BEV-VAE
paper来源
BEV-VAE: Multi-view Image Generation with Spatial Consistency for Autonomous Driving
论文提出目标
为训练端到端驾驶模型特别是NVS提供数据增强手段。
现有方法特点
- 主流的都是基于微调的Stable Diffusion模型
- 多视角图像生成视为带有相邻视角一致性约束的二维合成任务
- 只能一定程度的保证空间一致性
- 依赖于图像空间中视角相关的交叉注意力机制来隐式建模3D结构,缺乏统一的结构化表征
- 难以支持任意相机位姿的新视角合成,也无法直接基于3D布局进行可控生成
- 3D bbox的二维投影导致深度丢失,不同物体的投影在图像空间中overlap,引入遮挡歧义
- 生成模型必须同时学习生成跨视角空间一致的图像
- 夸视角具有歧义的二维条件对齐很难,训练过程复杂且几何基础薄弱
BEV-VAE的特点
- 统一3D场景表征的多视角图像生成
- 编码阶段显式构建空间对齐的BEV潜在空间
- BEV空间中直接实现基于扩散模型的生成方案
- 跨视角对齐实现高保真重建
- BEV潜在空间支持通过操控相机位姿实现新视角合成,支持任意相机位姿进行NVS
- 允许基于3D物体布局(如改变物体数量、位置或类别)的可控生成
- 生成全部7V 环视图像的方法,证明了鲁棒性和实用性
实现思路与框架

图1:多视角图像生成两种范式的对比。(a) 图像潜在空间生成依赖3D物体的2D投影指导图像合成,通过跨视角注意力机制强制实现空间一致性;(b) BEV潜在空间生成以3D OCC为条件产生统一表征,从中解码出所有视角,天然保持空间一致性,并可通过调整相机位姿实现新视角合成。
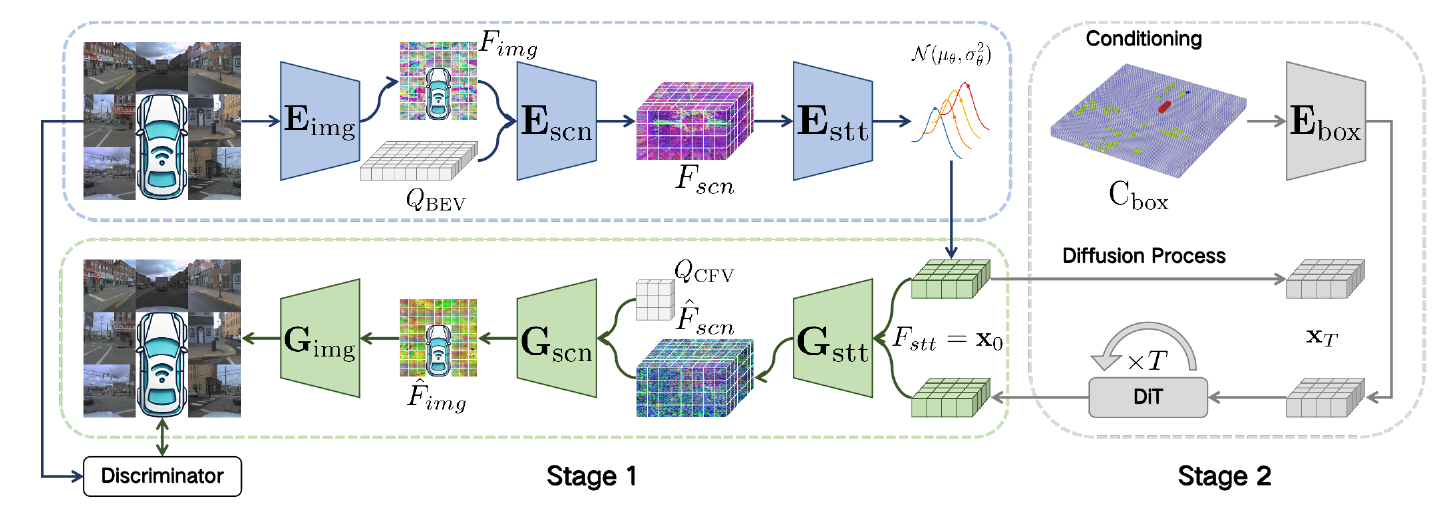
Pipeline与方法论
BEV-VAE 的工作流程分为两个阶段:
- 第一阶段:训练一个多视图图像变分自编码器(VAE),将多视图图像编码到紧凑的 BEV 潜在空间中,再将其解码回具有一致性的多视图图像。
- 第二阶段:在已学习的 BEV 潜在空间中训练一个去噪扩散 Transformer(DiT),该 Transformer 能从噪声中生成 BEV 潜在表示,随后由预训练的 VAE 解码器将这些表示解码为多视图图像。
具体实现
BEV-VAE 的核心方法围绕基于 Transformer 的编码器和解码器展开,二者分别用于处理多视图图像和 BEV 表示。
(一)编码器:输入多视图图像
编码器负责将多视图图像转换为 BEV 潜在空间中的表示,具体分为图像编码器、场景编码器和状态编码器三个部分。
1. 图像编码器
图像编码器采用视觉 Transformer(ViT),其后连接一个仅用于上采样的特征金字塔网络(FPN),以提取多尺度图像特征。对于输入尺寸为 [H, W, 3] 的图像,ViT 会将其编码为一系列标记(tokens);FPN 则提取不同尺度的特征并将它们拼接,拼接后的特征可表示为:
其中,是来自视角 v 的扁平化多尺度特征。
2. 场景编码器
场景编码器利用可变形注意力(Deformable Attention),将多视图图像特征聚合为 BEV 中的三维场景特征。它会在自动驾驶主车(ego vehicle)周围的预定义三维参考点 处定义一个 BEV 网格查询(BEV grid queries),并通过相机参数将这些 BEV 参考点投影到每个相机的图像平面上。随后,通过可变形注意力从图像特征中的投影点聚合特征,最终得到三维 BEV 场景特征,过程可表示为:
3. 状态编码器
状态编码器对三维 BEV 场景特征进行进一步处理:首先重塑特征以拼接高度维度,然后在水平面上将其划分为二维补丁(2D patches),并应用自注意力(self-attention)学习压缩后的二维空间状态特征 。此外,该编码器还会预测高斯分布
的均值
和方差
,并利用重参数化技巧对状态特征进行采样:
,其中
。
(二)解码器:输入状态特征,重建多视图图像
解码器负责将 BEV 潜在空间中的状态特征重建为多视图图像,具体分为状态解码器、场景解码器和图像解码器三个部分。
1. 状态解码器
状态解码器从压缩的二维状态特征 中重建详细的三维 BEV 场景特征
。它通过自注意力、反卷积(deconvolution)扩展水平维度、维度划分恢复高度结构,以及一个仅用于下采样的 FPN,最终重建出多尺度三维 BEV 场景特征。
2. 场景解码器
场景解码器通过沿相机视锥体视图(CFV,Camera's Frustum View)中的光线聚合特征,将三维 BEV 场景特征 F^bev 转换为相机视角特征 Fcfvv。对于每个相机视角 v,它会沿预定义的光线和深度级别定义 CFV 查询 {Qcfvv} 和参考点 {Pcfvv},并将这些 CFV 参考点投影到 BEV 空间;随后,通过可变形注意力从重建的 BEV 场景特征中聚合特征,再为光线沿线上的每个深度位置 d 估计深度权重 wd,最后通过加权求和得到投影的图像特征:
Fprojv=∑dwd⋅DeformAttn(F^bev;Pcfv,dv)
3. 图像解码器
图像解码器接收每个视角的投影图像特征 Fprojv:首先通过线性层将特征映射到更高维度,然后应用自注意力建模图像平面上的空间关系,最后通过反卷积逐步将分辨率上采样回原始尺寸 [H, W, 3],得到重建图像 I^v。
(三)第一阶段:VAE 的训练损失函数
第一阶段训练 VAE 时,采用的联合损失函数 LVAE 如下:
各损失项的含义如下:
:KL 散度,用于衡量学习到的潜在分布与标准高斯先验分布 N(0,1) 之间的差异;
是权重(例如
),用于正则化潜在空间。
:生成器 G 的对抗损失,目的是最大化判别器 D 对伪造图像
的输出(即让判别器难以区分伪造图像与真实图像)。
:判别器 D 的损失,用于训练判别器区分真实图像
与伪造图像
是自适应权重,用于平衡
(四)第二阶段:DiT 的训练与可控生成
第二阶段训练一个去噪扩散 Transformer(DiT),用于建模从 VAE 编码器得到的 BEV 潜在状态 S 的分布。该 DiT 学习将带噪声的潜在状态去噪,恢复为原始潜在状态 S。
为实现可控生成,本文采用无分类器引导(CFG,Classifier-Free Guidance),并以三维目标布局作为条件:
- 将三维边界框 {B3D} 体素化为二进制占用张量 O,其中 O(x,y,z,c)=1 表示体素(x,y,z)被类别c的目标占用,O(x,y,z,c)=0则表示未被占用。
- 对该占用张量进行下采样,并按通道维度拼接,形成条件占用特征 Focc,且确保其与状态特征 S 在空间上对齐。
- 通过逐元素加法将该条件注入 DiT:
Scond=S+γ⋅Focc,其中 γ 是引导尺度(guidance scale)。
二、实验结果
本文在 nuScenes(6 相机)和 Argoverse 2(AV2,7 相机)两个数据集上进行了实验,采用的评价指标包括:
- 重建质量:峰值信噪比(PSNR)、结构相似性指数(SSIM);
- 生成 / 重建质量:弗雷歇 inception 距离(FID);
- 多视图空间一致性(MVSC):通过生成 / 重建图像与真实图像中 LoFTR 关键点匹配置信度的比值来衡量。
实验得出的关键结论如下:
- 重建结果(表 1、图 3):增大潜在维度可提升图像质量(PSNR、SSIM、FID)和空间一致性(MVSC);BEV-VAE 的 MVSC 值较高,证明其借助共享 BEV 潜在空间能够有效维持多视图间的空间一致性。
- 新视角合成(图 4、图 8-13):通过调整相机外参实现新视角合成,进一步验证了所学习的 BEV 空间具有结构化的三维特性。
- 生成结果(表 2、图 5、图 6):成功实现了以三维布局为条件的多视图图像合成。
- 消融实验:
- 对潜在维度和引导尺度的消融实验确定了最优设置(例如潜在维度 = 256、引导尺度γ=2.0或γ=3.0);
- 对损失函数的消融实验(表 4)证实:感知损失和对抗损失对提升视觉真实感至关重要,KL 损失则有助于稳定优化。
- 与现有方法的对比(表 3):在 nuScenes 数据集上,从零开始训练的 BEV-VAE 显著优于 BEVGen,并缩小了与基于 Stable Diffusion 等大型预训练图像模型微调方法之间的性能差距,凸显了基于 BEV 方法的有效性。
- 可控生成能力:该框架支持通过三维目标操作(如目标移除(图 6、图 14-15)或旋转(图 16))实现可控生成。
三、局限性与未来工作
(一)局限性
- 与利用大型预训练图像模型的方法相比,BEV-VAE 生成图像的分辨率较低;
- 性能依赖于数据集规模(不过这也意味着随着数据量增加,模型具有可扩展性)。
(二)未来工作
未来可探索的方向包括:时间建模(temporal modeling)、物理先验(physical priors)的融入,以及在下游任务中的应用拓展。
四、总结
总体而言,BEV-VAE 通过将多视图图像生成过程建立在一致的三维 BEV 表示之上,为自动驾驶领域提供了一种结构化、可扩展的多视图图像生成方法。
链接
GitHub - Czm369/bev-vae: BEV-VAE: Multi-view Image Generation with Spatial Consistency for Autonomous Driving