吴恩达机器学习作业九:kmeans聚类
数据集在作业一
Kmeans聚类
K-means 是一种无监督聚类算法,其核心思想是将数据集划分为 k 个不同的簇(Cluster),使得每个簇内的数据点尽可能相似,而不同簇的数据点尽可能差异较大。
算法流程

这个过程其实有点像梯度下降,都是一点一点向最优值逼近。
代码
读取数据及可视化
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio# 读取数据
data=sio.loadmat("ex7data2.mat")
X=data['X']
# print(X.shape)(300, 2)# 可视化
def plot_data(X):plt.scatter(X[:,0],X[:,1],marker='o',c='y',edgecolors='g')plt.show()# plot_data(X)
簇分配
def find_centres(X,centers):m=X.shape[0]idx=np.zeros(m)for i in range(m):min_dist=np.inffor j in range(len(centers)):dist=np.sum((X[i]-centers[j])**2)if dist<min_dist:min_dist=distidx[i]=jreturn idx作用是对所有的点按照新的中心进行划分。
初始聚类中心
centers=np.array([[3,3],[6,2],[8,5]])
idx=find_centres(X,centers)#每个样本所属的簇索引
# print(idx)计算聚类中心,按照初始簇分配来计算平均中心
def compute_centres(X,idx,centers):centers=[]#用来存储新的聚类中心for i in range(int(idx.max())+1):centers.append(np.mean(X[idx==i],axis=0))return centerscenters_new=compute_centres(X,idx,centers)
# print(centers_new)计算聚类中心,按照初始簇分配来计算平均中心
def compute_centres(X,idx,centers):centers=[]#用来存储新的聚类中心for i in range(int(idx.max())+1):centers.append(np.mean(X[idx==i],axis=0))return centerscenters_new=compute_centres(X,idx,centers)
# print(centers_new)按照分好的簇,取新的一轮中心点
执行kmeans聚类
def kmeans(X,centers,count):centers_all=[]centers_all.append(centers)for i in range(count):idx=find_centres(X,centers)centers=compute_centres(X,idx,centers)centers_all.append(centers)return idx,np.array(centers_all)idx是用来记录最新的每个点属于哪一个簇,centers_all是用来记录所有中心点。
绘制kmeans聚类过程
def plot_kmeans(X,idx,centers_all):plt.scatter(X[:,0],X[:,1],marker='o',c=idx,cmap='rainbow')plt.plot(centers_all[:,:,0],centers_all[:,:,1],'kx--')plt.show()idx,centers_all=kmeans(X,centers,100)
plot_kmeans(X,idx,centers_all)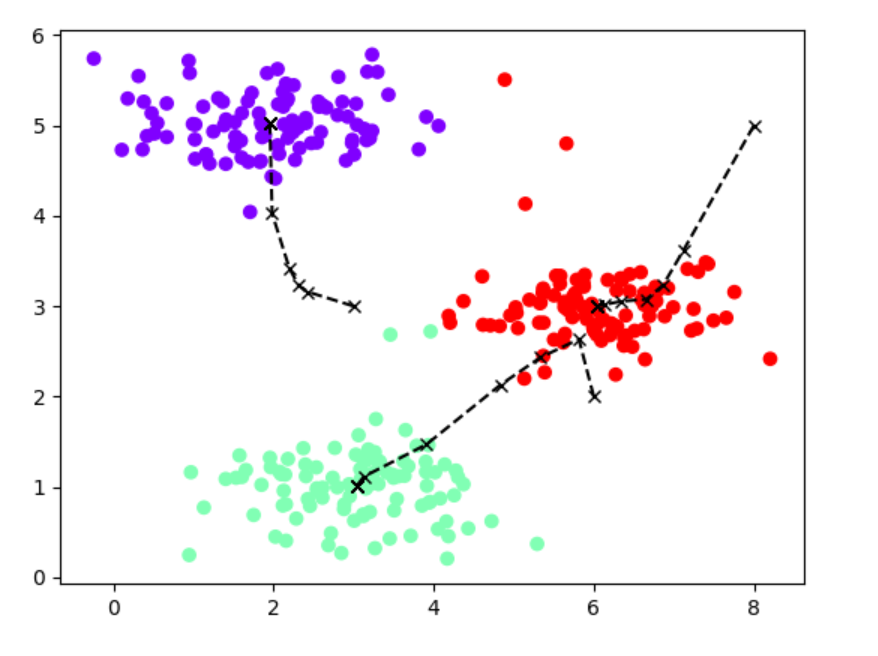
总结
读入数据——构建簇分配——构建计算簇类中心函数——初始化簇类中心——搭建执行kmeans算法