使用 JavaScript 构建 RAG(检索增强生成)库:原理与实现
在这篇文章中,我们将探索如何用 JavaScript 构建一个 RAG 库。该库将集成检索、向量存储、以及生成模型等组件,提供一个完整的解决方案,用于处理基于查询的文本生成。
目录
什么是 RAG(检索增强生成)?
构建 RAG 库的基础组件
向量检索(Retriever)
文本切分与向量化(Embedding)
生成模型(Generator)
代码实现:JavaScript RAG 库
向量存储与检索
生成模型与回答
性能优化与扩展
总结与未来展望
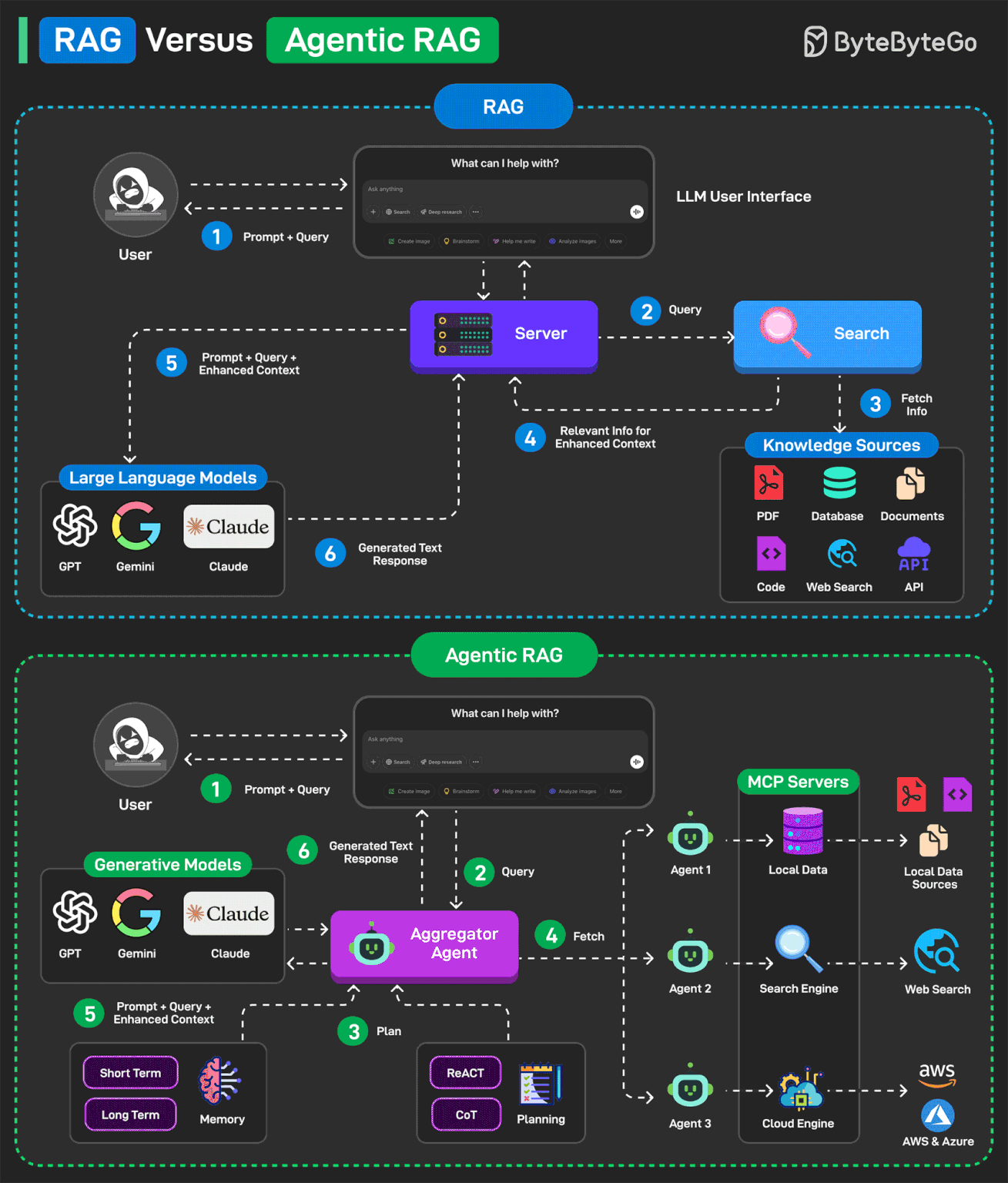
1. 什么是 RAG(检索增强生成)?
RAG 是一种将大语言模型与外部信息检索相结合的技术。具体来说,它将用户查询通过检索引擎与外部知识库中的文档匹配,获得相关的信息片段,然后将这些信息与用户问题一同输入生成模型,生成更为准确的答案。
RAG 技术的优势在于:
提升生成质量:通过引入外部文档信息,能够帮助语言模型避免“幻觉”现象(即模型生成不准确或不相关的内容)。
降低模型复杂度:不需要预先训练一个巨大的语言模型来记住所有知识,模型只需要生成相关信息的解释或答案。
提高上下文准确性:在对话或查询场景下,能基于特定文档回答问题,提供更具上下文的答案。
2. 构建 RAG 库的基础组件
为了实现一个简单的 JavaScript RAG 库,我们需要构建以下几个基础组件:
2.1 向量检索(Retriever)
向量检索的目标是将文本数据转换为向量,并通过向量空间中的相似度来找到与用户查询最相关的文档。这通常需要一个嵌入(embedding)模型,如 OpenAI 的文本嵌入(text-embedding)模型。
2.2 文本切分与向量化(Embedding)
为了将文档转化为可以用于检索的向量,我们需要对文本进行切分,并将每个文本片段转化为向量。这通常通过嵌入模型来完成。
2.3 生成模型(Generator)
生成模型(如 GPT-4、BERT 等)负责根据检索到的文档与用户输入生成合适的答案。生成模型会结合查询和相关文档信息,生成自然语言文本。
3. 代码实现:JavaScript RAG 库
以下是实现 RAG 库的核心代码,涉及向量检索、文本切分、向量化和生成模型的集成。
3.1 向量存储与检索(VectorStore)
首先,我们需要创建一个简化版的 MemoryVectorStore,用于存储文档的向量化信息并进行检索。
// vectorStore.js
class MemoryVectorStore {constructor() {this.documents = [];this.vectors = [];}// 向向量库添加文档与其向量表示addDocument(doc, vector) {this.documents.push(doc);this.vectors.push(vector);}// 基于向量与查询进行相似度检索async search(queryVector, topK = 3) {const scores = this.vectors.map((vector, idx) => {// 计算向量的余弦相似度const dotProduct = vector.reduce((sum, val, i) => sum + val * queryVector[i], 0);const magnitudeA = Math.sqrt(vector.reduce((sum, val) => sum + val * val, 0));const magnitudeB = Math.sqrt(queryVector.reduce((sum, val) => sum + val * val, 0));return dotProduct / (magnitudeA * magnitudeB);});// 获取 topK 相似度最高的文档const topDocs = scores.map((score, idx) => ({ score, doc: this.documents[idx] })).sort((a, b) => b.score - a.score).slice(0, topK).map((entry) => entry.doc);return topDocs;}
}module.exports = MemoryVectorStore;
3.2 文本切分与向量化(Embedding)
接下来,我们需要将文档文本转化为向量表示。在实际应用中,可以通过 API(如 OpenAI API)或本地模型生成文本的向量。这里我们假设用简单的随机数生成器模拟向量。
// embedding.js
const MemoryVectorStore = require('./vectorStore');// 模拟生成嵌入向量
function embedText(text) {return Array.from({ length: 128 }, () => Math.random()); // 假设向量维度为 128
}async function embedDocuments(documents) {const vectorStore = new MemoryVectorStore();documents.forEach((doc) => {const vector = embedText(doc);vectorStore.addDocument(doc, vector);});return vectorStore;
}module.exports = embedDocuments;
3.3 生成模型(Generator)
接下来,我们可以创建一个简单的生成模型接口,用于生成回答。在实际情况中,你可以使用 OpenAI API 或其他语言模型生成回答。
// generator.js
const { Configuration, OpenAIApi } = require("openai");async function generateAnswer(question, context) {const configuration = new Configuration({apiKey: process.env.OPENAI_API_KEY,});const openai = new OpenAIApi(configuration);const prompt = `Q: ${question}\n\nContext:\n${context}\n\nAnswer:`;const response = await openai.createCompletion({model: "text-davinci-003",prompt,max_tokens: 150,});return response.data.choices[0].text.trim();
}module.exports = generateAnswer;
3.4 结合所有组件实现 RAG
最终,我们将所有组件结合起来,构建一个完整的 RAG 流程。
// rag.js
const embedDocuments = require('./embedding');
const generateAnswer = require('./generator');
const MemoryVectorStore = require('./vectorStore');async function runRAG(query, documents) {const vectorStore = await embedDocuments(documents);// 将查询转换为向量(此处我们简化为随机数生成)const queryVector = Array.from({ length: 128 }, () => Math.random());// 检索相关文档const topDocs = await vectorStore.search(queryVector);// 将检索到的文档组合成上下文const context = topDocs.join("\n");// 使用生成模型生成答案const answer = await generateAnswer(query, context);return answer;
}// 示例使用
const documents = ["LangChain 是一个用于构建大规模自然语言处理应用的框架。","RAG(检索增强生成)通过结合生成模型和检索来提高答案的准确性。","OpenAI 提供强大的 API 用于文本生成和嵌入。"
];const query = "什么是 LangChain?";runRAG(query, documents).then((answer) => {console.log("Generated Answer:", answer);
});
4. 性能优化与扩展
为了提高 RAG 系统的性能和可扩展性,以下是一些优化建议:
向量存储的持久化:可以使用像 Pinecone、Weaviate 或 Qdrant 等外部向量数据库来替代内存存储,支持更大规模的数据检索。
批量向量化:通过批量化处理文档向量化,提高效率。
缓存机制:对常见查询结果进行缓存,避免重复计算。
并行化处理:对于大型文档库,可以通过并行化处理检索与生成步骤,提高响应速度。
5. 总结与未来展望
在本文中,我们通过构建一个简单的 JavaScript RAG 库,展示了如何实现基于检索增强生成的问答系统。通过将向量检索、文本切分与向量化、生成模型等组件组合起来,我们能够高效地生成基于外部文档的答案。
未来,我们可以进一步优化 RAG 系统的性能,支持更复杂的模型和更大规模的数据存储,从而为各种应用场景提供强大的支持。