机器学习进阶,一文搞定模型选型!
已经学习了那么多算法(比如线性规划、多项式、决策树、支持向量机、随机森林),当拿到一批数据后,该如何选择算法模型呢?
这是一个非常棒的问题,也是机器学习实践中最核心、最关键的一步。选择正确的算法远比盲目地调参更重要。
面对一批新数据,选择算法模型是一个系统性的决策过程,而不是凭感觉猜测。它依赖于你对数据、问题和算法本身的深刻理解。
以下是我为你梳理的一个系统化的决策流程和思考框架,你可以遵循这个路线图来做出选择:
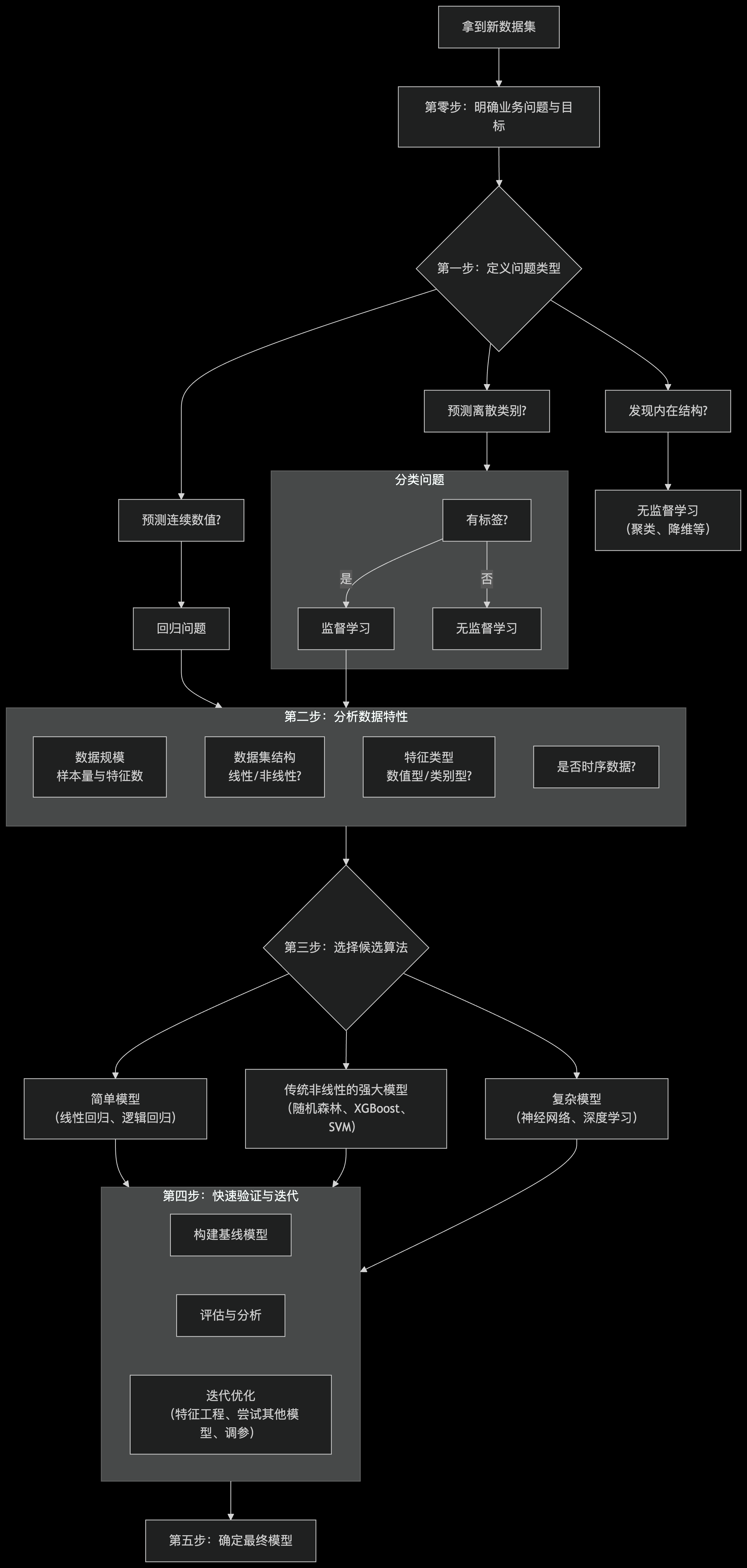
上图展示了核心的决策路径,以下是每个步骤的详细说明:
第零步:最重要的一步——明确你的业务问题与目标
在看任何数据之前,先问自己:
- 最终目标是什么? 是要预测一个值(房价)、预测一个类别(是否患病)、发现数据的自然分组(客户分群),还是只是探索数据?
- 成功的标准是什么? 业务上关心的是什么?是预测准确率、是召回率(不要漏掉一个坏人)、是模型的可解释性,还是预测速度?
- 准确率 vs. 可解释性:医生需要用模型辅助诊断,他必须知道模型为什么下这个结论(可解释性高),而不是一个黑盒。决策树、线性模型
更优。 - 极致性能 vs. 资源消耗:在图像识别比赛中,为了提升0.1%的准确率,可以使用复杂的 深度学习模型。但在一台嵌入式设备上,可能需要轻量的 朴素贝叶斯 或小型的决策树。
- 准确率 vs. 可解释性:医生需要用模型辅助诊断,他必须知道模型为什么下这个结论(可解释性高),而不是一个黑盒。决策树、线性模型
第一步:定义问题类型(这是最直接的筛选器)
- 预测一个连续数值? -> 回归问题
○ 例如:预测房价、预测销量、预测温度。
○ 常用算法:线性回归、回归树、随机森林回归、XGBoost回归、SVR(支持向量回归)。 - 预测一个离散的类别/标签? -> 分类问题
○ 例如:判断邮件是否是垃圾邮件、识别图片中的动物种类。
○ 常用算法:逻辑回归、决策树、随机森林、XGBoost、SVM(支持向量机)、朴素贝叶斯、K近邻。 - 发现数据内在的结构/分组? -> 无监督学习
○ 例如:将客户分成不同的群体以便精准营销、对新闻主题进行自动聚类。
○ 常用算法:K-Means聚类、DBSCAN、主成分分析(PCA)用于降维。
第二步:分析你的数据集特性
确定了问题类型后,分析数据本身的特点能帮你进一步缩小选择范围。
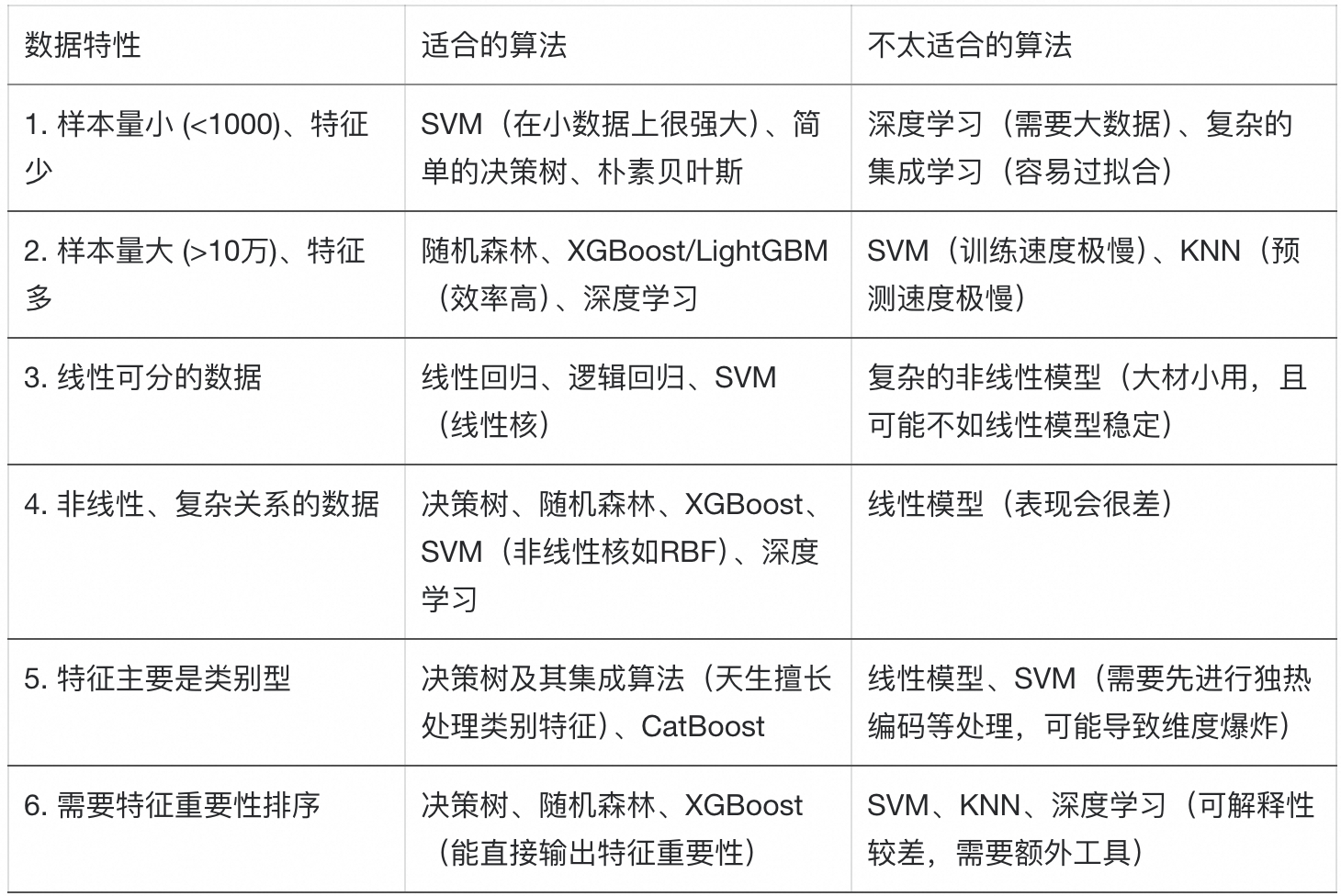
第三步:实用主义的选择策略与推荐
基于以上分析,一个非常实用且高效的策略是:
- 永远从简单开始:
○ 回归:先试试线性回归,建立一个性能基线。
○ 分类:先试试逻辑回归 或 朴素贝叶斯。
○ 如果简单模型表现已经很好,就没必要用复杂模型。奥卡姆剃刀原理:如无必要,勿增实体。 - 转向强大的 “即插即用” 型算法:
○ 如果简单模型表现不佳,随机森林 和 梯度提升树(如XGBoost) 几乎是你在结构化数据(表格数据)上的首选。
○ 为什么?
■ 它们对数据和参数的要求不高,默认参数往往就能得到不错的结果。
■ 能自动处理非线性关系和特征交互。
■ 不需要繁琐的特征缩放(如归一化)。
■ 能处理混合类型的特征。
■ 天然地提供了特征重要性排序。 - 在特定情况下考虑其他模型:
○ SVM:当数据量不是特别大,并且特征维度很高时(例如文本分类),线性SVM通常非常有效。
○ KNN:作为一个简单的基线,或者当数据分布非常不规则时。但计算成本高,不适合大数据。
○ 深度学习:主要适用于非结构化数据(图像、文本、音频),或者有海量样本的表格数据。对于中小型结构化数据,树模型通常更优。
第四步:快速验证与迭代
理论分析只是第一步,最终还是要用实验说话。
- 构建基线模型:用一两个简单模型(如逻辑回归)建立一个性能基线。
- 尝试2-3个候选模型:根据你的分析,选择2-3个最有可能的模型(例如随机森林、XGBoost、SVM)。
- 使用交叉验证:在训练集上使用交叉验证来公平地评估这些模型的性能。
- 分析结果:
○ 哪个模型在验证集上表现最好?
○ 是否过拟合?(训练集分数远高于验证集分数 -> 简化模型,如增加正则化、剪枝)
○ 是否欠拟合?(训练集和验证集分数都低 -> 使用更复杂的模型或更好的特征) - 迭代优化:选择最好的那个模型进行进一步的调参和特征工程。
总结
拿到数据后,不要急于写代码,先花时间思考:
- 目标:我的业务目标是什么? -> 确定问题类型。
- 数据:我的数据有什么特点?(大小、线性、特征类型) -> 筛选候选算法。
- 实践:从简单到复杂,快速实验和验证 -> 选择并迭代。
记住,没有“最好”的算法,只有“最合适”的算法。 随机森林和XGBoost因其强大的性能和易用性,在现实中已成为处理表格数据的首选起点。但最终的选择必须依赖于你对具体问题的理解和实际的实验验证。