、归一化)和向量化,使用最大池化操作聚合所有帧特征
- 将视频特征向量存入向量数据库,可与其他视频的特征向量做点积实现相似度比较
代码示例(Python版本)
# 设备配置
device = None
# 加载预训练模型
model = None
# 图像预处理
preprocess = Nonedef init_model():global device, model, preprocessif model is not None:returnstart_time = time.time()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 使用更强大的ResNet50模型model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V2)model = torch.nn.Sequential(*(list(model.children())[:-1]))model = model.to(device)model.eval()preprocess = transforms.Compose([transforms.ToPILImage(),transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])end_time = time.time()logger.info(f"init_model cost time: {end_time - start_time}s")def scene_detect(video_path, threshold=0.3): # 修正阈值范围为0-1cap = cv2.VideoCapture(video_path)last_hist = Noneframes = []while True:ret, frame = cap.read()if not ret:breakframe = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)hist = cv2.calcHist([frame], [0,1,2], None, [8,8,8], [0,256,0,256,0,256])hist = cv2.normalize(hist, hist).flatten()if last_hist is not None:# 使用Bhattacharyya距离,有效范围0-1diff = cv2.compareHist(last_hist, hist, cv2.HISTCMP_BHATTACHARYYA)if diff > threshold:frames.append(frame)else:frames.append(frame)last_hist = histcap.release()return framesdef video_to_feature(video_path):init_model()frames = scene_detect(video_path)if len(frames) < 5: # 最少采样5帧cap = cv2.VideoCapture(video_path)total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))# 均匀采样补充帧sample_indices = np.linspace(0, total_frames-1, 5, dtype=int)for idx in sample_indices:cap.set(cv2.CAP_PROP_POS_FRAMES, idx)ret, frame = cap.read()if ret:frames.append(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))cap.release()frame_features = extract_features(frames)# 使用最大池化替代平均池化return np.max(frame_features, axis=0) 实现方案分析
总结:当前自研方案能有效解决我们短剧判重的需求。
优点:
- 基于 ImageNet 预训练的 ResNet50 模型,具备强大的特征提取能力
- 结合场景检测和均匀采样,既保证了关键内容的捕捉,又确保了采样的充分性
- 对帧级特征和最终向量都进行了归一化,有利于相似度计算的稳定性
缺点:
- 场景检测阈值固定,可能不适用于所有类型的视频内容
- 对镜头快速切换或渐变场景的处理能力有限
- 仅使用余弦相似度,对复杂语义关系的表达能力有限
适用场景:
- 视频去重任务:能够有效识别完全相同或高度相似的视频
- 内容推荐系统:可作为视频内容相似度计算的基础
- 版权检测:识别相同内容但可能有轻微处理差异的视频
- 视频聚类分析:将相似内容的视频归为一类
不太适用的场景:
- 语义理解要求高的场景:如需要理解视频具体情节或主题
- 细粒度内容区分:难以区分内容相似但有细微差别的视频
- 跨模态内容匹配:无法处理音频或文本为主的内容匹配