GPU 优化 - tensor core 用swizzle 解决bank conflict
上一篇博客讲用tensor core 去做5G 均衡器矩阵乘法,代码会遇到一些bank conflict. 通过查看cuda 编程手册和一些网上的博客(实用 Swizzle 教程(一) - 知乎),我们发现是load_matrix_sync()导致的。它底层调用ldmatrix ptx 指令
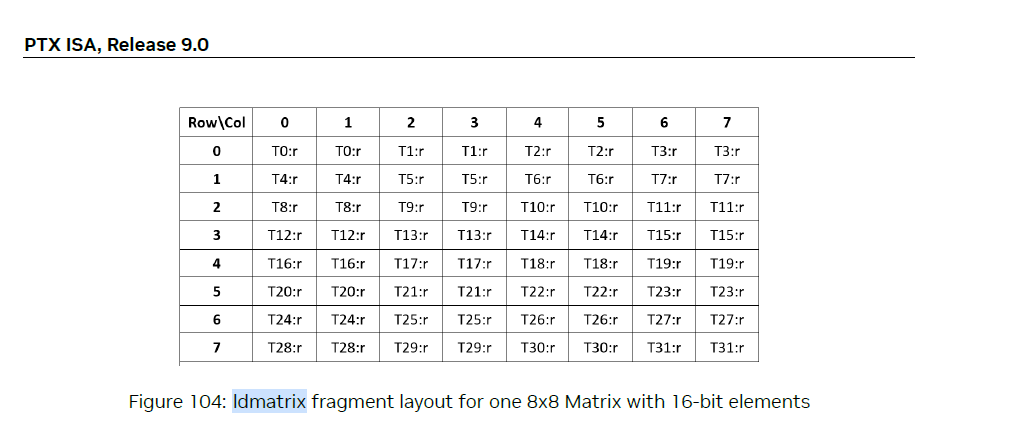
所以,一个16x16x16的矩阵乘法里面每个矩阵被分成4个8x8 load 操作,如果没有padding的话,会产生bank conflict. 下面所有的图里面,同一个颜色代表同一个warp一轮要访存的元素组,里面的值代表共享内存的bank ID。ldmax 如果配置x4, 那么同一个warp里面要做4轮,正好把16x16一次性用一个warp load完。
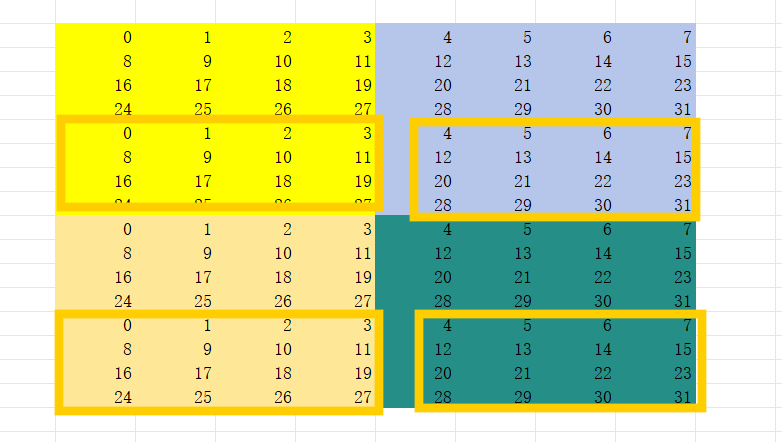
加了padding之后,任何一个8x8的矩阵load, warp里面的thread都不会和其他的threads 产生bank conflict. 但是这种消耗我们共享内存的size。
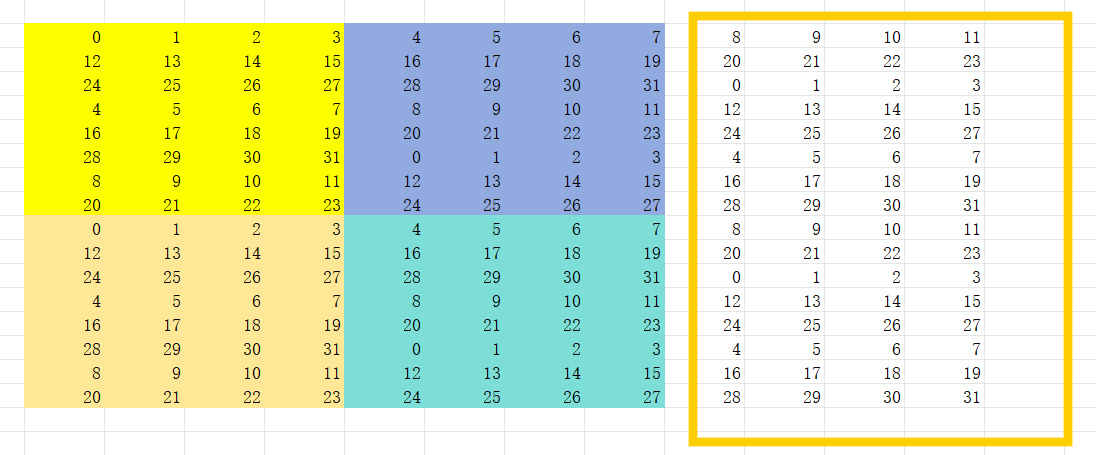
所以,会有一种叫做swizzle的方法在不消化更多共享内存的情况下去避免这种conflict。如下图,我们在把矩阵从global memory load 到shared memory的时候,把数据8x8矩阵下面四行数据掉个位置,这样在同一warp去访存的时候,里面的元素不就在不同的bank里面嘛。
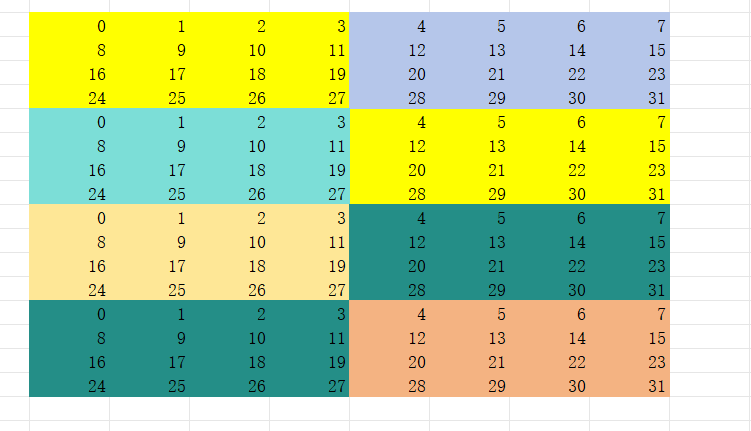
怎么做到这样的呢?具体实现,伪代码如下
第一步,从全局内存G(64x64, half)到共享内存Gs(16x16, half), 假定从第iCol个16列开始

第二步, 从共享内存到寄存器,先介绍一些ldmatrix api封装
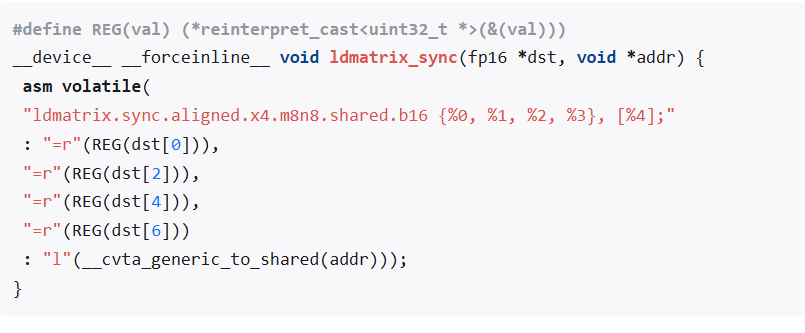

根据上面介绍的博客里面说,

它的意思就是要把warp里面每个thread的地址给它配置好(addr 0 ~ 31)。没有变化之前,下面每个thread 应该配置如下的地址:
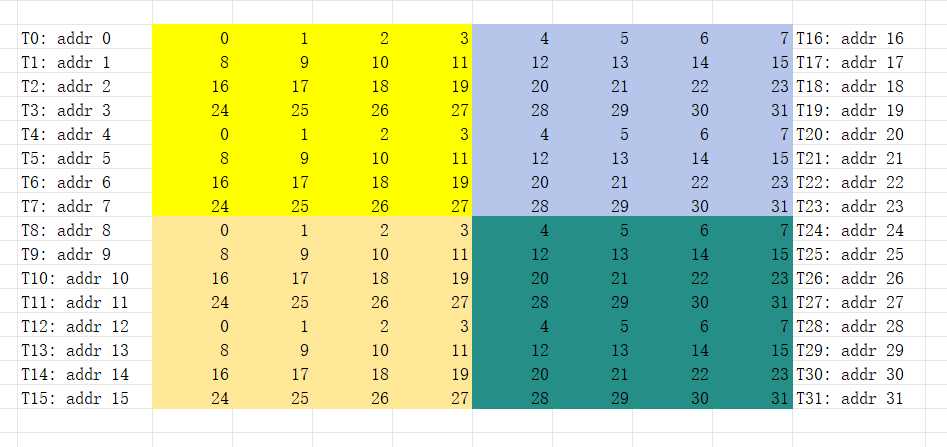
我们变换后如下,
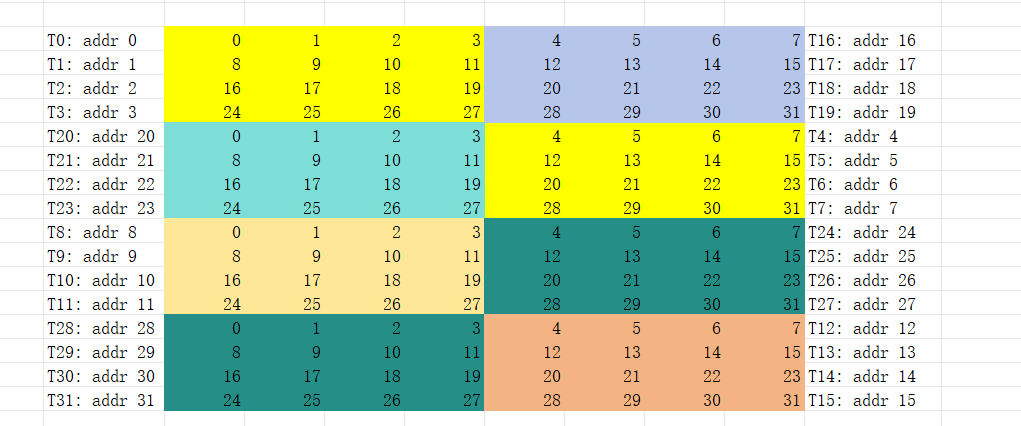
所以得到下面的映射关系,

上面介绍的博客,介绍了一种统一的写法下·

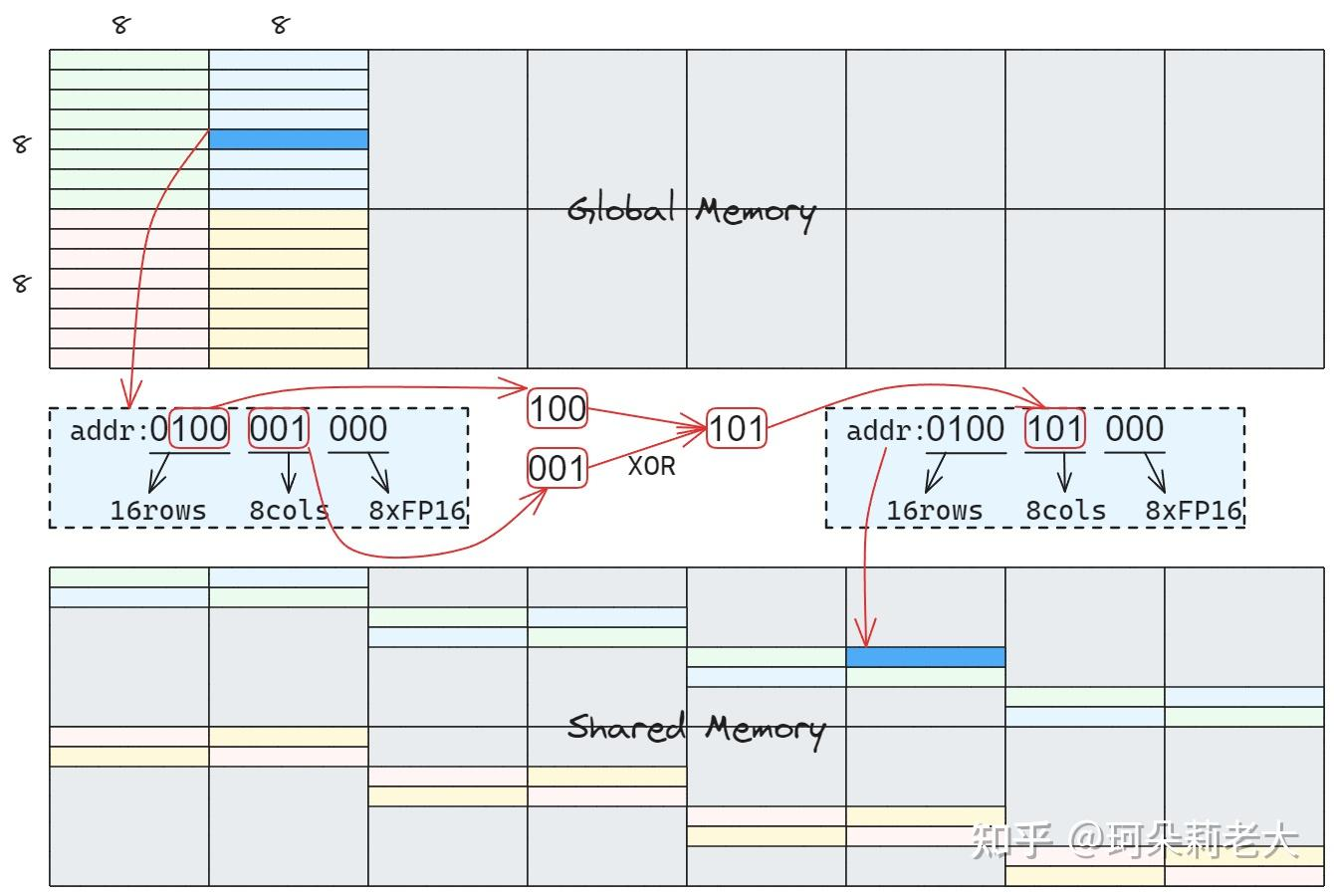

举个例子,tid = 4, rAddr = 4 * 16 = 64.
swizzle<3, 1, 3>(64) = {
Bmask = ((1 << 1) - 1) << 3 = 8;
return ((64 >> 3) & 8) ^ 64 = 72
}
OK啦