联邦学习论文分享:GPT-FL: Generative Pre-Trained Model-AssistedFederated Learning
摘要
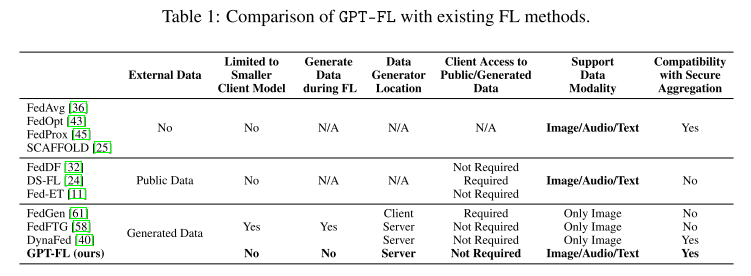
1. 提出的方法:GPT-FL
框架:GPT-FL 是一个 生成式预训练模型(如 GPT)辅助的联邦学习(FL)框架。
核心机制:
使用大模型生成 多样化合成数据;
先在服务器端用这些合成数据训练一个下游模型;
再在联邦学习流程中,用客户端的私有数据对下游模型进行微调。
2. 实验发现与效果
性能提升:GPT-FL 在 模型准确率、通信效率、客户端采样效率 上都超过了现有 SOTA 方法。
关键作用:
合成数据生成的下游模型能 调控梯度多样性的方向;
这样加快了收敛速度 → 带来显著的准确率提升。
适用性强:无论目标数据是 在预训练模型领域内还是领域外,GPT-FL 都有明显提升。
引言
1. 背景与问题
标准联邦学习(FL)问题:由于不同客户端数据分布异质性大,模型性能有限。
已有改进方向:
基于公共数据的 FL:依赖高质量公共数据,但很难获取。
基于生成模型的合成数据 FL:用生成模型+知识蒸馏生成数据,但存在两大问题:
合成数据在生成模型未收敛前质量差,影响训练;
知识蒸馏需共享模型权重,不兼容安全聚合协议,隐私保障不足。
2. GPT-FL 的方法与优势
核心思路:
利用 生成式预训练模型(如 GPT) 生成多样化合成数据;
解耦合成数据生成与联邦训练过程;
在 服务器端用合成数据训练下游模型,再进入标准 FL 流程由客户端微调。
五个主要优点:
摆脱公共数据依赖,适用性更强。
合成数据质量不受客户端私有数据分布和模型结构影响。
主要计算在服务器完成,降低通信和计算成本。
不增加客户端计算负担。
不改变标准 FL 框架 → 完全兼容安全聚合协议 & 不引入额外超参数。
3. 实验发现
整体性能:在 图像和语音数据集上,GPT-FL 都超过了 SOTA 方法。
五点关键结果:
在数据异质性高/低场景下都表现优异,同时通信和采样效率更好。
零样本设定下:图像任务 GPT-FL > 标准 FL;但语音任务中因生成模型质量不足,效果较差。
不依赖单一数据源(即使生成模型领域外数据,仍优于标准 FL)。
合成数据生成的下游模型可 调节梯度多样性,加快收敛并提升精度。
GPT-FL 可与已有下游预训练模型结合,在 FL 中进一步增强性能。
相关工作
1. 标准联邦学习(Standard FL)
基本机制:客户端在本地训练 → 服务器聚合更新全局模型 → 再下发给客户端。
隐私增强:提出 安全聚合(SA) 协议,只暴露加总后的更新,避免泄露单个客户端参数。
主要问题:由于客户端数据分布异质性,容易出现 client drift(客户端漂移),导致性能下降。
已有改进方法:FedProx、SCAFFOLD、FedOpt、ProxSkip 等通过调整聚合函数来缓解 drift。
2. 基于公共数据的 FL(FL with Public Data)
思路:利用网络收集的公共数据来辅助训练和聚合,比如 FedDF、DS-FL、Fed-ET。
优点:可以在服务器侧利用公共数据做 知识蒸馏(KD) 或分担部分计算(Mixed FL)。
局限性:
依赖公共数据质量,难以保证收集到合适的数据。
公共数据与训练数据的关联性要求不明确 → 很难找到合适数据。
涉及 KD 需要共享模型权重,不兼容安全聚合,易受后门攻击。
部分方法还要求客户端处理公共数据 → 增加客户端计算负担。
3. 基于合成数据的 FL(FL with Synthetic Data)
代表方法:FedGen、FedFTG(在服务器端训练轻量生成器,结合本地模型信息生成合成数据)。
优势:不需要真实公共数据。
局限性:
生成器依赖全局模型 → 在数据高度异质时性能差。
合成数据质量受限于全局模型结构,训练中不稳定。
多为 图像任务,难以扩展到语音、时间序列等模态。
轻量生成器(MLP 或 GAN)在高保真数据生成上存在不足。
不支持安全聚合(因为用到 KD),存在隐私风险。
其他替代方法(如 DynaFed 的梯度反演)对高分辨率图像/非图像模态(音频)也有限制。
4. 引出 GPT-FL
上述方法都存在 公共数据难获取 / 合成数据质量不稳 / 隐私保护不足 / 任务模态受限 的问题。
GPT-FL 的定位:提出一种新的 利用生成式预训练模型生成合成数据 的 FL 方法,解决上述不足。
算法
整体概览
1. GPT-FL 的整体流程(四步架构)
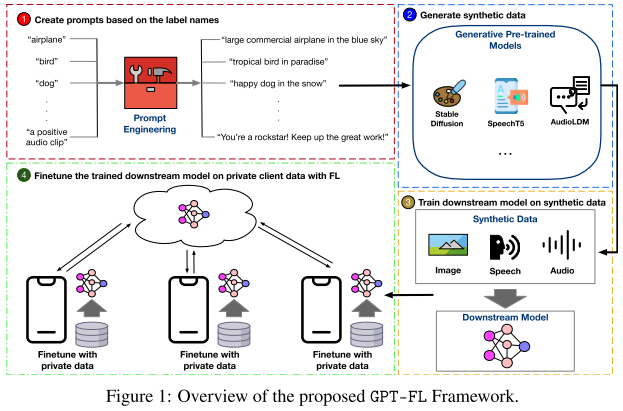
目标:把 大规模预训练模型(foundation models)的知识迁移到 FL 系统,提升联邦学习性能。
四个步骤:
基于标签创建提示语(prompts) → 用于引导生成式预训练模型。
生成合成数据 → 利用生成模型(如 Stable Diffusion)生成多样化数据。
服务器端训练下游模型 → 用合成数据集中训练好模型并下发给客户端。
客户端本地微调 → 客户端再用私有数据在标准 FL 框架下进行 finetune。
2. 第一步:基于标签的 Prompt 构造
客户端需提供 标签名集合(label names),服务器据此生成 prompt。
仅靠标签名容易导致 生成数据质量和多样性不足。
解决方法:
使用 LLM(如 GPT-3)扩展标签描述(例:标签“airplane” → prompt “Large commercial airplane in the blue sky”)。
借鉴现有研究 [47],随机设置 unconditional guidance scale(范围 1~5)来提升生成多样性。
GPT-FL 还支持接入其他 prompt engineering 技术,增强合成数据的多样性与质量。
3. 提升标签隐私:IBLT 机制
问题:客户端上传标签名可能会泄露数据分布。
解决:使用 可逆布隆查找表(IBLT) 对标签进行编码:
客户端本地先将标签名编码到 IBLT。
服务器通过 安全聚合协议 聚合所有 IBLT。
解码后可获得 全局标签集合的并集,但无法识别单个客户端的标签信息。
这样就能在不泄露单个客户端标签的前提下,保证服务器端能够正确生成 prompts。
生成合成样本
1. 合成数据的生成方式
输入:之前构造好的 prompts。
模型选择(按不同模态):
图像 → Latent Diffusion Model(用 Stable Diffusion V2.1 权重)。
语音(text-to-speech)→ SpeechT5。
音频(text-to-audio)→ AudioLDM。
2. 框架的通用性
GPT-FL 不局限于图像或音频,还支持其他数据模态。
可灵活替换不同的 预训练生成模型,适配各种任务。
3. 设计理念:API 调用而非本地部署
GPT-FL 把 生成式预训练模型当作服务提供方,仅通过 API 调用生成数据。
不需要修改或部署模型内部参数/结构。
好处:
节省服务器端算力和部署成本。
符合当前趋势(很多大模型只提供 API 访问)。
提升可扩展性和适用性,更方便在不同场景下应用。
基于合成样训练
1. 下游模型训练流程
在服务器端,用生成的 合成数据 来训练一个下游模型。
训练完成后,把这个下游模型分发给所有客户端,作为后续 联邦学习的初始化模型。
2. 训练中的挑战
合成数据容易 模式化(patternized),缺乏真实数据的多样性。
这会导致模型训练过程中容易出现 过拟合问题。
3. 解决办法
在训练过程中调整超参数来缓解过拟合:
使用 更大的 weight decay(权重衰减)。
使用 更小的学习率。
本地微调
1. 微调步骤
客户端收到服务器分发的下游模型(基于合成数据训练的)。
以该模型为起点,用自己的 私有数据 在 标准联邦学习框架 下继续微调,直到收敛。
2. 方法特性
保持标准 FL 框架:GPT-FL 没有对 FL 机制做额外改动,所以依然完全兼容 安全聚合协议,隐私保护不受影响。
无额外超参数:不像其他基于生成数据的方法(如 FedGen、FedFTG、DynaFed),GPT-FL 不需要引入新的超参数。
这样避免了复杂的超参搜索问题。
使得 GPT-FL 更加 实用且易于应用。
理论背景
1. 背景理论
在经验风险最小化(ERM)中,训练数据被假设为从全局数据随机抽取的子集。
由预训练生成模型产生的合成数据可以视为另一组“随机子集”,用它做预训练相当于对模型做了一次 分布偏置的训练。
2. 数学表述
定义:
∇F(x) :全局最优梯度
∇f(x) :训练数据的随机梯度(无偏)
∇F′(x) :合成数据的最优梯度
∇f′(x) :合成数据的随机梯度(无偏)
由于合成数据和真实数据分布不同:
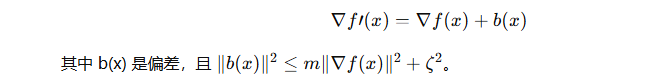
已知理论:带偏梯度在非凸光滑问题下仍可收敛。
3. 对训练加速的影响
带偏梯度使模型初始化时就接近局部最优区域 → 初始损失低。
合成数据越多,偏差越小 → 收敛更快(更低的 m 和 ζ²)。
4. 对泛化性能的提升
泛化性能衡量训练集损失和真实全局损失的差距。
通过预训练合成数据,模型训练不仅依赖真实数据,还融合了额外数据 → 损失差距可能减小 → 泛化能力提高。
实验
设置
1. 数据集、模型与任务
图像分类:CIFAR-10、CIFAR-100、Oxford 102 Flower
模型:ConvNet、ResNet18、ResNet50、VGG19
特点:CIFAR-10/100 物体多样,Flowers102 高分辨率适合细粒度分析
语音任务:Google Speech Command(关键词识别)、ESC-50(环境声音分类)
使用先前研究的音频模型
2. 数据异质性(Non-IID)
CIFAR-10/100:按 Dirichlet 分布分配给 100 个客户端(α=0.1, 0.5)
Flowers102:分为 50 个子集
Google Speech Command:按 2,618 个说话人 ID 分布
ESC-50:按 Dirichlet 分布分为 100 个子集(α=0.1)
3. 对比基线
标准 FL 方法:FedAvg、FedProx、SCAFFOLD
使用公开数据的 FL 方法:FedDF、DS-FL、Fed-ET
使用生成合成数据的 FL 方法:FedGen、DynaFed
4. 评估指标
测试准确率
每个实验使用 3 个随机种子,报告平均值和标准差
实验一
1. 实验设置
数据集:CIFAR-10、CIFAR-100、Flowers102(因 FedGen 和 DynaFed 仅支持图像)
模型:VGG19、ConvNet
客户端采样:CIFAR 每轮随机采样 10 个客户端,Flowers102 使用全部 50 个客户端
优化器:FedAvg
通信轮数:500
本地训练 epoch:1
2. 整体性能
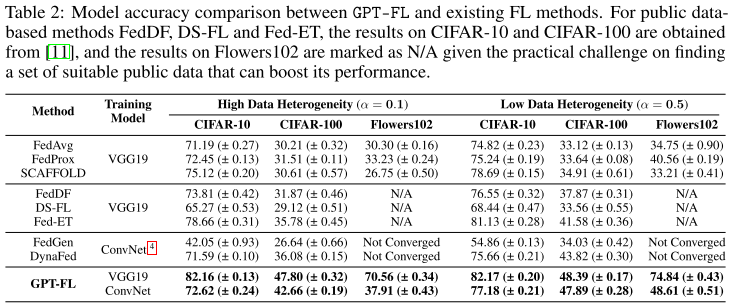
GPT-FL 在三套图像数据集上 始终优于所有基线方法
FedGen 和 DynaFed 对高分辨率 Flowers102 不收敛,也无法训练较大的 VGG19
GPT-FL 不仅收敛,而且在 Flowers102 上达到了 最先进精度
GPT-FL 对大模型支持良好,精度明显高于小模型 ConvNet
对 Flowers102,其他基于公开数据或生成数据的方法存在挑战,GPT-FL 明显优于标准 FL
3. 通信效率
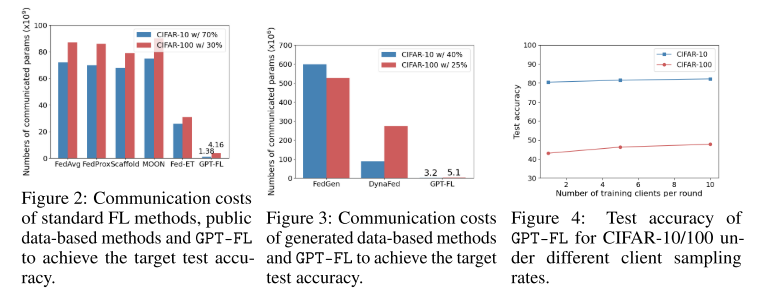
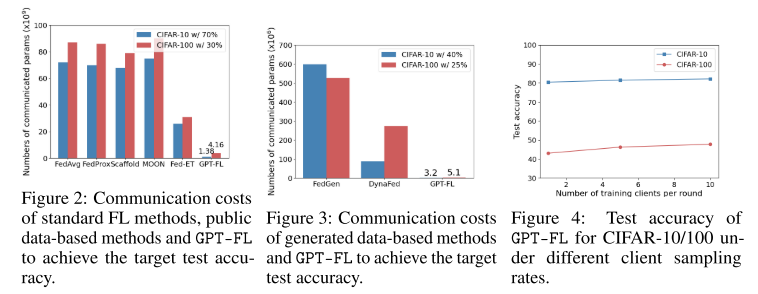
测量方式:达到目标精度所需交换的模型参数总量
结果:GPT-FL 比最佳公开数据方法 Fed-ET 减少 94% 通信成本,比最佳生成数据方法 DynaFed 减少 98%
显示 GPT-FL 在通信效率上优势显著
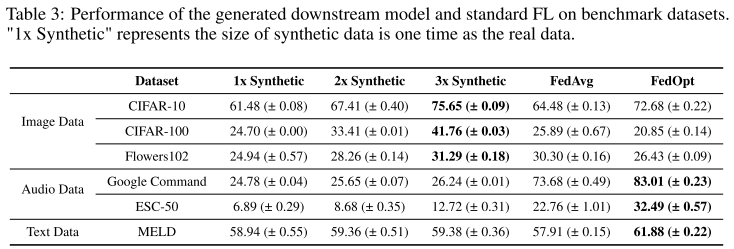
4. 客户端采样效率
测试 GPT-FL 在低客户端参与情况下性能
结果:每轮仅 1 个客户端,CIFAR-10 达 80.44% 精度,CIFAR-100 达 43.07%
远高于其他方法(使用 9 倍客户端)
表明 GPT-FL 在 低客户端参与场景下仍能高效训练
理解该算法
集中式训练使用合成数据
1. 实验设置
比较对象:
集中式训练:使用生成的合成数据训练下游模型
标准 FL:使用客户端私有数据训练全局模型
数据集:
图像:CIFAR-10、CIFAR-100、Flowers102(ResNet18/ResNet50)
音频:ESC-50、Google Speech Commands
文本:MELD(情感分析,报告 F1 分数)
2. 域外数据生成的影响(Out-of-Domain Generation)
图像:
使用生成的合成图像进行集中式训练 优于 FL 设置,准确率更高
原因:Stable Diffusion 使用的 LAION-5B 数据库覆盖面广,几乎包含实验所需的相关图像
音频:
使用合成音频进行集中式训练 劣于 FL 设置
原因可能是生成模型训练语料有限(约 4 亿句,书籍语料库),导致领域知识不足,合成语音质量有限
结论:集中式训练依赖于生成数据的质量和覆盖领域
3. 合成数据量的影响
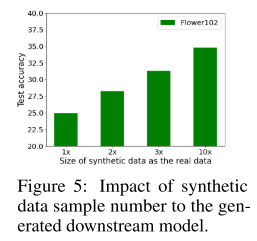
实验:在 Flowers102 数据集上,将合成数据扩展至真实数据的 10 倍
结果:模型性能随着合成数据量增加而提高
原因:
增加数据量提升多样性
合成数据与真实数据重叠更多
模型能学习更稳健、可泛化的特征
也验证了理论分析(Section 4)关于合成数据帮助加速训练和提升泛化能力的结论
为什么要联邦学习微调共同下游模型
1. 实验对比
客户端孤立微调(Client-isolated fine-tuning):
随机选取 10 个客户端
每个客户端独立使用本地数据对合成数据训练的下游模型微调 500 个 epoch
最终计算这些客户端的平均准确率
GPT-FL 联邦微调:
使用标准 FL 框架
客户端协作微调合成数据训练的下游模型
2. 结果与分析

客户端孤立微调准确率明显低于 GPT-FL 联邦微调
原因:
本地数据量有限
标签分布不均衡(skewed label distribution)
→ 导致单个客户端无法充分优化模型
3. 结论
联邦微调能够整合多客户端的多样化数据,弥补单客户端数据量和分布不足的问题
强调了 FL 在微调阶段的价值,尤其在本地数据有限或异质的情况下
为什么该算法能带来提升
1. 联邦微调(FL Fine-tuning)的好处
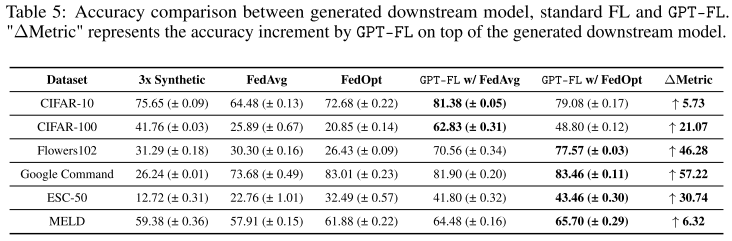
将客户端私有数据与合成数据生成的下游模型结合进行 FL 微调,可以显著提升模型性能。
结果表明,不论合成数据的模态(图像、音频等)或质量如何,FL 微调后的模型性能远超单独使用 FL 或中央化训练(CL)加合成数据训练的模型。
对 跨域/out-of-domain 的合成数据(如音频数据),私有数据的加入尤其有用。例如在 ESC-50 数据集上,GPT-FL + FedOpt 的测试准确率比标准 FL 高近两倍,比仅用合成数据训练高近三倍。
2. 下游模型初始化带来的优化优势
GPT-FL 生成的自定义模型可以改善 FL 优化过程。
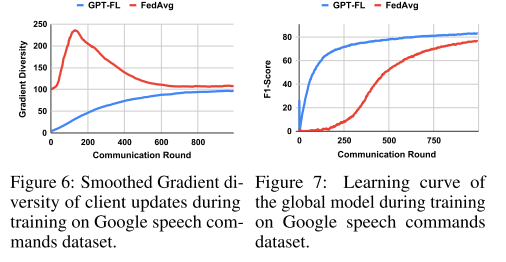
实验对比了 GPT-FL 初始化模型和随机初始化模型的 梯度多样性(gradient diversity):
GPT-FL 初始化模型的初始梯度多样性更低
低梯度多样性意味着客户端更新波动较小,训练初期收敛更快
随训练进行,两者梯度多样性趋于相似,性能曲线也一致
3. 原因分析
低初始梯度多样性 → 减少客户端偏移(client drift)问题
结合私有数据进行微调 → 提高模型在真实数据上的适应性和泛化能力