李宏毅NLP-13-Vocoder
大纲

简介
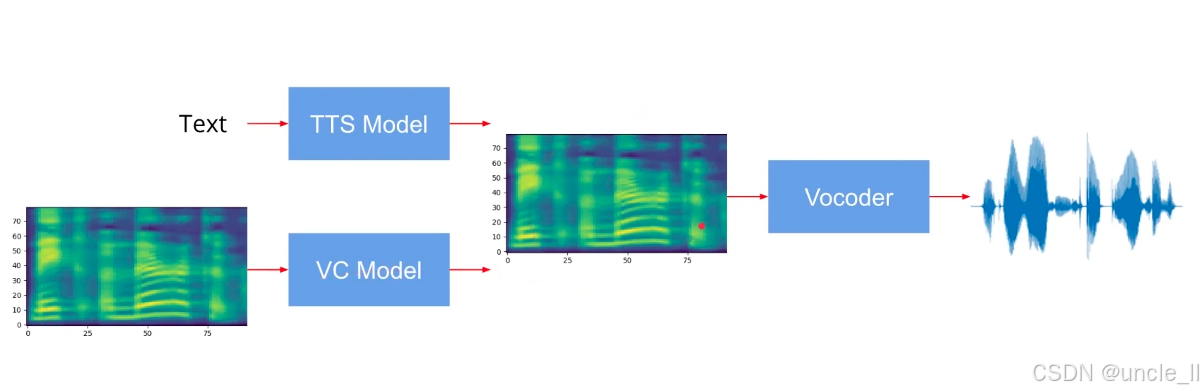
- TTS:文本→TTS 模型→目标频谱(直接从文本生成语音特征);
- VC:参考语音→VC 模型→转换后频谱(改变参考语音的音色,保留内容);
- 频谱图:是语音的 “中间表示”,包含 梅尔频谱(Mel-Spectrogram)等形式,能编码 “基频、谐波、共振峰” 等声学特征;
无论频谱来自 TTS 还是 VC,都通过Vocoder将 “频域特征” 逆转为 “时域声波”,得到可听的语音。
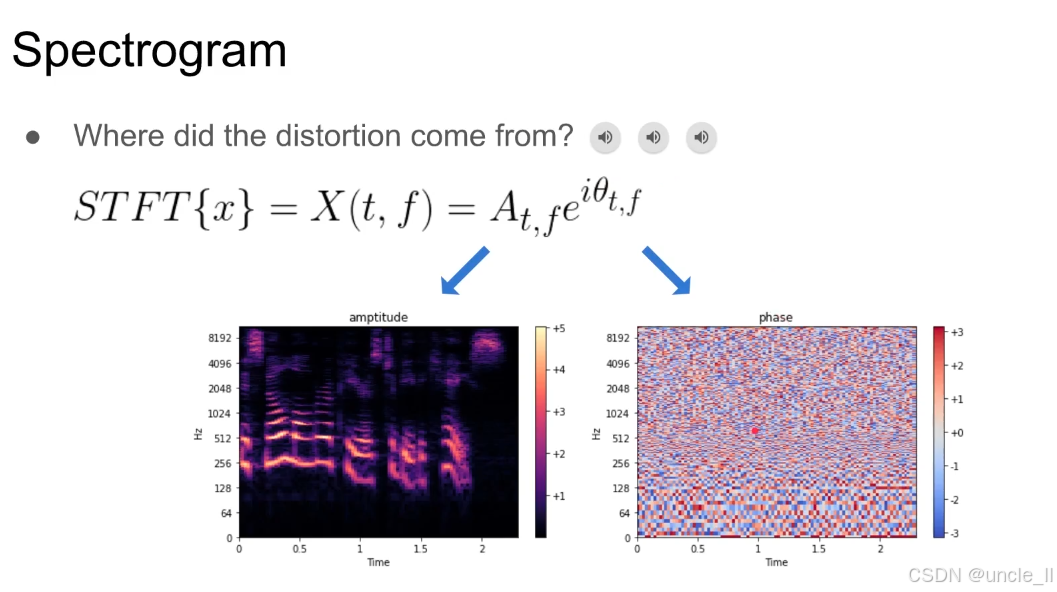
短时傅里叶变换(STFT)将时域语音信号 xxx 转换为时频域表示 X(t,f)X(t, f)X(t,f),其复数形式可分解为:
X(t,f)=At,feiθt,fX(t, f) = A_{t,f} e^{i\theta_{t,f}}X(t,f)=At,feiθt,f
-
At,fA_{t,f}At,f:幅度谱(Amplitude Spectrogram),表示频率 fff 在时刻 ttt 的能量强度;
-
θt,f\theta_{t,f}θt,f:相位谱(Phase Spectrogram),表示频率 fff 在时刻 ttt 的相位偏移;
-
eiθt,fe^{i\theta_{t,f}}eiθt,f:欧拉公式,将相位信息编码为复数的 “角度” 部分。
幅度谱(左图)
- 视觉特征:色彩明亮的热力图,高频(纵轴 Hz)和时间(横轴 Time)的能量分布清晰可见(如共振峰、谐波结构);
- 物理意义:直接对应人耳感知的 “响度” 和 “音色轮廓”,是传统语音处理(如 ASR、TTS)的核心特征。
相位谱(右图)
- 视觉特征:色彩斑驳的 “噪声状” ,相位值(色标从 - 3 到 + 3)无明显规律;
- 物理意义:描述信号的 “时间对齐” 和 “波形精细结构”,传统上因 “难以建模” 被忽视,但对波形自然度至关重要。

前端模型:TTS 或 Voice Conversion 生成声学特征(如频谱、梅尔谱);声码器(Vocoder)根据声学特征,生成最终的时域波形(即能听到的声音)。
传统方法: - Griffin-Lim 等早期声码器通过 “幅度主导 + 相位迭代” 生成波形,但相位恢复精度不足,导致失真;
现代方法:
- 用深度学习模型(如 GAN、Flow、Autoregressive 模型)学习 “声学特征→波形” 的映射;自然度高,可实时生成;
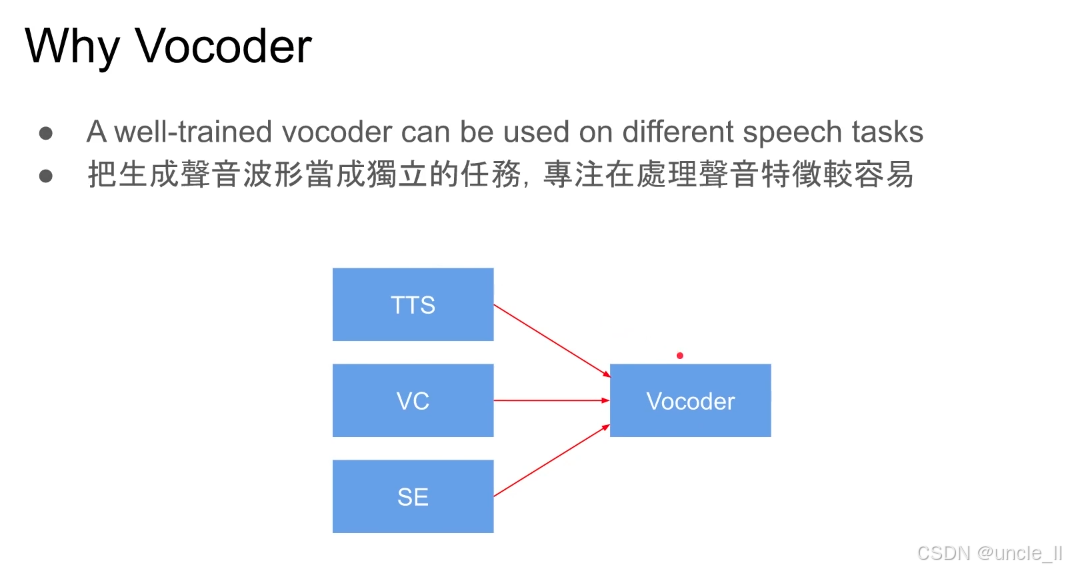
声码器(Vocoder)在语音技术中的核心价值,通过将 “波形生成” 任务独立化,实现跨场景复用和语音细节的精准优化:
-
经过良好训练的声码器可作为通用波形生成模块,适配多种语音任务,避免了为每个任务单独开发波形生成模块,降低了研发成本并提升了系统一致性:
-
TTS(文本转语音):将文本生成的声学特征(如梅尔谱)转换为语音波形;
-
VC(语音转换):将源说话人语音的声学特征转换为目标说话人音色的波形;
-
SE(语音增强):将去噪后的声学特征重构为清晰语音波形。
-
这种复用性避免了为每个任务单独开发波形生成模块,降低了研发成本并提升了系统一致性。
-
专注语音细节处理,把生成声音波形当成独立的任务,专注在处理声音特征较容易
-
独立任务拆分:将复杂的语音生成流程分解为 “声学特征生成” 和 “波形合成” 两个子任务,声码器专注后者;
-
细节优化优势:语音波形包含微小的声学细节,独立优化声码器可更高效地提升:
- 自然度:减少金属声、毛刺等失真;
- 保真度:保留语音的细微质感;
- 效率:通过专用模型实现实时波形生成。
-
Neural Vocoder
WaveNet
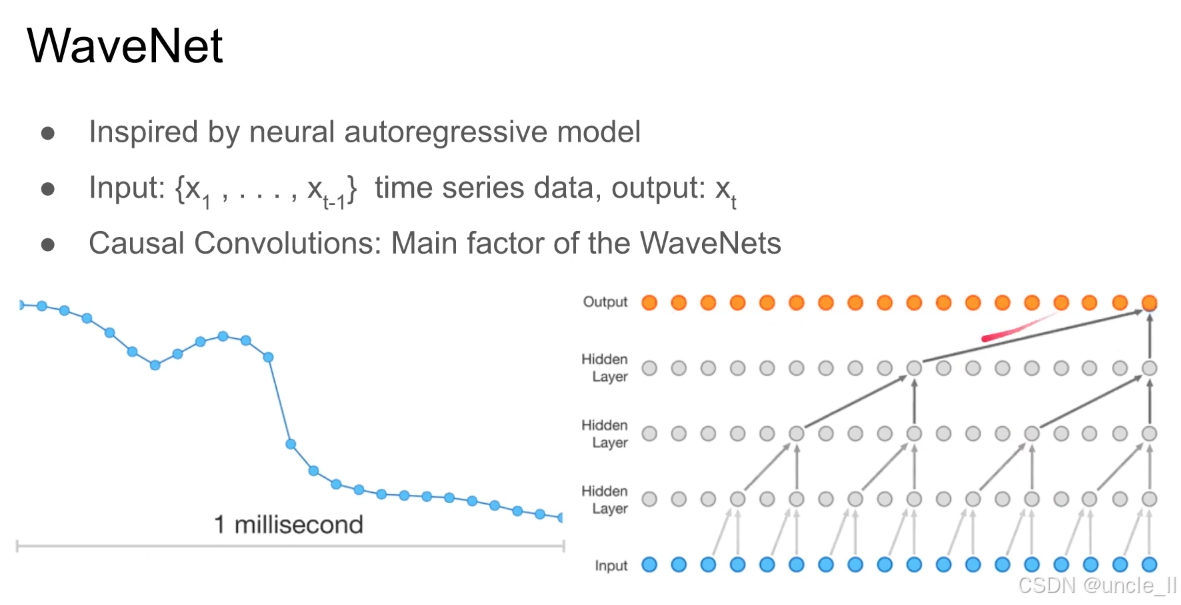
WaveNet,它是基于自回归思想的神经声学模型,核心是通过因果卷积(Causal Convolutions)逐点生成高保真语音波形:
WaveNet 受神经自回归模型启发,遵循 “过去预测未来” 的逻辑:
- 输入:时间序列的历史数据 {x1,x2,...,xt−1x_1,x_2,...,x_{t−1}x1,x2,...,xt−1}(已生成的波形点);
- 输出:下一个时刻的波形点 xtx_txt;
- 迭代生成:通过逐点生成,最终拼接出完整语音波形。
- 生成的 xtx_txt 会被 “反馈” 到输入层,作为历史数据继续生成 xt+1x_{t+1}xt+1,直到完整波形生成。
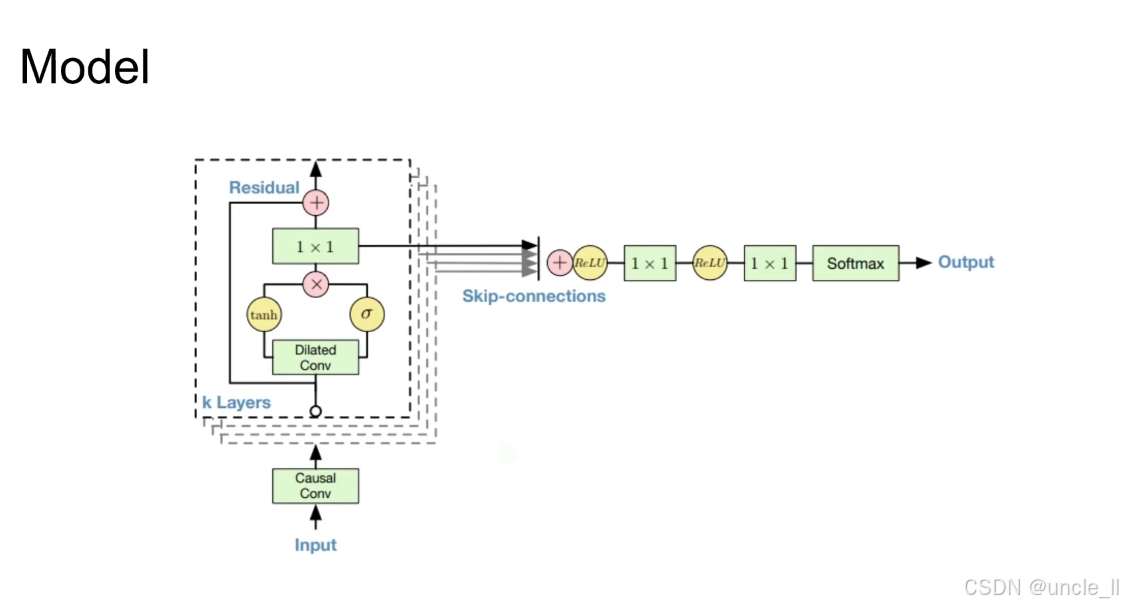
WaveNet 模型的核心架构,它是语音合成领域的经典自回归模型,通过 “因果卷积 + 膨胀卷积 + 残差连接 + 跳跃连接” 的组合,实现高保真语音波形的逐点生成:
-
输入层(Input)与因果卷积(Causal Conv)
-
输入:历史语音波形的时序数据;
-
因果卷积:确保 “当前时刻的计算只依赖过去的历史信息,不泄露未来信息” 。
-
-
膨胀卷积(Dilated Conv)与门控机制(tanh + σ)
-
膨胀卷积:通过 “间隔采样” 扩大卷积的感受野(即模型能 “看到” 的历史序列长度),无需增加参数量即可捕捉长时依赖(如语音的韵律、语调);
-
门控机制:用 tanh(捕捉特征)和 σ(sigmoid,控制特征流量)的乘积,模拟语音信号的时变特性(如音量起伏、发音快慢)。
-
-
残差连接(Residual)
- 每个膨胀卷积模块的输出与输入相加(
Residual +),缓解深层网络的梯度消失问题,让信息能高效传递到高层。
- 每个膨胀卷积模块的输出与输入相加(
-
跳跃连接(Skip-connections)
- 多个膨胀卷积模块的输出被 “跳跃式” 汇总,确保所有层级的特征都能参与最终预测,提升模型对细粒度语音特征的捕捉能力。
-
输出层(Output)
- 经过多层 1×1 卷积、ReLU 激活和 Softmax,输出 “下一个波形点” 的概率分布,实现逐点生成。

Softmax 分布在语音生成(如 WaveNet)中的应用,如何通过 “独热向量序列建模 +μ-law 压缩” 解决 “音频数据维度爆炸” 的问题:
输入输出形式
-
输入和输出是独热向量(one-hot vectors)序列,而非标量(scalers)。
- 例:语音波形的每个采样点被编码为独热向量,模型逐点生成序列。
-
概率建模:整个序列的概率 $ p(\mathbf{x}) $ 是 “每个时刻 $ t $ 条件概率 $ p(x_t | x_1, …, x_{t-1}) $” 的乘积:
$ p(\mathbf{x}) = \prod_{t=1}^T p(x_t | x_1, …, x_{t-1}) $
音频数据的高维度
- 音频采样:原始音频是16 位整数序列,范围为 [−32768,32767][-32768, 32767][−32768,32767](共 $ 32767 - (-32768) + 1 = 65536 $ 个可能值)。
- Softmax 层维度:若直接对每个采样点做 Softmax,输出层维度需为 65536(对应所有可能的采样值)。
- 问题:维度太大→参数量爆炸、训练 / 推理效率极低。
解决方案:μ-law 算法压缩
- 核心作用:将 16 位整数(65536 个值) 压缩为 8 位整数(256 个值),即 [−32768,32767]→[0,255][-32768, 32767] \rightarrow [0, 255][−32768,32767]→[0,255]
- 压缩逻辑:
- 对大动态范围的音频信号(如 loud 与 quiet 部分),通过非线性映射 “压缩大值、保留小值细节”;
- 使 Softmax 层维度从 65536 骤减到 256,大幅降低模型复杂度。
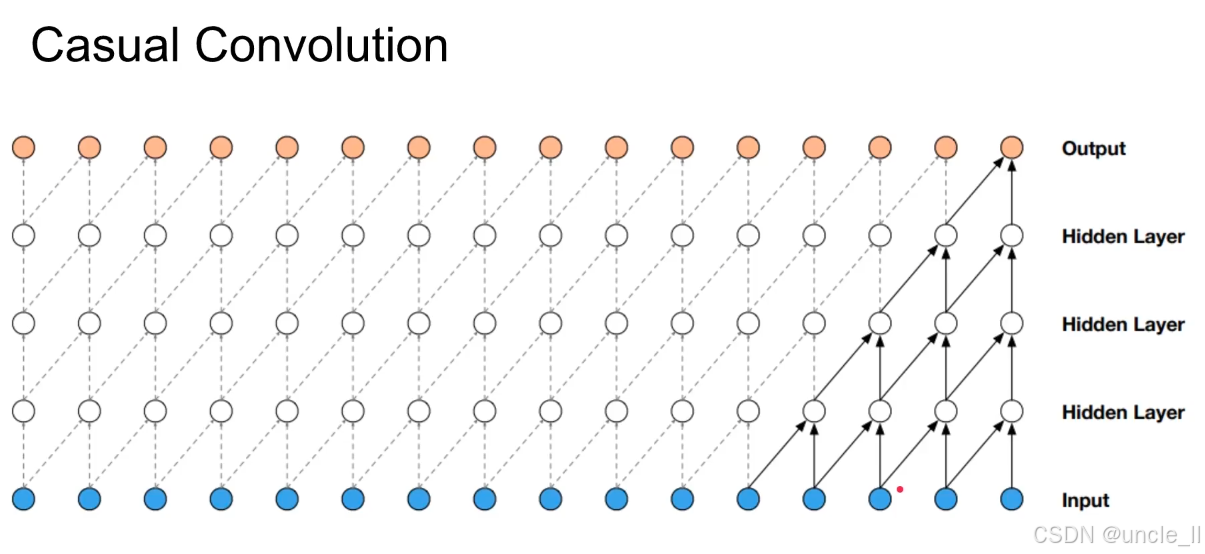
因果卷积(Causal Convolution)是一种特殊的卷积操作,确保模型在处理时序数据时 “只依赖过去信息,不泄露未来信息”。
输入层(Input,蓝色圆点)
- 代表时序输入序列(如语音波形的采样点、文本的字符),每个圆点对应一个时刻的输入值;
- 箭头方向:所有信息流严格从 “左→右”(过去→未来),无反向箭头。
隐藏层(Hidden Layer,白色圆点)
- 多层卷积层堆叠,每层通过卷积核提取时序特征;
- 卷积核作用范围:仅覆盖 “当前位置左侧” 的输入(含当前位置),例如:
- 底层隐藏层的某个白色圆点,仅接收其左侧若干蓝色输入点的信息;
- 上层隐藏层的圆点,仅接收其下方隐藏层 “左侧圆点” 的信息。
输出层(Output,橙色圆点)
- 最终生成的时序输出序列,每个橙色圆点对应 “基于历史输入预测的当前时刻值”;
- 生成逻辑:从左到右逐点生成,每个输出点仅依赖其左侧的输入和隐藏层状态。
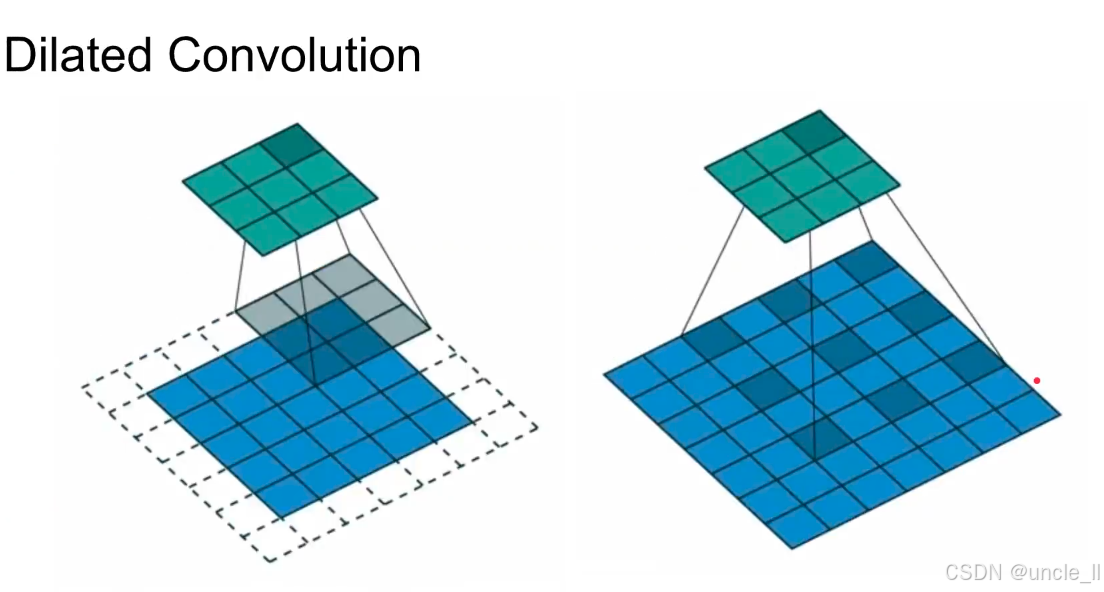
膨胀卷积(Dilated Convolution) 它是一种特殊的卷积操作,通过 “间隔采样” 扩大卷积的感受野(即模型能 “看到” 的输入范围),同时不增加参数量。膨胀卷积通过设置膨胀率(Dilation Rate) 控制 卷积核覆盖输入时的间隔,从而在不增加卷积核大小的前提下,让模型能看到更远的输入。
左图:普通卷积
- 卷积核覆盖:3×3 卷积核直接覆盖相邻的 9 个输入单元(灰色区域);
- 感受野:较小(仅局部区域),适合捕捉短距离依赖。
右图:膨胀卷积(Dilation Rate > 1)
- 间隔采样:卷积核以间隔 1 的方式覆盖输入(蓝色区域),相当于用更大的 虚拟卷积核 捕捉信息;
- 感受野扩大:相同大小的卷积核,能覆盖更广阔的输入区域(如膨胀率为 2 时,3×3 卷积的感受野等效于 5×5 普通卷积);
- 无参数量增加:仅改变采样间隔,不增加卷积核参数,高效且节省算力。
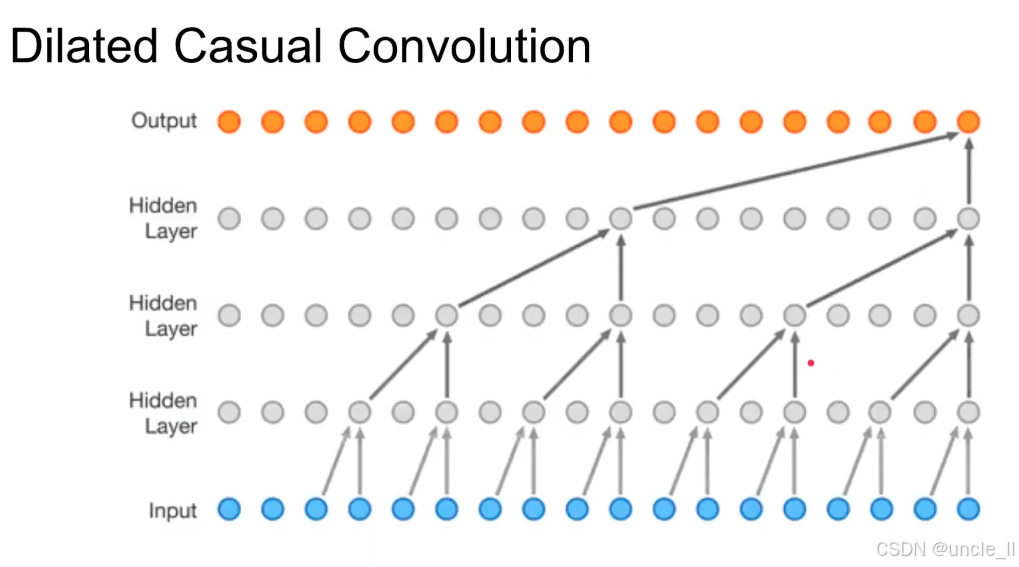
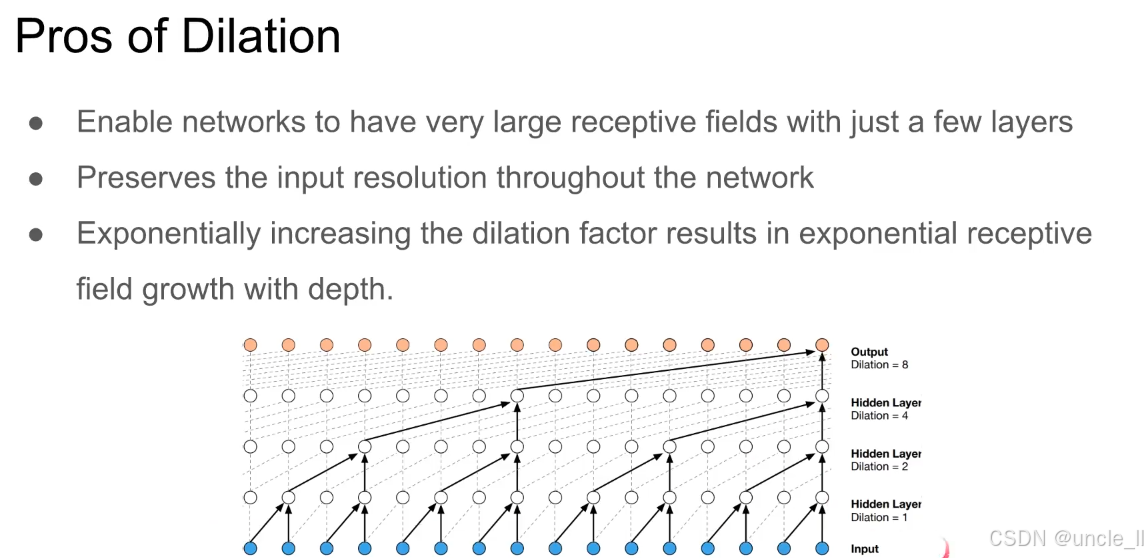
膨胀因果卷积(Dilated Casual Convolution) 是 “膨胀卷积” 与 “因果卷积” 的结合,同时具备两种特性:
- 因果性:当前输出仅依赖过去的输入(无未来信息泄露,符合 “过去预测未来” 的自回归逻辑);
- 长距离感受野:通过膨胀采样,让模型能看到更远的历史输入(捕捉长时语音韵律、语调等特征)。
隐藏层多层膨胀卷积层堆叠,每层通过间隔采样(膨胀率 > 1)扩大感受野;
膨胀卷积(Dilation) 的三大优势:
-
小层数实现大感受野
-
膨胀卷积能让网络仅用少量层,就获得极大的感受野(即模型能 “看到” 的输入范围)。
-
对比:普通卷积需堆叠多层才能覆盖长距离,而膨胀卷积通过 “间隔采样”,单层即可覆盖更远输入。
-
-
保持输入分辨率
-
膨胀卷积不改变输入的 “空间 / 时序分辨率”(如语音波形的采样率、图像的像素数)。
-
对比:池化(Pooling)会降低分辨率,膨胀卷积则能在 “不压缩输入” 的前提下扩大感受野。
-
-
感受野指数级增长
-
若膨胀因子(Dilation Factor)指数级增加(如 1→2→4→8),感受野会随网络深度指数级扩大。
-
例:图中隐藏层膨胀因子从 1→2→4→8,输出层感受野覆盖极长的输入序列。
-

带条件的 WaveNet(Conditional WaveNet) 在原始 WaveNet(自回归生成语音波形)的基础上,加入额外的条件信号,让生成的语音 “受条件控制”(例如:用文本作为条件生成指定内容的语音,或用说话人特征控制音色)。
- 全局条件:让整个波形生成过程受 “全局特征” 控制(如统一的说话人音色、文本的整体风格)。
- 局部条件:让波形的 “逐点生成” 受 “局部细粒度特征” 控制(如每帧的韵律、文本的逐字发音)。

核心技术特点:
-
直接在波形级别操作
-
区别于传统 “先提取特征再合成波形” 的两阶段方法,WaveNet直接对原始语音波形(时域信号)进行建模与生成;
-
优势:保留语音最精细的细节,合成语音自然度更高。
-
-
因果滤波器与膨胀卷积结合
-
因果滤波器(Causal filters):确保 当前时刻的生成仅依赖过去的历史信息(无未来信息泄露,符合自回归逻辑);
-
膨胀卷积(Dilated convolutions):通过 间隔采样”让模型的感受野(Receptive fields)随深度指数级增长;
-
关键价值:能高效建模音频信号的长时依赖关系。
-
-
可结合其他输入(全局 / 局部条件
-
支持引入额外条件信号(如说话人特征、文本内容),实现 “可控语音生成”;
-
例:Conditional WaveNet 通过全局条件控制说话人音色,通过局部条件控制逐帧发音内容。
-
实际应用优势:
- 在真实场景任务中表现优异,如:
- 语音合成(TTS):生成接近真人的自然语音;
- 语音转换(VC):实现高保真的音色转换;
- 语音增强:有效修复噪声污染的语音。
局限性
- 推理速度慢;
- 原因:自回归生成的天然缺陷 —— 必须按时间顺序逐点计算,无法并行,导致实时性差。
FFTNet

FFTNet(快速傅里叶变换网络),它是针对文本转语音(TTS)任务的一种新型模型,主要围绕 “提速” 和 “提升音质” 展开:FFTNet 则通过算法优化,大幅提升了语音生成的实时性。展示了一些训练和合成技术,这些技术能同时提升 WaveNet 和 FFTNet 生成音频的质量
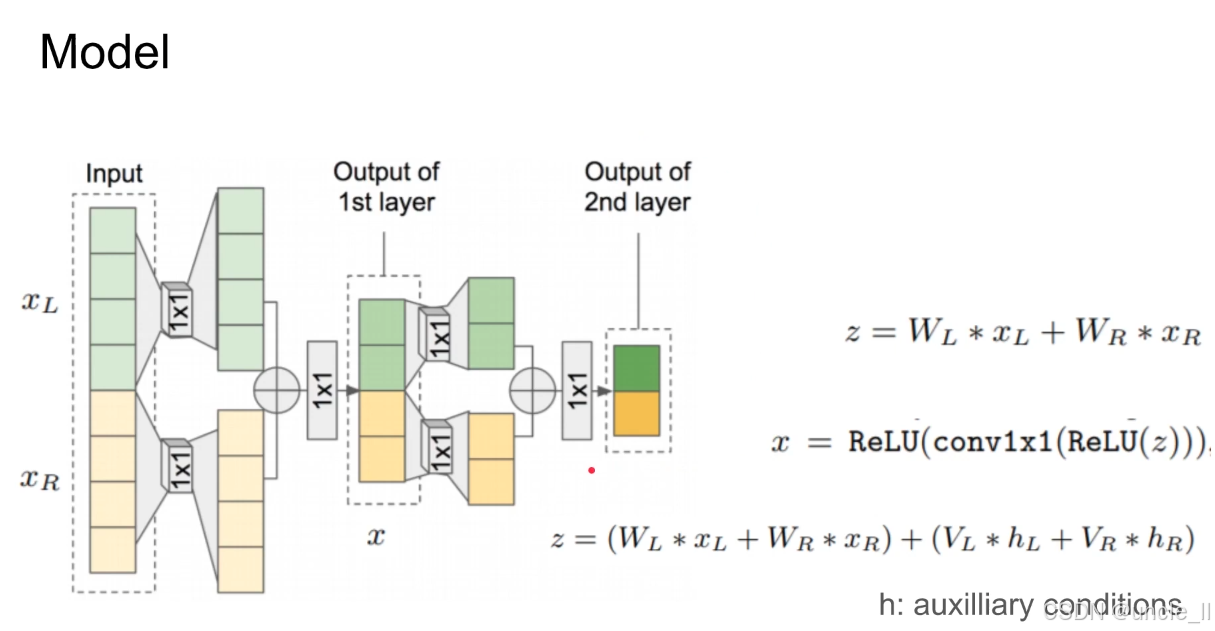
模型通过 线性组合多源特征 + 注入辅助条件,让生成过程既利用多维度输入信息,又能被外部条件(如文本、风格)精准控制,是 “可控生成” 类任务的典型技术思路。

FFTNet(快速傅里叶变换网络)用于提升模型训练效果或最终音频质量的技巧:
1. Zero padding(零填充)
- 说明:训练时,在音频的开头填充零。
- 目的:调整音频长度(使输入满足模型固定长度要求),或为模型提供 “起始阶段” 的稳定输入(避免开头部分因缺乏历史信息导致生成不稳定)。
2. Conditional sampling(条件采样)
- 核心:采样过程受额外条件控制(如说话人特征、文本内容等)。
- 作用:让生成的音频 “符合指定条件”(如用特定说话人音色生成语音、按文本内容生成对应语音)。
3. Injected noise(注入噪声)
- 说明:训练时,向输入 x 中注入高斯噪声,但目标真实标签保持 “干净”。
- 目的:增强模型的鲁棒性(让模型在有噪声的输入下也能学习到核心特征),同时提升生成音频的 “自然随机性”(避免生成结果过于僵硬)。
4. Post-synthesis denoising(合成后去噪)
- 说明:对生成的有声音频(voiced audio,如包含元音的语音),应用频谱减法(spectral subtraction) 进行降噪。
- 作用:去除生成音频中可能存在的 “合成噪声”,提升最终音频的清晰度和自然度。

FFTNet 的核心价值是 速度突(比 WaveNet 快,甚至 CPU 实时),但 音质与 WaveNet 相当的结论缺乏复现性;不过,其衍生的训练技巧和 “改进版 FFT + 的高 MOS”,仍为自回归语音生成的优化提供了思路。
WaveRNN

WaveRNN 将 16 位音频拆分为 高位(Coarse) 和 低位(Fine)”两部分,各用 8 位表示(范围 0∼255):
- 高位(Coarse, ctc_tct):对应更重要的位(More significant),决定音频的 大体幅值范围;
- 低位(Fine, ftf_tft):对应次要的位(Less significant),补充 精细的幅值细节。
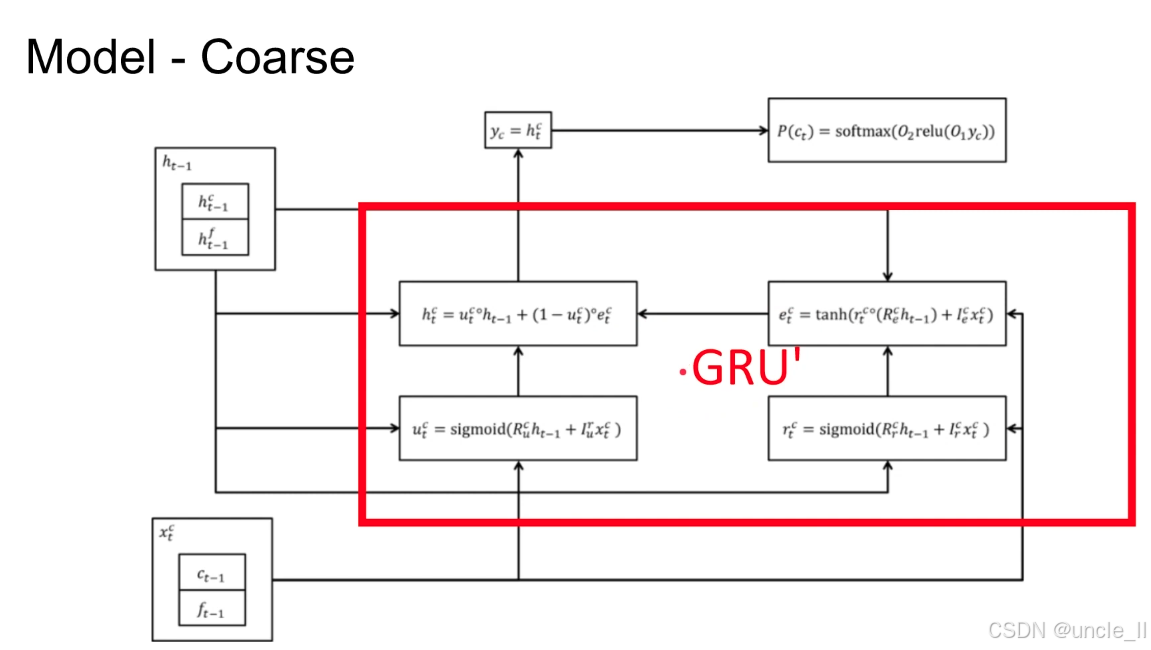
Coarse 分支 是 WaveRNN 双 Softmax 分层建模的核心:
- 先通过 GRU 捕捉音频的宏观幅值特征(粗粒度);
- 再结合 Fine 分支补充 “微观细节”,最终实现 “高效且高保真” 的音频生成。
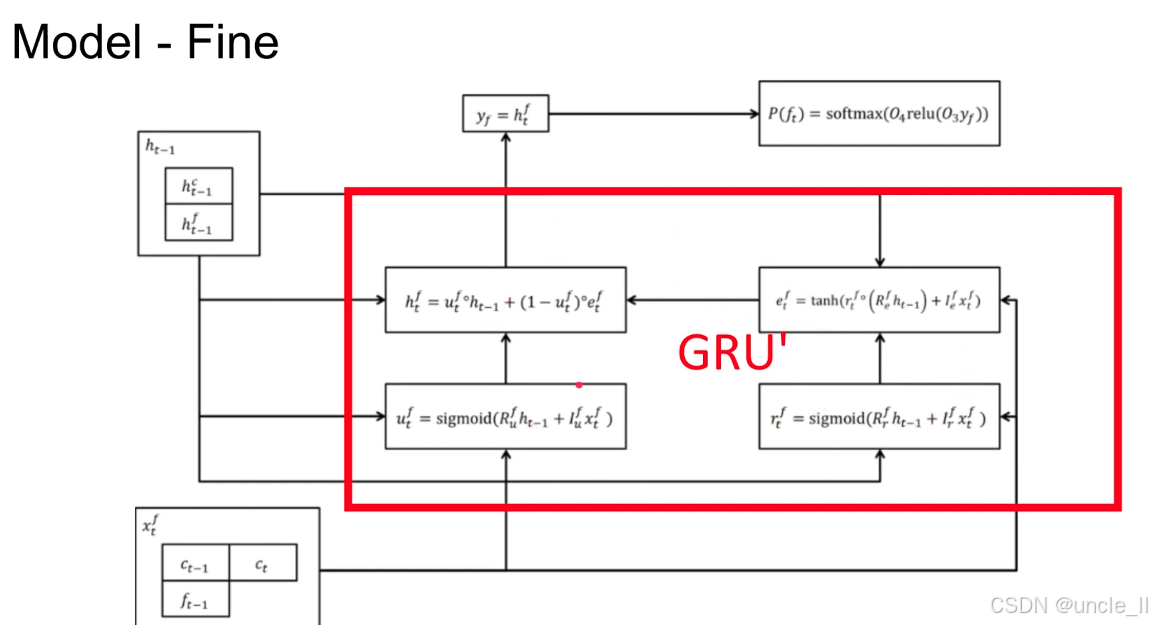
细粒度分支的输入包含 “当前时刻粗粒度输出ctc_tct,说明细粒度细节需基于粗粒度的宏观幅值生成(如先确定声音大概有多响,再细化响度的微小波动);
分层建模:Coarse 分支捕捉音频的骨架幅值范围,Fine 分支补充骨架上的纹理细节波动,两者结合实现 “高效 + 高保真” 的 16 位音频生成(对比直接建模 65536 维更轻量)。

WaveRNN 模型的加速方法,通过稀疏化和子尺度优化等技术,实现移动端 CPU 的实时语音生成:
-
Sparse WaveRNN(稀疏化 WaveRNN)
- Weight Sparsification Method(权重稀疏化方法):对模型的权重进行稀疏化处理(即让大量权重为 0),减少计算时的乘法操作,提升推理速度;
- Structured Sparsity(结构化稀疏):不仅让权重稀疏,还保证稀疏的结构性(如按行、列或块稀疏),使硬件(如 CPU)能利用稀疏性进行高效并行计算。
-
Subscale WaveRNN(子尺度 WaveRNN)
-
Subscale dependency scheme(子尺度依赖策略):将音频生成的长时序依赖拆解为子尺度的短依赖,降低模型的记忆负担,加速推理;
-
Batched sampling(批量采样):同时对多个子尺度的语音片段进行采样,利用批量计算提升效率(类似并行处理多个小任务)。
-
通过上述稀疏化和子尺度优化,WaveRNN 能在移动设备的 CPU上实现 实时语音生成
WaveGlow
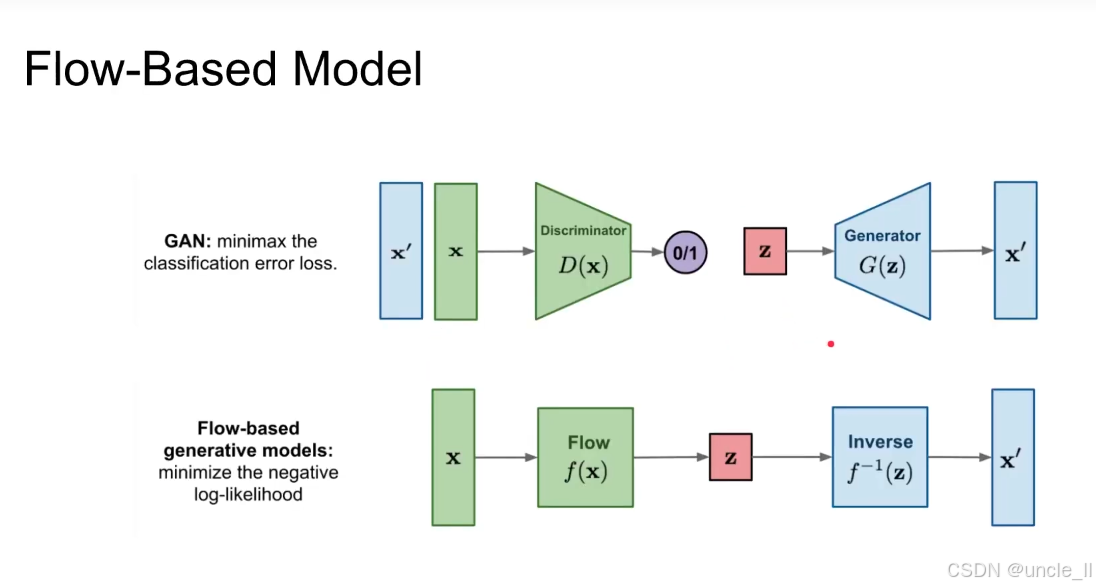
生成对抗网络(GAN)
-
生成器(Generator, G):输入随机噪声 ,生成伪造样本 ;
-
判别器(Discriminator, D):输入真实样本 或伪造样本,输出 “属于真实样本的概率”(0/1 二分类)。
-
极小极大博弈(minimax the classification error loss):
- 生成器目标:生成尽可能逼真的样本,最小化判别器的分类准确率(让判别器无法区分真假);
- 判别器 目标:最大化对真假样本的分类准确率(正确区分真实与伪造样本);
- 数学上通过极小极大损失函数实现。
基于流的生成模型(Flow-Based Model)
-
流变换(Flow):输入真实样本,通过可逆变换(双射函数)将其映射到隐空间的简单分布(如高斯分布);
-
逆变换(Inverse):输入隐空间噪声,通过流变换的逆操作生成样本。
-
最小化负对数似然(minimize the negative log-likelihood):
- 核心思想:通过可逆变换,让真实样本 在隐空间 的分布尽可能接近简单分布(如高斯分布);
- 数学上通过最大化 “数据的对数似然” 实现。
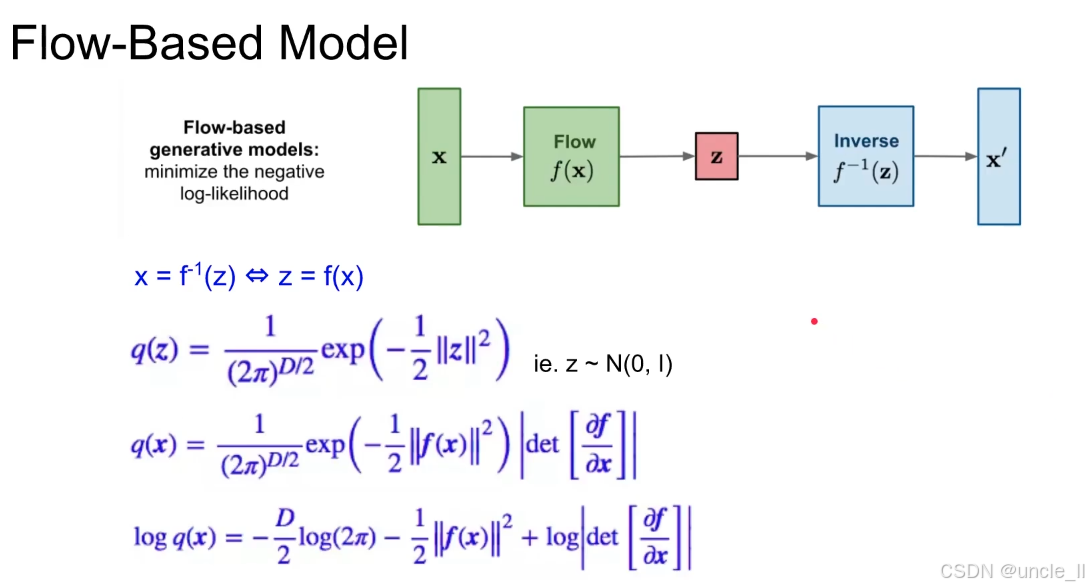
- 训练:通过优化算法最大化 logq(x)logq(x)logq(x),使模型学习到能将真实数据 x 映射到正态分布 z 的可逆流 fff;
- 生成:从标准正态分布采样 z,通过逆变换 f−1(z)f^{−1}(z)f−1(z) 生成逼真样本 x′。
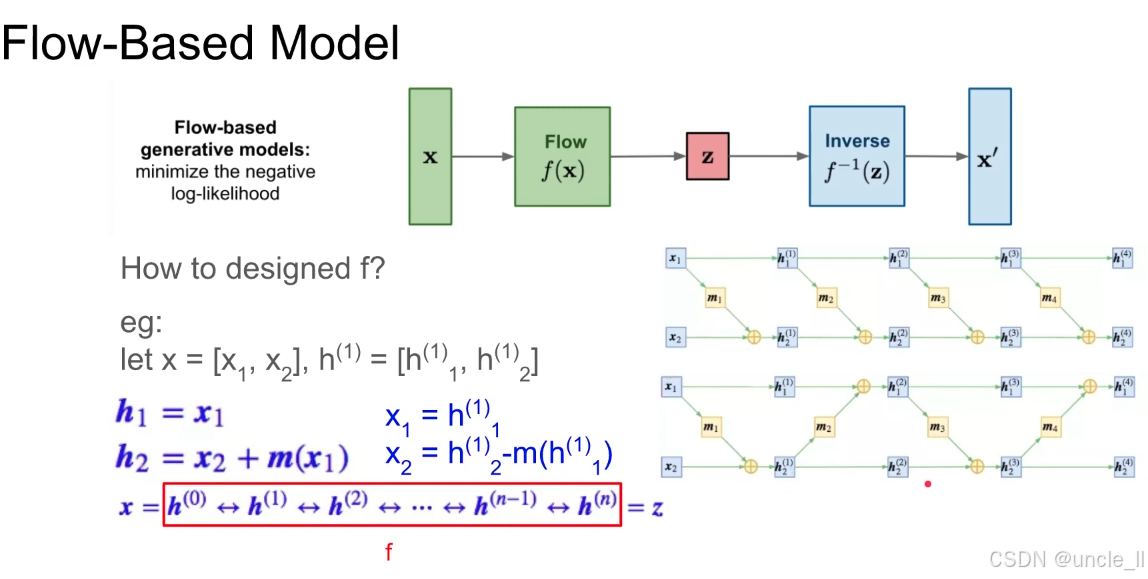
基于流的生成模型通过 “分而治之” 的策略设计 f:
- 将复杂的可逆变换拆解为多个简单可逆子变换的堆叠;
- 每个子变换(如耦合层)保证可逆性和低计算成本;
- 整体通过深度堆叠实现对高维复杂数据分布的建模。
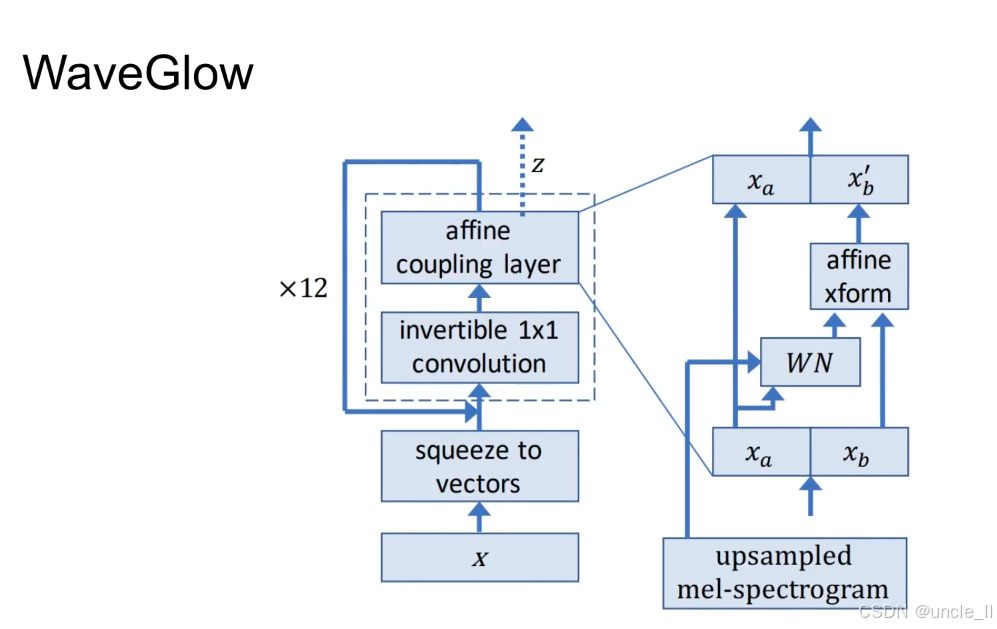
WaveGlow 模型的核心架构:
核心流程(左侧主模块,重复 12 次)
- 输入 xxx:原始语音波形(时域信号);
- squeeze to vectors:将波形数据 “压缩” 为向量形式,调整维度以适配后续流变换;
- invertible 1×1 convolution:可逆的 1×1 卷积,用于混合特征通道(类似 “洗牌” 操作,增强特征交互);
- affine coupling layer:仿射耦合层(流模型的核心模块),通过 “固定部分引导变换部分” 实现可逆的特征映射,最终将输入映射到隐空间噪声 zzz(服从标准正态分布)。
条件注入(右侧细节模块)
WaveGlow 是条件生成模型,需引入 “梅尔频谱(mel-spectrogram)” 作为条件控制生成的语音内容:
- upsampled mel-spectrogram:上采样后的梅尔频谱(与波形时序对齐);
- WN(WaveNet 模块):基于 WaveNet 的结构,处理梅尔频谱并生成 “条件特征”;
- affine xform:仿射变换,将 WN 的输出与流模块的特征融合,使生成的语音 “内容与梅尔频谱一致”;
- xax_axa,xbx_bxb:特征的两个分支,通过仿射耦合层实现 “条件引导的可逆变换”。

- WaveGlow 采用基于流(Flow-Based)的架构,使得音频合成速度超过实时(即生成一段音频的时间,比音频本身的时长更短)。
- WaveGlow 训练难度极高,原始论文中需要8 块 Nvidia GV100 高端 GPU 才能完成训练。
总结
一、音质(Quality)
- 结论:WaveNet>others
- 解释:WaveNet 生成的语音自然度最高(接近真人),其他模型(如 WaveRNN、FFTNet、WaveGlow)在音质上略逊于 WaveNet。
二、训练速度(Training Speed)
- 结论:WaveRNN>=WaveNet>=FFTNet>>WaveGlow
三、推理速度(Inference Speed)
(1)实时性标准:在16kHz 采样率(即音频每秒有 16000 个采样点)下,生成速度与播放速度同步。
(2)模型对比
- WaveGlow (520kHz)>>Real-time:WaveGlow 推理速度极快(生成速度达 520kHz),远超过实时;
- Real-time>WaveRNN>=FFTNet:WaveRNN、FFTNet 能满足实时,但速度慢于 WaveGlow;
- WaveNet (0.11kHz):WaveNet 推理极慢(仅 0.11kHz),远低于实时。
(3)传统算法对比:高度优化的 Griffin-Lim 算法推理速度达 507kHz,与 WaveGlow 相当。
四、领域挑战与未来方向
(1)当前困境:神经声码器存在 “两难”:要么推理慢(如 WaveNet),要么训练难(如 WaveGlow)。
(2)优化需求:现有模型需在 “架构、训练策略、硬件加速” 等方面深度优化,才能平衡性能与效率。
(3)未来工作:研究的重要方向是开发 “快、音质高、易训练” 三者兼备的声码器。