Machine Learning HW3 report:图像分类(Hongyi Lee)
任务:使用CNN把食物图片分为11类(不能使用预训练的模型)。此任务很耗时,一次训练至少1h,所以要利用好Kaggle notebook中Save Version功能,并行训练节省时间。
基准
- Simple : 0.50099
- Medium : 0.73207 Training Augmentation + Train Longer
- Strong : 0.81872 Training Augmentation + Model Design + Train Looonger (+ Cross Validation + Ensemble)
- Boss : 0.88446 Training Augmentation + Model Design +Test Time Augmentation + Train Looonger (+ Cross Validation + Ensemble)
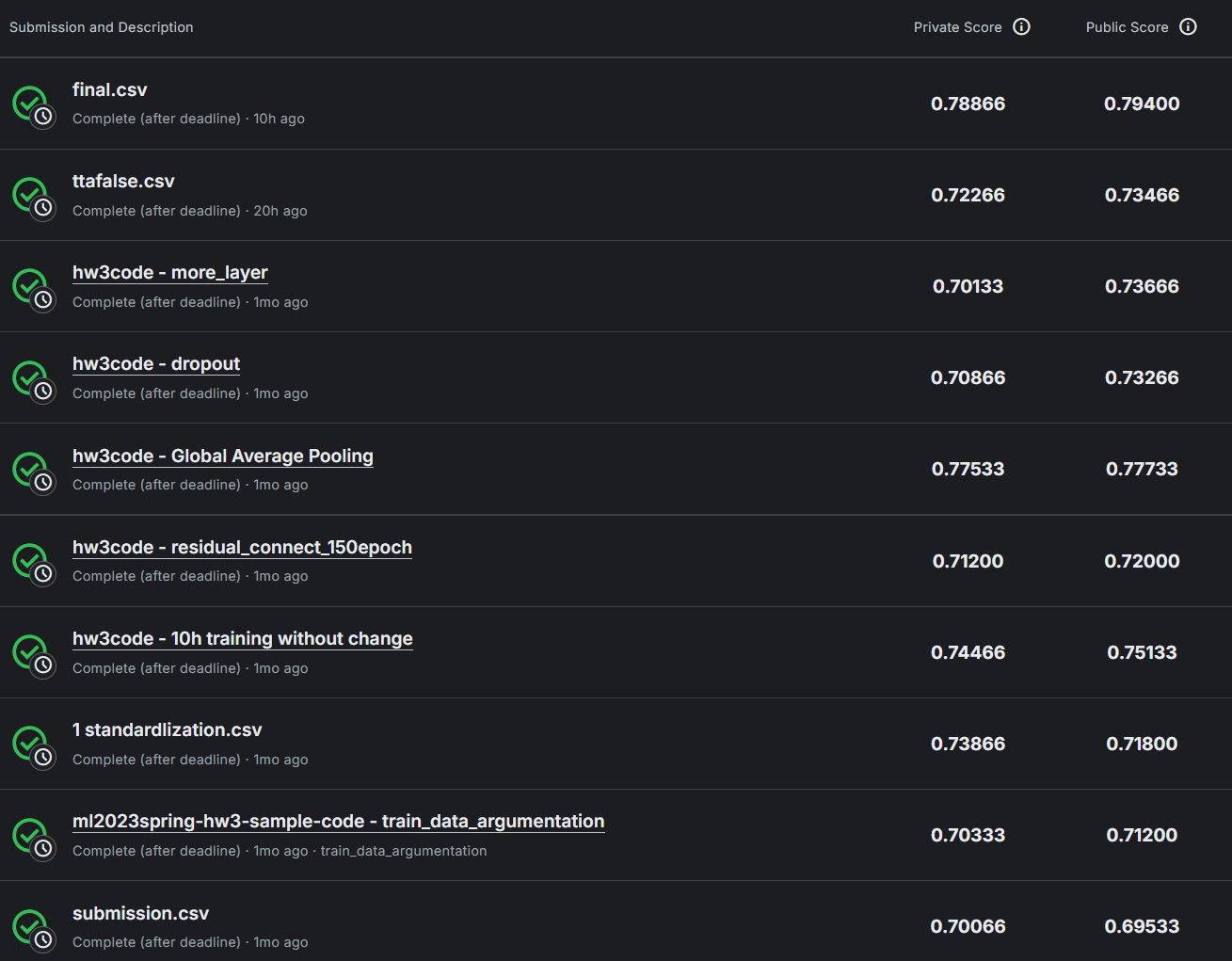
结果
优化思路
- Residual Connection(残差连接)
- 用checkpoint保存模型后继续训练
- 使用已存在的模型:Visit torchvision.models for a list of model structures, or go to timm for the latest model structures
- data augmentation (数据增强): Modify the image data so non-identical inputs are given to the model each epoch, to prevent overfitting of the model; Visit torchvision.transforms for a list of choices and their corresponding effect. Diversity is encouraged! Usually, stacking multiple transformations leads to better results.
- 使用mixup实现数据增强,不过需要改写torch.utils.Dataset, getitem(),写自己的CrossEntropyLoss支持多个标签
- Test Time Augmentation
- Cross Validation: uses different portions of the data to validate and train a model on different iterations
- 融合现有的训练和测试数据,增加训练数据比例(Currently, train : validation ~ 3 : 1)
- Ensemble:Average of logits or probability或Voting
- spatial transformer layer
- Image Normalization与batch Normalization
原代码中的错误及其他改进
- 如果直接运行sample code,不能正确显示训练进度条报错如下。这个错误是由于 Jupyter widgets 的版本不兼容导致的。查了多种解决方式都无效。最后将原代码中
from tqdm.auto import tqdm改为from tqdm import tqdm后解决了,tqdm.auto本来是用来自动识别当前运行环境,但在这里反而出错,只能说此功能还不够完善。
Failed to load model class ‘HBoxModel’ from module ‘@jupyter-widgets/controls’ Error: Module @jupyter-widgets/controls, version ^1.5.0 is not registered, however, 2.0.0 is at …
- 加入以下代码,显示训练时间、最佳准确率。
#在训练开始前加入
import time
total_start = time.time()#在训练完成后加入
total_time = time.time() - total_start
print(f'\nTotal time: {int(total_time // 60)} min {int(total_time % 60)} sec',end=', ')
print(f'best accuracy: {best_acc:.5f}')
实验过程
- 直接运行sample code,epoch = 24,耗时55min,效果不错,best acc = 0.69254,Kaggle private score = 0.70066,逼近了Medium水平。
- data augmentation,修改
test_tfm,增加中间三行代码,Total time: 53 min 51 sec, best accuracy: 0.47737
test_tfm = transforms.Compose([transforms.Resize((128, 128)),transforms.RandomResizedCrop(128), # 随机裁剪区域,缩放到128*128(增加位置鲁棒性)transforms.RandomHorizontalFlip(), # 水平翻转,默认50%概率transforms.ColorJitter(brightness=0.2, contrast=0.2), # 随机调整亮度和对比度transforms.ToTensor(),
])
- 在
test_tfm加入Image Standarlization,Total time: 54 min 58 sec, best accuracy: 0.44407
test_tfm = transforms.Compose([transforms.Resize((128, 128)),transforms.RandomResizedCrop(128), # 随机裁剪区域,缩放到128*128(增加位置鲁棒性)transforms.RandomHorizontalFlip(), # 水平翻转,默认50%概率transforms.ColorJitter(brightness=0.2, contrast=0.2), # 随机调整亮度和对比度transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 图像标准化
])
- 观察后发现了前两次实验效果变差的原因:应该调整
train_tfm而非test_tfm!重新进行上述实验。将test_tfm改为原样,Total time: 56 min 11 sec, best accuracy: 0.70634,private score:0.70333。奇怪的是比起改动前几乎没有提升效果,此外发现训练时accuracy达到0.81210,存在Overfitting。
# 原代码如下:
train_tfm = transforms.Compose([# Resize the image into a fixed shape (height = width = 128)transforms.Resize((128, 128)),# You may add some transforms here.# 增强数据transforms.RandomChoice(transforms=[ # 随机选择以下两种操作的一种# Apply TrivialAugmentWide data augmentation methodtransforms.TrivialAugmentWide(), # 在训练过程中自动为每张图像选择一种随机增强操作# Return original imagetransforms.Lambda(lambda x: x),],p=[0.95, 0.1]), # 每个转换操作被选择的概率分布# ToTensor() should be the last one of the transforms.transforms.ToTensor(),
])# 修改后:
train_tfm = transforms.Compose([# Resize the image into a fixed shape (height = width = 128)transforms.Resize((128, 128)),# You may add some transforms here.# 增强数据transforms.RandomResizedCrop(size=128, scale=(0.8, 1.0)), # 随机裁剪区域,缩放到128*128(增加位置鲁棒性)transforms.RandomRotation(degrees=30), # 随机旋转±30度transforms.RandomHorizontalFlip(), # 水平翻转,默认50%概率transforms.ColorJitter(brightness=0.2, contrast=0.2), # 随机调整亮度和对比度# ToTensor() should be the last one of the transforms.transforms.ToTensor(),
])
train_tfm最后一步加入Image Standarlization。Total time: 58 min 18 sec, best accuracy: 0.34147,准确率暴跌。发现训练时acc = 0.81429,非常高,说明测试时出了问题
train_tfm = transforms.Compose([# Resize the image into a fixed shape (height = width = 128)transforms.Resize((128, 128)),# You may add some transforms here.# 增强数据transforms.RandomResizedCrop(size=128, scale=(0.8, 1.0)), # 随机裁剪区域,缩放到128*128(增加位置鲁棒性)transforms.RandomRotation(degrees=30), # 随机旋转±30度transforms.RandomHorizontalFlip(), # 水平翻转,默认50%概率transforms.ColorJitter(brightness=0.2, contrast=0.2), # 随机调整亮度和对比度# ToTensor() should be the last one of the transforms.transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 图像标准化
])
- 找到了上次实验问题:测试时缺少与训练时一致的标准化操作,这种现象被称为 “预处理不一致偏差”,原因在于训练和测试数据分布不一致。修改
train_tfm,加上相同的标准化处理,重新训练。Total time: 57 min 52 sec, best accuracy: 0.72379,private:0.73866,达到了Medium。
test_tfm = transforms.Compose([transforms.Resize((128, 128)),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 测试时图像必须也标准化!
])
- 把epoch数量从24改为250,patience改为20(即连续20次无进步,退出训练)。训练34个epoch后,best acc已经达到0.72761,最终训练了102个epoch,Total time: 248 min 38 sec, best accuracy: 0.74015,private:0.74466。相比而言,多训练了5h,只提升了百分之一左右,效率很低。
- 残差连接。重构神经网络结构,换为残差连接(实现如代码所示),按照主流设计最后只用一层全连接神经网络(原代码用了三层),epoch设为150。24个epoch后acc = 0.66807。最终训练了63个epoch,Total time: 164 min 2 sec, best accuracy: 0.70428,private:0.71200
#残差链接:主流设计:两个卷积层 + 一次残差相加
class ResidualBlock(nn.Module):def __init__(self,in_channel,out_channel,stride=1):super().__init__()self.relu = nn.ReLU() # 定义实例。nn.ReLU(x)是错的!!nn.ReLU是类self.conv1 = nn.Conv2d(in_channel,out_channel,kernel_size=3,stride=stride,padding=1) #第一个卷积层,可能特征图长宽会改变self.bn1 = nn.BatchNorm2d(out_channel)self.conv2 = nn.Conv2d(out_channel,out_channel,kernel_size=3,stride=1,padding=1) #第二个卷积层self.bn2 = nn.BatchNorm2d(out_channel)self.shortcut = nn.Sequential() #residual connect, 维数相同则与输入相同if stride != 1 or in_channel != out_channel:self.shortcut = nn.Sequential(nn.Conv2d(in_channel,out_channel,kernel_size=1,stride=stride),nn.BatchNorm2d(out_channel))def forward(self, x):residual = self.shortcut(x)x = self.relu(self.bn1(self.conv1(x))) #F.rulu 和nn.ReLU不一样!!x = self.bn2(self.conv2(x))x += residualreturn self.relu(x)#新的神经网络架构# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)# torch.nn.MaxPool2d(kernel_size, stride, padding)# input 維度 [3, 128, 128]self.cnn = nn.Sequential(nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2, 2, 0), # [64, 64, 64]#第一层池化,减少参数量,后面的残差连接无需池化 ResidualBlock(64,128,2), #处理后: [128, 32, 32],分别表示channel, sizeResidualBlock(128,256,2), #[256, 16, 16]ResidualBlock(256,512,2), #[512, 8, 8]ResidualBlock(512,1024,2), #[1024, 4, 4])self.fc = nn.Linear(1024*4*4, 11) # 11个类别。后面不能加ReLu!# 原代码最后两层都是全连接网络
self.fc = nn.Sequential(nn.Linear(512*4*4, 1024),nn.ReLU(),nn.Linear(1024, 512),nn.ReLU(),nn.Linear(512, 11)
)
- 全局平均池化:在
self.cnn的最后加上两行代码,把4×4的特征图取平均压缩为1×1,再降维。24个epoch后acc 0.71644,最终训练了118个epoch,Total time: 286 min 29 sec, best accuracy: 0.76066,private:0.77533。有大幅度提升。
self.cnn = nn.Sequential(nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2, 2, 0), # [64, 64, 64]#第一层池化,减少参数量,后面的残差连接无需池化 ResidualBlock(64,128,2), #处理后: [128, 32, 32],分别表示channel, sizeResidualBlock(128,256,2), #[256, 16, 16]ResidualBlock(256,512,2), #[512, 8, 8]ResidualBlock(512,1024,2), #[1024, 4, 4]nn.AdaptiveAvgPool2d((1, 1)), # [1024, 1, 1] → 全局平均池化nn.Flatten() # [1024]
)
- 增加层数,epoch = 24,Total time: 64 min 55 sec, best accuracy: 0.71367,private:0.70133。相同epoch时,比起调整前反而有细微退步。
self.cnn = nn.Sequential(nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2, 2, 0), # [64, 64, 64]#第一层池化,减少参数量,后面的残差连接无需池化 ResidualBlock(64,128,2), #处理后: [128, 32, 32],分别表示channel, sizeResidualBlock(128,128,1), #[128, 32, 32]ResidualBlock(128,256,2), #[256, 16, 16]ResidualBlock(256,256,1), #[256, 16, 16]ResidualBlock(256,512,2), #[512, 8, 8]ResidualBlock(512,512,1), #[512, 8, 8]ResidualBlock(512,1024,2), #[1024, 4, 4]nn.AdaptiveAvgPool2d((1, 1)), # [1024, 1, 1] → 全局平均池化nn.Flatten() # [1024]
)
- 增加dropout:
self.cnn最后加入nn.Dropout(0.3)。Total time: 74 min 47 sec, best accuracy: 0.71584,private:0.70866提升不大 - 把训练文件和测试文件合并、打乱,重新划分,比例从3:1改为4:1。把神经网络结构改回第八次的结构,epoch = 24。Total time: 60 min 36 sec, best accuracy: 0.72798,进步明显
path = "/kaggle/input/ml2023spring-hw3/train"
all_files = ([os.path.join(path,x) for x in os.listdir(path) if x.endswith(".jpg")])
path = "/kaggle/input/ml2023spring-hw3/valid"
all_files += ([os.path.join(path,x) for x in os.listdir(path) if x.endswith(".jpg")])
# shuffle and re-divide
random.shuffle(all_files) #random seed已经固定,可以复现
split_idx = int(len(all_files) * 0.8)
train_files = all_files[:split_idx]
valid_files = all_files[split_idx:] # Construct train and valid datasets.
# The argument "loader" tells how torchvision reads the data.
train_set = FoodDataset("/kaggle/input/ml2023spring-hw3/train", tfm=train_tfm, files = train_files)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
valid_set = FoodDataset("/kaggle/input/ml2023spring-hw3/valid", tfm=test_tfm, files = valid_files)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=True)
- Test Time Augmentation。修改部分较多,具体见代码。从这个实验开始,改为colab平台上运行(因为恰好有colab pro+账号,GPU算力更高,选择L4 GPU),但在kaggle上运行也完全没问题。Total time: 51 min 7 sec, best accuracy: 0.73161,private:0.72266
#1.需要修改test_tfm
test_tfm = transforms.Lambda(lambda x: x) # Return original image#2. designed for test time augmentation
tta_tfm = transforms.Compose([ transforms.Resize((128, 128)), transforms.RandomHorizontalFlip(p=0.5), # 水平翻转 transforms.ColorJitter(brightness=0.2, contrast=0.2), # 随机调整亮度和对比度 transforms.RandomRotation(30), # 随机旋转 transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]), # 测试时图像必须也作相同标准化处理!
])#3. 利用继承的思想实现test time argumentation
class TTADataset(FoodDataset): def __init__(self, *args, TTA_tfm=tta_tfm, n_aug=5, **kwargs): """ n_aug 增强次数(不含原图),default = 5 """ super().__init__(*args, **kwargs) self.n_aug = n_aug self.tfm = TTA_tfm self.ori_tfm = transforms.Compose([ # 处理原图像 transforms.Resize((128, 128)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 测试时图像必须也标准化! ]) def __getitem__(self, index): # 获取原始图像(此时还不是tensor) image, label = super().__getitem__(index) # 调用父类方法 tta_images = [self.ori_tfm(image)] for _ in range(self.n_aug): tta_images.append(self.tfm(image)) # return tta_images, label # 返回list时,会出问题!!DataLoader 自动把每一位 TTA 样本合并成 batch 了! tta_images = torch.stack(tta_images) #转化为tensor [n_aug+1, 3, 128, 128] return tta_images, label#4. 重写valid_set
valid_set = TTADataset("/kaggle/input/ml2023spring-hw3/valid", TTA_tfm=tta_tfm, n_aug=5, tfm=test_tfm, files=valid_files)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)#5. 修改训练阶段validation逻辑
for batch in tqdm(valid_loader): # A batch consists of image data and corresponding labels. imgs, labels = batch with torch.no_grad(): if imgs.ndim == 5: # [B, N, C, H, W], 启用了TTAB, N, C, H, W = imgs.shape tta_images = imgs.view(B * N, C, H, W).to(device) # 首先改变形状,计算出全部结果 outputs = model(tta_images) # shape: [B * N, num_classes] outputs = outputs.view(B, N, -1) #恢复原来的形状 shape: [B, N, num_classes] # 加权平均预测 weights = torch.tensor([0.5] + [(0.5 / (N - 1))] * (N - 1), device=device) # [N],权重,原图0.5,其余被平分(默认是5张) weighted_preds = outputs * weights.view(1, -1, 1) #广播乘法[B, N, C] logits = weighted_preds.sum(dim=1) #加权融合 shape: [B, num_classes] else: logits = model(imgs.to(device))#6. 改写测试集
test_set = TTADataset("/kaggle/input/ml2023spring-hw3/test", TTA_tfm=tta_tfm, n_aug=5, tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)#7. 修改test逻辑
#改测试逻辑
with torch.no_grad(): for batch in tqdm(test_loader): imgs, _ = batch # imgs可能是普通tensor或TTA列表 if imgs.ndim == 5: # TTA模式 B, N, C, H, W = imgs.shape tta_images = imgs.view(B * N, C, H, W).to(device) # 首先改变形状,计算出全部结果 outputs = model(tta_images) # shape: [B * N, num_classes] outputs = outputs.view(B, N, -1) #恢复原来的形状 shape: [B, N, num_classes] # 加权平均预测 weights = torch.tensor([0.5] + [(0.5 / (N - 1))] * (N - 1), device=device) # [N],权重,原图0.5,其余被平分(默认是5张) weighted_preds = outputs * weights.view(1, -1, 1) #广播乘法 broadcasting: [B, N, C] test_pred = weighted_preds.sum(dim=1) #加权融合 shape: [B, num_classes] else: # 普通模式 test_pred = model_best(imgs.to(device)) # 获取预测标签 test_label = np.argmax(test_pred.cpu().numpy(), axis=1) prediction.extend(test_label.tolist())
- 查阅资料后,发现上次实验有问题:TTA一般只用于test阶段,而在validation阶段不应该使用,必须保证 validation 的结果能真实反映模型对“原始数据”的泛化能力,只有在完全相同的条件下(都不用TTA) 比较模型,才能公平地判断出哪个模型的本体更强。 把validation阶段重新修改回原来的逻辑,即不执行上次实验的第5、6,并如下修改了代码。把epoch数量从24改为500,patience改为49,继续使用colab上L4 GPU(A100 GPU、L4 GPU在此任务中表现相近,但A100计算单元消耗速度快得多)。
最终训练了412个epoch,Total time: 577 min 56 sec, best accuracy: 0.80946,0.78866。此次出现了Overfitting,train accuracy达到了99%;此外,patience设置过大,30要更为合理。
#TTADataset中初始化函数添加了mode = "no_tta",self.mode = mode
#修改__getitem__逻辑,使其能返回未经tta增强的image
class TTADataset(FoodDataset): def __init__(self, *args, TTA_tfm=tta_tfm, n_aug=5, mode = "no_tta", **kwargs): """ n_aug 增强次数(不含原图),default = 5 mode 模式,启用tta或者不启用 """ super().__init__(*args, **kwargs) self.n_aug = n_aug self.tfm = TTA_tfm self.mode = mode self.ori_tfm = transforms.Compose([ # 处理原图像 transforms.Resize((128, 128)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 测试时图像必须也标准化! ]) def __getitem__(self, index): image, label = super().__getitem__(index) # 调用父类方法 if self.mode != "no_tta": # 此时为原始图像 tta_images = [self.ori_tfm(image)] for _ in range(self.n_aug): tta_images.append(self.tfm(image)) # return tta_images, label # 返回list时,会出问题!!DataLoader 自动把每一位 TTA 样本合并成 batch 了! tta_images = torch.stack(tta_images) #转化为tensor [n_aug+1, 3, 128, 128] return tta_images, label image = self.ori_tfm(image) return image, label#改validation、test,如果在kaggle上运行,要改路径
valid_set = TTADataset("/content/valid", tfm=test_tfm, files = valid_files)
test_set = TTADataset("/content/test", TTA_tfm=tta_tfm, n_aug=5, tfm=test_tfm,mode = "tta")
易错
- nn.ReLu不能直接调用!PyTorch 中
nn.ReLU是一个类,不是函数,所以不能像普通函数那样直接nn.ReLU(x)使用。
#方法1 实例化
import torch
import torch.nn as nnx = torch.tensor([-1.0, 0.0, 2.0])
relu = nn.ReLU() # 实例化
y = relu(x) # 调用实例
print(y) # tensor([0., 0., 2.])#方法2 F.relu(函数,直接可用)
import torch
import torch.nn.functional as Fx = torch.tensor([-1.0, 0.0, 2.0])
y = F.relu(x) # 直接调用函数
print(y) # tensor([0., 0., 2.])
- 实现的Dataset继承类中__getitem__返回的image(或其他东西)类型要是tensor,绝对不能是list,否则训练时DataLoader合并batch时会出错
相关技术
图像归一化(Normalization)与标准化(Standardlization)
- 区别。归一化:将数据按比例缩放至特定范围(如[0,1]或[-1,1]);标准化:将数据转换为均值为0、标准差为1的分布
- Pytorch中实现。归一化:
transforms.ToTensor() # 将[0,255]线性映射到[0,1](Min-Max Normalization),标准化:transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])注意,PyTorch的Normalize()实际实现的是标准化 - 作用。归一化:统一特征尺度,加速梯度收敛等;标准化:提升模型泛化性,增强鲁棒性等。
- 易错。如果训练时数据进行了归一化与标准化,那么测试时数据也必须进行相同的归一化与标准化
残差连接
主流设计:两个卷积层 + 一次残差相加
核心思想:
不是直接让网络学习一个期望的映射 H(x),而是让网络学习残差映射 F(x)=H(x)−x
公式上,假设输入是 x,输出是 y:
y=F(x)+x
- F(x):经过卷积层、BN、激活函数后的输出(残差)
- x:直接加到输出上的原输入(shortcut/skip connection)
为什么有效?
- 减轻梯度消失:梯度可以直接沿着跳跃连接 x 反向传播,不经过很多非线性层。
- 学习残差更容易:通常残差 F(x) 比原映射 H(x)更接近零,网络只需学习微调,而不是整个复杂映射。
- 便于堆叠更多层:ResNet 可以轻松构建 50、101、甚至上百层的 CNN。
全局平均池化(Global Average Pooling, GAP)
这是一个非常简洁但极其强大的概念,在现代卷积神经网络(尤其是GoogLeNet、ResNet等)中扮演着关键角色。它将 每个通道的空间特征图 压缩成一个数值,即对每个通道做 空间维度的平均值。
- 输入:
H × W × C的特征图(高度 × 宽度 × 通道数) - 输出:
1 × 1 × C或直接C的向量 - 常用于 网络末端替代全连接层。
- 巨大优势:
- 极大减少参数量,防止过拟合:GAP本身零参数。它直接输出一个长度为
C(通道数)的向量,可以连接到最终的分类层(一个普通的全连接层,输入为C,输出为类别数)。参数量从亿级骤降到C * num_classes,例如512 * 1000 = 51.2万,减少了几个数量级。 - 增强模型鲁棒性:每个通道的特征图可以看作是对某个特定类别特征的“热度图”。GAP对空间信息进行整合,使得网络对输入物体的空间平移更加鲁棒。
- 原生支持任何输入尺寸:因为GAP不管输入特征图的高和宽是多少,它都直接取平均。这使得网络可以接受非固定尺寸的输入,而传统的FC层要求固定的输入维度。
- 极大减少参数量,防止过拟合:GAP本身零参数。它直接输出一个长度为
Test Time Augmentation
在模型 推理阶段(测试阶段),对输入数据做多种数据增强(augmentation),然后将模型的多次预测结果进行融合(如平均或投票),以提高模型的鲁棒性和准确率。
- 目的:缓解模型对输入分布的敏感性,让预测更稳健。
- 区别于训练阶段数据增强:
- 训练时增强是为了增加数据量、防止过拟合
- 测试时增强是为了提升预测稳定性和精度
总结
在hw3中,通过实现残差连接、TTA等技术,重新划分数据集并应用GAP,深化了对CNN的代码理解与实践能力,收获良多。不足之处在于没有尝试足够多网络架构,此外data argumentation做的也不够(做好了应该能较大幅度的提升准确率);如果使用ensemble技术,应该能较大地提高准确率。