【MYSQL】从混乱到清晰:联合查询帮你打通数据孤岛



目录
- 一:前言
- 二:联合查询简介
- 三:那么为什么要使用联合查询
- 四:建立数据进行练习
- 4.1创建相关的表并加入数据
- 4.2进行案例的分享
- 4.3内连接
- 4.4外连接
- 4.5自连接
- 4.6⼦查询
- 五:合并查询
- 5.1Union
- 5.2Union al
- 六:插⼊查询结果
- 七:总结
一:前言
在数字化浪潮席卷全球的当下,数据已成为企业发展的核心驱动力。无论是大型企业还是中小型组织,每天都在产生、收集着海量的业务数据,这些数据涵盖了用户信息、交易记录、产品详情等方方面面。然而,一个普遍存在的现象却让这些宝贵的数据难以充分发挥价值 —— 数据孤岛。
不同的业务模块、不同的系统往往将数据存储在各自独立的数据库表中,这些表就像一个个孤立的岛屿,彼此之间缺乏有效的连接。当企业需要进行数据分析、业务决策或者生成综合报表时,不得不耗费大量的时间和精力在这些数据孤岛之间穿梭,手动整合信息。这种低效的工作方式不仅容易出错,还会让企业错失市场机遇,在激烈的竞争中处于不利地位。
而 MySQL 联合查询,正是解决数据孤岛问题的一把利器。它能够打破表与表之间的壁垒,建立起有效的数据连接,让分散的数据得以整合、关联,从而为企业提供清晰、全面的数据视角。本文将深入探讨数据孤岛带来的困境,详细解析MySQL 联合查询的技术核心,并提供从应用到优化的实战指南,帮助你真正掌握这一技术,让数据从混乱走向清晰,为企业的发展注入强大动力。
二:联合查询简介
1. 数据困境:孤岛带来的效率瓶颈
在数据驱动的商业环境中,企业数据往往分散在多张表中,形成难以互通的 “数据孤岛”。以电商场景为例,订单信息、商品详情、用户数据分别存储在独立表中,若要分析 “新客户偏好商品”,需手动跨表筛选、匹配、整合,不仅耗时且易出错。
这种分散状态会引发三重问题:
处理低效:跨表分析需重复操作,错过决策窗口期 数据矛盾:不同表中重复记录的字段值可能冲突,难以校验真实性
资源浪费:各部门重复存储同类数据,增加存储成本与管理复杂度
2. 联合查询:打破壁垒的技术核心
MySQL 联合查询通过建立表间关联,实现数据高效流通,其技术框架包含基础语法与连接类型两部分。
三:那么为什么要使用联合查询
在数据设计时由于范式的要求,数据被拆分到多个表中,那么要查询⼀个条数据的完整信息,就要从多个表中获取数据,如下图所⽰:要获取学⽣的基本信息和班级信息就要从学⽣表和班级表中获取,这时就需要使⽤联合查询,这⾥的联合指的是多个表的组合。
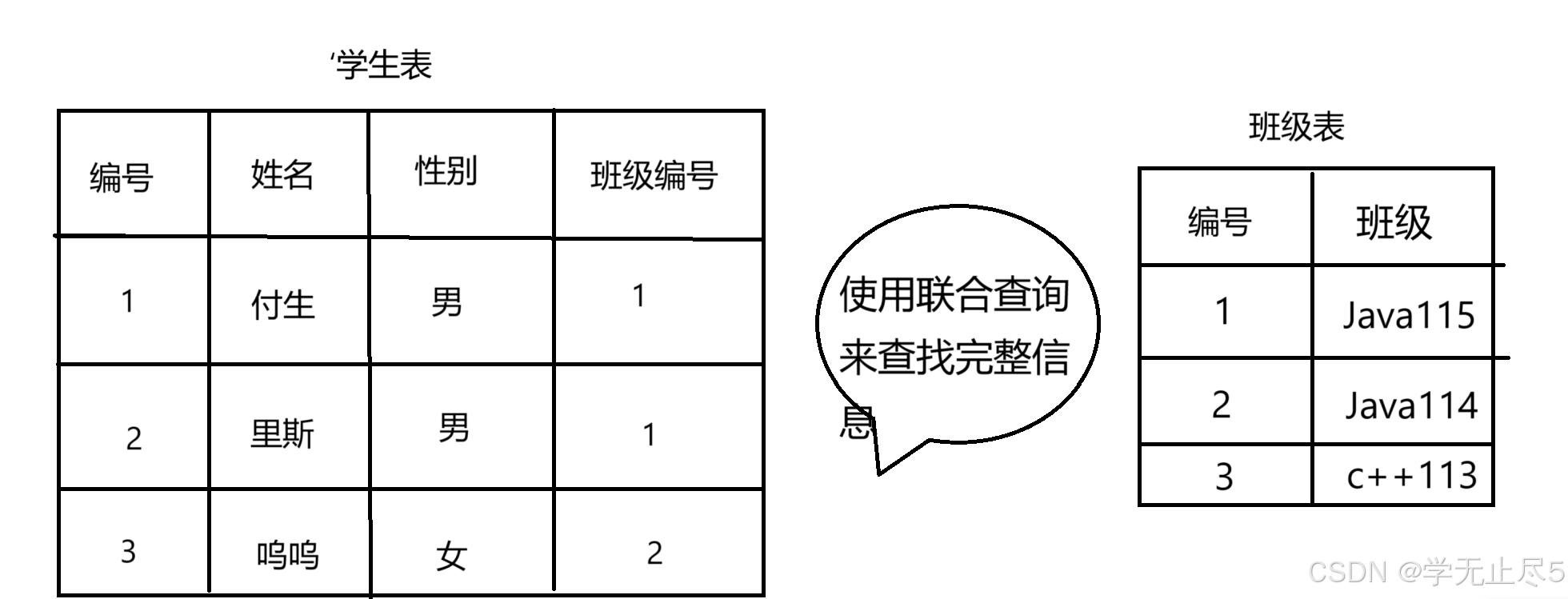
注意:如果联合查询表的个数越多,表中的数据量越大,临时表就会越大,所以根据实际情况确定联合查询表的个数
四:建立数据进行练习
4.1创建相关的表并加入数据
1.创建课程表(course)
CREATE TABLE course (id INT PRIMARY KEY AUTO_INCREMENT COMMENT '课程ID,自增主键',name VARCHAR(50) NOT NULL COMMENT '课程名称'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '课程表';
2.创建班级表(class)
CREATE TABLE class (id INT PRIMARY KEY AUTO_INCREMENT COMMENT '班级ID,自增主键',name VARCHAR(50) NOT NULL COMMENT '班级名称'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '班级表';
- 接着创建学生表(student)
CREATE TABLE student (id INT PRIMARY KEY AUTO_INCREMENT COMMENT '学生ID,自增主键',name VARCHAR(50) NOT NULL COMMENT '学生姓名',sno VARCHAR(20) UNIQUE NOT NULL COMMENT '学号,唯一',age INT NOT NULL COMMENT '年龄',gender TINYINT NOT NULL COMMENT '性别(1:男,2:女)',enroll_date DATE NOT NULL COMMENT '入学日期',class_id INT NOT NULL COMMENT '关联班级表的班级ID',-- 添加外键关联班级表CONSTRAINT fk_student_class FOREIGN KEY (class_id) REFERENCES class(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '学生表';
- 最后创建成绩表(score)
CREATE TABLE score (id INT PRIMARY KEY AUTO_INCREMENT COMMENT '成绩记录ID,自增主键',score DECIMAL(5, 2) NOT NULL COMMENT '成绩,保留两位小数',student_id INT NOT NULL COMMENT '关联学生表的学生ID',course_id INT NOT NULL COMMENT '关联课程表的课程ID',-- 添加外键约束,关联学生表的主键CONSTRAINT fk_score_student FOREIGN KEY (student_id) REFERENCES student(id),-- 添加外键约束,关联课程表的主键CONSTRAINT fk_score_course FOREIGN KEY (course_id) REFERENCES course(id),-- 确保同一学生同一课程只有一条成绩记录UNIQUE KEY uk_student_course (student_id, course_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '学生成绩表';
四个表就成功创建完成了
mysql> insert into course (name) values
('Java'), ('C++'), ('MySQL'), ('操作系统'), ('计'> 算机⽹络'), ('数据结构');
insert into class(name) values ('Java001班'), ('C++001班'), ('前端001班');
insert into student (name, sno, age, gender,enroll_date, class_id) values-> ('唐三藏', '100001', 18, 1, '1986-09-01', 1),-> ('孙悟空', '100002', 18, 1, '1986-09-01', 1),-> ('猪悟能', '100003', 18, 1, '1986-09-01', 1),-> ('沙悟净', '100004', 18, 1, '1986-09-01', 1),-> ('宋江', '200001', 18, 1, '2000-09-01', 2),-> ('武松', '200002', 18, 1, '2000-09-01', 2),-> ('李逹', '200003', 18, 1, '2000-09-01', 2),-> ('不想毕业', '200004', 18, 1, '2000-09-01', 2);
insert into score (score, student_id, course_id) values-> (70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),-> (60, 2, 1),(59.5, 2, 5),-> (33, 3, 1),(68, 3, 3),(99, 3, 5),-> (67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),-> (81, 5, 1),(37, 5, 5),-> (56, 6, 2),(43, 6, 4),(79, 6, 6),-> (80, 7, 2),(92, 7, 6);
4.2进行案例的分享
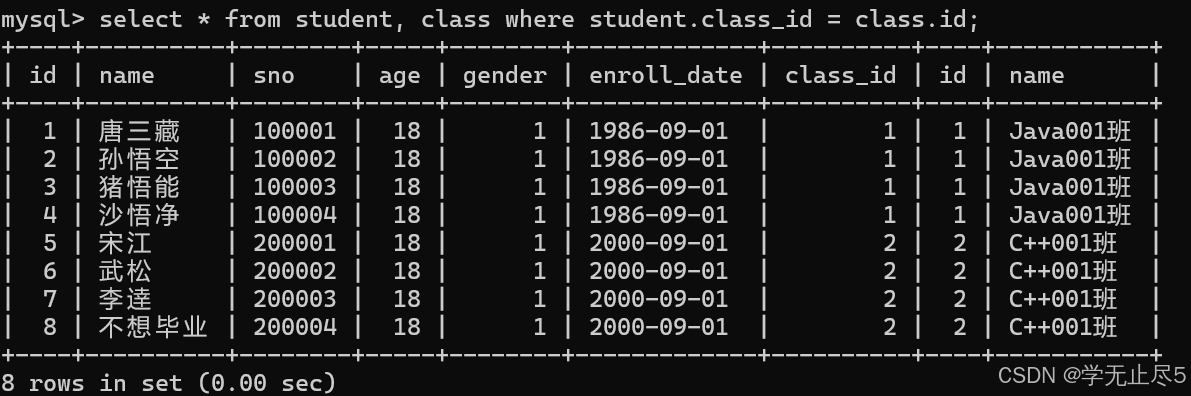
查询学⽣姓名为孙悟空的详细信息,包括学⽣个⼈信息和班级信息
先确定连接条件,student表中的class_id与class表中id列的值相等
执行sql语句:
select * from student, class where student.class_id = class.id;
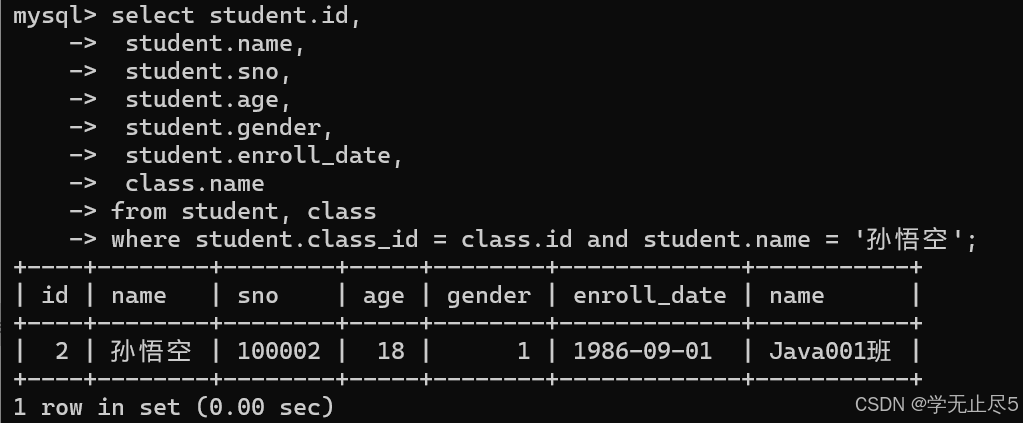
精减查询结果字段
select student.id, student.name, student.sno, student.age, student.gender, student.enroll_date, class.name
from student, class
where student.class_id = class.id and student.name = '孙悟空';
我们也可以为表名指定别名
select-> s.id,-> s.name,-> s.sno,-> s.age,-> s.gender,-> s.enroll_date,-> c.name-> from-> student s , class c-> where-> s.class_id = c.id-> and-> s.name = '孙悟空';

4.3内连接
语法:
1 select 字段 from 表1 别名1, 表2 别名2 where 连接条件 and 其他条件
2 select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 where 其他条件;
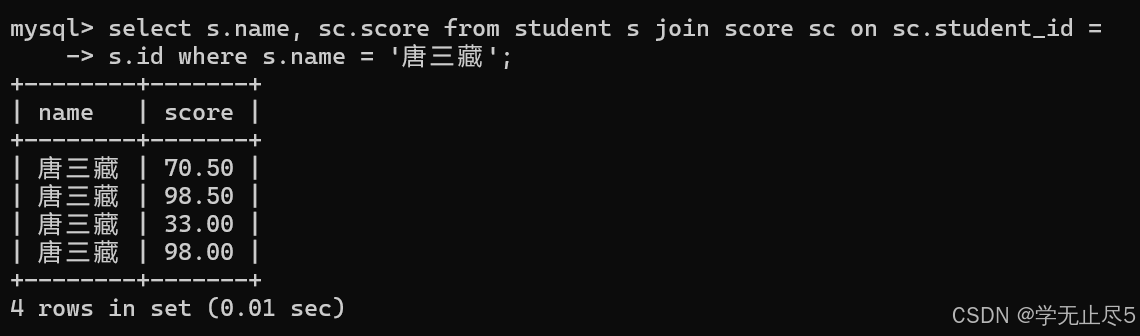
详细分析:例如查询"唐三藏"同学的成绩
select s.name, sc.score from student s join score sc on sc.student_id =
s.id where s.name = '唐三藏';
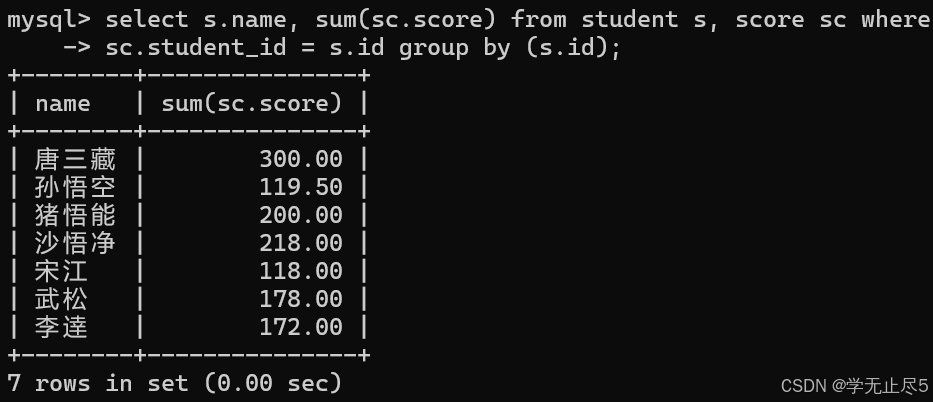
查询所有同学的总成绩,及同学的个⼈信息
select s.name, sum(sc.score) from student s, score sc where
sc.student_id = s.id group by (s.id);
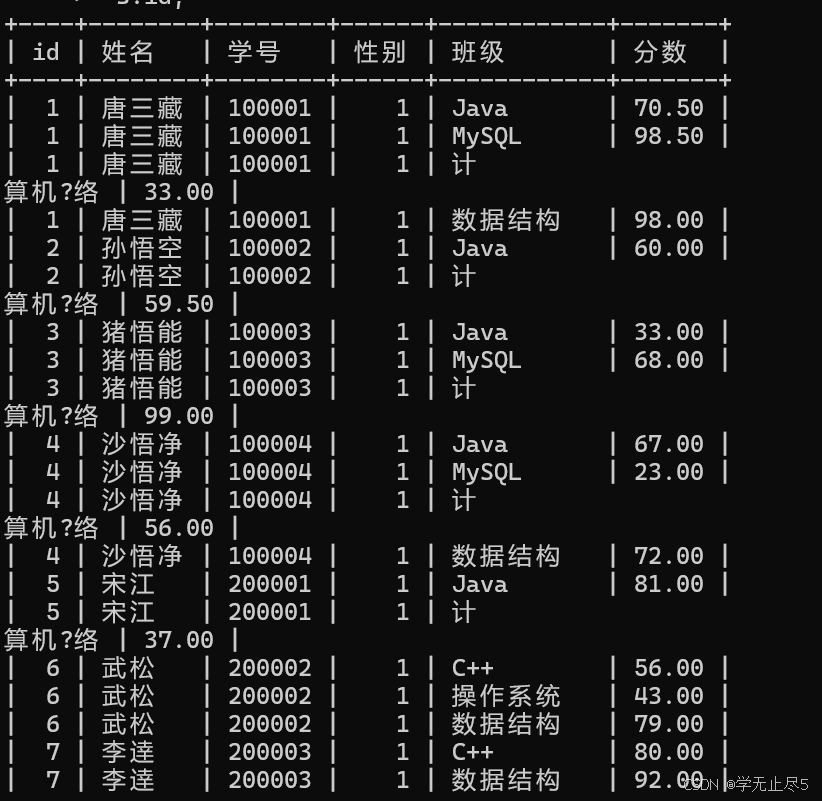
查询所有同学每⻔课的成绩,及同学的个⼈信息
selects.id as id,s.name as 姓名,s.sno as 学号,s.gender as 性别,c.name as 班级,sc.score as 分数
from student s, course c, score sc
where s.id = sc.student_id
and c.id = sc.course_id
order by s.id;
4.4外连接
外连接分为左外连接、右外连接和全外连接三种类型,MySQL不⽀持全外连接。
左外连接:返回左表的所有记录和右表中匹配的记录。如果右表中没有匹配的记录,则结果集中对 应字段会显⽰为NULL。
右外连接:与左外连接相反,返回右表的所有记录和左表中匹配的记录。如果左表中没有匹配的记 录,则结果集中对应字段会显⽰为NULL。
全外连接:结合了左外连接和右外连接的特点,返回左右表中的所有记录。如果某⼀边表中没有匹 配的记录,则结果集中对应字段会显⽰为NULL。
语法:
-- 左外连接,表1完全显⽰
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显⽰
select 字段 from 表名1 right join 表名2 on 连接条件;
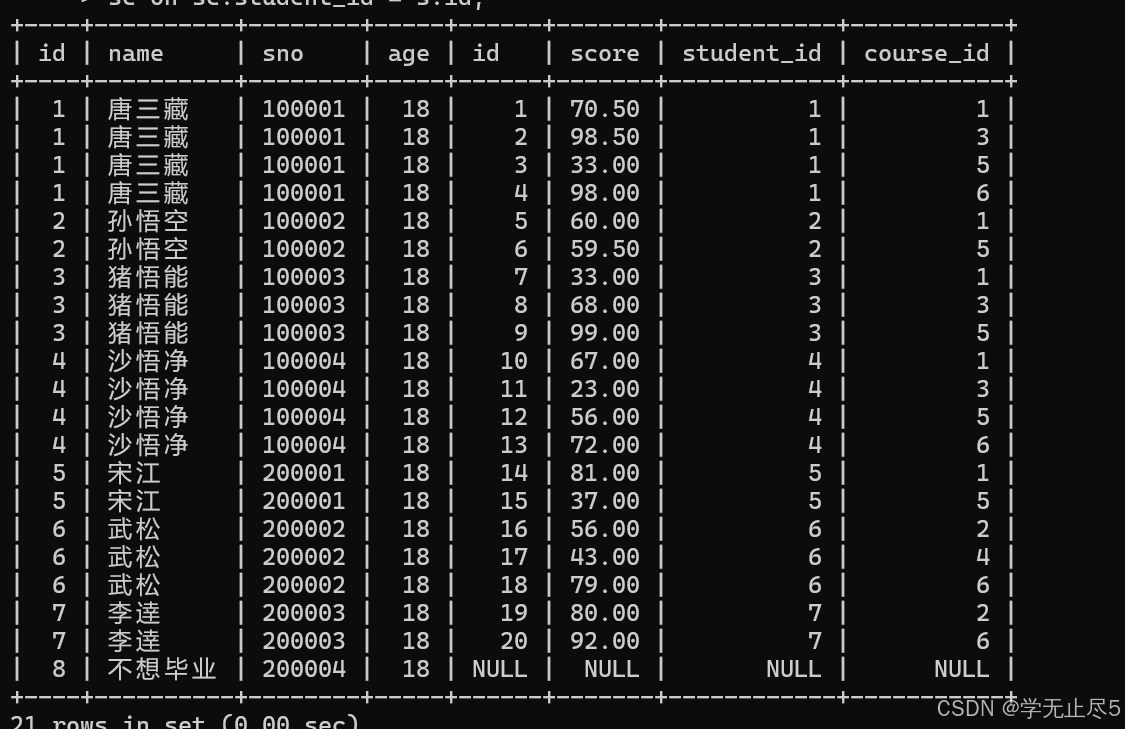
例子:查询没有参加考试的同学信息
# 左连接以JOIN左边的表为基准,左表显⽰全部记录,右表中没有匹配的记录⽤NULL填充
mysql> select s.id, s.name, s.sno, s.age, sc.* from student s LEFT JOIN score
sc on sc.student_id = s.id;
select s.* from student s LEFT JOIN score sc on sc.student_id = s.id
where sc.score is null;
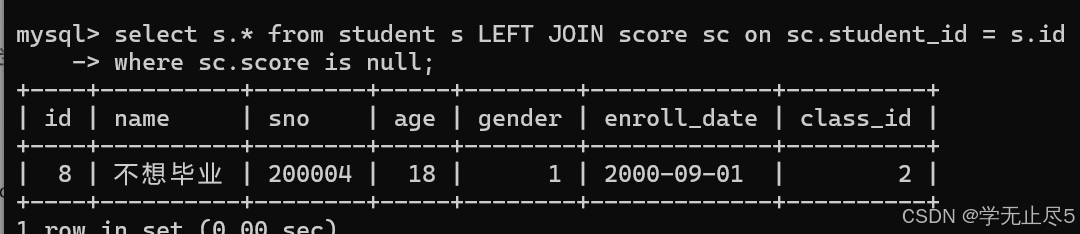
查询没有学⽣的班级
# 右连接以JOIN右边的表为基准,右表显⽰全部记录,左表中没有匹配的记录⽤NULL填充
mysql> select * from student s RIGHT JOIN class c on c.id = s.class_id;
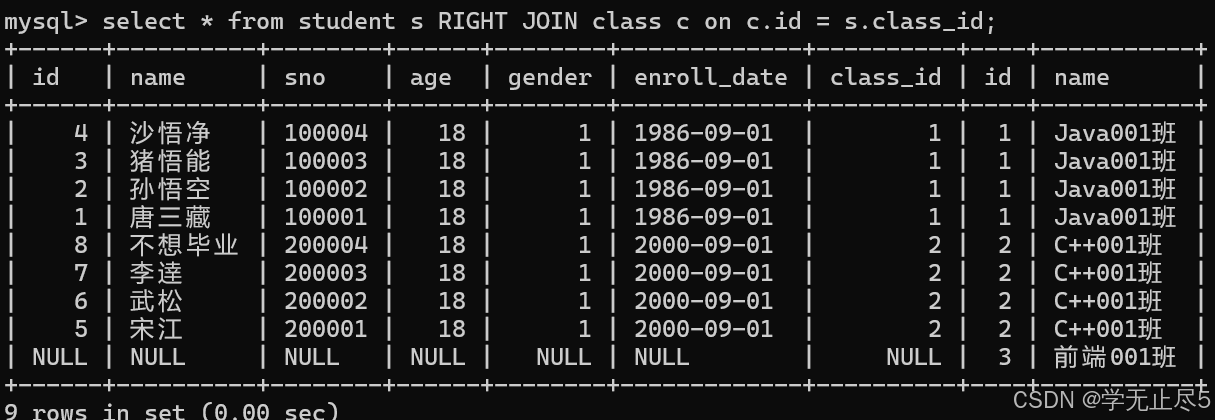
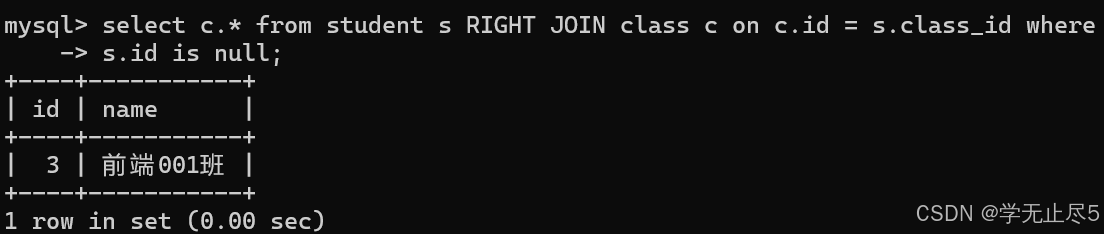
在# 过滤有学⽣的班级
select c.* from student s RIGHT JOIN class c on c.id = s.class_id where
s.id is null;
4.5自连接
⾃连接是⾃⼰与⾃⼰取笛卡尔积,可以把⾏转化成列,在查询的时候可以使⽤where条件对结果进⾏过滤,或者说实现⾏与⾏之间的⽐较。在做表连接时为表起不同的别名
.
# 不为表指定别名
mysql> select * from score, score;
ERROR 1066 (42000): Not unique table/alias: 'score'
# 指定别名
mysql> select * from score s1, score s2;
例子:
显⽰所有"MySQL"成绩⽐"JAVA"成绩⾼的成绩信息
⾸先分两步进⾏,先查出JAVA和MySQL的课程Id,分别为1和3
select * from course where name = 'Java' or name = 'MySQL';

select s1.* from score s1, score s2 where s1.student_id = s2.student_id
and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;

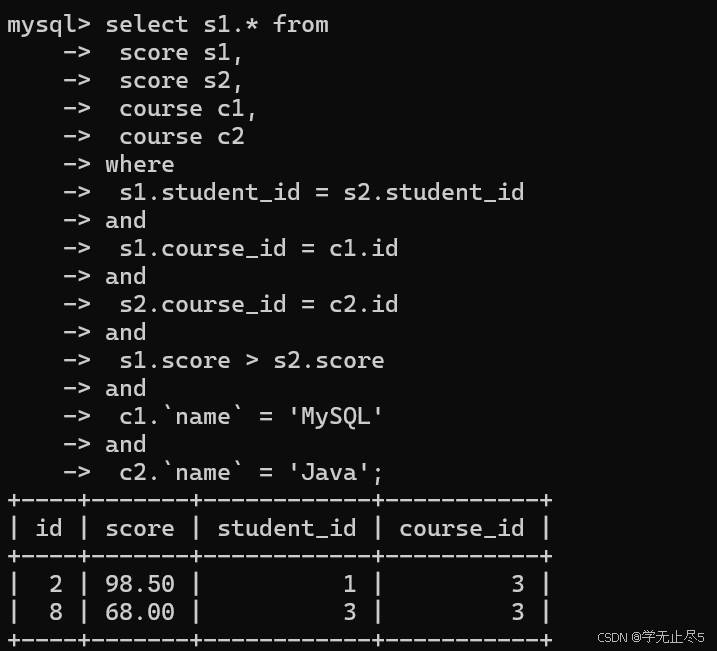
select s1.* fromscore s1, score s2, course c1,course c2
wheres1.student_id = s2.student_id
ands1.course_id = c1.id
ands2.course_id = c2.id
ands1.score > s2.score
andc1.`name` = 'MySQL'
andc2.`name` = 'Java';
4.6⼦查询
⼦查询是把⼀个SELECT语句的结果当做别⼀个SELECT语句的条件,也叫嵌套查询
语法:
select * from table1 where col_name1 {= | IN} (select col_name1 from table2 where col_name2 {= | IN} [(select ...)] ...
)
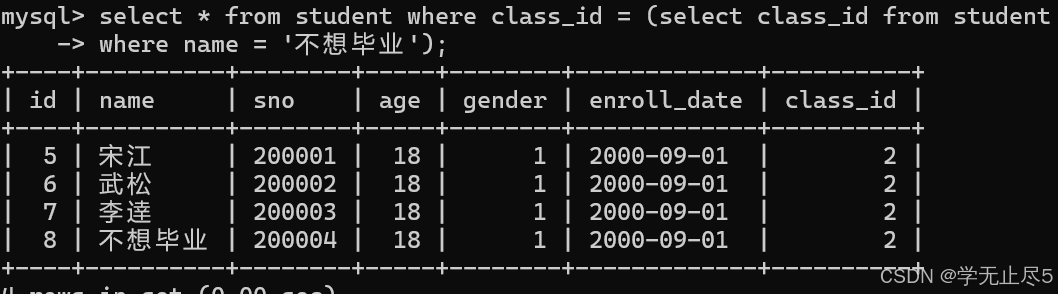
select * from student where class_id = (select class_id from student
where name = '不想毕业');
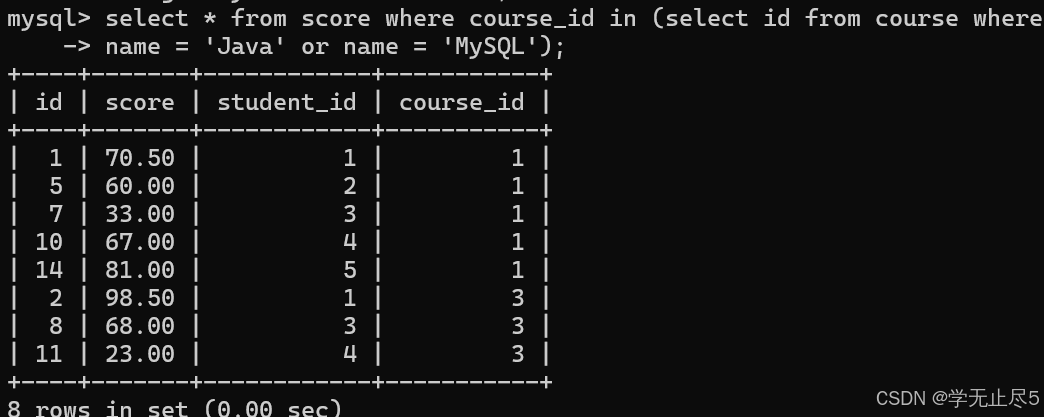
select * from score where course_id in (select id from course where
name = 'Java' or name = 'MySQL');
五:合并查询
在实际应⽤中,为了合并多个select操作返回的结果,可以使⽤集合操作符 union,union all
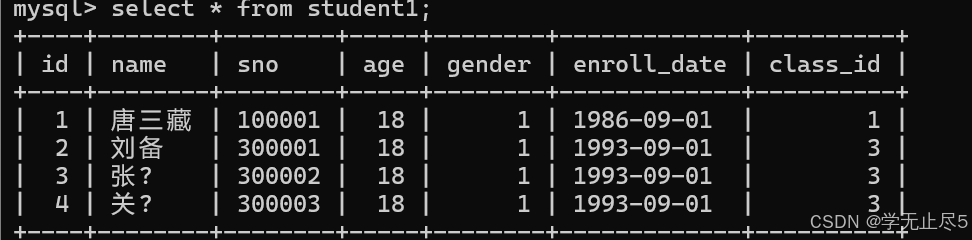
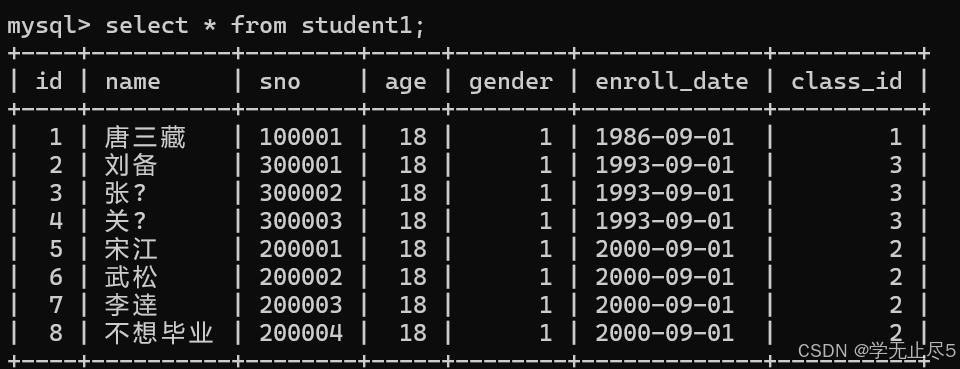
先创建⼀个新表并初始化数据
create table student1 like student;
insert into student1 (name, sno, age, gender, enroll_date, class_id) values
('唐三藏', '100001', 18, 1, '1986-09-01', 1),
('刘备', '300001', 18, 1, '1993-09-01', 3),
('张⻜', '300002', 18, 1, '1993-09-01', 3),
('关⽻', '300003', 18, 1, '1993-09-01', 3)
5.1Union
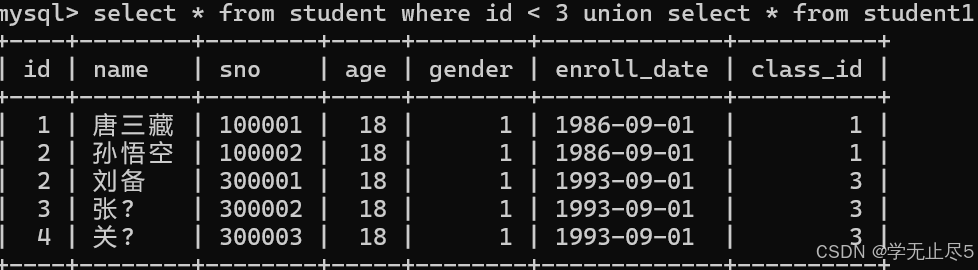
该操作符⽤于取得两个结果集的并集。当使⽤该操作符时,会⾃动去掉结果集中的重复⾏。
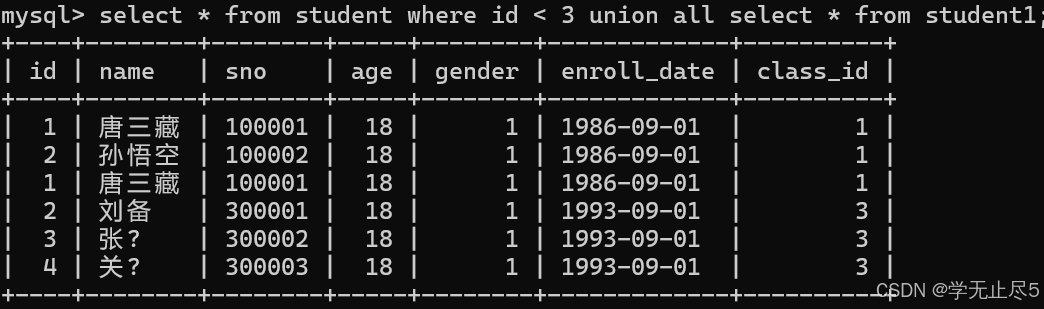
例子:查询student表中 id < 3 的同学和student1表中的所有同学
select * from student where id < 3 union select * from student1;
5.2Union al
该操作符⽤于取得两个结果集的并集。当使⽤该操作符时,不会去掉结果集中的重复⾏
示例:
select * from student where id < 3 union all select * from student1;
六:插⼊查询结果
语法:INSERT INTO table_name [(column [, column ...])] SELECT ...
例子:将student表中C++001班的学⽣复制到student1表中
insert into student1 (name, sno, age, gender, enroll_date, class_id)select s.name, s.sno, s.age, s.gender, s.enroll_date, s.class_idfrom student s, class c where s.class_id = c.id and c.name = 'C++001班';
七:总结
MySQL联合查询是打破数据孤岛、实现多表数据整合的核心技术,主要通过JOIN系列语法(INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN)及UNION/UNION ALL实现,适用于需跨表关联分析的场景。
其核心价值在于基于指定关联字段(如主键与外键),建立表间逻辑连接,避免手动拼接数据的低效与误差,快速获取完整数据视图。例如通过INNER JOIN匹配订单表与用户表的共同数据,可直接查询“用户-订单”关联信息;LEFT JOIN则能保留主表(如用户表)全部数据,同时关联从表(如订单表)匹配项,适配“需展示主表全量信息”的需求。
使用时需注意:关联字段需确保数据类型一致,避免隐式转换影响性能;优先通过WHERE过滤无效数据,减少关联计算量;复杂多表查询建议结合索引优化(如给关联字段建索引),避免全表扫描。合理运用联合查询,可显著提升数据处理效率,为企业数据分析、报表生成与业务决策提供高效支持。