DAY 18 推断聚类后簇的类型 - 2025.8.30
推断聚类后簇的类型
聚类后的分析:推断簇的类型
知识点回顾:
- 推断簇含义的2个思路:先选特征和后选特征
- 通过可视化图形借助ai定义簇的含义
- 科研逻辑闭环:通过精度判断特征工程价值
作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征工程后模型效果有无提升。
笔记:
1. 推断簇含义的 2 个思路:先选特征 vs 后选特征
聚类是无监督学习(无预设标签),“推断簇含义” 本质是通过 “特征差异” 给无标签的簇赋予业务 / 科研意义。这两种思路的核心区别在于 “特征筛选的时机”,适用于不同数据场景:
思路 1:先选特征(“目标导向” 型,适合业务 / 科研目标明确场景)
-
核心逻辑:先根据已知的分析目标,筛选出与 “业务问题 / 研究假设” 强相关的特征,再基于这些特征的簇内分布差异,直接解读簇含义。
(避免 “用无关特征聚类后,无法关联业务” 的问题) -
实操步骤:
- 明确目标:比如 “分析用户消费行为聚类”,核心目标是区分 “高价值用户”“潜力用户”“低活跃用户”;
- 筛选核心特征:围绕目标选特征(如 “月消费额”“消费频率”“客单价”“最近消费时间”),排除无关特征(如 “用户注册地区编码”,若目标不涉及地域);
- 聚类与解读:基于筛选后的特征聚类,然后计算每个簇在核心特征上的统计值(均值、中位数、占比),通过差异定义含义。
例:簇 1“月消费额均值 5000+、消费频率 10 次 / 月”→ 定义为 “高价值活跃用户”;簇 2“月消费额均值 200+、消费频率 1 次 / 3 月”→ 定义为 “低活跃沉睡用户”。
-
适用场景:业务目标清晰(如用户分层、产品分类)、已知核心影响因素(如科研中已知某几个指标与研究变量相关)。
思路 2:后选特征(“探索导向” 型,适合数据无明确目标场景)
- 核心逻辑:先基于全量特征(或降维后的关键特征)完成聚类,再通过 “簇间特征差异分析”,筛选出对 “簇区分贡献最大的特征”,反推簇含义。
(适合 “数据驱动探索”,比如 “不知道数据能分几类、每类特点是什么” 的场景) - 实操步骤:
- 初步聚类:用全量标准化特征(或 PCA 降维后的主成分)做聚类(如 KMeans、层次聚类),得到簇标签;
- 筛选 “区分度高的特征”:
- 定量方法:计算每个特征在不同簇间的 “变异系数(CV)” 或 “ANOVA 方差分析的 F 值”——CV/F 值越大,说明该特征在簇间差异越显著,对簇区分的贡献越大;
- 工具支持:用pandas计算各簇的特征均值,用seaborn画 “箱线图 / 小提琴图” 直观对比簇间特征分布;
- 解读含义:基于 “高区分度特征” 的簇间差异定义含义。
例:全量特征(年龄、收入、消费、浏览时长)聚类后,发现 “收入” 和 “消费” 的簇间 CV 最大(簇 1 收入均值 8k、消费均值 3k;簇 2 收入均值 20k、消费均值 8k)→ 用这两个特征定义簇为 “中等收入消费型”“高收入高消费型”。
- 适用场景:数据探索阶段(如初期数据分析、科研中 “无预设假设的探索性研究”)、核心特征不明确(如不知道哪些指标能区分样本类型)。
2. 通过可视化图形借助 AI 定义簇的含义
可视化的核心是 “将高维特征的簇差异转化为直观图形”,而 AI 的作用是 “加速特征差异的识别”(避免人工对比多个特征的繁琐)。两者结合能大幅提升簇含义解读的效率和准确性,常见落地方式有 3 类:
方式 1:先可视化降维,再用 AI 分析特征贡献
- 流程:高维数据→PCA/TSNE 降维(转 2D/3D)→可视化簇分布→AI 计算 “特征对降维主成分的贡献”→关联簇含义。
例:- 用 PCA 将 10 个用户特征降为 2 个主成分(PC1、PC2),画散点图(颜色代表簇),先直观看到簇的分离情况;
- 用 AI 工具(如sklearn的PCA.explained_variance_ratio_、或 AI 分析平台(如 Tableau、PowerBI 的特征重要性插件)计算 “哪些原始特征对 PC1/PC2 贡献最大”—— 比如发现 “月消费额” 对 PC1 贡献 80%,“消费频率” 对 PC2 贡献 75%;
- 结合散点图中簇的位置(如簇 A 在 PC1 正方向、PC2 正方向)→ 对应 “高消费额 + 高频率”→ 定义为 “核心用户”。
方式 2:AI 生成 “簇特征对比报告”,结合可视化验证
- 流程:聚类后→用 AI 工具(如 Python 的pandas_profiling、ChatGPT 代码生成器、专业数据分析 AI(如 DataRobot))自动输出 “各簇在所有特征上的统计对比表”→ 用可视化(热力图、雷达图)呈现差异→ 基于报告定义含义。
例:- AI 自动生成表格:包含每个簇的 “特征均值、中位数、占比”,并标注 “簇间差异显著的特征”(如用星号标记 ANOVA p<0.05 的特征);
- 用热力图可视化 “簇 - 特征均值矩阵”(颜色越深代表均值越高),直观看到 “簇 3 在‘复购率’‘客单价’上颜色最深,在‘退货率’上颜色最浅”;
- 结合报告和热力图,定义簇 3 为 “高复购、高客单、低退货的优质用户”。
方式 3:AI 辅助 “业务标签映射”(适合有历史业务数据场景)
- 流程:若数据中包含 “非标签但有业务含义的字段”(如用户的 “历史营销活动参与记录”“商品购买品类”)→ 用 AI 工具(如文本聚类、关联规则算法)分析 “簇与业务字段的关联关系”→ 定义含义。
例:- 聚类得到用户簇后,用 AI 分析 “各簇用户参与‘618 大促’的占比”—— 发现簇 1 参与率 85%,其他簇 < 30%;
- 再分析 “簇 1 购买的商品品类”——AI 关联规则显示 “簇 1 购买‘高端家电’的概率是其他簇的 5 倍”;
- 结合两者,定义簇 1 为 “大促敏感型高端家电消费者”。
3. 科研逻辑闭环:通过精度判断特征工程价值
聚类本身无 “精度” 概念(无预设标签),这里的 “精度” 本质是聚类结果的 “有效性验证指标”,而 “特征工程价值” 则是通过 “不同特征工程方案下的聚类有效性差异” 来判断 —— 核心是 “用验证指标量化特征工程的好坏”,形成 “特征工程→聚类→验证→优化” 的闭环。
第一步:明确 “聚类有效性指标”(替代 “精度” 的核心指标)
聚类无真实标签,需用内部指标(基于数据本身的特征分布)或外部指标(若有间接标签)判断结果质量:
| 指标类型 | 常用指标 | 核心含义 | 评判标准 |
|---|---|---|---|
| 内部指标 | 轮廓系数(Silhouette) | 衡量 “簇内样本相似度” 与 “簇间样本差异度” 的平衡 | 越接近 1 越好(取值范围 [-1,1]) |
| 内部指标 | CH 指数(Calinski-Harabasz) | 簇间方差与簇内方差的比值 | 越大越好(值越大,簇区分越明显) |
| 内部指标 | DB 指数(Davies-Bouldin) | 簇内平均距离与簇间距离的比值 | 越接近 0 越好(值越小,簇内越紧凑、簇间越分散) |
| 外部指标 | 调整兰德指数(ARI) | 若有 “间接标签”(如业务中人工标注的少量样本),衡量聚类结果与间接标签的一致性 | 越接近 1 越好(取值范围 [-1,1]) |
第二步:用 “指标差异” 判断特征工程价值
特征工程(如特征筛选、归一化、降维、缺失值填充)的核心目的是 “提升数据对聚类任务的适配性”,其价值可通过 “同一聚类算法下,不同特征工程方案的有效性指标对比” 来量化:
- 实操逻辑:控制 “聚类算法、超参数(如 KMeans 的 k 值)” 不变,只改变 “特征工程方案”,对比指标优劣。
- 案例:分析 “用户消费数据聚类”,测试 2 种特征工程方案:
| 特征工程方案 | 聚类算法 | 轮廓系数 | CH 指数 | DB 指数 | 结论(特征工程价值) |
|---|---|---|---|---|---|
| 方案 1:全量原始特征(未标准化,含无关特征 “注册时间”) | KMeans(k=3) | 0.32 | 156 | 1.28 | 指标较差,无关特征 + 未标准化干扰了聚类 |
| 方案 2:筛选核心特征(消费额、频率、客单价)+ 标准化 | KMeans(k=3) | 0.68 | 423 | 0.51 | 所有指标显著优于方案 1,说明该特征工程方案有效,提升了聚类质量 |
第三步:形成科研闭环
通过 “指标对比” 验证特征工程价值后,需进一步关联 “聚类结果的业务 / 科研意义”,形成完整闭环:
特征工程方案A → 聚类结果A → 指标验证(A优于B/C)→ 解读簇含义(A的结果更易关联业务目标)→ 结论(方案A更适合该聚类任务)
例:科研中研究 “细胞类型聚类”,方案 A(筛选与细胞功能相关的 10 个基因特征)的 CH 指数是方案 B(全量 50 个基因特征)的 2.3 倍,且方案 A 的簇能对应已知的 “活性细胞 / 休眠细胞” 类型,方案 B 的簇无法关联细胞功能→ 结论 “筛选核心基因特征的工程方案,对细胞聚类任务有显著价值”。
总结
这 3 个方向本质是 “聚类分析落地的三阶逻辑”:
- 簇含义解读(先选 / 后选特征):解决 “聚类后不知道簇是什么” 的问题;
- 可视化 + AI 辅助:提升解读效率,避免人工分析的片面性;
- 指标验证特征工程价值:解决 “如何判断聚类结果可靠” 的问题,形成科研 / 业务闭环。
实际应用中,三者通常结合使用(如 “先选特征聚类→用可视化 + AI 解读簇含义→用指标验证特征工程是否有效”),确保从数据到结论的严谨性。
4. 附录
1. axes.flatten() 的具体作用
flatten() 是 numpy 数组的内置方法,作用是将任意维度的数组 “展平” 为一维数组,且不改变元素的顺序(默认按 “行优先” 顺序,即先遍历第一行,再遍历第二行……)。
对 matplotlib 的子图 axes 数组使用 flatten(),就是将多维的子图坐标轴数组转为一维,后续可以用 单个索引 直接定位到某个子图,而不用嵌套索引。
2. 对比:用与不用 flatten() 的区别
以 “2 行 2 列的子图” 为例,直观对比两种访问方式:
场景:创建 2×2 子图,给每个子图画折线图
import matplotlib.pyplot as plt
import numpy as np# 1. 创建 2 行 2 列的子图,axes 是 2×2 的二维数组
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
x = np.linspace(0, 10, 100) # 生成 x 数据
方式 1:不用flatten(),需嵌套索引访问子图
二维数组需要用 axes[行索引, 列索引] 访问,索引从 0 开始:
# 第 1 行第 1 个子图(行 0,列 0)
axes[0, 0].plot(x, np.sin(x))
axes[0, 0].set_title('sin(x)')# 第 1 行第 2 个子图(行 0,列 1)
axes[0, 1].plot(x, np.cos(x))
axes[0, 1].set_title('cos(x)')# 第 2 行第 1 个子图(行 1,列 0)
axes[1, 0].plot(x, np.tan(x))
axes[1, 0].set_title('tan(x)')# 第 2 行第 2 个子图(行 1,列 1)
axes[1, 1].plot(x, np.exp(x))
axes[1, 1].set_title('exp(x)')
方式 2:用 flatten(),一维索引直接访问子图
先将二维 axes 展平为一维,再用 axes[索引] 访问(索引按 “行优先” 顺序,0→1→2→3):
# 将 2×2 的二维 axes 展平为一维数组(长度 4)
axes = axes.flatten()# 第 1 个子图(索引 0,对应原 0,0)
axes[0].plot(x, np.sin(x))
axes[0].set_title('sin(x)')# 第 2 个子图(索引 1,对应原 0,1)
axes[1].plot(x, np.cos(x))
axes[1].set_title('cos(x)')# 第 3 个子图(索引 2,对应原 1,0)
axes[2].plot(x, np.tan(x))
axes[2].set_title('tan(x)')# 第 4 个子图(索引 3,对应原 1,1)
axes[3].plot(x, np.exp(x))
axes[3].set_title('exp(x)')
总结
axes = axes.flatten() 的核心是将多维子图坐标轴数组转为一维,核心价值是:
- 简化子图访问方式(用单个索引替代嵌套索引);
- 支持批量循环处理子图(避免嵌套循环,代码更简洁);
- 是 matplotlib 多子图绘图中 “批量操作” 的常用技巧。
作业
1. 心脏病数据集做聚类分析
# 数据导入
import pandas as pd
data = pd.read_csv('heart.csv')
data.head()
age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target
0 63 1 3 145 233 1 0 150 0 2.3 0 0 1 1
1 37 1 2 130 250 0 1 187 0 3.5 0 0 2 1
2 41 0 1 130 204 0 0 172 0 1.4 2 0 2 1
3 56 1 1 120 236 0 1 178 0 0.8 2 0 2 1
4 57 0 0 120 354 0 1 163 1 0.6 2 0 2 1
# 区分标签和特征
X = data.drop(['target'],axis=1)
y = data['target']# 对特征做数据标准化处理
from sklearn.preprocessing import StandardScaler # 包导入
scaler = StandardScaler() # 初始化
X_scaled = scaler.fit_transform(X) # 对X做标准化
from sklearn.cluster import KMeans # 导入K-meand聚类算法
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score # 导入轮廓系数,CH指数,DB指数# 评估不同K值下的指标
k_range = range(2,11) # 选择范围 K 从 2 到 10
inertia_values = [] # 存储不同k值对应的惯性(肘部法则)
silhouette_scores = [] # 存储不同k值对应的轮廓系数
ch_scores = [] # 存储不同k值对应的CH指数
db_scores = [] # 存储不同k值对应的DB指数# 利用for循环遍历所有K值,计算不同K值的惯性,轮廓系数,CH指数,DB指数,并存储for k in k_range:kmeans = KMeans(k,random_state=42) # 初始化KMeans模型,指定聚类数为k,设置随机种子确保结果可重现kmeans_labels = kmeans.fit_predict(X_scaled) # 对标准化后的数据集X_scaled进行拟合并预测聚类标签inertia_value = kmeans.inertia_ # 计算惯性(所有样本到其最近聚类中心的距离平方和)inertia_values.append(inertia_value) # 存储silhouette = silhouette_score(X_scaled,kmeans_labels) # 计算轮廓系数(评估聚类质量,范围[-1,1],越接近1越好)silhouette_scores.append(silhouette) # 存储ch = calinski_harabasz_score(X_scaled,kmeans_labels) # 计算CH指数(值越大表示聚类效果越好)ch_scores.append(ch) # 存储db = davies_bouldin_score(X_scaled,kmeans_labels) # 计算DB指数(值越小表示聚类效果越好)db_scores.append(db) # 存储print(f'k={k},惯性:{inertia_value:.2f},轮廓系数:{silhouette:.3f},CH 指数:{ch:.2f}, DB 指数:{db:.3f}')import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制评估指标图
plt.figure(figsize=(15,10)) # 新建画布# 肘部法则图(Inertia)
plt.subplot(2,2,1) # 包含2行 2列的子图,当前为第一个子图
plt.plot(k_range,inertia_values,marker = 'o') # x值为k_range,y值为inertia_values
plt.title('肘部法则确定最优聚类数k(惯性越小越好)') # 标题
plt.xlabel('聚类数(k)') # 横坐标
plt.ylabel('惯性') # 纵坐标
plt.grid(True) # 显示网格# 轮廓系数图
plt.subplot(2,2,2) # 当前为第二个子图
plt.plot(k_range,silhouette_scores,marker='o', color='orange') # x值为k_range,y值为silhouette_scores
plt.title('轮廓系数确定最优聚类数k(越大越好)') # 标题
plt.xlabel('聚类数(k)') # 横坐标
plt.ylabel('轮廓系数') # 纵坐标
plt.grid(True) # 显示网格# CH指数图
plt.subplot(2,2,3) # 当前为第三个子图
plt.plot(k_range,ch_scores,marker='o',color='green')
plt.title('Calinski-Harabasz 指数确定最优聚类数k(越大越好)')
plt.xlabel('聚类数(k)')
plt.ylabel('CH指数')
plt.grid(True)# DB 指数图
plt.subplot(2,2,4) # 当前为第四个子图
plt.plot(k_range,db_scores,marker = 'o',color='red')
plt.title('Davies-Bouldin 指数确定最优聚类数 k(越小越好)')
plt.xlabel('聚类数 (k)')
plt.ylabel('DB 指数')
plt.grid(True)plt.tight_layout()
plt.show()
k=2,惯性:3331.64,轮廓系数:0.166,CH 指数:54.87, DB 指数:2.209
k=3,惯性:3087.69,轮廓系数:0.112,CH 指数:41.36, DB 指数:2.544
k=4,惯性:2892.52,轮廓系数:0.118,CH 指数:36.06, DB 指数:2.175
k=5,惯性:2814.65,轮廓系数:0.094,CH 指数:29.76, DB 指数:2.386
k=6,惯性:2673.22,轮廓系数:0.095,CH 指数:28.13, DB 指数:2.377
k=7,惯性:2596.68,轮廓系数:0.088,CH 指数:25.50, DB 指数:2.290
k=8,惯性:2464.39,轮廓系数:0.115,CH 指数:25.22, DB 指数:2.136
k=9,惯性:2415.63,轮廓系数:0.105,CH 指数:23.18, DB 指数:2.133
k=10,惯性:2337.41,轮廓系数:0.111,CH 指数:22.31, DB 指数:2.056
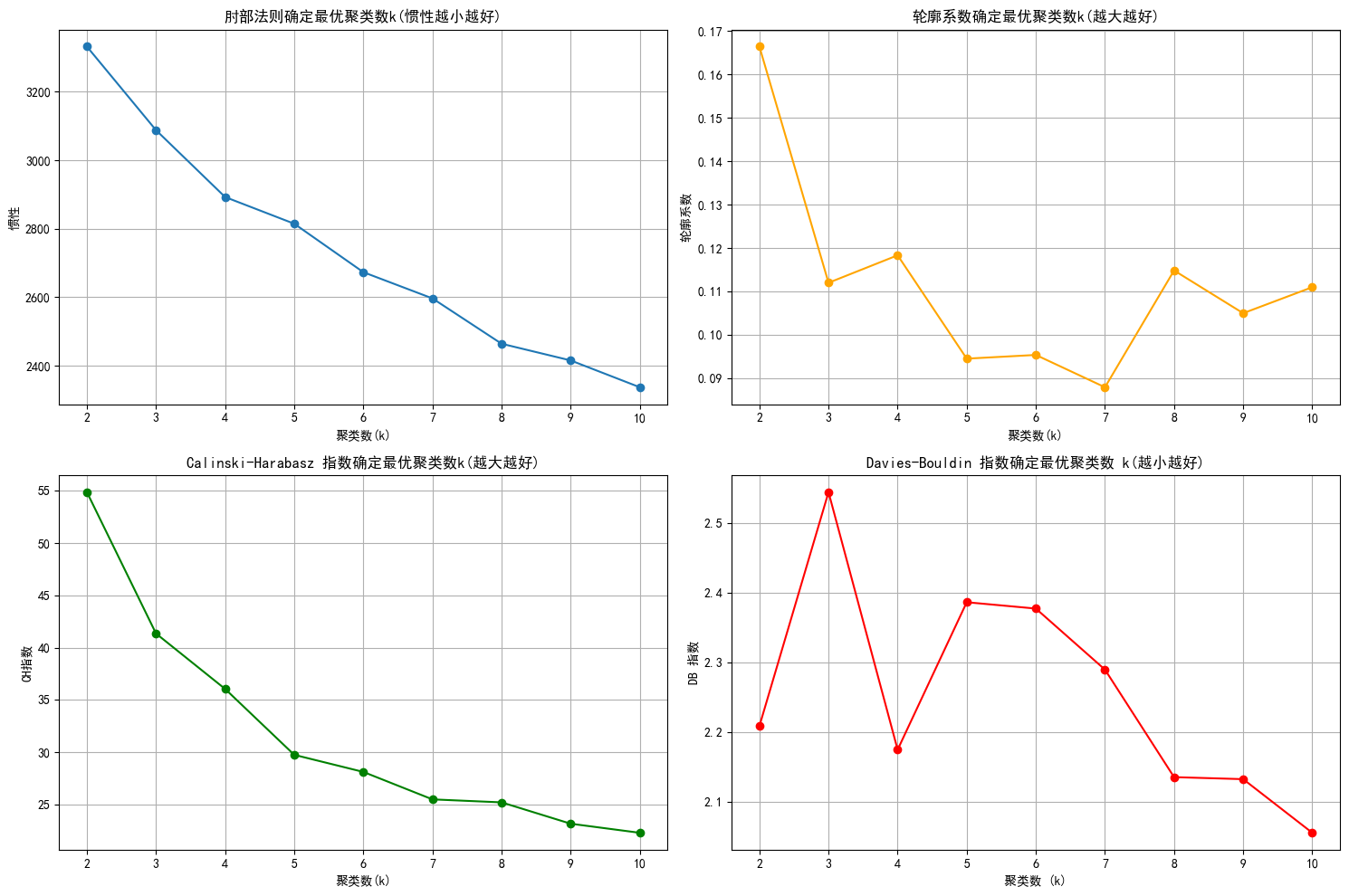
- 根据肘部法则,都可以
- 根据轮廓系数,2,4,8,10
- 根据CH指数,8之前
- 根据DB指数,2,4,10
综上,2,4应该都可以,我们选择4
selected_k = 4# 使用选择的 k 值进行 KMeans 聚类
kmeans = KMeans(n_clusters=selected_k,random_state=42)
kmeans_labels = kmeans.fit_predict(X_scaled)
X['KMeans_Cluster'] = kmeans_labels # 在原始数据集 X 中添加一列 "KMeans_Cluster",存储每个样本对应的聚类标签,便于后续分析# 导入pca
from sklearn.decomposition import PCA # 使用pca降维到 2D 进行可视化
pca = PCA(n_components=2) #初始化 PCA(主成分分析)模型,指定降维到 2 个维度
X_pca = pca.fit_transform(X_scaled) #对标准化数据 X_scaled 进行 PCA 降维处理import matplotlib.pyplot as plt
import seaborn as sns # 导入seaborn# KMeans 聚类结果可视化
plt.figure(figsize=(6,5)) # 建画布
sns.scatterplot(x=X_pca[:,0],y=X_pca[:,1],hue = kmeans_labels,palette='viridis')
# 使用 seaborn 绘制散点图,x 轴为 PCA 第一主成分,y 轴为 PCA 第二主成分
# 用不同颜色(hue=kmeans_labels)表示不同的聚类
# 使用 'viridis' 调色板,使颜色区分明显plt.title(f'KMeans Clustering with k={selected_k} (PCA Visualization)')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.show()# 打印 KMeans 聚类标签的前几行
print(f"KMeans Cluster labels (k={selected_k}) added to X:")
print(X[['KMeans_Cluster']].value_counts())
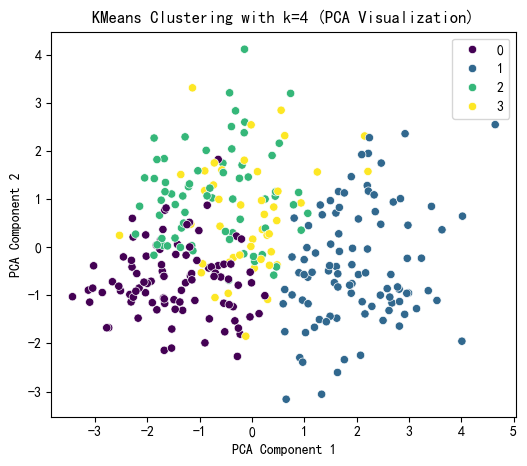
KMeans Cluster labels (k=4) added to X:
KMeans_Cluster
1 95
0 94
2 69
3 45
Name: count, dtype: int64
X.columns
Index(['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'thalach','exang', 'oldpeak', 'slope', 'ca', 'thal', 'KMeans_Cluster'],dtype='object')
x1 = X.drop('KMeans_Cluster',axis = 1) # 删除聚类标签列
y1 = X['KMeans_Cluster']# 构建随机森林,用shap重要性来筛选重要性
import shap
import numpy as np
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
model = RandomForestClassifier(n_estimators=100, random_state=42) # 随机森林模型
model.fit(x1, y1) # 训练模型,此时无需在意准确率 直接全部数据用来训练了

shap.initjs()
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x1) # 这个计算耗时
shap_values.shape # 第一维是样本数,第二维是特征数,第三维是类别数
(303, 13, 4)
# --- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:, :, 0], x1, plot_type="bar",show=False) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()
— 1. SHAP 特征重要性条形图 —
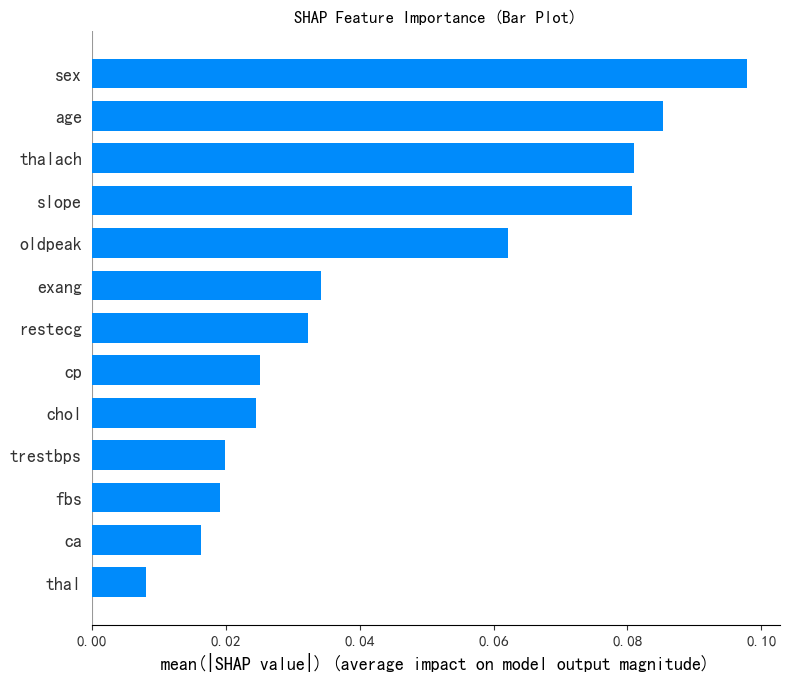
# 此时判断一下这几个特征是离散型还是连续型
import pandas as pd
selected_features = ['sex', 'age','thalach', 'slope']for feature in selected_features:unique_count = X[feature].nunique() # 唯一值指的是在某一列或某个特征中,不重复出现的值# 连续型变量通常有很多唯一值,而离散型变量的唯一值较少print(f'{feature} 的唯一值数量: {unique_count}')if unique_count < 10: # 这里 10 是一个经验阈值,可以根据实际情况调整print(f'{feature} 可能是离散型变量')else:print(f'{feature} 可能是连续型变量')
sex 的唯一值数量: 2
sex 可能是离散型变量
age 的唯一值数量: 41
age 可能是连续型变量
thalach 的唯一值数量: 91
thalach 可能是连续型变量
slope 的唯一值数量: 3
slope 可能是离散型变量
# X["Purpose_debt consolidation"].value_counts() # 统计每个唯一值的出现次数
import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()
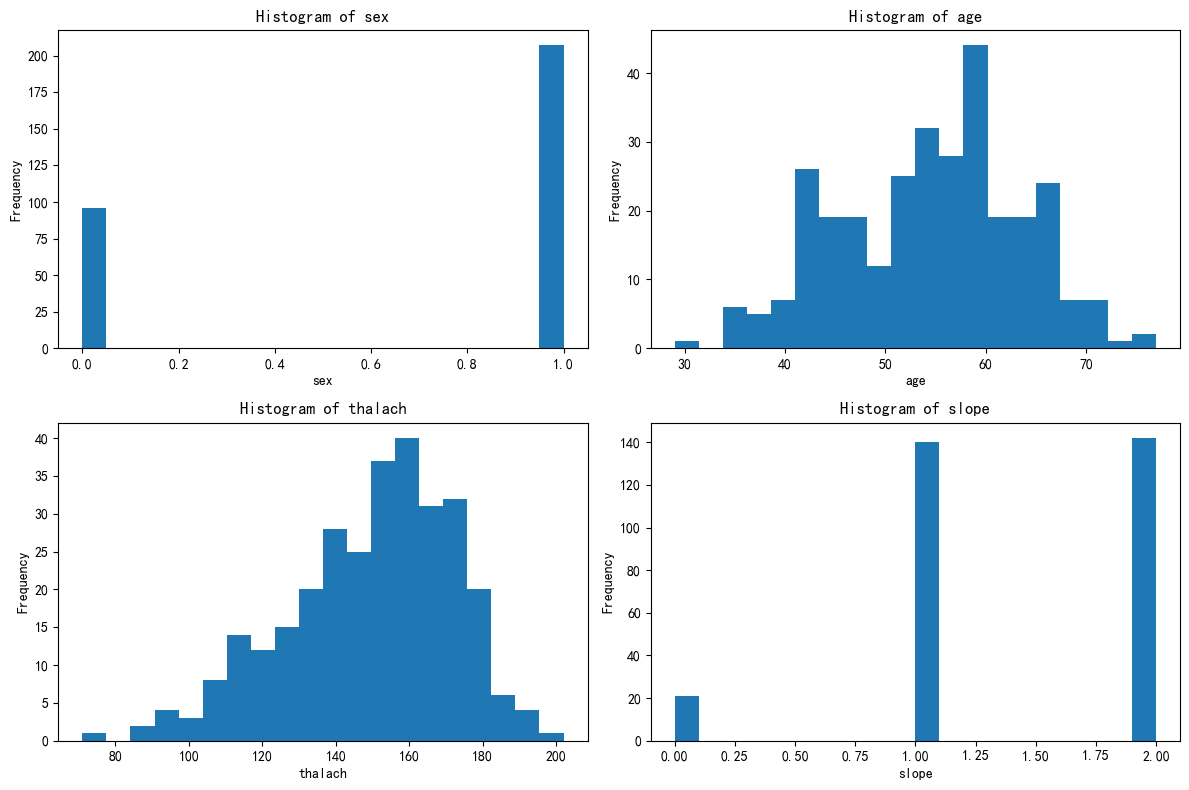
# 绘制出每个簇对应的这四个特征的分布图
X[['KMeans_Cluster']].value_counts()
KMeans_Cluster
1 95
0 94
2 69
3 45
Name: count, dtype: int64
# 分别筛选出每个簇的数据
X_cluster0 = X[X['KMeans_Cluster'] == 0]
X_cluster1 = X[X['KMeans_Cluster'] == 1]
X_cluster2 = X[X['KMeans_Cluster'] == 2]
X_cluster3 = X[X['KMeans_Cluster'] == 3]
# 先绘制簇0的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster0[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()
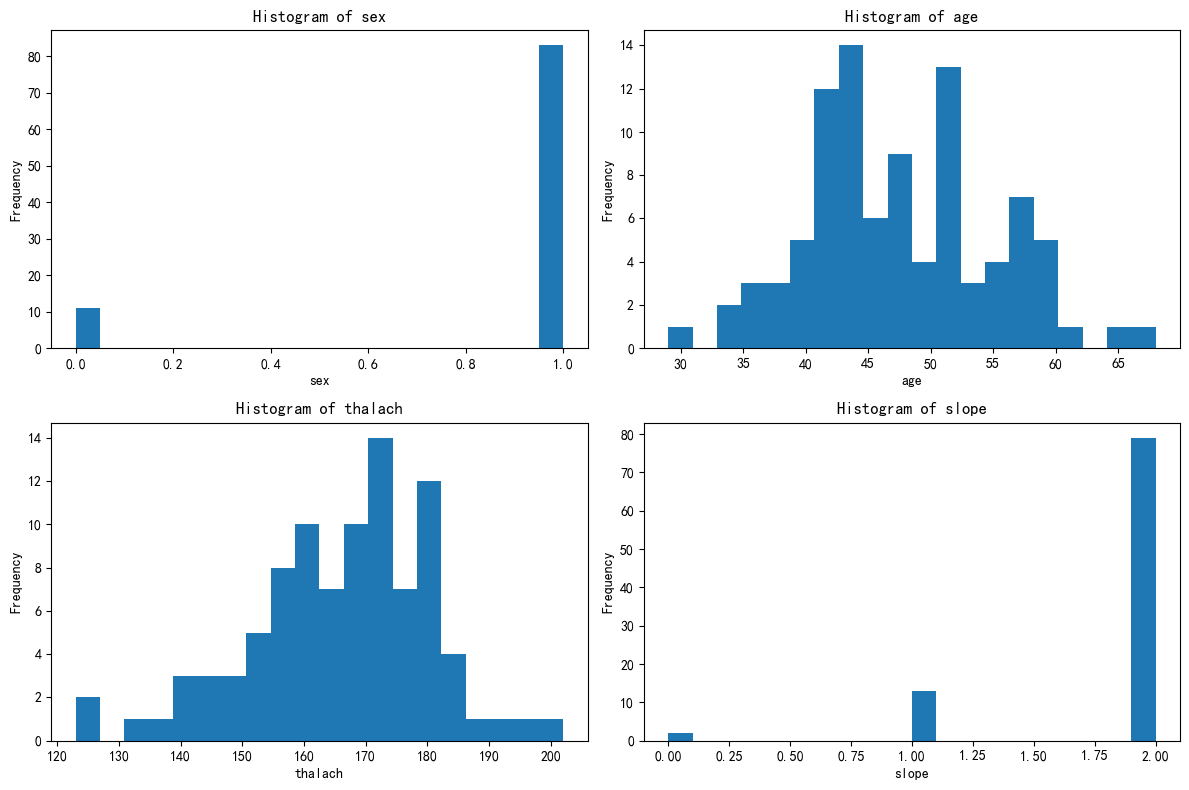
# 先绘制簇1的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
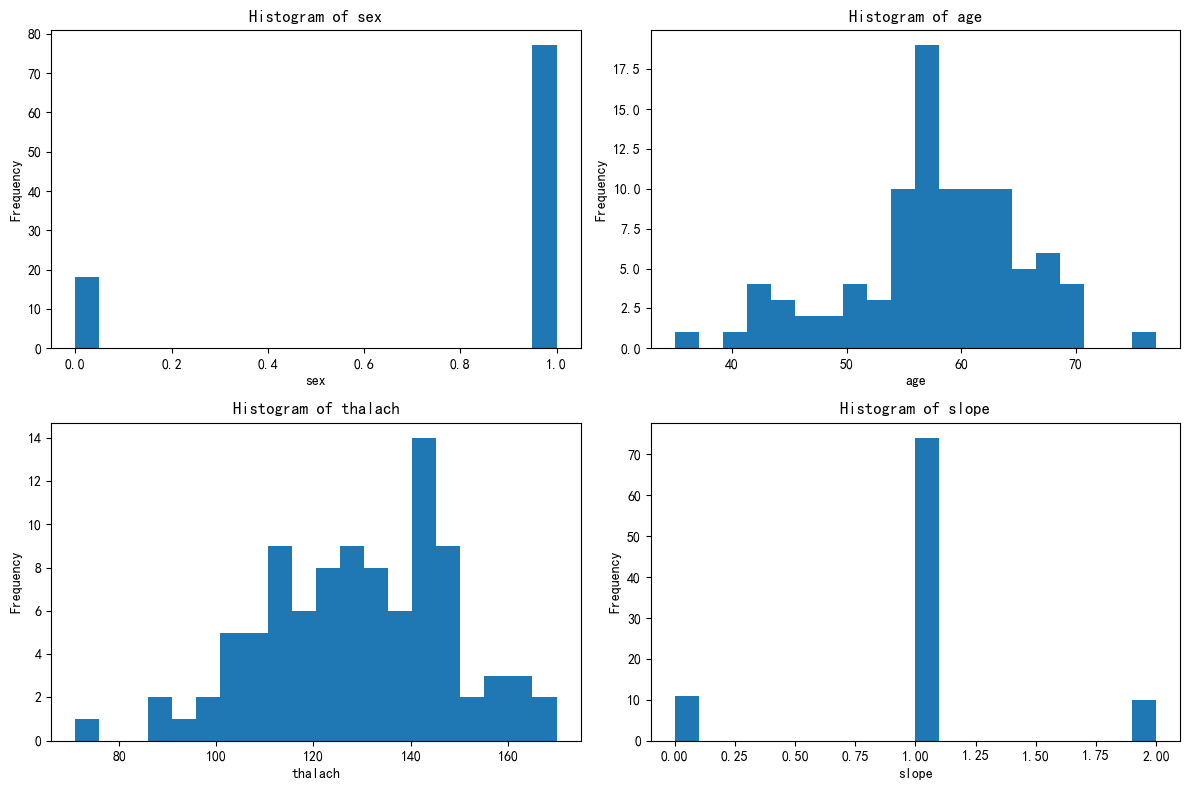
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster1[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()
# 先绘制簇2的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
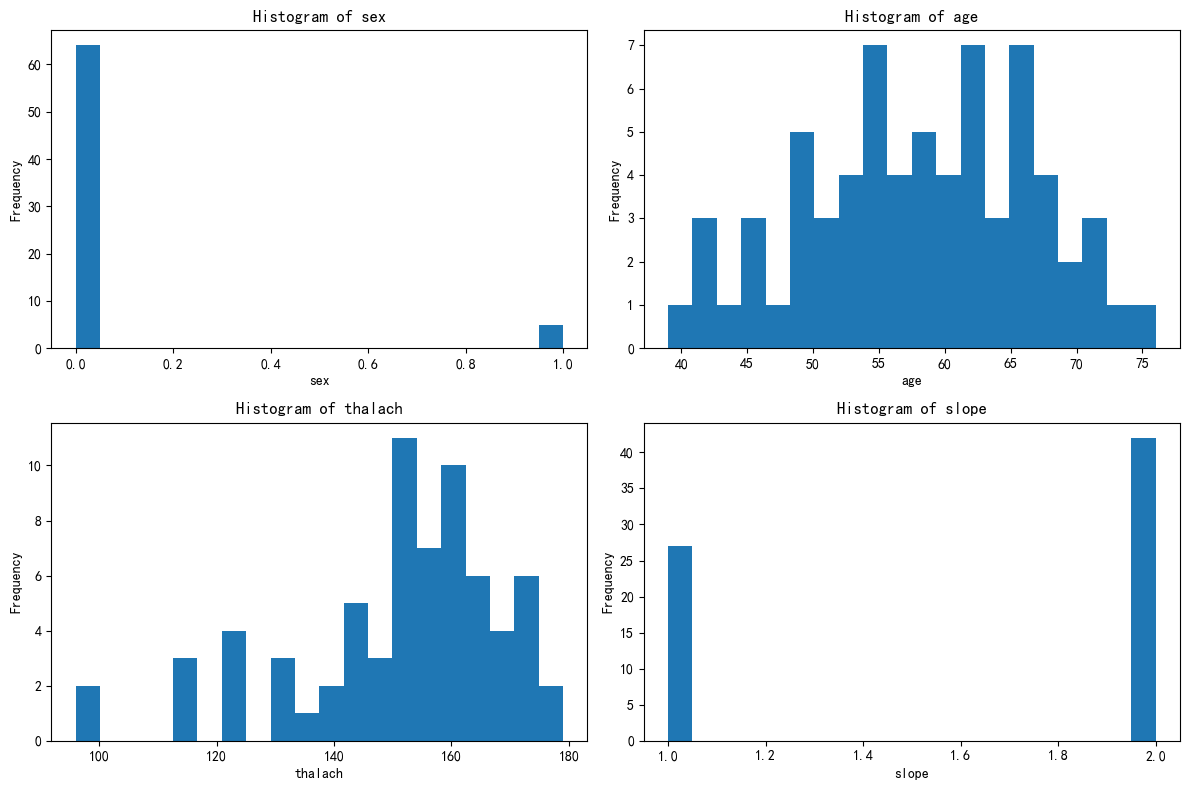
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster2[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()
# 先绘制簇3的分布图import matplotlib.pyplot as plt# 总样本中的前四个重要性的特征分布图
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()for i, feature in enumerate(selected_features):axes[i].hist(X_cluster3[feature], bins=20)axes[i].set_title(f'Histogram of {feature}')axes[i].set_xlabel(feature)axes[i].set_ylabel('Frequency')plt.tight_layout()
plt.show()
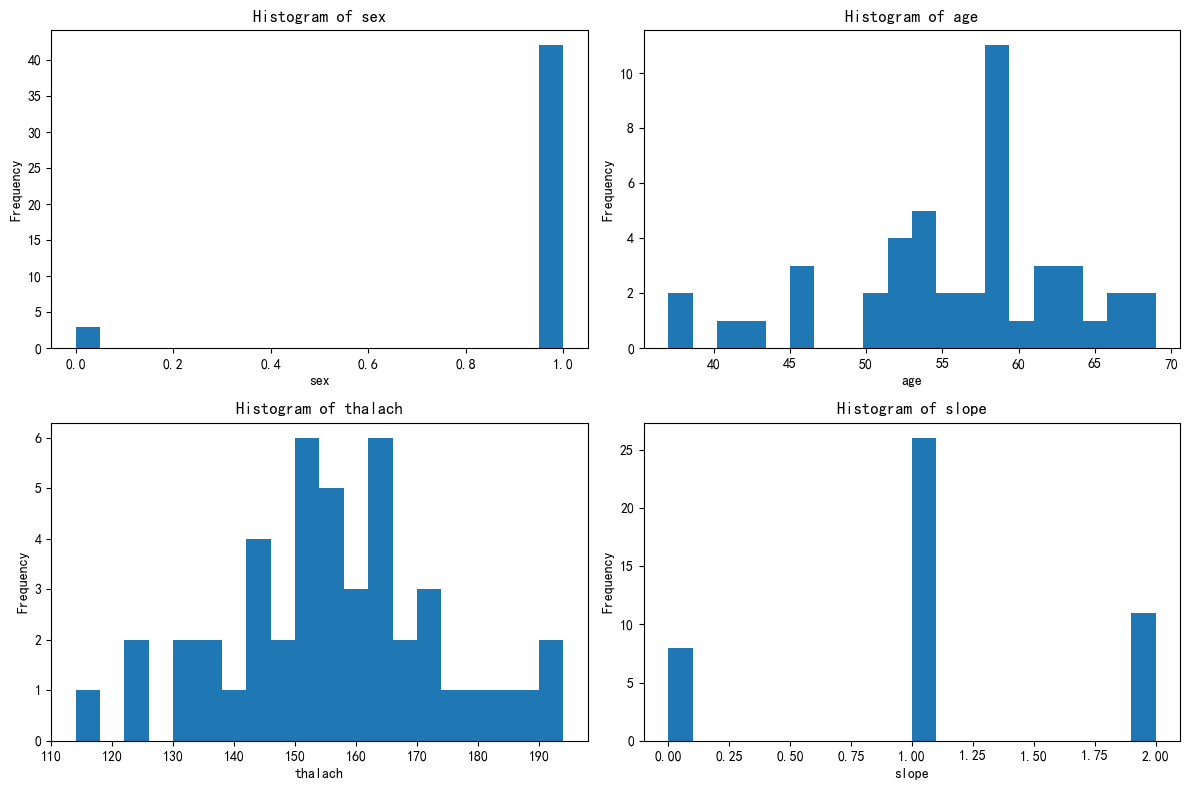
这 4 个簇可能对应 “不同性别 + 年龄层的心脏生理状态分组”:
- 簇 1:年轻男性,心脏储备强、运动耐量高;
- 簇 2:中年男性,心脏功能处于 “人生中期”,负荷能力平稳;
- 簇 3:老年男性,心脏储备随年龄下降,运动时心率响应弱;
- 簇 4:女性群体,因生理差异,心脏指标分布与男性呈现系统性不同。
@浙大疏锦行