PyTorch实战——GoogLeNet与Inception详解
PyTorch实战——GoogLeNet与Inception详解
- 0. 前言
- 1. Inception 模块
- 2. 1x1 卷积
- 3. 全局平均池化
- 4. 辅助分类器
- 5. Inception V1
- 6. Inception v3
- 相关链接
0. 前言
从 LeNet 到 VGG,我们已经观察到卷积神经网络 (Convolutional Neural Network, CNN) 模型的演进过程:通过堆叠更多的卷积层和全连接层,构建需要训练更多参数的深度神经网络。GoogLeNet 的出现则带来了一种截然不同的 CNN 架构,其核心是由并行卷积层组成的模块——Inception 模块。因此,GoogLeNet 也称为 Inception v1。GoogLeNet 引入了一些全新的设计元素,包括:
Inception模块:由多个并行卷积层组成的模块1x1卷积:用于减少模型参数数量- 全局平均池化:替代全连接层,减少过拟合
- 辅助分类器:用于正则化和梯度稳定
GoogLeNet 有 22 层,比任意 VGG 模型的层数都要多。然而,由于采用了一些优化技巧,GoogLeNet 的参数数量仅为 500 万,远低于 VGG 的 1.38 亿参数量。接下来,我们将详细介绍 GoogLeNet 模型的关键特性。
1. Inception 模块
GoogLeNet 最重要的贡献之一是提出了由多个并行卷积层组成的卷积模块,这些卷积层最终被拼接成一个输出向量。这些并行卷积层使用不同的卷积核大小(从 1x1 到 3x3 再到 5x5),旨在从图像中提取多层次的视觉信息。此外,采用 3x3 的最大池化层进一步增强了特征提取能力。下图展示了 Inception 模块及 GoogLeNet 的整体架构:

基于该架构图,使用 PyTorch 实现 Inception 模块:
class InceptionModule(nn.Module):def __init__(self, input_planes, n_channels1x1, n_channels3x3red, n_channels3x3, n_channels5x5red, n_channels5x5, pooling_planes):super(InceptionModule, self).__init__()# 1x1 convolution branchself.block1 = nn.Sequential(nn.Conv2d(input_planes, n_channels1x1, kernel_size=1),nn.BatchNorm2d(n_channels1x1),nn.ReLU(True),)# 1x1 convolution -> 3x3 convolution branchself.block2 = nn.Sequential(nn.Conv2d(input_planes, n_channels3x3red, kernel_size=1),nn.BatchNorm2d(n_channels3x3red),nn.ReLU(True),nn.Conv2d(n_channels3x3red, n_channels3x3, kernel_size=3, padding=1),nn.BatchNorm2d(n_channels3x3),nn.ReLU(True),)# 1x1 conv -> 5x5 conv branchself.block3 = nn.Sequential(nn.Conv2d(input_planes, n_channels5x5red, kernel_size=1),nn.BatchNorm2d(n_channels5x5red),nn.ReLU(True),nn.Conv2d(n_channels5x5red, n_channels5x5, kernel_size=3, padding=1),nn.BatchNorm2d(n_channels5x5),nn.ReLU(True),nn.Conv2d(n_channels5x5, n_channels5x5, kernel_size=3, padding=1),nn.BatchNorm2d(n_channels5x5),nn.ReLU(True),)# 3x3 pool -> 1x1 conv branchself.block4 = nn.Sequential(nn.MaxPool2d(3, stride=1, padding=1),nn.Conv2d(input_planes, pooling_planes, kernel_size=1),nn.BatchNorm2d(pooling_planes),nn.ReLU(True),)def forward(self, ip):op1 = self.block1(ip)op2 = self.block2(ip)op3 = self.block3(ip)op4 = self.block4(ip)return torch.cat([op1,op2,op3,op4], 1)
2. 1x1 卷积
在 Inception 模块中,除了并行的卷积层外,每个并行层前都有一个 1x1 卷积层。使用 1x1 卷积的主要目的是降维。1x1 卷积不会改变图像的宽度和高度,但可以改变图像的深度。这一技巧用于在进行 1x1、3x3 和 5x5 卷积之前减少输入特征的深度,从而减少参数数量,构建更轻量级的模型并防止过拟合。
3. 全局平均池化
从 GoogLeNet 整体架构中可以看到,模型的倒数第二层是一个 7x7 的平均池化层。该层进一步减少了模型的参数数量,从而降低了过拟合的风险。如果没有这一层,模型将因全连接层的密集连接而增加数百万个参数。
4. 辅助分类器
GoogLeNet 整体架构中还展示了模型中的两个额外输出分支,即辅助分类器。这些辅助分类器通过增加反向传播时的梯度幅度,解决了梯度消失问题,尤其是靠近输入端的层。由于 GoogLeNet 层数较多,梯度消失可能成为一个主要限制。因此,辅助分类器在这个 22 层的深度模型中非常有用。此外,辅助分支还起到了正则化的作用。需要注意的是,这些辅助分支在预测时会被关闭或丢弃。
5. Inception V1
定义好 Inception 模块后,就可以轻松实现整个 Inception v1 模型:
class GoogLeNet(nn.Module):def __init__(self):super(GoogLeNet, self).__init__()self.stem = nn.Sequential(nn.Conv2d(3, 192, kernel_size=3, padding=1),nn.BatchNorm2d(192),nn.ReLU(True),)self.im1 = InceptionModule(192, 64, 96, 128, 16, 32, 32)self.im2 = InceptionModule(256, 128, 128, 192, 32, 96, 64)self.max_pool = nn.MaxPool2d(3, stride=2, padding=1)self.im3 = InceptionModule(480, 192, 96, 208, 16, 48, 64)self.im4 = InceptionModule(512, 160, 112, 224, 24, 64, 64)self.im5 = InceptionModule(512, 128, 128, 256, 24, 64, 64)self.im6 = InceptionModule(512, 112, 144, 288, 32, 64, 64)self.im7 = InceptionModule(528, 256, 160, 320, 32, 128, 128)self.im8 = InceptionModule(832, 256, 160, 320, 32, 128, 128)self.im9 = InceptionModule(832, 384, 192, 384, 48, 128, 128)self.average_pool = nn.AvgPool2d(7, stride=1)self.fc = nn.Linear(4096, 1000)def forward(self, ip):op = self.stem(ip)out = self.im1(op)out = self.im2(op)op = self.maxpool(op)op = self.a4(op)op = self.b4(op)op = self.c4(op)op = self.d4(op)op = self.e4(op)op = self.max_pool(op)op = self.a5(op)op = self.b5(op)op = self.avgerage_pool(op)op = op.view(op.size(0), -1)op = self.fc(op)return op
除了实例化自定义模型外,我们还可以加载预训练的 GoogLeNet 模型:
import torchvision.models as models
model = models.googlenet(weights=models.GoogLeNet_Weights.DEFAULT)
6. Inception v3
在 GoogLeNet 之后,还开发了多个 Inception 版本,其中 Inception v3 是一个重要的改进版本。它进一步优化了模型结构,引入了更高效的卷积分解和正则化技术,提升了模型的性能和效率。
Inception v3 是 Inception v1 的改进,其参数数量从 v1 的 500 万增加到了 2400 万。除了增加了更多的层,Inception v3 模型还引入了多种不同的 Inception 模块,这些模块按顺序堆叠在一起。下图展示了不同的 Inception 模块及完整的模型架构:
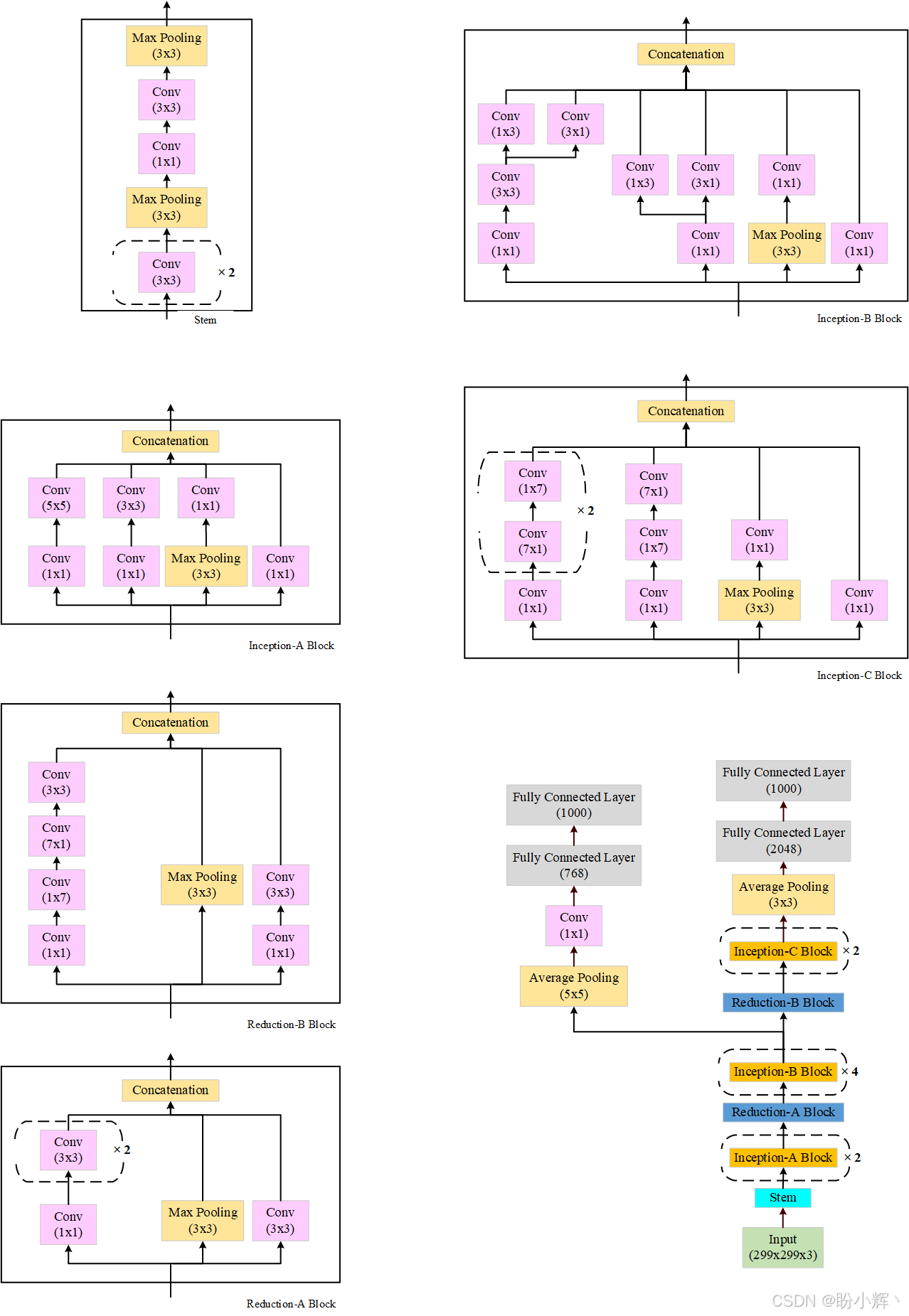
从架构中可以看出,Inception v3 是 Inception v1 模型的架构扩展。同样,除了手动构建模型外,我们还可以使用 PyTorch 提供的预训练模型:
import torchvision.models as models
model = models.inception_v3(weights=models.Inception_V3_Weights.DEFAULT)
相关链接
PyTorch实战(1)——深度学习概述
PyTorch实战(2)——使用PyTorch构建神经网络
PyTorch实战(3)——PyTorch vs. TensorFlow详解
PyTorch实战(4)——卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)——深度卷积神经网络
PyTorch实战(6)——模型微调详解