智能高效内存分配器测试报告
一、项目背景
- 这个项目是为了学习和实现一个高性能、特别是高并发场景下的内存分配器。这个项目是基于谷歌开源项目tcmalloc(Thread-Caching Malloc)实现的。tcmalloc 的核心目标就是替代系统默认的
malloc/free,在多线程环境下提供更高效的内存管理。 - C/C++的malloc虽然通用,但在高并发环境下,频繁申请和释放内存会引起剧烈锁竞争,进而造成性能瓶颈。
- 理解tcmalloc这个项目,不仅是深入 C++ 高性能编程、提升技术深度的绝佳途径,也是巩固C++学习的重要方式。
二、项目功能
项目介绍
采取三层结构:thread_cache-central_cache-page_cache。当一个线程需要申请内存时,先向thread cache进行申请,thread cache没有内存,转而向central cache进行申请,central cache没有内存,转而向page cache进行申请,page cache没有内存,会直接在堆上进行开辟。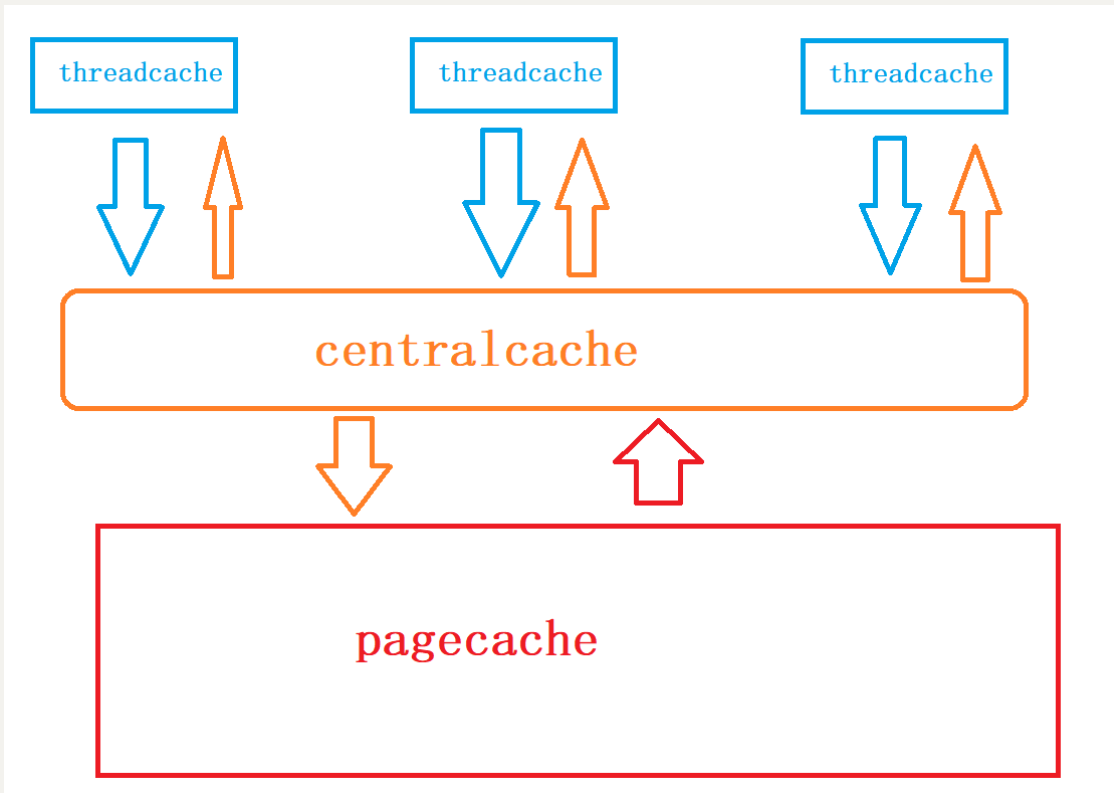
在进行归还内存时,不会直接释放掉,直接释放掉下次申请还要再进行上面的流程。对thread cache增加自由链表的结构,每次用完释放后,直接将其链入thread cache的自由链表中,待自由链表长度过长或占用内存过大,我们在统一进行回收合并,这样也能解决外碎片问题。
这三层结构主要解决小于和等于256KB大小的内存申请和释放问题,对于申请和释放大于256KB的内存块,直接向page cache进行申请和释放。
**thread cache:**对于小块内存进行管理,这个是每个线程独有的,这里不存在线程安全问题,不用进行加锁,每个线程独享一个cache。
**central cache:**中心缓存,所有线程共享的,thread cache按需从里面申请内存,会在合适时候对thread cache进行回收,以达到内存调度。central cache这里会存在内存竞争的问题,所以需要加锁。
**page cache:**是以页为单位进行存储和分配的,central cache向其申请对象时,page cache会给出若干页,进行切割定长内存小块分配给central cache。当若干页进行回收后,会进行合并,解决了内存碎片问题(外碎片)。
项目目标
- 高性能: 绝大多数小内存分配在 Thread Cache 无锁完成,大幅提升并发性能。
- 低锁竞争: 通过线程私有缓存和批量操作,将全局锁竞争降到最低(主要在 Central Cache 的桶锁)。
- 碎片控制: Page Cache 的合并机制有效缓解了外部碎片问题。
三、测试计划
单元测试
**一般测试:**测试是否能正常工作
void Test_ConcurrentAlloc1()
{int* p1 = (int*)ConcurrentAlloc(6); //maxsize:2 allocnum:1 size:0int* p2 = (int*)ConcurrentAlloc(7); //3 2 1int* p3 = (int*)ConcurrentAlloc(8); //3 0int* p4 = (int*)ConcurrentAlloc(1); //4 3 2int* p5 = (int*)ConcurrentAlloc(1); //4 1int* p6 = (int*)ConcurrentAlloc(1); //4 0int* p7 = (int*)ConcurrentAlloc(1); //5 4 3*p1 = 10;*p2 = 20;*p3 = 30;*p4 = 40;cout << p1 << ": " << *p1 << endl;cout << p2 << ": " << *p2 << endl;cout << p3 << ": " << *p3 << endl;cout << p4 << ": " << *p4 << endl;ConcurrentFree(p1); //maxsize:5 size:4 span._usecount:10ConcurrentFree(p2); //5 0 5ConcurrentFree(p3); //5 1 5ConcurrentFree(p4); //5 2 5ConcurrentFree(p5); //5 3 5ConcurrentFree(p6); //5 4 5ConcurrentFree(p7); //5 0 0
}
运行结果:

特殊测试:是否可以分配大块内存
void Test_BigAlloc()
{int *p1 = (int *)ConcurrentAlloc(MAX_BYTES + 100);int *p2 = (int *)ConcurrentAlloc(NPAGES << PAGE_SHIFT);*p1 = 10;*p2 = 20;cout << p1 << ": " << *p1 << endl;cout << p2 << ": " << *p2 << endl;ConcurrentFree(p1);ConcurrentFree(p2);
}
测试结果:

基准测试
// ntimes 一轮申请和释放内存的次数
// rounds 轮次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(malloc(16));v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (unsigned int)malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, (unsigned int)free_costtime);printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, (unsigned int)malloc_costtime + free_costtime);
}// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(ConcurrentAlloc(16));v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (unsigned int)malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, (unsigned int)free_costtime);printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime + free_costtime);
}int main()
{size_t n = 10000;cout << "==========================================================" << endl;BenchmarkConcurrentMalloc(n, 10, 10);cout << endl << endl;BenchmarkMalloc(n, 10, 10);cout << "==========================================================" << endl;return 0;
}
测试结果:
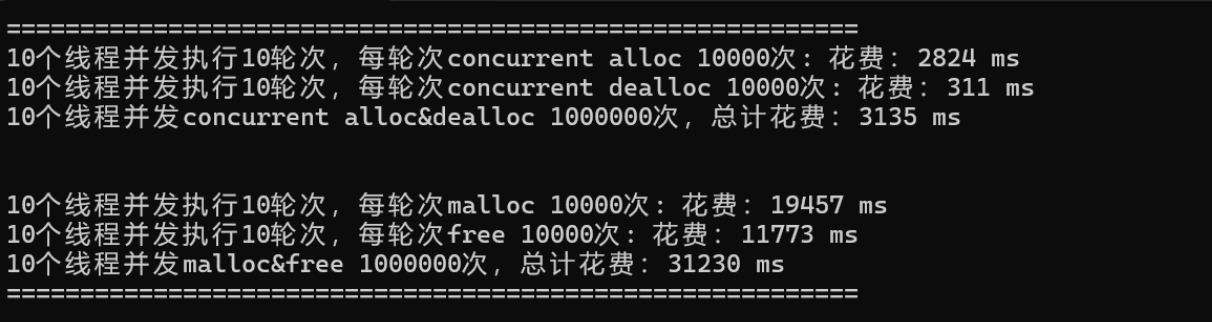
性能测试
多线程环境下的内存分配/释放压力测试:
void MultiThreadAlloc1()
{std::vector<void*> v;for (size_t i = 0; i < 7; ++i){void* ptr = ConcurrentAlloc(6);v.push_back(ptr);}for (auto e : v){ConcurrentFree(e);}
}
测试结果:
- ThreadCache 的批量分配和释放机制
- 对象在ThreadCache和CentralCache间的流动
- 内存池的资源保留策略
- 整个生命周期没有内存泄漏
内存碎片化测试:
void TestFragmentation() {const int BLOCK_COUNT = 500;std::vector<void*> mediumBlocks;std::vector<void*> smallBlocks;// 分配中型内存块 (32KB)for (int i = 0; i < BLOCK_COUNT; ++i) {mediumBlocks.push_back(ConcurrentAlloc(32 * 1024));}// 释放75%的中型块(制造碎片)for (int i = 0; i < BLOCK_COUNT * 3/4; ++i) {ConcurrentFree(mediumBlocks[i]);}// 分配大量小内存块 (128B)for (int i = 0; i < BLOCK_COUNT * 10; ++i) {smallBlocks.push_back(ConcurrentAlloc(128));}// 尝试分配大内存块void* bigBlock = ConcurrentAlloc(128 * 1024);assert(bigBlock != nullptr && "Fragmentation may be too high!");// 清理ConcurrentFree(bigBlock);for (auto p : smallBlocks) ConcurrentFree(p);for (int i = BLOCK_COUNT * 3/4; i < BLOCK_COUNT; ++i) {ConcurrentFree(mediumBlocks[i]);}std::cout << "Fragmentation Test: Passed\n";
}
测试结果:
- 在高度碎片化的环境中仍能分配大内存块
- 自动合并相邻空闲Span的能力
- 正确处理不同大小内存块的混合分配
- 资源完全回收无泄漏