Spring Boot集成Kafka常见业务场景最佳实践实战指南
一、基础集成与核心组件解析
(一)环境搭建与依赖配置
在 Spring Boot 项目中集成 Kafka,首先需通过 Maven 添加核心依赖:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
在application.properties或application.yml中配置 Kafka 连接参数,包括服务地址、序列化器、消费者组等关键信息,确保生产者与消费者能正确连接 Kafka 集群。例如在application.properties中:
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=my-group
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
上述配置中,spring.kafka.bootstrap-servers指定了 Kafka 服务器的地址和端口;spring.kafka.consumer.group-id设置了消费者组 ID,同一消费者组内的消费者会均衡消费主题中的消息;序列化器和反序列化器则决定了消息在发送和接收时如何进行数据格式转换,这里使用StringSerializer和StringDeserializer处理字符串类型的消息 。
(二)生产者核心实现
利用 Spring 提供的KafkaTemplate实现消息发送,支持同步与异步发送模式。同步发送时,send方法会阻塞当前线程,直到消息发送完成;异步发送时,send方法会立即返回,通过ListenableFuture和Callback处理发送结果,实现可靠的消息发送机制。示例代码如下:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
@Service
public class KafkaProducerService {
private static final String TOPIC = "test-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessageSync(String message) {
kafkaTemplate.send(TOPIC, message);
}
public void sendMessageAsync(String message) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(TOPIC, message);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("Message sent successfully: " + result.getRecordMetadata());
}
@Override
public void onFailure(Throwable ex) {
System.out.println("Failed to send message: " + ex.getMessage());
}
});
}
}
在上述代码中,sendMessageSync方法为同步发送消息,直接调用kafkaTemplate.send方法;sendMessageAsync方法为异步发送消息,发送后通过addCallback方法添加回调函数,在消息发送成功或失败时分别执行相应的逻辑,这样可以在不阻塞主线程的情况下,对消息发送结果进行处理,提高系统的响应性能 。
(三)消费者核心实现
通过@KafkaListener注解监听指定主题,支持单条消息处理与批量消息处理。手动提交偏移量模式下,结合Acknowledgment确保消息处理的可靠性,避免重复消费或丢失。示例代码如下:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
@KafkaListener(topics = "test-topic", groupId = "my-group")
public void handleMessage(ConsumerRecord<String, String> record) {
System.out.println("Received message: " + record.value());
}
@KafkaListener(topics = "test-topic", groupId = "my-group", ackMode = "MANUAL")
public void handleMessageWithManualAck(ConsumerRecord<String, String> record, Acknowledgment ack) {
try {
System.out.println("Received message for manual ack: " + record.value());
// 执行业务逻辑
// 业务逻辑处理成功后手动提交偏移量
ack.acknowledge();
} catch (Exception e) {
// 处理异常,可选择重试或记录日志等操作
}
}
}
在handleMessage方法中,使用@KafkaListener监听test-topic主题的消息,当有消息到达时,会自动调用该方法处理单条消息;在handleMessageWithManualAck方法中,设置了ackMode = "MANUAL"开启手动提交偏移量模式,Acknowledgment参数用于在消息处理完成后手动提交偏移量,保证消息被正确处理后才更新消费进度,防止因处理过程中出现异常导致消息丢失或重复消费 。
二、常见业务场景实战解析
(一)异步解耦:订单系统事件驱动架构
在电商系统中,订单的创建往往会触发一系列后续操作,如库存扣减、物流通知以及积分计算等 。传统的同步处理方式会导致接口响应时间长,系统耦合度高,维护困难。借助 Kafka 实现异步解耦,能有效提升系统的可扩展性与响应速度。
首先,定义订单事件类,用于封装订单相关信息,例如:
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import java.io.Serializable;
import java.time.LocalDateTime;
@Data
public class OrderEvent implements Serializable {
private static final long serialVersionUID = 1L;
private String orderId;
private String userId;
private double amount;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime createTime;
}
生产者在订单创建后,将订单事件发送到 Kafka 的order-topic主题:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
@Service
public class OrderProducer {
private static final String TOPIC = "order-topic";
@Autowired
private KafkaTemplate<String, OrderEvent> kafkaTemplate;
public void sendOrderEvent(OrderEvent orderEvent) {
kafkaTemplate.send(TOPIC, orderEvent);
}
}
库存服务作为消费者监听order-topic主题,处理库存扣减逻辑:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class InventoryConsumer {
@KafkaListener(topics = "order-topic", groupId = "inventory-group")
public void handleOrder(ConsumerRecord<String, OrderEvent> record) {
OrderEvent orderEvent = record.value();
System.out.println("处理库存扣减:订单" + orderEvent.getOrderId() + ",用户" + orderEvent.getUserId());
// 实际调用库存服务接口进行扣减
boolean success = deductStock(orderEvent.getOrderId());
if (!success) {
// 处理失败,可发送到死信队列或进行重试
throw new RuntimeException("库存扣减失败");
}
}
private boolean deductStock(String orderId) {
// 模拟库存扣减逻辑,返回操作结果
// 实际应用中会调用真实的库存服务接口
return true;
}
}
物流服务同样监听order-topic主题,处理物流通知逻辑:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class LogisticsConsumer {
@KafkaListener(topics = "order-topic", groupId = "logistics-group")
public void handleLogistics(ConsumerRecord<String, OrderEvent> record) {
OrderEvent orderEvent = record.value();
System.out.println("处理物流通知:订单" + orderEvent.getOrderId() + ",用户" + orderEvent.getUserId());
// 调用物流API创建运单等操作
createWaybill(orderEvent.getOrderId());
}
private void createWaybill(String orderId) {
// 模拟创建运单逻辑
System.out.println("已为订单 " + orderId + " 创建运单");
}
}
通过这种方式,订单创建服务与库存服务、物流服务之间实现了解耦 。订单创建后,只需将事件发送到 Kafka,后续的处理由各个服务异步完成,互不干扰,提升了系统的整体性能和可维护性 。
(二)流量削峰:秒杀系统流量缓冲
在秒杀活动等高并发场景下,瞬间涌入的大量请求极易使系统因负载过高而崩溃,数据库也可能因承受不住压力而出现响应缓慢甚至宕机的情况 。Kafka 作为流量缓冲层,能够有效缓解系统在高并发时的压力,保障系统的稳定性。
当用户发起秒杀请求时,生产者将订单请求批量发送到 Kafka 的seckill-topic主题 。例如:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class SeckillProducer {
private static final String TOPIC = "seckill-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendSeckillOrders(List<String> orders) {
for (String order : orders) {
kafkaTemplate.send(TOPIC, order);
}
}
}
消费者从seckill-topic主题消费订单请求,根据系统处理能力控制消费速率 。关键在于合理配置消费者的max.poll.records(单次拉取最大消息数)与max.poll.interval.ms(拉取间隔超时时间)参数 。示例配置如下:
spring.kafka.consumer.max-poll-records=100
spring.kafka.consumer.max-poll-interval-ms=300000
同时,要根据预估的并发量和系统处理能力,合理设置 Kafka 主题的分区数 。假设预估秒杀活动的并发量为 10000,系统每秒能处理 1000 个订单,可将分区数设置为 10,使消费者能并行消费消息,提高处理效率 。消费者代码示例如下:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import java.util.Optional;
@Service
public class SeckillConsumer {
@KafkaListener(topics = "seckill-topic", groupId = "seckill-group")
public void handleSeckillOrder(ConsumerRecord<String, String> record) {
Optional<String> kafkaMessage = Optional.ofNullable(record.value());
kafkaMessage.ifPresent(message -> {
System.out.println("处理秒杀订单:" + message);
// 执行秒杀业务逻辑,如扣减库存、更新订单状态等
processSeckillOrder(message);
});
}
private void processSeckillOrder(String order) {
// 模拟秒杀业务逻辑,如调用库存服务扣减库存,调用订单服务创建订单等
System.out.println("已处理秒杀订单:" + order);
}
}
通过 Kafka 的流量削峰,前端大量的秒杀请求先进入 Kafka 队列,消费者按照系统能承受的速率逐步处理,避免了数据库直接承受峰值压力,确保了秒杀活动的顺利进行 。
(三)日志收集:分布式系统日志聚合
在分布式系统中,各服务产生的日志分散在不同的节点上,给日志的集中管理、分析和监控带来了挑战 。利用 Kafka 构建统一的日志收集平台,能够实现日志的高效聚合与处理 。
各服务在运行过程中,将日志消息发送到 Kafka 的log-topic主题 。以 Spring Boot 应用为例,通过配置logback实现日志发送,在logback-spring.xml中添加如下配置:
<appender name="KAFKA" class="ch.qos.logback.classic.net.SyslogAppender">
<destination>localhost:9092</destination>
<syslogHost>logstash</syslogHost>
<port>514</port>
<facility>LOCAL0</facility>
<suffixPattern>[%thread] %-5level %logger{36} - %msg%n</suffixPattern>
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</Pattern>
</layout>
</encoder>
</appender>
<root level="info">
<appender-ref ref="KAFKA" />
</root>
消费者组从log-topic主题消费日志消息,分别处理日志存储和实时监控任务 。日志存储消费者将日志写入 Elasticsearch,实现日志的持久化存储与全文检索 。示例代码如下:
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.core.IndexRequest;
import co.elastic.clients.elasticsearch.core.IndexResponse;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import java.io.IOException;
@Service
public class LogStorageConsumer {
@Autowired
private ElasticsearchClient elasticsearchClient;
@KafkaListener(topics = "log-topic", groupId = "log-storage-group")
public void handleLogStorage(ConsumerRecord<String, String> record) {
String logMessage = record.value();
try {
IndexRequest<String> request = IndexRequest.of(i -> i
.index("logs")
.id(record.offset() + "")
.document(logMessage)
);
IndexResponse response = elasticsearchClient.index(request);
System.out.println("日志已写入Elasticsearch,结果:" + response.result());
} catch (IOException e) {
System.err.println("写入Elasticsearch失败:" + e.getMessage());
}
}
}
实时监控消费者负责实时监控日志,一旦发现异常日志,立即触发报警机制 。示例代码如下:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class LogMonitorConsumer {
@KafkaListener(topics = "log-topic", groupId = "log-monitor-group")
public void handleLogMonitor(ConsumerRecord<String, String> record) {
String logMessage = record.value();
if (logMessage.contains("ERROR")) {
// 发送报警通知,如邮件、短信等
sendAlarm(logMessage);
}
}
private void sendAlarm(String logMessage) {
System.out.println("触发报警:发现异常日志 - " + logMessage);
// 实际应用中会调用邮件、短信服务接口发送报警通知
}
}
Kafka 的持久化存储特性确保了日志在传输过程中不会丢失,多消费者组并行处理的模式满足了不同业务对日志的多样化需求 ,为分布式系统的运维和监控提供了有力支持 。
三、高级特性与最佳实践
(一)可靠性保障
- 生产者端:设置acks=-1要求所有副本确认消息,结合retries配置失败重试机制,确保消息成功发送到 Kafka 集群。在application.properties中配置生产者相关参数:
spring.kafka.producer.acks=-1
spring.kafka.producer.retries=3
acks=-1表示生产者在消息被所有副本确认后才会认为消息发送成功,极大地保证了消息不会因副本丢失而发送失败;retries指定了发送失败时的重试次数,当网络抖动等瞬时故障发生时,生产者可以自动重试发送消息,提高消息发送的成功率 。在KafkaProducerService中,异步发送消息时可以结合retries配置对发送结果进行更健壮的处理:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
@Service
public class KafkaProducerService {
private static final String TOPIC = "test-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessageAsync(String message) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(TOPIC, message);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("Message sent successfully: " + result.getRecordMetadata());
}
@Override
public void onFailure(Throwable ex) {
// 处理发送失败,结合retries配置进行日志记录或进一步处理
System.err.println("Failed to send message after retries: " + ex.getMessage());
}
});
}
}
- 消费者端:关闭自动提交偏移量,手动提交时结合业务处理结果,保证消息处理成功后再提交。引入死信队列(DLQ),通过DeadLetterPublishingRecoverer处理多次重试失败的消息,便于后续排查与处理。在application.properties中关闭自动提交偏移量:
spring.kafka.consumer.enable-auto-commit=false
在消费者代码中,手动提交偏移量:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
@KafkaListener(topics = "test-topic", groupId = "my-group", ackMode = "MANUAL")
public void handleMessageWithManualAck(ConsumerRecord<String, String> record, Acknowledgment ack) {
try {
System.out.println("Received message for manual ack: " + record.value());
// 执行业务逻辑
processBusinessLogic(record.value());
// 业务逻辑处理成功后手动提交偏移量
ack.acknowledge();
} catch (Exception e) {
// 处理异常,可选择重试或记录日志等操作
System.err.println("Failed to process message: " + e.getMessage());
}
}
private void processBusinessLogic(String message) {
// 模拟业务逻辑处理
System.out.println("Processing business logic for message: " + message);
}
}
配置死信队列,首先定义死信队列相关配置类:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.retrytopic.DeadLetterPublishingRecoverer;
import org.springframework.kafka.retrytopic.RepublishMessageRecoverer;
import org.springframework.kafka.retrytopic.RetryTopicConfiguration;
import org.springframework.retry.backoff.ExponentialBackOffPolicy;
import org.springframework.retry.policy.SimpleRetryPolicy;
import org.springframework.retry.support.RetryTemplate;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class KafkaDlqConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-dlq-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 配置重试策略
RetryTemplate retryTemplate = new RetryTemplate();
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy();
retryPolicy.setMaxAttempts(3);
retryTemplate.setRetryPolicy(retryPolicy);
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(1000);
backOffPolicy.setMultiplier(2);
retryTemplate.setBackOffPolicy(backOffPolicy);
// 配置死信队列
RepublishMessageRecoverer recoverer = new DeadLetterPublishingRecoverer(kafkaTemplate, (record, ex) -> {
// 可以根据异常类型或其他条件决定死信队列主题
return "dlq-topic";
});
factory.setRetryTemplate(retryTemplate);
factory.setRecoveryCallback(context -> {
recoverer.accept((org.apache.kafka.clients.consumer.ConsumerRecord<?, ?>) context.getAttribute("record"), (Exception) context.getLastThrowable());
return null;
});
return factory;
}
@Bean
public RetryTopicConfiguration retryTopicConfiguration() {
return RetryTopicConfigurationBuilder.newBuilder()
.fixed(3, "1000")
.dlt("dlq-topic")
.build();
}
}
通过上述配置,当消费者处理消息失败时,会根据重试策略进行重试,若达到最大重试次数仍失败,则消息会被发送到死信队列dlq-topic,方便后续对异常消息进行排查和处理 。
(二)性能优化策略
- 批量发送:配置producer.batch-size与linger.ms,攒够一定数量或等待一定时间后批量发送消息,减少网络 IO 开销。在application.properties中配置:
spring.kafka.producer.batch-size=16384
spring.kafka.producer.linger.ms=10
producer.batch-size指定了生产者批量发送消息时的缓冲区大小,单位是字节,默认值是 16384(16KB) 。当生产者发送的消息字节数累计达到这个值时,就会触发一次批量发送;linger.ms指定了生产者在发送消息前等待更多消息的时间,单位是毫秒,默认值是 0 。设置为 10 表示生产者会等待 10 毫秒,看是否有更多消息到达,若有则一起批量发送,这样可以有效减少网络请求次数,提升发送性能 。
2. 并行处理:根据业务数据量合理设置 Topic 分区数,消费者端通过concurrency配置并发线程数,确保消费者线程数与分区数匹配,充分利用并行处理能力。在创建 Topic 时,可以使用KafkaAdmin来设置分区数,例如:
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaAdmin;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaTopicConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public KafkaAdmin kafkaAdmin() {
Map<String, Object> configs = new HashMap<>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
return new KafkaAdmin(configs);
}
@Bean
public NewTopic myTopic() {
return new NewTopic("my-topic", 4, (short) 1);
}
}
上述代码创建了一个名为my-topic的 Topic,设置分区数为 4,副本因子为 1 。在消费者配置中,设置concurrency与分区数一致:
spring.kafka.listener.concurrency=4
这样每个消费者线程可以独立处理一个分区的消息,实现并行消费,提高消费效率 。
3. 压缩优化:启用 Kafka 消息压缩(如 Snappy、Gzip),减少网络传输数据量,提升吞吐量,配置producer.properties.compression.type即可开启压缩功能。在application.properties中配置:
spring.kafka.producer.properties.compression.type=snappy
这里选择了 Snappy 压缩算法,它具有较高的压缩速度和适中的压缩比,适合对性能要求较高且对空间节省有一定需求的场景 。若选择 Gzip 算法,虽然压缩比更高,但会消耗更多的 CPU 资源,适用于带宽受限、对压缩比要求高的场景 。启用压缩后,生产者在发送消息时会对消息进行压缩,消费者在接收消息时会自动解压缩,整个过程对业务代码透明,有效减少了网络传输的数据量,提升了系统的整体吞吐量 。
(三)动态消费者管理
针对需要动态启停消费者或调整并发数的场景,利用KafkaListenerEndpointRegistry获取消费者容器,通过pause、resume方法控制消费者状态,支持运行时动态调整concurrency参数,满足灵活的业务需求。首先注入KafkaListenerEndpointRegistry:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.config.KafkaListenerEndpointRegistry;
import org.springframework.stereotype.Service;
@Service
public class ConsumerManager {
@Autowired
private KafkaListenerEndpointRegistry kafkaListenerEndpointRegistry;
public void pauseConsumer(String listenerId) {
kafkaListenerEndpointRegistry.getListenerContainer(listenerId).pause();
}
public void resumeConsumer(String listenerId) {
kafkaListenerEndpointRegistry.getListenerContainer(listenerId).resume();
}
public void adjustConcurrency(String listenerId, int newConcurrency) {
kafkaListenerEndpointRegistry.getListenerContainer(listenerId).setConcurrency(newConcurrency);
}
}
假设在一个电商系统中,在促销活动期间订单量会大幅增加,此时可以通过调用adjustConcurrency方法动态增加消费者的并发数,以加快订单处理速度;在活动结束后,订单量减少,可调用该方法降低并发数,节省系统资源 。通过pauseConsumer和resumeConsumer方法,可以在系统维护或某些特殊情况下暂停消费者,待条件恢复后再恢复消费,实现对消费者的灵活管理 。
四、生产环境关键技术点
(一)监控与运维
集成 Spring Boot Actuator 与 Prometheus,监控消费者滞后量(Consumer Lag)、消息吞吐量等关键指标,及时发现系统瓶颈。Spring Boot Actuator 提供了一系列的端点,用于监控和管理 Spring Boot 应用,通过集成 Prometheus,能够将 Kafka 相关的监控指标暴露给 Prometheus 进行收集和分析 。在pom.xml中添加 Actuator 和 Prometheus 相关依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
在application.properties中配置 Actuator 和 Prometheus 相关属性:
management.endpoints.web.exposure.include=*
management.metrics.export.prometheus.enabled=true
配置日志框架记录消费者异常,便于故障排查与定位 。以logback为例,在logback-spring.xml中配置:
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="CONSOLE" />
</root>
在消费者代码中,通过捕获异常并记录日志,方便后续分析问题:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerService.class);
@KafkaListener(topics = "test-topic", groupId = "my-group")
public void handleMessage(ConsumerRecord<String, String> record) {
try {
System.out.println("Received message: " + record.value());
// 执行业务逻辑
processBusinessLogic(record.value());
} catch (Exception e) {
logger.error("Failed to process message: " + e.getMessage(), e);
}
}
private void processBusinessLogic(String message) {
// 模拟业务逻辑处理
System.out.println("Processing business logic for message: " + message);
}
}
通过上述配置,Prometheus 可以定期拉取 Spring Boot 应用暴露的 Kafka 监控指标,如消费者滞后量,即消费者未处理的消息数量 ,可通过kafka_consumer_lag指标监控;消息吞吐量可通过kafka_producer_record_send_total和kafka_consumer_records_consumed_total指标结合时间窗口计算得出 。同时,logback将消费者处理消息过程中的异常信息记录到日志中,便于运维人员快速定位问题 。
(二)版本兼容与升级
选择与 Spring Boot 版本兼容的 Kafka 客户端,升级前进行充分的兼容性测试,确保生产者与消费者协议版本一致,避免因版本不兼容导致的连接失败或消息解析异常 。在pom.xml中,根据 Spring Boot 版本选择合适的spring-kafka版本,例如 Spring Boot 2.6.x 版本可搭配spring-kafka 2.8.x 版本 。查看 Spring 官方文档或spring-kafka的发布说明,获取版本兼容性信息 。在升级 Kafka 客户端前,搭建与生产环境相似的测试环境,进行全面的兼容性测试 。测试内容包括生产者发送消息、消费者接收消息、消息的序列化与反序列化、事务处理等功能是否正常 。例如,编写测试用例验证不同版本客户端之间的通信:
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.test.EmbeddedKafkaBroker;
import org.springframework.kafka.test.context.EmbeddedKafka;
import org.springframework.test.annotation.DirtiesContext;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
import static org.junit.jupiter.api.Assertions.assertEquals;
@SpringBootTest
@EmbeddedKafka(topics = "test-topic")
@DirtiesContext
public class KafkaCompatibilityTest {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private EmbeddedKafkaBroker embeddedKafkaBroker;
@Test
public void testKafkaCompatibility() throws InterruptedException {
String message = "Test message for compatibility";
CountDownLatch latch = new CountDownLatch(1);
kafkaTemplate.send(new ProducerRecord<>("test-topic", message));
embeddedKafkaBroker.consumeFromAllEmbeddedTopics((ConsumerRecord<String, String> record) -> {
assertEquals(message, record.value());
latch.countDown();
});
latch.await(10, TimeUnit.SECONDS);
}
}
通过上述测试,确保在升级 Kafka 客户端后,系统能够正常运行,避免因版本不兼容带来的潜在风险 。
(三)安全配置
启用 Kafka 的 SSL/TLS 加密传输,配置生产者与消费者的认证信息,确保数据在网络传输中的安全性 。在application.properties中配置 SSL 相关参数,例如:
spring.kafka.consumer.properties.security.protocol=SSL
spring.kafka.consumer.properties.ssl.truststore.location=/path/to/truststore.jks
spring.kafka.consumer.properties.ssl.truststore.password=truststore-password
spring.kafka.producer.properties.security.protocol=SSL
spring.kafka.producer.properties.ssl.keystore.location=/path/to/keystore.jks
spring.kafka.producer.properties.ssl.keystore.password=keystore-password
其中,truststore用于验证 Kafka 服务器的身份,keystore用于客户端认证 。通过 OpenSSL 等工具生成 SSL 证书和密钥,将其配置到上述路径中 。通过 ACL(访问控制列表)控制不同用户对 Topic 的读写权限,保障集群资源的合理使用 。在 Kafka 中,通过kafka-acls.sh脚本或AdminClient来配置 ACL 规则 。例如,使用kafka-acls.sh添加一条允许用户user1对test-topic进行读写的规则:
bin/kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:user1 --operation Read --operation Write --topic test-topic
在 Spring Boot 应用中,通过配置KafkaProperties来设置认证信息,确保生产者和消费者能够按照 ACL 规则访问 Kafka 集群 。例如:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class KafkaSecurityConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.properties.security.protocol}")
private String securityProtocol;
@Value("${spring.kafka.consumer.properties.ssl.truststore.location}")
private String truststoreLocation;
@Value("${spring.kafka.consumer.properties.ssl.truststore.password}")
private String truststorePassword;
@Value("${spring.kafka.producer.properties.ssl.keystore.location}")
private String keystoreLocation;
@Value("${spring.kafka.producer.properties.ssl.keystore.password}")
private String keystorePassword;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.SECURITY_PROTOCOL_CONFIG, securityProtocol);
props.put(ConsumerConfig.SSL_TRUSTSTORE_LOCATION_CONFIG, truststoreLocation);
props.put(ConsumerConfig.SSL_TRUSTSTORE_PASSWORD_CONFIG, truststorePassword);
return props;
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.SECURITY_PROTOCOL_CONFIG, securityProtocol);
props.put(ProducerConfig.SSL_KEYSTORE_LOCATION_CONFIG, keystoreLocation);
props.put(ProducerConfig.SSL_KEYSTORE_PASSWORD_CONFIG, keystorePassword);
return props;
}
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
通过上述配置,实现了 Kafka 的 SSL/TLS 加密传输和 ACL 访问控制,保障了生产环境中数据传输的安全性和集群资源的合理使用 。
五、总结与最佳实践总结
本文从基础集成到高级特性,结合订单系统、秒杀系统、日志收集等常见业务场景,详细介绍了 Spring Boot 与 Kafka 的集成实践。在实际开发中,需根据业务需求合理选择可靠性与性能策略,注重监控与运维,确保 Kafka 在分布式系统中稳定高效运行。通过遵循最佳实践,能够充分发挥 Kafka 的高吞吐量、低延迟优势,实现系统的异步解耦、流量削峰与可扩展架构设计。
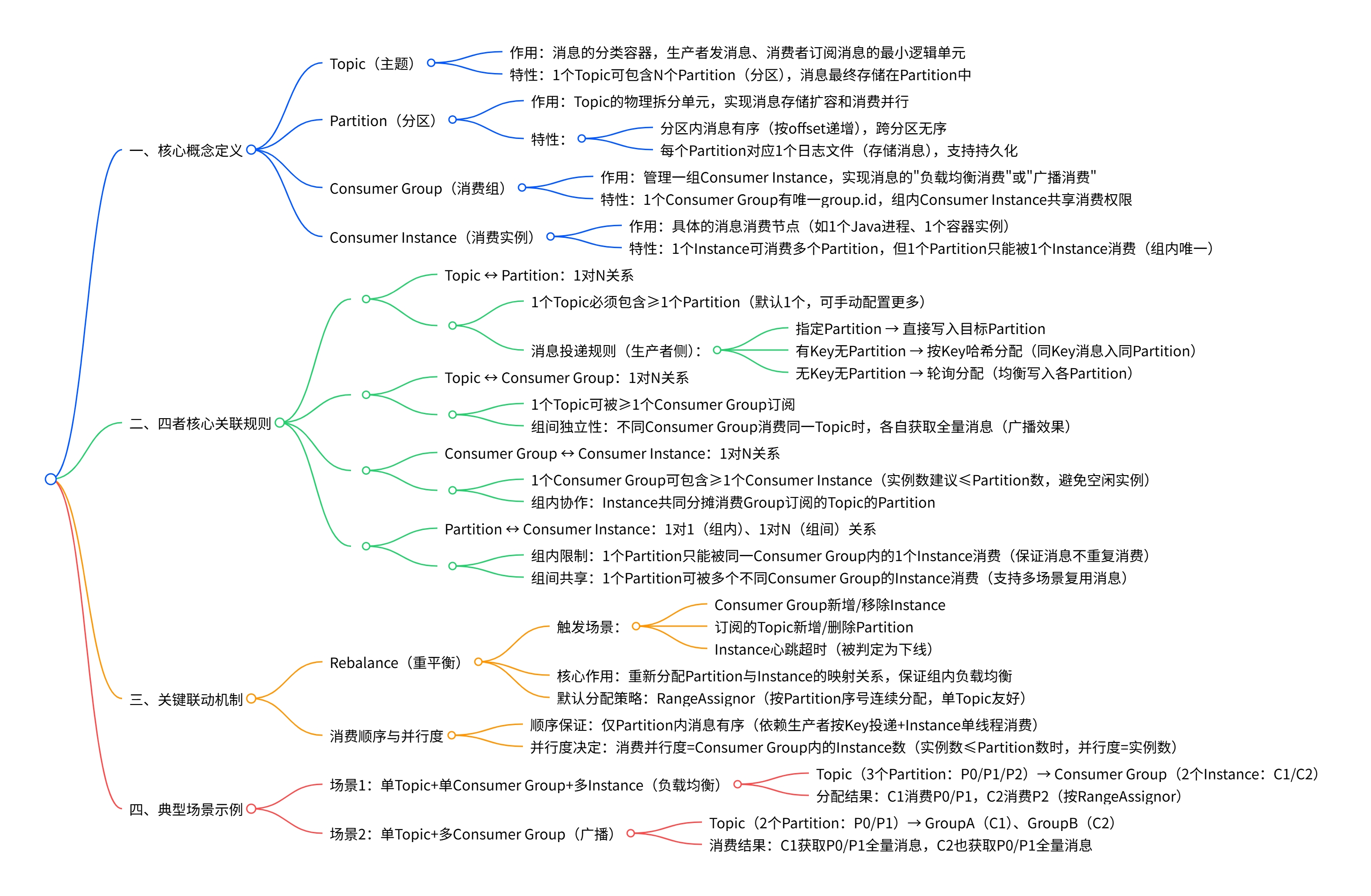
最后附上kafka的一些基础知识思维导图: