食物分类案例优化改进 (数据增强,最优模型保存和使用)
目录
一.数据增强
二.保存最优模型
三.使用最优模型
一.数据增强
由于训练数据集图片太少所以我们模型的正确率很低,数据增强可以变相增加我们的训练集,
数据增强就是在对训练集增加格式转换,从而每次训练的图片都不一样,测试集则只需做标准化即可
transforms.RandomRotation(45),#随机旋转
transforms.CenterCrop(256),#从中心裁剪[256,256]
transforms.RandomHorizontalFlip(p=0.5),#随机水平旋转,概率p=0.5
transforms.RandomVerticalFlip(p=0.5),#随机垂直旋转,概率p=0.5
transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),#brightness(亮度)contrast(对比度)saturation(饱和度)hue(色调)
transforms.RandomGrayscale(p=0.1),#p的概率转换为灰度图,但任然是三个通道,不过三个通道相同
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])#标准化,设置通用的均值和标准差
data_transforms={'train':transforms.Compose([transforms.Resize([300,300]),transforms.RandomRotation(45),#随机旋转transforms.CenterCrop(256),#从中心裁剪[256,256]transforms.RandomHorizontalFlip(p=0.5),#随机水平旋转,概率p=0.5transforms.RandomVerticalFlip(p=0.5),#随机垂直旋转,概率p=0.5transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),#brightness(亮度)contrast(对比度)saturation(饱和度)hue(色调)transforms.RandomGrayscale(p=0.1),#p的概率转换为灰度图,但任然是三个通道,不过三个通道相同transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])#标准化,设置通用的均值和标准差]),'valid':#测试集只用标准化transforms.Compose([transforms.Resize([256,256]),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])
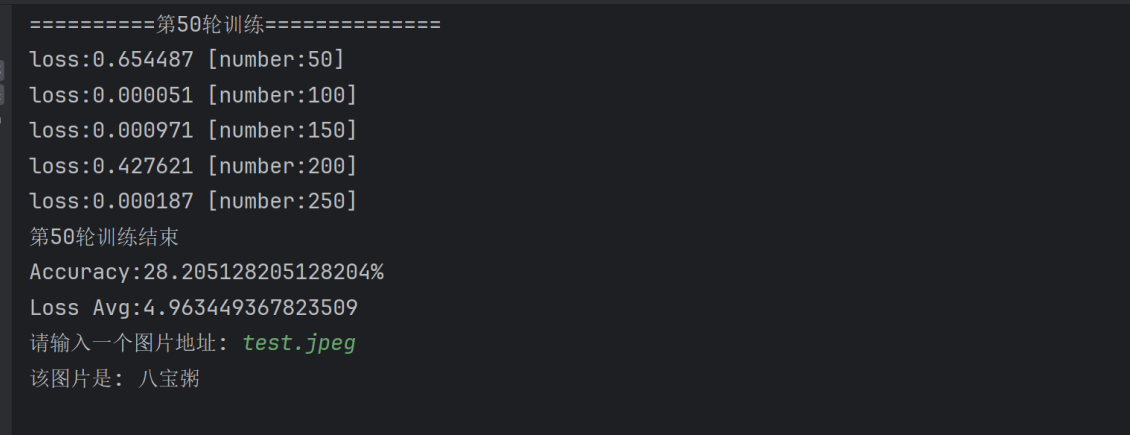
}需要注意的是数据增强后我们的训练轮次epoch必须更大这样才能起到变相增加训练集的作用,epoch太小反而会比之前的正确率更低
训练测试结果如下:
二.保存最优模型
我们知道模型的准确率并不会随着训练的轮次一直升高,当训练达到了一定的次数,我们的模型准确率就会开始波动下降,如图
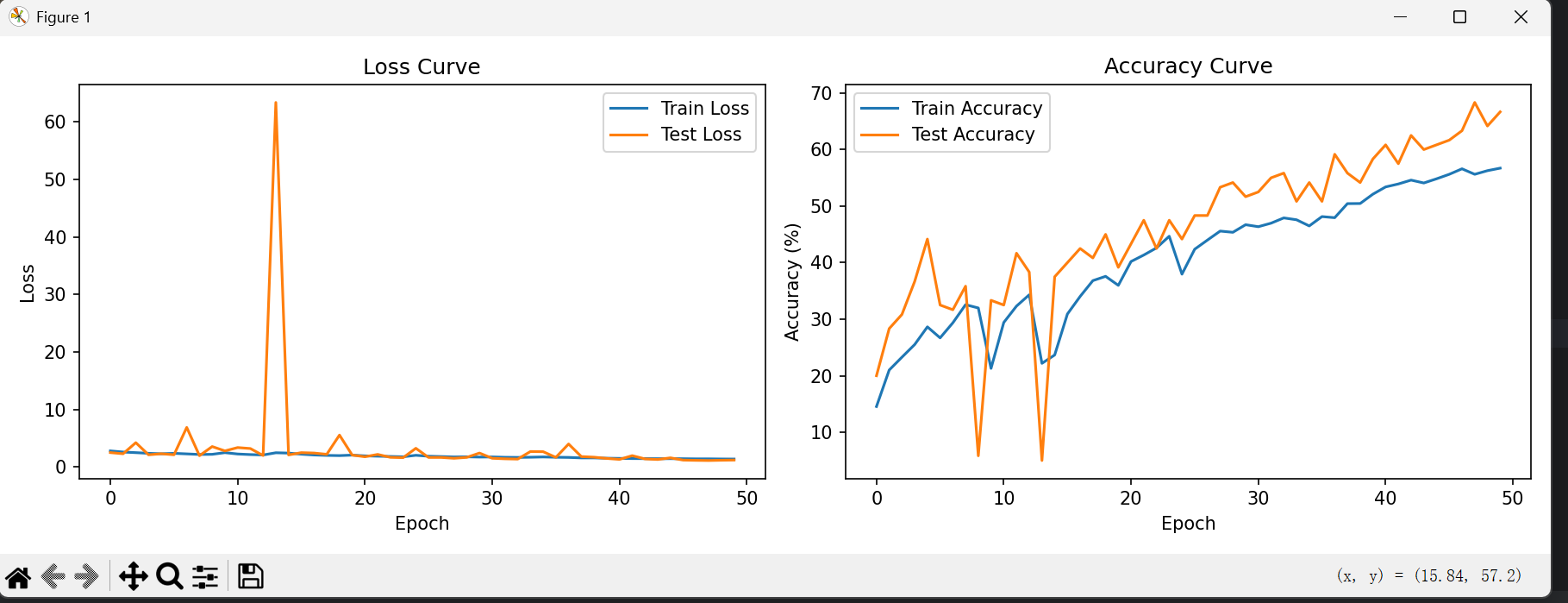
所以我们需要在每一轮训练后都测试一次模型的准确率,比较前后的准确率,在最大准确率的时候通过 torch.save(model,'best_model.pt')保存模型,我们只需要在test()测试函数后面添加几行代码即可实现:
best_acc=0
def test(dataloader,model,loss_fn):global best_accmodel.eval()len_data=len(dataloader.dataset)correct,loss_sum=0,0num_batch=0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss_sum += loss_fn(pred, y).item()correct+=(pred.argmax(1)==y).type(torch.float).sum().item()num_batch+=1loss_avg=loss_sum/num_batchaccuracy=correct/len_dataprint(f'Accuracy:{100 * accuracy}%\nLoss Avg:{loss_avg}')if accuracy>best_acc:best_acc=accuracy# torch.save(model.state_dict(),'best_model.pt')torch.save(model,'best_model.pt')代码训练完成后我们将会得到一个best_model.pt文件(后缀pt或pth都行)
三.使用最优模型
我们只需要在创建模型后导入之前的保存的文件即可
model=CNN().to(device)
# model=model.load_state_dict(torch.load('best_model.pt'))
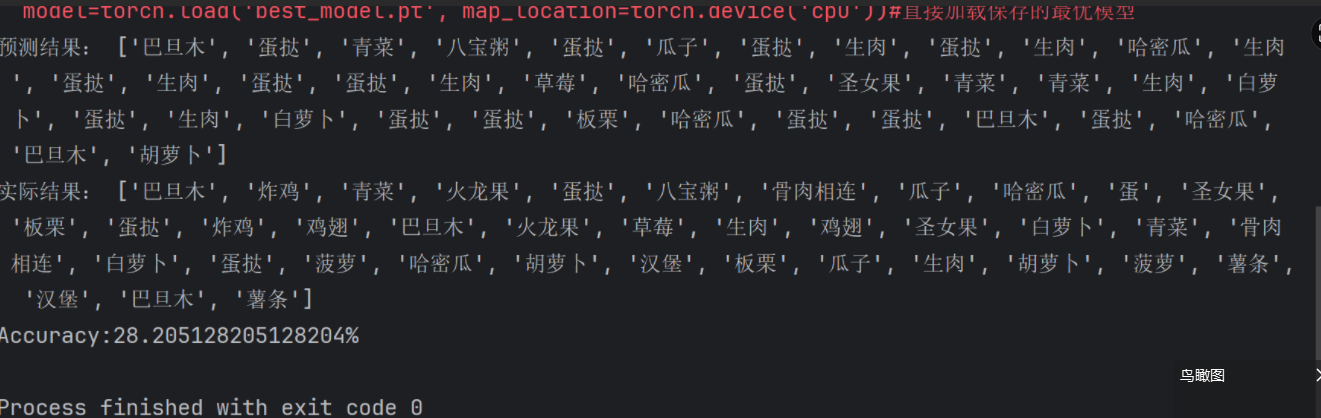
model=torch.load('best_model.pt')#直接加载保存的最优模型由于我们是直接导入最优模型,所以我们之前代码中的train(),test()方法,data_tranform字典中的‘train’项我们也不需要了,但是food_dataset类的定义必须存在,因为后续我们还要用数据集通过此类经过DataLoader传入模型来预测出食物类别,神经网络类CNN的定义也需要,因为我们是先实现神经网络类的创建再导入的最优模型,代码如下
import os
dire={}
def train_test_file(root,dir):f_out=open(dir+'.txt','w')path=os.path.join(root,dir)for root,directories,files in os.walk(path):if len(directories)!=0:dirs=directorieselse:now_dir=root.split('\\')for file in files:path=os.path.join(root,file)f_out.write(path+' '+str(dirs.index(now_dir[-1]))+'\n')dire[dirs.index(now_dir[-1])]=now_dir[-1]f_out.close()
root=r'.\food_dataset'
train_dir='train'
test_dir='test'
train_test_file(root,train_dir)
train_test_file(root,test_dir)
import torch
from torch.utils.data import Dataset,DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
data_transforms={'valid':#测试集只用标准化transforms.Compose([transforms.Resize([256,256]),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])
}
class food_dataset(Dataset):#能通过索引的方式返回图片数据和标签结果def __init__(self,file_path,transform=None):self.file_path=file_pathself.imgs_paths=[]self.labels=[]self.transform=transformwith open(self.file_path) as f:samples=[x.strip().split(' ') for x in f.readlines()]for img_path,label in samples:self.imgs_paths.append(img_path)self.labels.append(label)def __len__(self):return len(self.imgs_paths)def __getitem__(self, idx):image=Image.open(self.imgs_paths[idx])if self.transform:image=self.transform(image)label=self.labels[idx]label=torch.from_numpy(np.array(label,dtype=np.int64))#label也转化为tensorreturn image,labeldevice='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')from torch import nn
class CNN(nn.Module):def __init__(self):super().__init__()#nn.Sequential()是将网络层组合在一起,内部不能写函数self.conv1=nn.Sequential(#1*3*256*256nn.Conv2d(in_channels=3,#输入通道数out_channels=8,kernel_size=5,stride=1,padding=2),#1*8*256*256nn.ReLU(),nn.MaxPool2d(kernel_size=2)#1*8*128*128)self.conv2 = nn.Sequential(nn.Conv2d(8,16,5,1,2),#1*16*128*128nn.ReLU(),nn.Conv2d(16,32,5,1,2),#1*32*128*128nn.ReLU(),nn.MaxPool2d(kernel_size=2)##1*32*64*64)self.conv3 = nn.Sequential(nn.Conv2d(32,64,5,1,2),#1*64*64*64nn.ReLU(),nn.Conv2d(64, 64, 5, 1, 2),#1*64*64*64nn.ReLU())# self.flatten=nn.Flatten()self.out=nn.Linear(64*64*64,20)def forward(self,x):x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=x.view(x.size(0),-1)# x=self.flatten(x)output=self.out(x)return outputmodel=CNN().to(device)
# model=model.load_state_dict(torch.load('best_model.pt'))
model=torch.load('best_model.pt', map_location=torch.device('cpu'))#直接加载保存的最优模型最后我们自己再写一个测试,预测出每个图片是什么食物,测试代码仿照之前的test()方法写即可
然后将真实结果和以讹传讹结果都答打印出来
#预测
model.eval()
res=[]
true_res=[]
with torch.no_grad():len_data = len(test_loader.dataset)correct= 0with torch.no_grad():for X, y in test_loader:X, y = X.to(device), y.to(device)pred = model(X)b=pred.argmax(1).item()res.append(dire[pred.argmax(1).item()])a=y.item()true_res.append(dire[y.item()])correct += (pred.argmax(1) == y).type(torch.float).sum().item()accuracy = correct / len_dataprint('预测结果:',res)print('实际结果:', true_res)print(f'Accuracy:{100 * accuracy}%')