【Unity Shader学习笔记】(二)图形显示系统
一、图形显示系统的基本流程
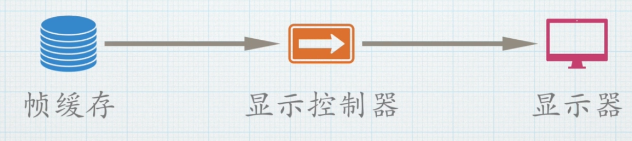
- 帧缓存:是显卡内存中的一块特定区域,专门用来存储即将要显示在屏幕上的一整帧图像的所有像素数据。渲染管线的最终目的就是把计算好的颜色值写入这个内存区域。每个像素的颜色信息(如RGBA值)都按顺序存放在这里。为了保证画面流畅,通常至少会有两个帧缓存:
前台缓存:正在被显示控制器读取并发送到显示器的帧缓存。这是当前屏幕上你正在看到的内容。
后台缓存:正在被图形渲染管线绘制的下一帧图像。程序(如游戏)总是在后台缓存上进行绘制。
- 显示控制器:它是显卡上的一个专用硬件组件,也称为视频定时控制器。他的任务就是从画室(显存)里拿起已经完成的画(前台缓存),以精确的速度跑到画布(显示器)前,严格按照从上到下、从左到右的顺序,把画上的每一个点复制到画布上。他每秒要重复这个过程60、144甚至更高次数(取决于刷新率)。
- 显示器:就是我们看到的物理屏幕(LCD、OLED等),接收显示控制器发来的信号,并根据信号指令控制每个物理像素点的亮度和颜色,从而将数字图像变为可见光。
二、早期的光栅扫描显示系统
在计算机图形学的早期,显示图像是一项复杂而精密的机械过程。
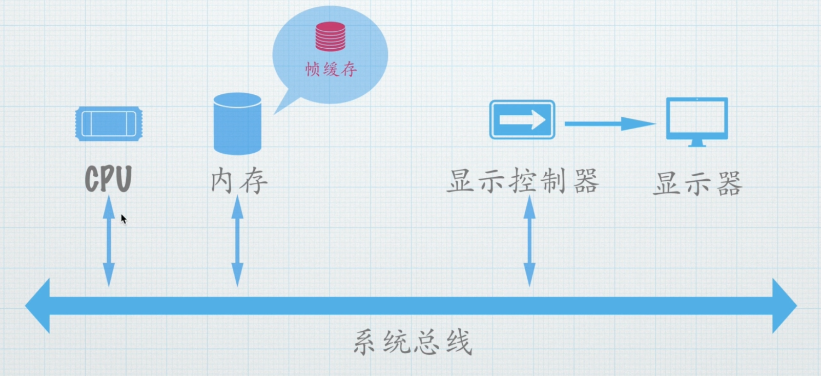
核心原理:电子枪像画笔一样,从屏幕左上角开始,一行一行地从左到右、从上到下地扫描整个屏幕,通过激发荧光粉来发光形成图像。
关键挑战:这个过程不能中断。一旦电子枪开始扫描,就必须持续不断地为它提供数据,否则画面就会闪烁或不完整。
解决方案:早期的计算机没有专门的图形处理器。沉重的负担全部压在中央处理器上。CPU需要亲自计算每个像素的颜色,并在电子枪扫描到那个像素的精确时刻,将颜色数据通过内存总线发送给显示器。
比喻:这就像让一位交响乐指挥家(CPU) 不仅要指挥整个乐团,还要亲自去拉第一小提琴,并在间隙跑去吹小号。效率低下,严重限制了图形能力的发展。
三、现代的光栅扫描显示系统
为了解决上述瓶颈,计算机架构发生了革命性的变化:显卡诞生了。
核心进化:将所有的图形计算任务从CPU卸载到一个专用的硬件上——这就是显卡。
工作流程:
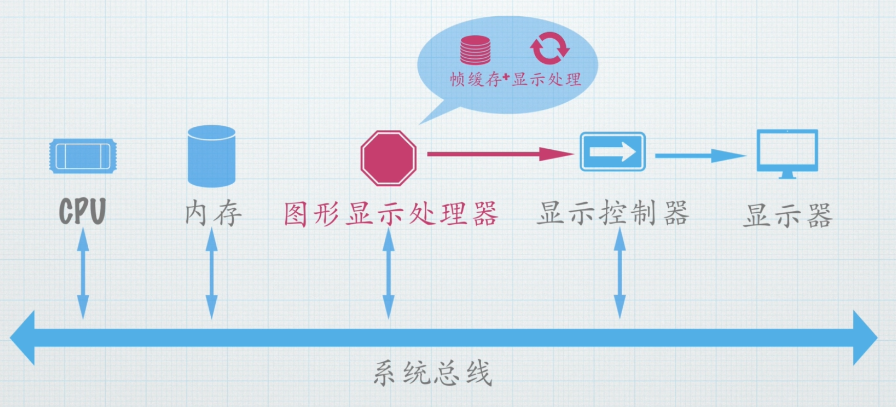
CPU(老板):发出高级指令,比如“在这个坐标画一个角色模型”。
GPU(图形经理):接收指令,调动其庞大的专业团队(大量核心)进行并行计算,完成建模、渲染、着色等所有复杂工作,将最终图像画在帧缓存里。
显示控制器(信使):以恒定节奏从帧缓存中读取数据,转换为信号发送给显示器。
显示器(画布):最终呈现图像。
意义:这种分工解放了CPU,让它能更好地处理系统逻辑、人工智能等更擅长的任务,而GPU则专注于海量的数学运算,使得复杂、逼真的实时图形成为可能。
四、显卡的心脏:GPU
GPU(Graphical Processing Unit)又称显示核心、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备上进行图像运算工作的微处理器。
定位:它不是一颗普通的处理器,而是一个高度专业化的并行计算怪兽。它的整个架构都是为了处理与构建图像相关的海量数学计算而设计的。
五、GPU的架构哲学:人多力量大
CPU和GPU的设计理念完全不同,这造就了它们截然不同的优缺点。
| 特性 | CPU | GPU |
| 核心设计 | 少量强大的“大脑” | 成千上万个简单的“小学生” |
| 擅长领域 | 复杂逻辑控制、串行任务、通用计算 | 大规模并行计算、简单但重复的任务 |
| 比喻 | 一位博士,能独立解决非常复杂的数学难题。 | 一万个小学生,每人只做一道简单的加法题,但一秒内就能全部算完。 |
| 优点 | 灵活性高,处理复杂任务能力强 | 核多力量大,极其擅长浮点运算和并行计算,图形渲染速度极快 |
| 缺点 | 管理控制能力弱(让一万个小学生协同完成一个复杂项目非常困难),功耗相对较高 | 不擅长处理分支判断多、逻辑复杂的任务 |
六、GPU的供应商
如今的GPU市场主要由三大巨头主导:
- 英特尔:集成显卡之王。其GPU芯片通常与CPU封装在同一块芯片上,功耗低,足以满足日常办公、高清视频播放和轻度游戏的需求,是市场份额最大的图形处理器供应商。
- 英伟达:独立显卡的领导者。以其高性能的GeForce系列游戏显卡和专业领域的Quadro系列著称。技术在业界领先,尤其是其CUDA并行计算平台和实时光线追踪技术,深刻影响了行业的发展。
- AMD:有力的竞争者。收购了曾经的图形巨头ATI,提供Radeon系列独立显卡。其技术路线与英伟达竞争激烈,性价比突出。同时,AMD也生产将CPU和GPU高效融合的APU产品。