MySQL 8.0.40 主从复制完整实验总结(基础搭建 + 进阶延时同步与误操作恢复)
一、环境准备
主从复制的前提是确保基础环境一致且网络互通,以下是本次实操的环境信息及前置要求。
1.1 环境信息表
| 主机名 | ip地址 | 操作系统 | mysql版本 |
|---|---|---|---|
| mysql-master | 192.168.2.102 | rhel7.9 | 源码安装mysql8.0.40 |
| mysql-slave1 | 192.168.2.104 | rhel7.9 | 源码安装mysql8.0.40 |
1.2 前置条件说明(生产必看)
在开始配置前,需确保以下条件已满足,否则可能导致复制失败:
- MySQL 已正常安装:主从库均已完成 MySQL 8.0.40 源码安装,且能通过/etc/init.d/mysqld start正常启动(源码安装需提前配置好服务脚本)。
- 网络互通:主库(192.168.2.102)与从库(192.168.2.104)之间能 ping 通,且主库已开放 3306 端口(MySQL 默认端口),关闭安全组件,或者开放3306端口。
- 时间同步:主从库时间需一致(误差建议≤1 秒),否则会导致 binlog 时间戳异常,影响复制。
二、主库(mysql-master)配置步骤
主库的核心作用是记录二进制日志(binlog),并允许从库通过复制账号读取 binlog。以下是完整配置流程:
2.1 步骤 1:创建数据备份目录
主库需存储全量备份文件,先创建专用备份目录:
[root@mysql-master ~]# mkdir -p /server/backup
2.2 步骤 2:配置 MySQL 主配置文件(my.cnf)
MySQL 的主从复制依赖my.cnf(主配置文件)中的关键参数,需编辑该文件启用 binlog 并设置唯一标识:
[root@mysql-master ~]# vim /etc/my.cnf
[mysqld]
# MySQL数据存储目录(需与实际安装路径一致,源码安装默认可能为/usr/local/mysql/data,本文为自定义路径)
datadir=/data/mysql
# MySQL socket文件路径,用于本地进程通信
socket=/data/mysql/mysql.sock
# 主库唯一标识(必填,取值1-4294967295,主从库必须不同,此处用IP最后一段102便于记忆)
server_id=102
# 启用二进制日志(主从复制核心,日志文件前缀为binlog,文件会生成在datadir目录下)
log-bin=binlog
# 不记录binlog的数据库(系统库+测试库,减少binlog体积,避免无用同步)
binlog_ignore_db="information_schema"
binlog_ignore_db="mysql"
binlog_ignore_db="test"
2.3 步骤 3:重启 MySQL 服务并验证配置
修改my.cnf后需重启 MySQL 服务,使配置生效,同时验证server_id是否正确:
# 重启MySQL服务(源码安装的服务脚本路径,需与实际一致)
[root@mysql-master ~]# /etc/init.d/mysqld restart
Shutting down MySQL. SUCCESS!
Starting MySQL. SUCCESS!
# 登录MySQL,验证server_id是否为102(主库配置值)
[root@mysql-master ~]# mysql -uroot -p -e"select @@server_id;"
Enter password:
+-------------+
| @@server_id |
+-------------+
| 102 |
+-------------+
2.4 步骤 4:准备测试数据(创建数据库 + 表 + 插入数据)
为验证后续复制效果,需在主库创建测试数据库(school)、表(student)并插入数据:
[root@mysql-master ~]# mysql -uroot -p
Enter password: mysql> create database school;
Query OK, 1 row affected (0.00 sec)mysql> use school
Database changed
mysql> create table student(id int(10) not NuLL unique primary key, name varchar(20) not NULL, sex varchar(4), birth year, department varchar(20), address varchar(50));
Query OK, 0 rows affected, 1 warning (0.01 sec)mysql> insert student values(901,'张三丰','男',2002,'计算机系','北京市海淀区');insert student values(904,'李广昌','男',1999,'英语系','辽宁省皋新市');
insert student values(905,'王翰','男',2004,'英语系','福建省厦门市');
insert student values(906,'王心凌','女',1998,'计算机系','湖南省衡阳市');Query OK, 1 row affected (0.01 sec)mysql> insert student values(902,'周全有','男',2000,'中文系','北京市昌平区');
Query OK, 1 row affected (0.00 sec)mysql> insert student values(903,'张思维','女',2003,'中文系','湖南省永州市');
Query OK, 1 row affected (0.00 sec)mysql> insert student values(904,'李广昌','男',1999,'英语系','辽宁省皋新市');
Query OK, 1 row affected (0.00 sec)mysql> insert student values(905,'王翰','男',2004,'英语系','福建省厦门市');
Query OK, 1 row affected (0.00 sec)mysql> insert student values(906,'王心凌','女',1998,'计算机系','湖南省衡阳市');
Query OK, 1 row affected (0.00 sec)mysql> select * from student-> ;
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 901 | 张三丰 | 男 | 2002 | 计算机系 | 北京市海淀区 |
| 902 | 周全有 | 男 | 2000 | 中文系 | 北京市昌平区 |
| 903 | 张思维 | 女 | 2003 | 中文系 | 湖南省永州市 |
| 904 | 李广昌 | 男 | 1999 | 英语系 | 辽宁省皋新市 |
| 905 | 王翰 | 男 | 2004 | 英语系 | 福建省厦门市 |
| 906 | 王心凌 | 女 | 1998 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
6 rows in set (0.00 sec)
2.5 步骤 5:创建复制专用账号并授权
从库需通过一个专用账号连接主库读取 binlog,该账号只需replication slave权限(最小权限原则,提升安全性):
-- 创建复制账号rep,允许从任何IP连接(%表示所有IP,生产建议限定从库IP,如'192.168.2.104')
mysql> create user 'rep'@'%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
-- 授予rep账号复制权限(replication slave是复制必需的最小权限)
mysql> grant replication slave on *.* to 'rep'@'%';
Query OK, 0 rows affected (0.00 sec)
-- 验证权限是否正确授予
mysql> show grants for 'rep'@'%';
+---------------------------------------------+
| Grants for rep@% |
+---------------------------------------------+
| GRANT REPLICATION SLAVE ON *.* TO `rep`@`%` |
+---------------------------------------------+
1 row in set (0.00 sec)
2.6 步骤 6:锁定主库表,防止数据变更
全量备份主库数据前,需锁定所有表(仅允许读,禁止写),避免备份过程中数据不一致:
mysql> flush tables with read lock;
Query OK, 0 rows affected (0.00 sec)
2.7 步骤 7:查看主库 binlog 状态(关键信息!必记录)
查看主库当前的 binlog 文件名和位置(从库需通过这两个参数定位主库的 binlog,实现增量同步):
mysql> create database score;
ERROR 1223 (HY000): Can't execute the query because you have a conflicting read lockmysql> show master status;
+---------------+----------+--------------+-------------------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+-------------------------------+-------------------+
| binlog.000003 | 687 | | information_schema,mysql,test | |
+---------------+----------+--------------+-------------------------------+-------------------+
1 row in set (0.00 sec)
- 关键信息记录:
- File:当前主库正在写入的 binlog 文件名,本文为binlog.000003;
- Position:当前 binlog 的偏移量,本文为687;
- 后续从库配置需用到这两个值,务必准确记录(若主库重启或执行flush logs,这两个值会变化,需重新获取)。
2.8 步骤 8:全量备份主库数据
通过mysqldump工具全量备份主库所有数据(含结构 + 数据),并压缩存储(减少文件体积,便于传输):
# 全量备份主库数据,压缩后存储到/server/backup目录
[root@mysql-master ~]# mysqldump -uroot -p -A -B | gzip > /server/backup/mysql_bak.$(date +%F).sql.gz
Enter password:
[root@mysql-master ~]# ll /server/backup/
总用量 276
-rw-r--r-- 1 root root 278926 9月 3 17:08 mysql_bak.2025-09-03.sql.gz
2.9 步骤 9:解锁主库表,恢复正常写入
备份完成后,解锁主库表,允许业务正常写入数据:
# 解锁表
mysql> unlock tables;
2.10 步骤 10:同步备份文件到从库
将主库的全量备份文件通过scp命令传到从库的/server/backup目录(从库需提前创建该目录):
[root@mysql-master ~]# scp /server/backup/mysql_bak.2025-09-03.sql.gz 192.168.2.104:/server/backup
root@192.168.2.104's password:
mysql_bak.2025-09-03.sql.gz 100% 272KB 75.2MB/s 00:00 #来到从库查看是否已经上传
[root@mysql-slave1 ~]# ll /server/backup/
总用量 276
-rw-r--r-- 1 root root 278926 9月 3 17:10 mysql_bak.2025-09-03.sql.gz三、从库(mysql-slave1)配置步骤
从库的核心作用是读取主库的 binlog,并重放日志实现数据同步。以下是完整配置流程:
3.1 步骤 1:配置 MySQL 主配置文件(my.cnf)
从库需设置唯一的server_id(与主库不同),若后续需搭建 “级联复制”(从库作为其他从库的主库),可启用 binlog(本文仅需基础主从,启用 binlog 更灵活):
- 在[mysqld]模块下添加 / 修改以下参数:
[root@mysql-slave1 ~]# vim /etc/my.cnf
[mysqld]
# 从库数据存储目录(需与实际安装路径一致,与主库保持相同结构)
datadir=/data/mysql
# 从库socket文件路径
socket=/data/mysql/mysql.sock
# 从库唯一标识(必须≠主库的102,此处用IP最后一段104便于记忆)
server_id=104
# 启用binlog(可选,若后续从库需作为其他从库的主库,必须启用;基础主从可省略,但建议保留)
log-bin=binlog
[root@mysql-slave1 ~]# /etc/init.d/mysqld restart
Shutting down MySQL. SUCCESS!
Starting MySQL. SUCCESS!
3.2步骤 2:解压备份文件并恢复从库数据
将主库的全量备份文件解压,然后恢复到从库,确保从库初始数据与主库一致:
[root@mysql-slave1 backup]# ls
mysql_bak.2025-09-03.sql.gz
[root@mysql-slave1 backup]# gzip -d mysql_bak.2025-09-03.sql.gz
# 恢复数据到从库(通过mysql命令执行备份SQL)
[root@mysql-slave1 backup]# mysql -uroot -p < mysql_bak.2025-09-03.sql
Enter password:
[root@mysql-slave1 backup]# mysql -uroot -p -e "select * from school.student;"
Enter password:
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 901 | 张三丰 | 男 | 2002 | 计算机系 | 北京市海淀区 |
| 902 | 周全有 | 男 | 2000 | 中文系 | 北京市昌平区 |
| 903 | 张思维 | 女 | 2003 | 中文系 | 湖南省永州市 |
| 904 | 李广昌 | 男 | 1999 | 英语系 | 辽宁省皋新市 |
| 905 | 王翰 | 男 | 2004 | 英语系 | 福建省厦门市 |
| 906 | 王心凌 | 女 | 1998 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
- 恢复说明:由于备份文件包含CREATE DATABASE和USE语句(主库备份时加了-B参数),恢复后从库会自动创建school数据库及student表,并插入与主库一致的数据。
3.3 步骤 3:配置从库复制参数(关键!关联主库)
在从库 MySQL 中执行change master to命令,配置主库信息(含主库 IP、复制账号、binlog 文件名及位置),建立主从关联:
[root@mysql-slave1 backup]# mysql -uroot -p
mysql> CHANGE REPLICATION SOURCE TO-> SOURCE_HOST='192.168.2.102', -- 主库IP地址-> SOURCE_USER='REP', -- 主库创建的复制账号-> SOURCE_PASSWORD='123456', -- 复制账号密码-> SOURCE_LOG_FILE='binlog.000003', -- 主库show master status输出的File值-> SOURCE_LOG_POS=3277, -- 主库show master status输出的Position值-> SOURCE_SSL=1;
Query OK, 0 rows affected, 2 warnings (0.00 sec)mysql> start replica;
Query OK, 0 rows affected (0.01 sec)mysql> show replica status \G;
*************************** 1. row ***************************Replica_IO_State: Waiting for source to send eventSource_Host: 192.168.2.102Source_User: repSource_Port: 3306Connect_Retry: 60Source_Log_File: binlog.000003Read_Source_Log_Pos: 3277Relay_Log_File: mysql-slave1-relay-bin.000002Relay_Log_Pos: 323Relay_Source_Log_File: binlog.000003Replica_IO_Running: YesReplica_SQL_Running: Yes
- 核心验证指标(必须满足):
- Slave_IO_Running: Yes:IO 线程正常(负责从主库读取 binlog 到从库的 relay log);
- Slave_SQL_Running: Yes:SQL 线程正常(负责重放 relay log 中的 SQL 语句,同步数据);
- Last_IO_Error和Last_SQL_Error:均为空(无错误);
- Seconds_Behind_Master: 0:主从无延迟
3.4步骤4:主从复制功能验证
搭建完成后,建议在主库执行数据变更,验证从库是否能自动同步:
#主库
[root@mysql-master ~]# mysql -uroot -p
mysql> create database t1;
Query OK, 1 row affected (0.00 sec)#从库
[root@mysql-slave1 backup]# mysql -uroot -p123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| school |
| sys |
| t1 |
+--------------------+
6 rows in set (0.00 sec)
四、主从复制进阶:延时同步配置与误操作数据恢复实操
1、停止从库复制进程
配置延时前需先停止从库的复制进程(避免动态修改参数冲突):
mysql> stop replica;
Query OK, 0 rows affected (0.01 sec)
- 命令解释:stop replica会同时停止从库的IO 线程(读取主库 binlog)和SQL 线程(重放 relay log),确保参数修改生效。
2、配置延时参数(SOURCE_DELAY)
通过CHANGE REPLICATION SOURCE设置从库 SQL 线程延迟 300 秒重放 relay log:
#配置从库延时同步,设置sql线程延迟300秒后读取relay log
mysql> stop replica;
Query OK, 0 rows affected (0.01 sec)mysql> CHANGE REPLICATION SOURCE TO SOURCE_DELAY = 300;
Query OK, 0 rows affected (0.00 sec)mysql> start replica;
Query OK, 0 rows affected (0.02 sec)mysql> show replica status\G
SQL_Delay: 300
3、主库误操作模拟(删库场景)
为验证延时同步的 “缓冲期” 价值,我们在主库模拟典型误操作:创建测试库表→插入数据→误删除库,步骤如下:
3.1 主库创建测试库表并插入数据
#主库上创建库和表
mysql> create database score;
Query OK, 1 row affected (0.01 sec)mysql> use score
Database changed
mysql> create table score(id int(10) not null unique primary key auto_increment, stu_id int(10)not null,c_name varchar(20),grade int(10));
Query OK, 0 rows affected, 3 warnings (0.01 sec)mysql> insert into score values(null,901,'计算机',98);
o score values(null,904,'计算机',70);
insert into score values(null,904,'英语',92);
insert into score values(null,905,'英语',94);
insert into score values(null,906,'计算机',49);
insert into score values(null,906,'英语',83);Query OK, 1 row affected (0.00 sec)mysql> insert into score values(null,901,'英语',80);
Query OK, 1 row affected (0.00 sec)mysql> insert into score values(null,902,'计算机',65);
Query OK, 1 row affected (0.00 sec)mysql> insert into score values(null,902,'中文',88);
Query OK, 1 row affected (0.00 sec)mysql> insert into score values(null,903,'中文',95);
Query OK, 1 row affected (0.01 sec)mysql> insert into score values(null,904,'计算机',70);
Query OK, 1 row affected (0.00 sec)mysql> insert into score values(null,904,'英语',92);
Query OK, 1 row affected (0.00 sec)mysql> insert into score values(null,905,'英语',94);
Query OK, 1 row affected (0.00 sec)mysql> insert into score values(null,906,'计算机',49);
Query OK, 1 row affected (0.00 sec)mysql> insert into score values(null,906,'英语',83);
Query OK, 1 row affected (0.00 sec)mysql> select * from score-> ;
+----+--------+-----------+-------+
| id | stu_id | c_name | grade |
+----+--------+-----------+-------+
| 1 | 901 | 计算机 | 98 |
| 2 | 901 | 英语 | 80 |
| 3 | 902 | 计算机 | 65 |
| 4 | 902 | 中文 | 88 |
| 5 | 903 | 中文 | 95 |
| 6 | 904 | 计算机 | 70 |
| 7 | 904 | 英语 | 92 |
| 8 | 905 | 英语 | 94 |
| 9 | 906 | 计算机 | 49 |
| 10 | 906 | 英语 | 83 |
+----+--------+-----------+-------+
10 rows in set (0.00 sec)
3.2 主库模拟误操作(删除 score 库)
mysql> drop database score;
Query OK, 1 row affected (0.01 sec)
- 此时主库的score库已删除,但由于从库配置了 300 秒延时,SQL 线程尚未执行drop database命令,这是恢复数据的关键窗口期。
4、从库数据恢复实操(核心步骤)
恢复的核心逻辑:停止从库 SQL 线程→从 relay log 中提取 “误操作前的有效数据”→恢复数据→重置复制位置避免再次执行误操作。
前置:定位恢复范围(关键!)
从库的中继日志(relay log) 已完整记录主库的所有操作(包括create database、insert、drop database),需先通过mysqlbinlog工具查看 relay log,定位 “误操作(drop)的位置 / 时间”,从而确定恢复范围(仅恢复 drop 前的操作)。
4.1 查看从库当前 relay log 信息
回到从库
mysql> show replica status\GSQL_Delay: 300SQL_Remaining_Delay: 164
#在sql线程延迟300秒时间内发现误删除数据库则立马停止从库的sql线程
mysql> stop slave sql_thread;
Query OK, 0 rows affected, 1 warning (0.01 sec)
#找到误删前relay log的起点和终点
mysql> show replica status\G
*************************** 1. row ***************************Replica_IO_State: Waiting for source to send eventSource_Host: 192.168.2.102Source_User: repSource_Port: 3306Connect_Retry: 60Source_Log_File: binlog.000003Read_Source_Log_Pos: 7328Relay_Log_File: mysql-slave1-relay-bin.000002Relay_Log_Pos: 323
4.2 解析 relay log,定位误操作位置
通过mysqlbinlog工具解析 relay log,查看drop database score的具体位置(或时间):
[root@mysql-slave1 mysql]# mysqlbinlog /data/mysql/mysql-slave1-relay-bin.000002 --base64-output=DECODE-ROWS -vv
#会看到输出以下内容
- 命令解释:
- /data/mysql/mysql-slave1-relay-bin.000002:relay log 文件路径(从show replica status获取);
- –base64-output=DECODE-ROWS:将 binlog 中的 base64 编码内容解码为可读的 SQL 语句;
- -vv:输出详细信息(含操作时间、位置、SQL 语句)
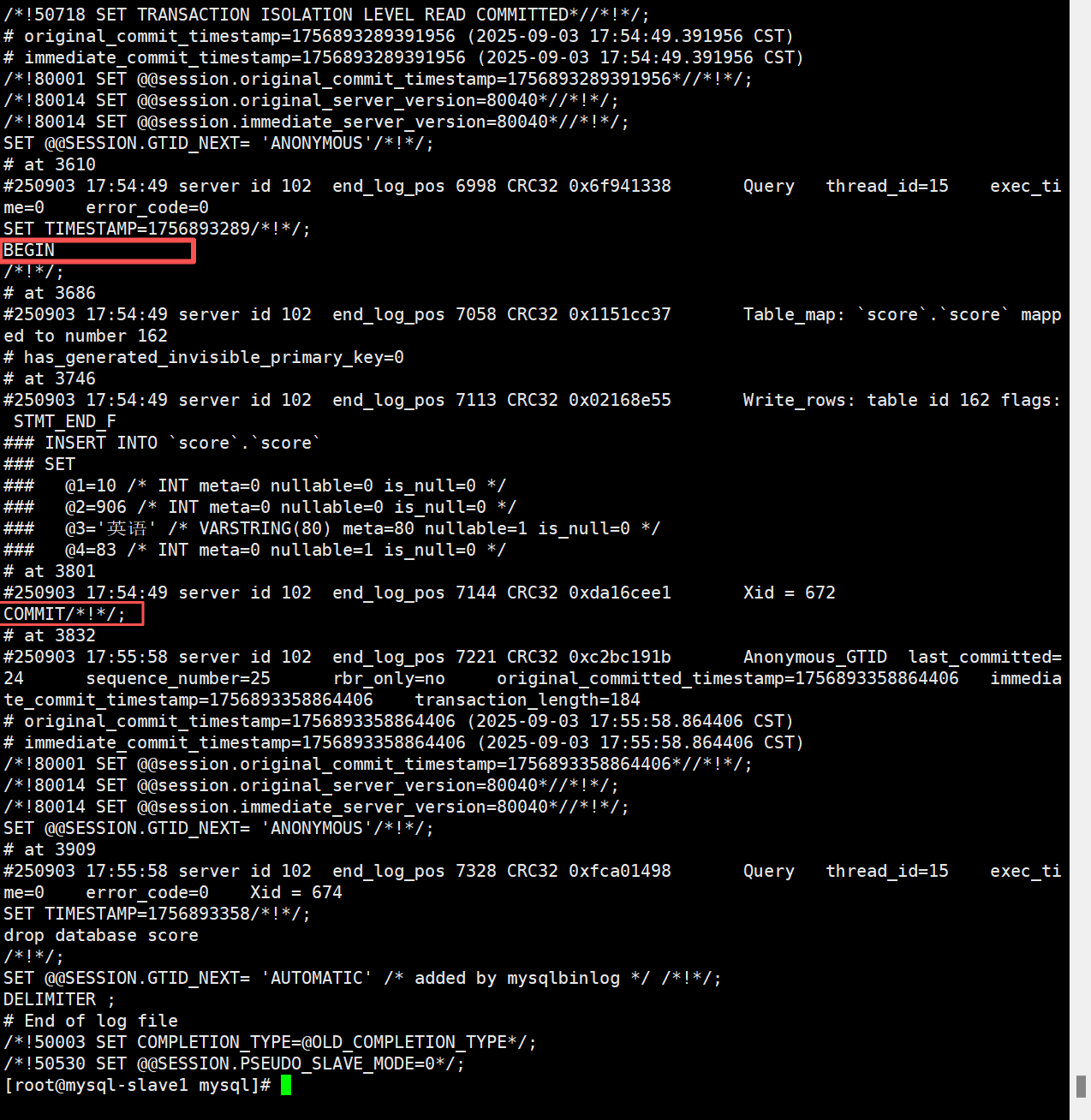
解析结果关键信息(对应原文图片内容)
解析后会看到类似以下内容,需重点记录:
at 3832 # drop database命令的起始位置
#250903 17:56:10 server id 102 end_log_pos 3879 Query thread_id=12 exec_time=0 error_code=0
use `score`/*!*/;
SET TIMESTAMP=1725326170/*!*/;
drop database score # 误操作SQL
/*!*/;
- 核心信息记录:
- 有效操作范围:从Relay_Log_Pos=323(初始位置)到3832(drop 命令起始位置前);
- 有效操作时间:从 “插入数据的时间(如 17:54:28)” 到 “drop 命令时间(17:56:10)” 前。
方法 1:基于位置点增量恢复(精准恢复)
适合明确知道误操作在 relay log 中的具体位置的场景,恢复精度最高(推荐优先使用)。
步骤 1:停止从库 SQL 线程(阻断误操作)
# 从库执行,仅停止SQL线程(IO线程可继续读取主库binlog,不影响后续同步)
mysql> stop replica sql_thread;
Query OK, 0 rows affected, 1 warning (0.01 sec)
步骤 2:生成 “有效操作” 的恢复 SQL
从 relay log 中提取 “323~3832 位置” 的 SQL(即 drop 前的所有操作),输出到指定文件:
[root@mysql-slave1 mysql]# mysqlbinlog mysql-slave1-relay-bin.000002 \ --start-position=323 \ # 恢复起始位置(relay log初始位置)
--stop-position=3832 \ # 恢复结束位置(drop命令前)-r /opt/pos.sql # 输出到/opt/pos.sql文件
步骤 3:执行恢复 SQL且验证恢复结果
[root@mysql-slave1 mysql]# mysql -uroot -p#调用恢复
mysql> source /opt/pos.sql
mysql> select * from score.score;
+----+--------+-----------+-------+
| id | stu_id | c_name | grade |
+----+--------+-----------+-------+
| 1 | 901 | 计算机 | 98 |
| 2 | 901 | 英语 | 80 |
| 3 | 902 | 计算机 | 65 |
| 4 | 902 | 中文 | 88 |
| 5 | 903 | 中文 | 95 |
| 6 | 904 | 计算机 | 70 |
| 7 | 904 | 英语 | 92 |
| 8 | 905 | 英语 | 94 |
| 9 | 906 | 计算机 | 49 |
| 10 | 906 | 英语 | 83 |
+----+--------+-----------+-------+
10 rows in set (0.00 sec)
- 结果说明:数据完全恢复,证明基于位置的恢复成功。
方法 2:基于时间点增量恢复(灵活恢复)
适合不知道具体位置,但明确误操作的大致时间的场景(如记得 “17:56 左右误删库”)。
步骤 1:清理测试环境(模拟新场景)
先删除从库已恢复的score库,模拟 “首次发现误操作” 的场景:
mysql> drop database score;
mysql> exit
步骤 2:生成 “有效时间范围” 的恢复 SQL
根据解析 relay log 得到的 “有效时间范围(17:54:28~17:55:58)”,提取该时间段的 SQL:
[root@mysql-slave1 mysql]# mysqlbinlog /data/mysql/mysql-slave1-relay-bin.000002 --base64-output=DECODE-ROWS -vv
[root@mysql-slave1 mysql]# mysqlbinlog mysql-slave1-relay-bin.000002 \
--start-datetime="2025-09-03 17:54:28" \ # 恢复起始时间(首条insert时间)
--stop-datetime="2025-09-03 17:55:58" \ # 恢复结束时间(drop前12秒)
-r /opt/time.sql # 输出到/opt/time.sql文件
注意:时间格式必须为YYYY-MM-DD HH:MM:SS,且建议比实际误操作时间提前几秒(避免遗漏)。
步骤 2:执行恢复并验证
[root@mysql-slave1 mysql]# mysql -uroot -p
mysql> source /opt/time.sql
mysql> select * from score.score;
+----+--------+-----------+-------+
| id | stu_id | c_name | grade |
+----+--------+-----------+-------+
| 1 | 901 | 计算机 | 98 |
| 2 | 901 | 英语 | 80 |
| 3 | 902 | 计算机 | 65 |
| 4 | 902 | 中文 | 88 |
| 5 | 903 | 中文 | 95 |
| 6 | 904 | 计算机 | 70 |
| 7 | 904 | 英语 | 92 |
| 8 | 905 | 英语 | 94 |
| 9 | 906 | 计算机 | 49 |
| 10 | 906 | 英语 | 83 |
+----+--------+-----------+-------+
10 rows in set (0.00 sec)
步骤 3:恢复后关键操作:重置复制位置
数据恢复后,若直接重启从库 SQL 线程,会再次执行 relay log 中的drop database命令(导致数据丢失)。需重置复制位置,跳过误操作:
# 从库执行,重置SQL线程到“drop命令后的位置(如3879)”
mysql> CHANGE REPLICATION SOURCE TOSOURCE_LOG_FILE='mysql-slave1-relay-bin.000002', # 当前relay log文件名SOURCE_LOG_POS=3879; # drop命令结束后的位置(从relay log解析获取)
Query OK, 0 rows affected (0.00 sec)# 重启SQL线程,恢复正常同步
mysql> start replica sql_thread;
Query OK, 0 rows affected (0.00 sec)
- 原理:让 SQL 线程从 “drop 命令之后” 开始重放,避免再次执行误操作。
总结
在生产里用MySQL主从搞增量备份,常靠“解除从库身份”和“主从调换”这两种操作,都不用停业务、不占主库资源,还能保数据完整,具体咋玩:
前者适合主库写业务特忙、腾不出资源备份的情况——先确认从库和主库数据完全同步,再停掉复制、重置从库的主库关联信息,让它变成独立数据库。之后直接用这独立库的binlog做增量备份,完全不影响主库干活,还能按天/按小时存多版备份。
后者更适合主库挂了或要升级维护的场景——先确认从库数据没问题,把它升成新主库;等原主库修好,再把它改成新从库同步新主库。这样业务几乎不停,而且原主库变从库后,还能接着用它同步的binlog做增量备份,一举两得。
其实俩操作都是利用从库和主库数据一致的特点,把从库当增量备份的“载体”,既不坑主库性能,又能应对不同生产情况。