大文件稳定上传:Spring Boot + MinIO 断点续传实践
文章目录
- 一、引言:问题背景
- 二、技术选型与项目架构
- 三、核心设计与实现
- 1. 初始化上传 (`/init`)
- 2. 上传分块 (`/chunk`)
- 3. 完成上传与合并 (`/complete`)
- 4. 查询上传进度 (`/progress`)
- 四、断点续传工作流程
- 五、方案优势总结
- 六、拓展优化
- 七、方案优势对比
一、引言:问题背景
在医疗问诊等需要高可靠性数据记录的场景中,我们的一项关键功能是:医生与患者问答填写问卷时,系统需要实时录制音频并与问卷绑定,以保证数据的真实性和有效性。然而,直接上传完整的录音文件(尤其是长时间问诊产生的大文件)面临两个严峻的技术挑战:
- 网络稳定性:医院网络环境复杂,长时间上传大文件极易因网络波动而中断,导致整个上传失败,用户体验极差。
- 文件与服务器压力:大文件上传占用服务器连接时间过长,接口响应慢,且服务端一次性处理大文件对内存和IO压力巨大,容易导致文件损坏或上传失败。
为了解决这些问题,我们放弃了传统的一次性上传方案,转而采用 分块上传与断点续传 相结合的技术方案。本文将详细介绍如何基于 Spring Boot 3.0、MyBatis-Plus 和 MinIO 对象存储来实现这一稳健的上传流程。
二、技术选型与项目架构
- 后端框架: Spring Boot 3.0
- ORM 框架: MyBatis-Plus 3.5
- 对象存储: MinIO 8.2.2
- 状态缓存: Redis (用于存储上传状态和分块索引)
- 核心思路: 将大文件分割成多个小块,分别上传。利用 MinIO 的分块上传能力和 Redis 的记录功能,实现上传中断后可从中断点继续上传,而非重新开始。
三、核心设计与实现
我们通过四个清晰的 RESTful 接口来串联整个上传流程:
init: 初始化上传,获取本次上传的唯一ID。chunk: 上传单个文件分块。complete: 通知服务端所有分块已上传完毕,执行合并操作。progress: 查询当前上传进度。
**上传任务状态流转图:**本图描述了一个上传任务可能处于的各种状态及其转换条件。任务从“初始化”状态进入“上传中”子状态,并随着每个分块的上传成功而逐步推进。核心在于,当任务因异常进入“已中断”状态后,可以通过查询进度重新回到“上传中”状态,继续上传剩余分块,从而实现“续传”。超时未完成的任务会被系统清理。
1. 初始化上传 (/init)
客户端在上传前,首先需要调用初始化接口。
Controller:
@Operation(summary = "初始化分片上传")
@PostMapping("/init")
public CommonResult<FileUploadDTO.UploadInitResponse> initUpload(@RequestParam("fileName") String fileName,@RequestParam("fileSize") long fileSize) {return CommonResult.SUCCESS(minioSysFileServiceImpl.initUpload(fileName, fileSize));
}
Service:
@Override
public FileUploadDTO.UploadInitResponse initUpload(String fileName, long fileSize) {// 1. 生成唯一上传ID,用于标识本次上传任务String uploadId = UUID.randomUUID().toString();// 2. 根据预设的分块大小,计算总分块数int totalChunks = (int) Math.ceil((double) fileSize / chunkSize);// 3. 创建上传状态对象并存入Redis,设置过期时间以防僵尸任务UploadStatus status = new UploadStatus(uploadId, fileName, fileSize, totalChunks);redisTemplate.opsForValue().set(RedisKeyUtil.getUploadKey(uploadId), status, 24, TimeUnit.HOURS);// 4. 返回给客户端:uploadId 和 总分块数return new FileUploadDTO.UploadInitResponse(uploadId, totalChunks, chunkSize);
}
此接口的核心是生成一个全局唯一的 uploadId,并将文件元信息(名称、大小、分块数)存入 Redis,为后续的分块上传和续传奠定基础。
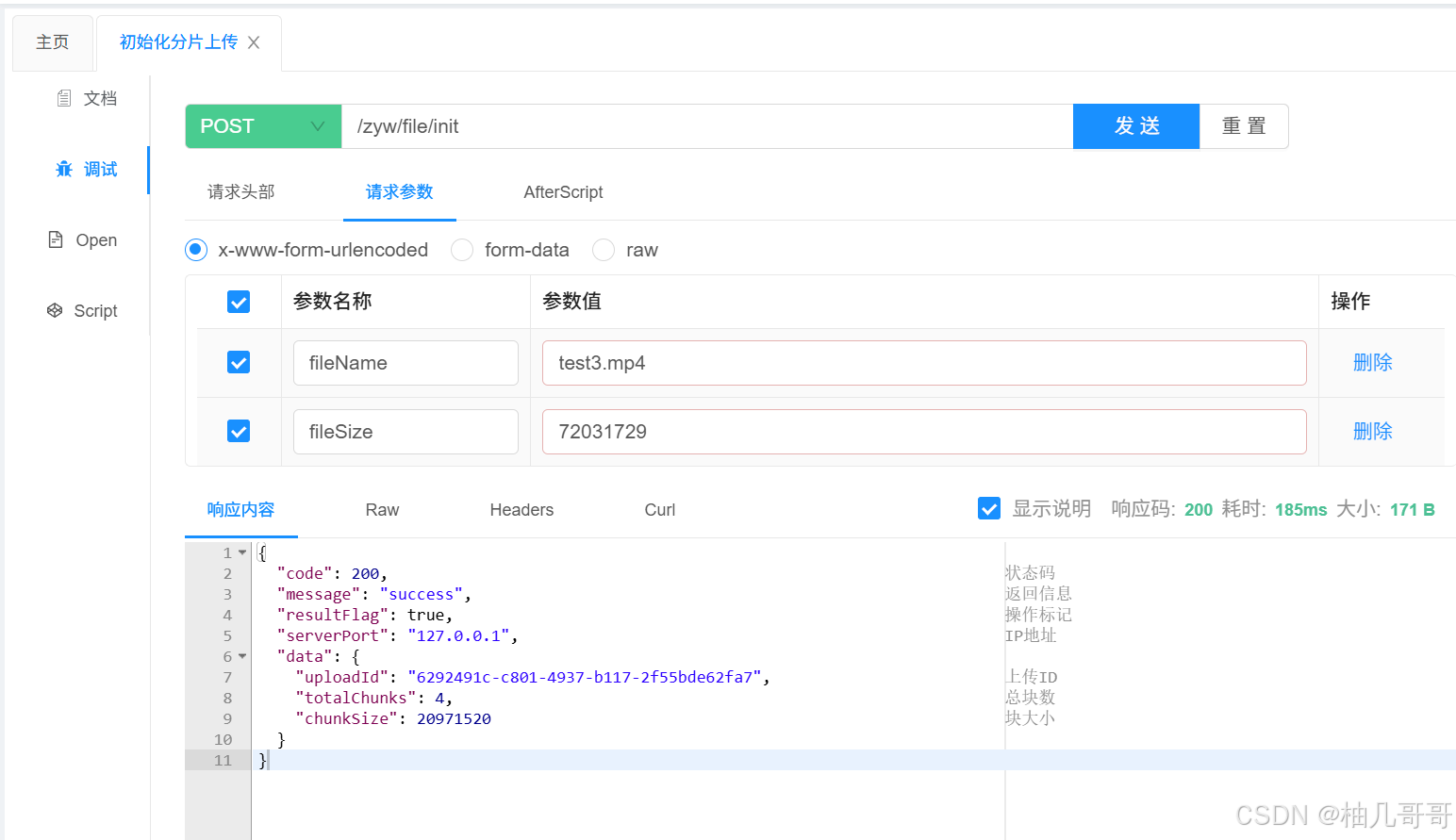
2. 上传分块 (/chunk)
客户端根据初始化接口返回的 totalChunks,将文件切分,并循环调用此接口上传每一个分块。
Controller:
@Operation(summary = "上传分片")
@PostMapping("/chunk")
public CommonResult<Void> uploadChunk(@RequestParam("uploadId") String uploadId,@RequestParam("chunkNumber") int chunkNumber,MultipartFile chunk) {minioSysFileServiceImpl.uploadChunk(uploadId, chunkNumber, chunk);return CommonResult.SUCCESS();
}
Service:
@Override
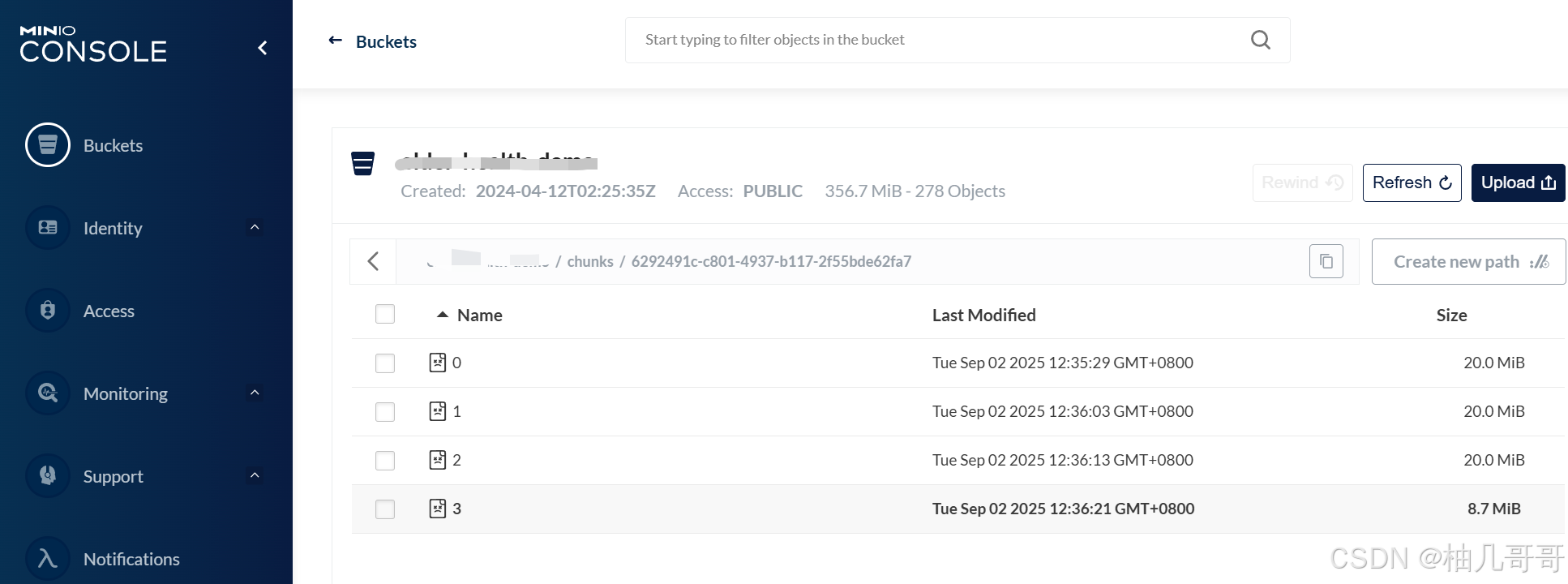
public void uploadChunk(String uploadId, int chunkNumber, MultipartFile chunk){// 1. 为当前分块生成在MinIO中的唯一对象名称// 格式如:chunks/{uploadId}/{chunkNumber}String objectName = chunkObjectName(uploadId, chunkNumber);try (InputStream inputStream = chunk.getInputStream()) {// 2. 调用MinIO SDK上传分块PutObjectArgs args = PutObjectArgs.builder().bucket(minioConfig.getBucketName()).object(objectName).stream(inputStream, chunk.getSize(), -1).contentType(chunk.getContentType()).build();minioClient.putObject(args);} catch (Exception e) {log.error("上传分块 {} 失败: {}", chunkNumber, e.getMessage());throw new BaseException(ResultCode.CHUNK_UPLOAD_FAILED); // 抛出自定义异常,由全局异常处理器处理}// 3. 上传成功后,在Redis中标记该分块已完成markChunkUploaded(uploadId, chunkNumber);
}private void markChunkUploaded(String uploadId, int chunkNumber) {// 使用Set结构存储已上传的分块编号redisTemplate.opsForSet().add(RedisKeyUtil.getUploadKey(uploadId) + ":chunks", chunkNumber);
}
每个分块都是独立上传的,一个分块的失败不会影响其他分块。成功上传后,其编号会被记录到 Redis 的 Set 中,用于后续的进度查询和完成校验。
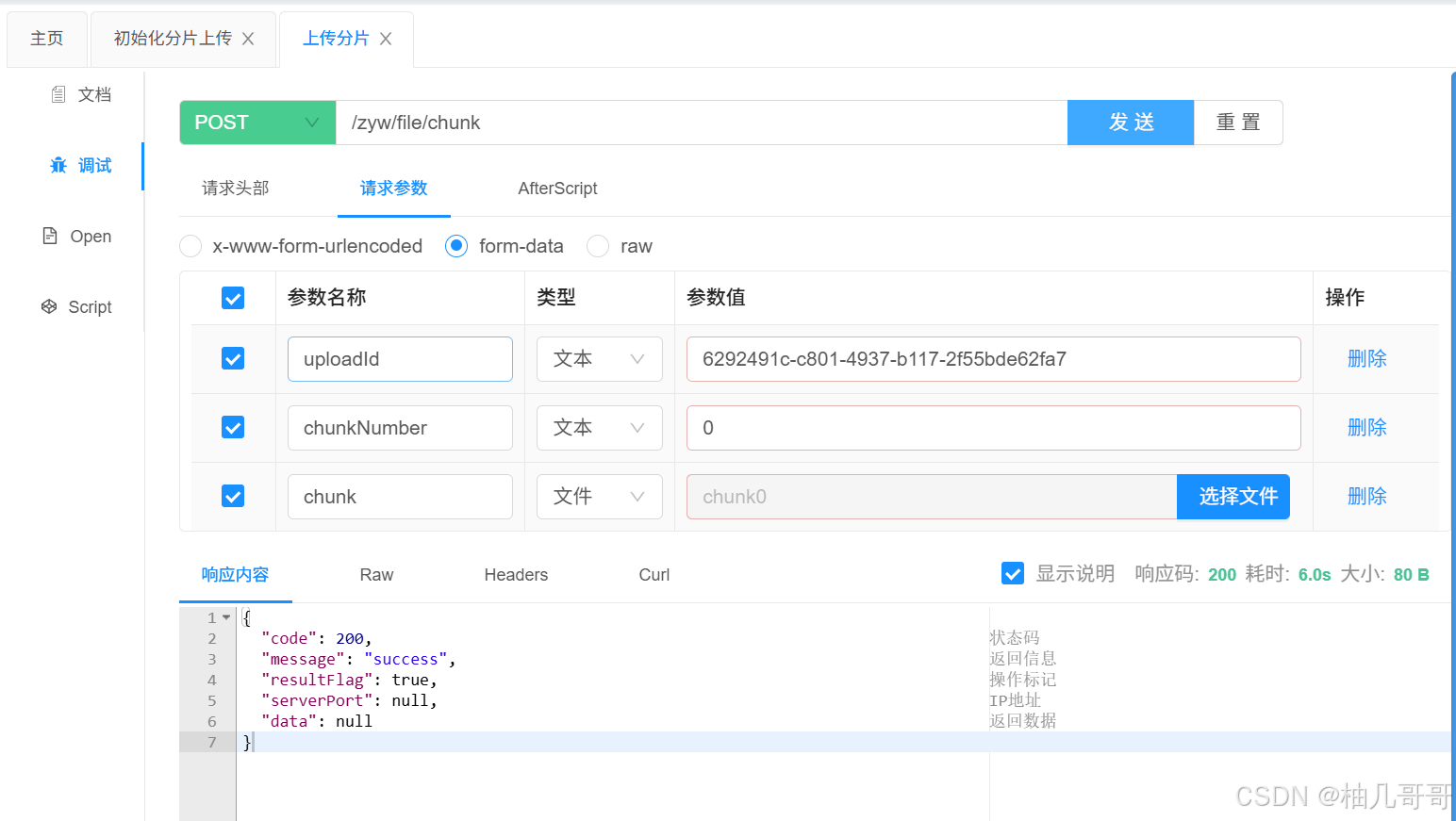
3. 完成上传与合并 (/complete)
当所有分块都上传完毕后,客户端调用此接口。
Controller:
@Operation(summary = "完成上传并合并文件")
@PostMapping("/complete")
public CommonResult<String> completeUpload(@RequestParam("uploadId") String uploadId){return CommonResult.SUCCESS(minioSysFileServiceImpl.completeUpload(uploadId));
}
Service:
@Override
public String completeUpload(String uploadId) {// 1. 从Redis获取上传状态,并检查所有分块是否已上传完成UploadStatus status = getUploadStatus(uploadId);if (!status.isComplete()) {throw new BaseException(ResultCode.CHUNK_UPLOAD_NOT_COMPLETE);}// 2. (业务逻辑)准备文件记录String originalFilename = status.getFileName();FileRecord record = ... // 创建或更新文件记录逻辑try {String finalObjectName = ... // 生成最终在MinIO中存储的文件名// 3. 核心:合并分块// 构建一个源分块列表List<ComposeSource> sources = IntStream.range(0, status.getTotalChunks()).mapToObj(i -> ComposeSource.builder().bucket(minioConfig.getBucketName()).object(chunkObjectName(uploadId, i)) // 指向每个分块.build()).collect(Collectors.toList());// 调用MinIO的composeObject API合并文件// 此操作在MinIO服务端进行,高效且不耗费应用服务器资源minioClient.composeObject(ComposeObjectArgs.builder().bucket(minioConfig.getBucketName()).object(finalObjectName).sources(sources).build());// 4. 合并成功后,清理临时分块文件for (int i = 0; i < status.getTotalChunks(); i++) {minioClient.removeObject(RemoveObjectArgs.builder().bucket(minioConfig.getBucketName()).object(chunkObjectName(uploadId, i)).build());}String fullUrl = minioConfig.getUrl() + "/" + minioConfig.getBucketName() + "/" + finalObjectName;record.setUrl(fullUrl);} catch (Exception e) {log.error("文件合并失败:{}", e.getMessage());throw new BaseException("文件合并失败");} finally {// 5. 清理Redis状态redisTemplate.delete(RedisKeyUtil.getUploadKey(uploadId));redisTemplate.delete(RedisKeyUtil.getUploadKey(uploadId) + ":chunks");}fileRecordService.saveOrUpdate(record);return record.getUrl(); // 返回最终文件的访问地址
}
这是最精妙的一步。合并操作 (composeObject) 是在 MinIO 服务端完成的,它只是将各个分块文件的元数据组合起来,形成一个逻辑上的完整文件,而不需要在应用服务器上进行耗时的二进制流合并,因此速度极快,资源消耗极低。
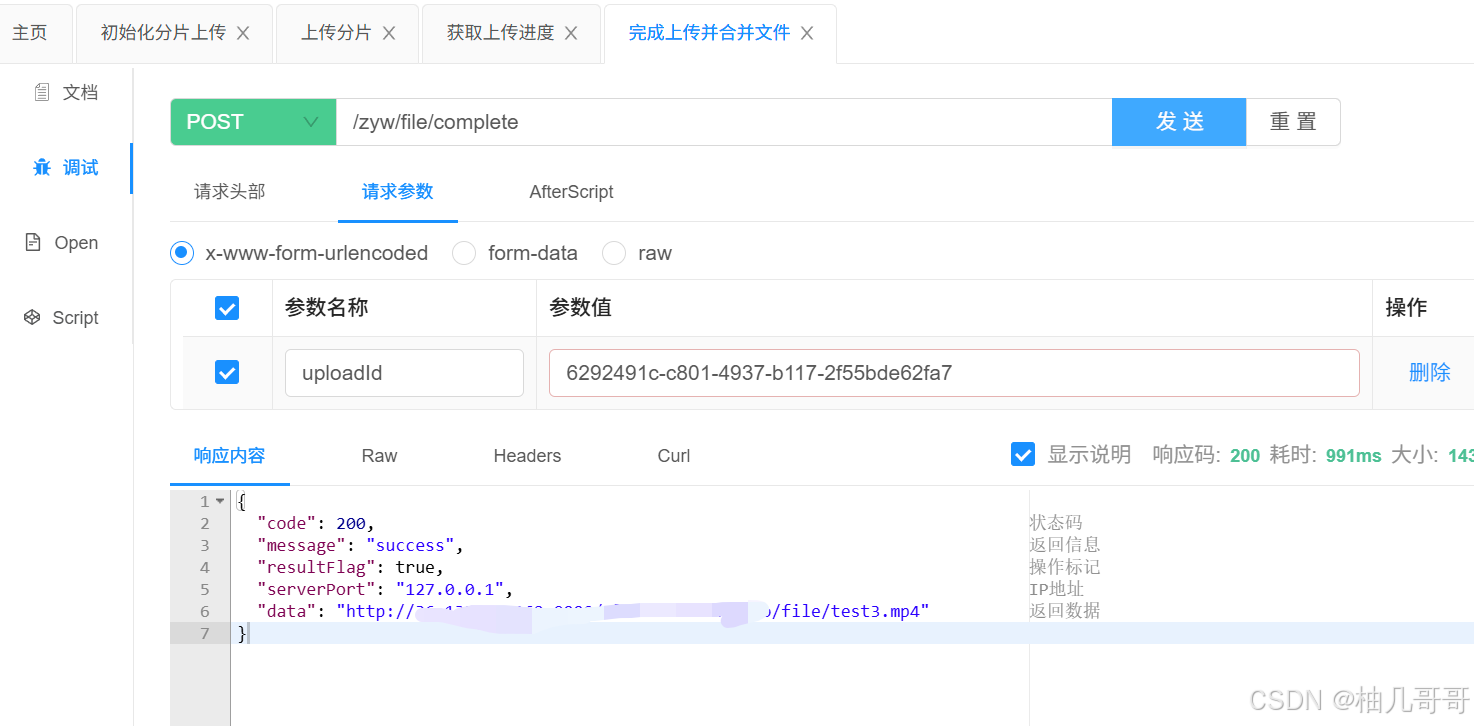
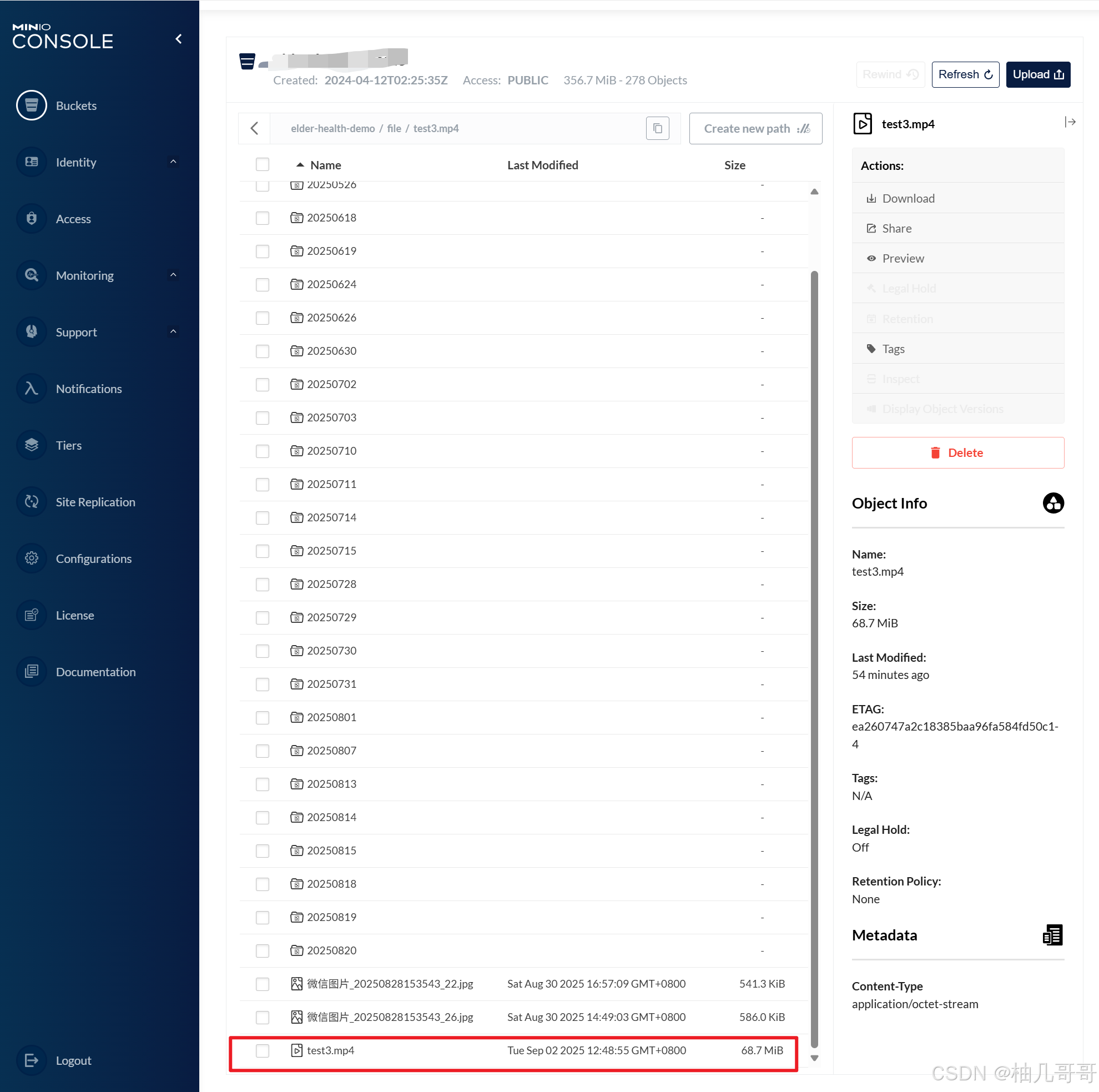
4. 查询上传进度 (/progress)
在上传过程中,客户端可以定时调用此接口来获取上传进度,用于前端显示进度条。
Service:
@Override
public FileUploadDTO.UploadProgressResponse getUploadProgress(String uploadId) {UploadStatus status = getUploadStatus(uploadId);return new FileUploadDTO.UploadProgressResponse(status.getUploadedChunks().size(), // 已上传数status.getTotalChunks(), // 总数status.getUploadedChunks() // 已上传的编号集合);
}private UploadStatus getUploadStatus(String uploadId) {// 从Redis获取基础状态UploadStatus status = (UploadStatus) redisTemplate.opsForValue().get(RedisKeyUtil.getUploadKey(uploadId));if (status == null) {throw new BaseException(ResultCode.CHUNK_ID_NOT_EXIST);}// 从Redis Set中获取已上传的分块编号,并设置到状态对象中Set<Object> uploadedChunks = redisTemplate.opsForSet().members(RedisKeyUtil.getUploadKey(uploadId) + ":chunks");if (uploadedChunks != null) {status.setUploadedChunks(uploadedChunks.stream().map(o -> Integer.parseInt(o.toString())) // 注意类型转换.collect(Collectors.toSet()));}return status;
}
四、断点续传工作流程
此方案如何实现断点续传?流程如下:
- 客户端首次上传文件前,调用
/init获取uploadId。 - 开始上传分块。假设在上传到第 50 个分块时网络中断。
- 网络恢复后,客户端可以先调用
/progress?uploadId=xxx查询进度。 - 接口返回
{uploadedChunks: 49, totalChunks: 100, uploadedChunkNumbers: [0,1,2,...,48]}。 - 客户端得知前 50 个块(0-49)中,第 49 块(索引从0开始)还未成功上传,于是从第 49 块开始继续上传,而不需要重传 0-48 块。
- 所有分块上传完成后,调用
/complete完成合并。
五、方案优势总结
- 提升稳定性:网络中断后可从断点继续,避免重复劳动和流量浪费。
- 减轻服务器压力:分块上传变小请求,降低服务器内存和IO压力。MinIO 服务端合并,效率极高。
- 提升用户体验:前端可以实时显示精确的上传进度条。
- 清晰的责任分离:四个接口职责单一,逻辑清晰,易于维护和扩展。
六、拓展优化
- 分块大小:需要根据实际网络情况和文件大小调整
chunkSize(例如 5MB 或 10MB),在减少请求次数和降低单次失败成本之间取得平衡。 - 异常处理与重试:在
uploadChunk方法中,可以实现更强大的重试机制,例如最多重试 3 次。 - 过期清理:需要有一个定时任务,清理 Redis 中超过一定时间(如 24 小时)仍未完成的
UploadStatus以及 MinIO 中对应的临时分块文件,避免存储资源浪费。 - 安全性:可以对
uploadId进行校验,确保用户只能操作自己发起的上传任务。
七、方案优势对比
传统方案 vs 分块断点续传方案
| 方面 | 传统单次上传 (Traditional) | 分块断点续传 (Chunked & Resumable) |
|---|---|---|
| 网络中断 | 完全失败,需从头开始重传 | 从中断点继续,仅需传剩余分块 |
| 进度反馈 | 难以实现精确的进度条 | 实时精确的进度反馈 |
| 服务器压力 | 长时间占用连接,内存IO压力大 | 分块小请求,压力分散,服务端合并高效 |
| 用户体验 | 差,失败成本高 | 优,可控且可靠 |