nacos 2.5.1 心跳源码解析
前言
最近在看 nacos 的源码,选择的版本是 2.5.1,当然这都不是重点,重点是在学习的过程中,遇到想不通的问题的时候,不论是问 AI 还是 在网上找信息,几乎就找不到正确的,都是人云亦云甚至直接抄别人的文章,最突出的表现就是 拿着 nacos 1.x 的源码,讲着 2.x 的原理。求人不如求己,自己来。
nacos 1.x 和 nacos 2.x 版本的主要区别
有很多,但是这里就说一点:
Nacos 2.x 重构了通信层,采用长连接代替 HTTP 短轮询,显著降低网络开销。新增 gRPC 协议支持,提升服务发现与配置推送的实时性。1.x 版本依赖 HTTP 轮询,存在延迟高和资源消耗大的问题。
实际上,在2.x 版本中,默认就是使用 grpc ,而非 http,但是http依旧做了保留。
下面步入正题,下文所说nacos均为 2.5.1 版本,代码全部来源于源码
心跳的基本概念
在看源码之前,首先需要对 “心跳” 有一个大体的了解或者说设想。带着问题去寻找答案而不是漫无目的的去看。
- 每隔一段时间客户端向服务端发送一个请求,表示自己还活着
- 猜测这个“每隔一段时间” 可能用的是 while(true){},当然也可能是其他的某些定时器
- 长时间不发送心跳会被客户端踢掉,那么服务端应该有一个类似计时器的东西,由单独的某个线程持续关注着客户端最后一次发心跳的时间和当前时间的时间差。那么务必会有一段类似这样的代码: if(now-xxxx.getLastBeatTime>规定的时间差){踢掉}
客户端心跳
为了更直观的了解 客户端的注册流程,我这里就没有使用 spring-boot-starter的方式去集成,而是直接写的注册代码
public class NacosClientDemo {public static void main(String[] args) throws NacosException, InterruptedException {// 1. 配置Nacos服务端地址和认证信息Properties properties = new Properties();// 本地Nacos服务端地址(默认端口8848)properties.setProperty("serverAddr", "localhost:8848");// 命名空间(默认public,注意:如果是自定义命名空间,需要填写命名空间ID而非名称)properties.setProperty("namespace", "public");// 账号密码(Nacos服务端开启认证时必须配置)properties.setProperty("username", "nacos");properties.setProperty("password", "nacos");// 2. 创建NamingService实例(客户端核心入口)NamingService namingService = NacosFactory.createNamingService(properties);// 3. 注册一个服务实例到Nacos服务端String serviceName = "service_"+ LocalDateTime.now(); // 服务名String ip = "127.0.0.1"; // 实例IP(可替换为实际服务IP)int port = 8080; // 实例端口(可替换为实际服务端口)namingService.registerInstance(serviceName, ip, port);System.out.println("服务实例注册成功:" + serviceName + "(" + ip + ":" + port + ")");// 4. 监听服务变化(可选,用于验证客户端是否正常接收服务端推送)namingService.subscribe(serviceName, event -> {if (event instanceof NamingEvent) {System.out.println("\n服务实例列表更新:" + ((NamingEvent) event).getInstances());}});// 5. 保持客户端运行,持续发送心跳(默认每5秒一次)System.out.println("\n客户端已启动,持续发送心跳中...(按Ctrl+C退出)");TimeUnit.HOURS.sleep(1); // 阻塞1小时,实际项目中可替换为服务自身的运行逻辑}
}
其实可以看到,重要的代码就两句
- NamingService namingService = NacosFactory.createNamingService(properties);
- namingService.registerInstance(serviceName, ip, port);
我们一个一个来看
NamingService namingService = NacosFactory.createNamingService(properties);
一步一步点进去
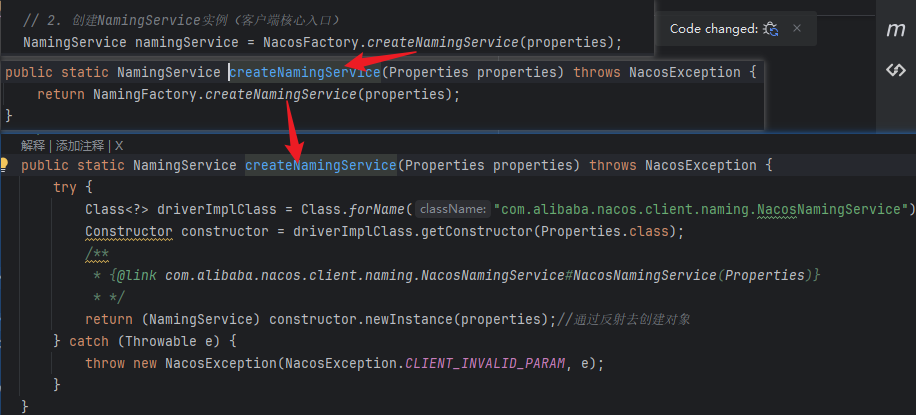
看到是通过反射去创建对象,那么创建的是谁我这里也标注出来
com.alibaba.nacos.client.naming.NacosNamingService#NacosNamingService(Properties)
走的是这个构造方法
ok,那我们就去看这个构造方法
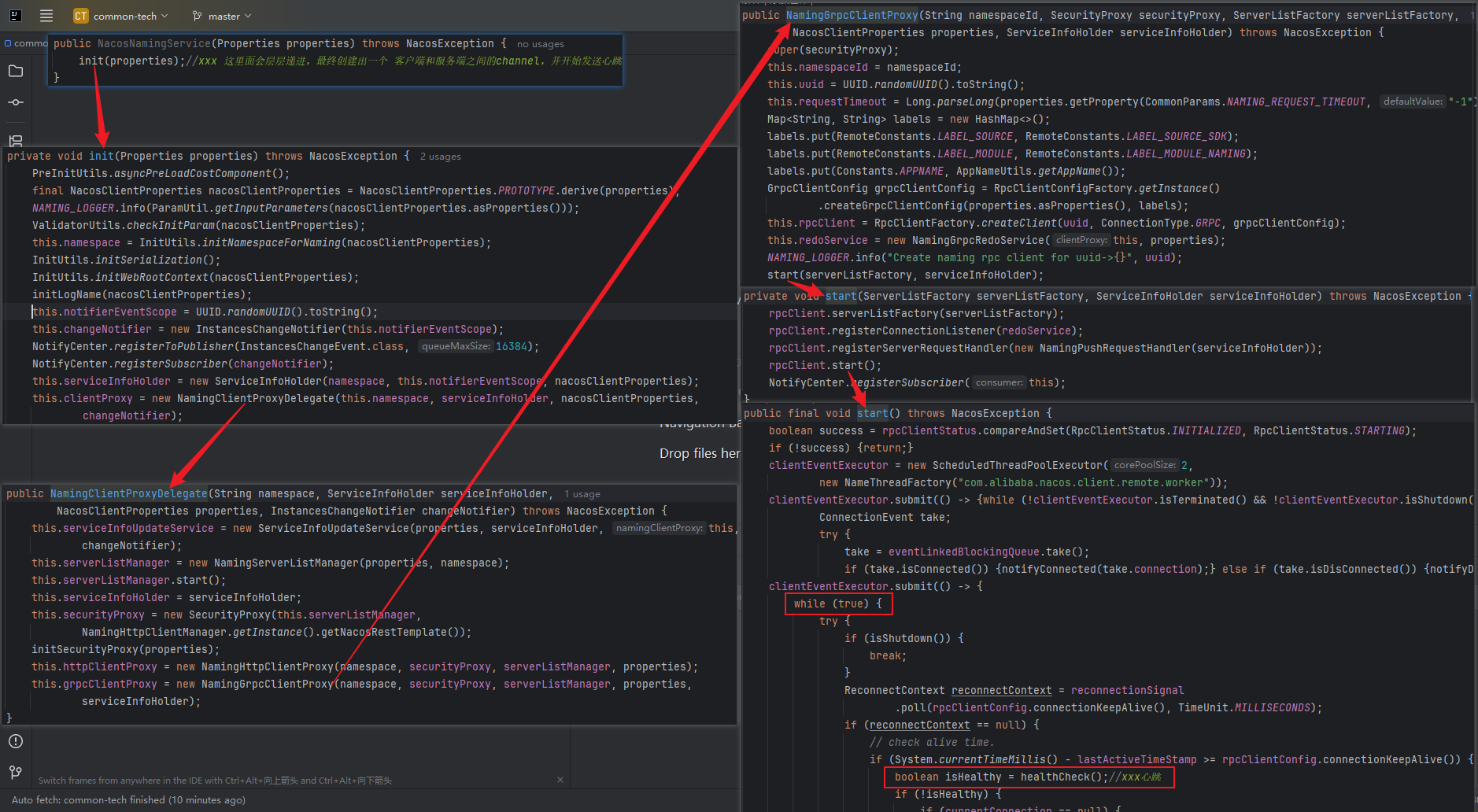
在进一步看看
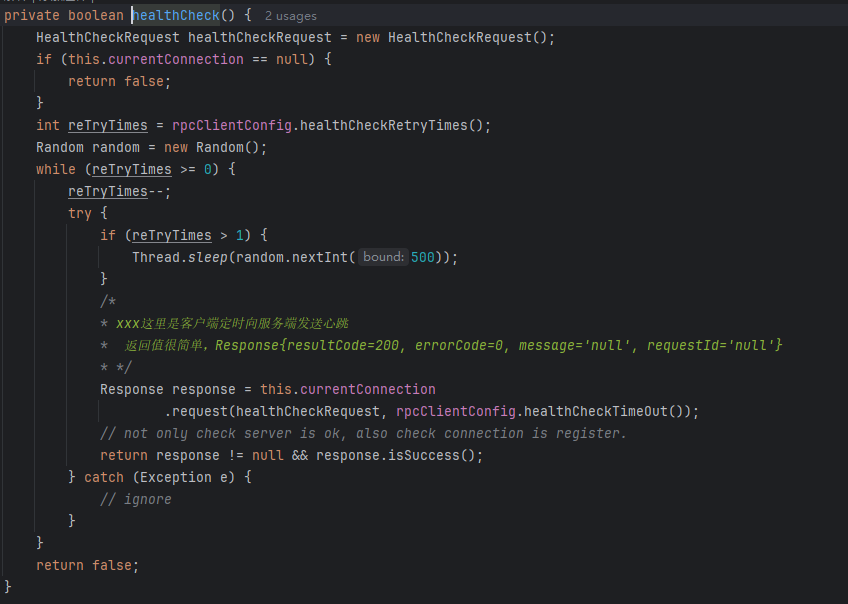
namingService.registerInstance(serviceName, ip, port);

👇

👇

👇
👇

👇
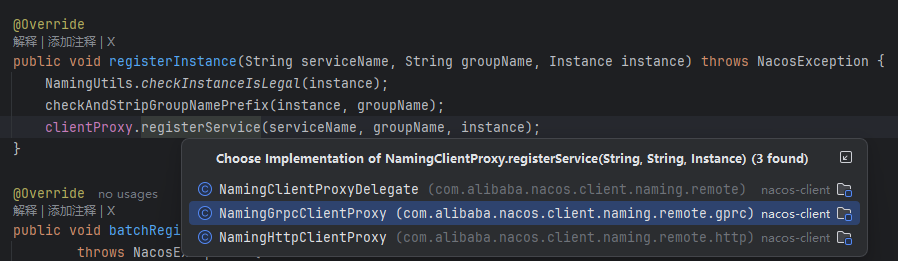
👇
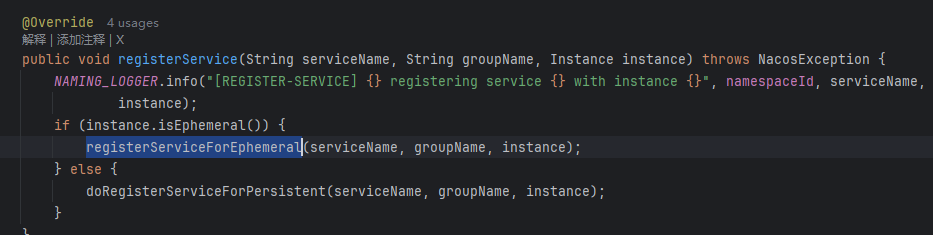
👇

👇

👇
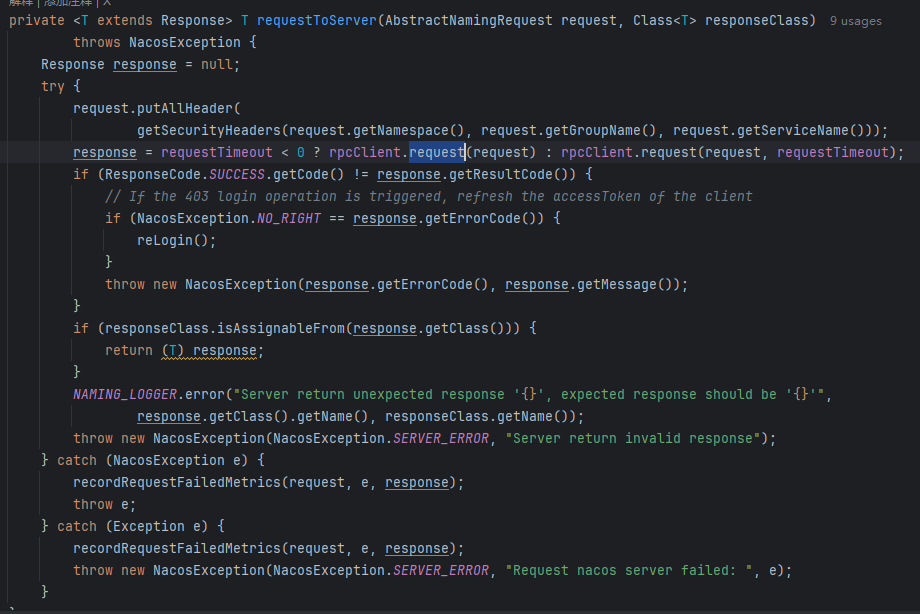
👇

👇
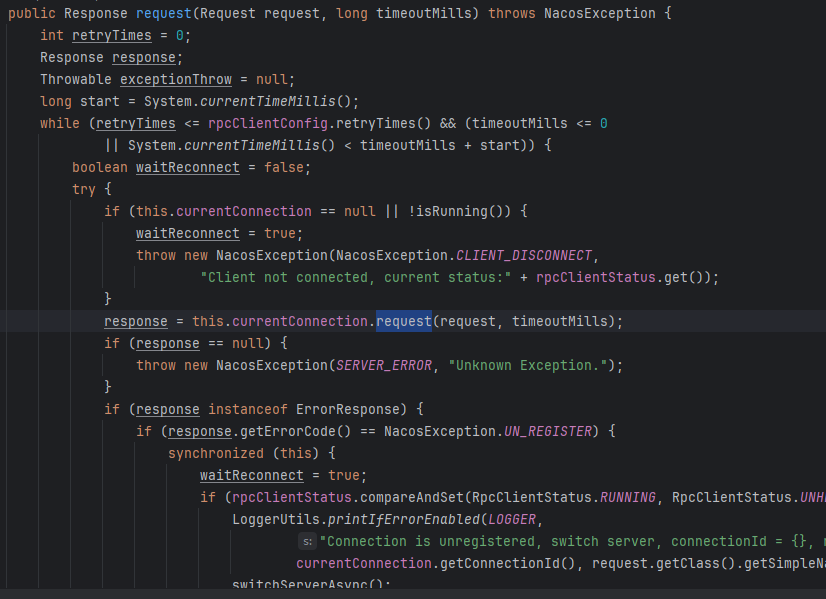
👇
👇

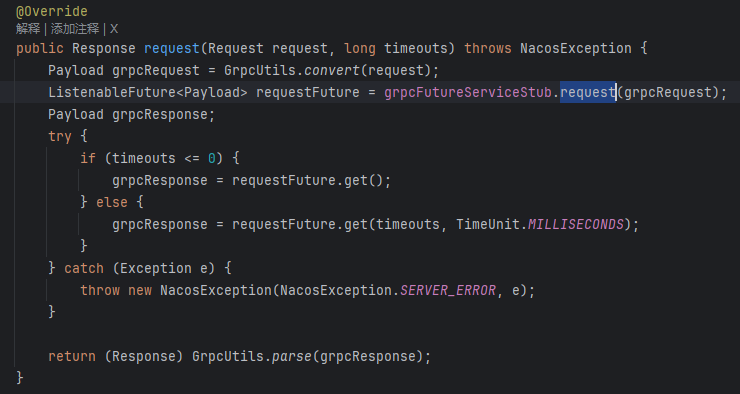
到这里,才是真的去发送 注册请求(真深啊)
这里有一点需要注意,一般 http 请求生活中见多了,通过 url 就能找到对应的接口方法,但是我们也说了 nacos 2.x 版本用的是 grpc,所以不像 url 那样那么直接,有兴趣的可以自己了解了解在 grpc 中是如何确定请求的是哪个方法的
服务端处理注册和心跳
ok,上文说了客户端是在哪里发送的注册和心跳,那么客户端是如何处理的?
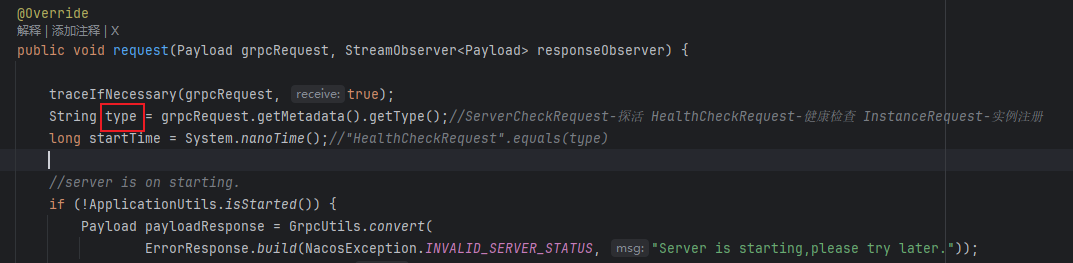
首先定位到 GrpcRequestAcceptor.request 方法,这个方法是 grpc 通信的核心方法
该方法是一个统一入口,就是说不论是心跳还是注册,都走这个方法,通过type进行区分
处理注册
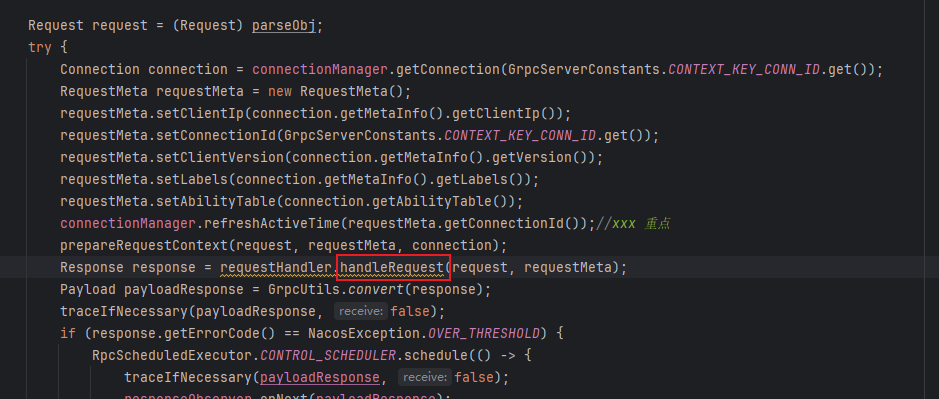
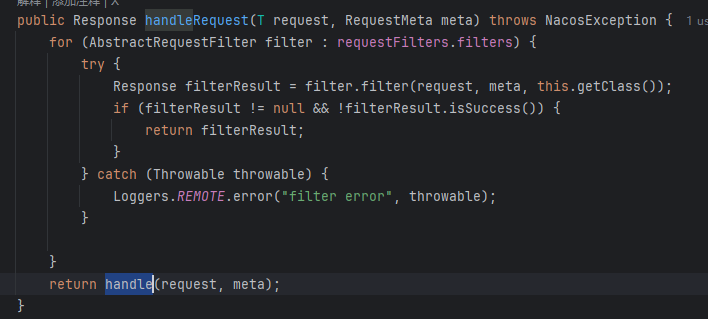
当请求是注册请求的时候,我们找到这里
👇
👇
👇
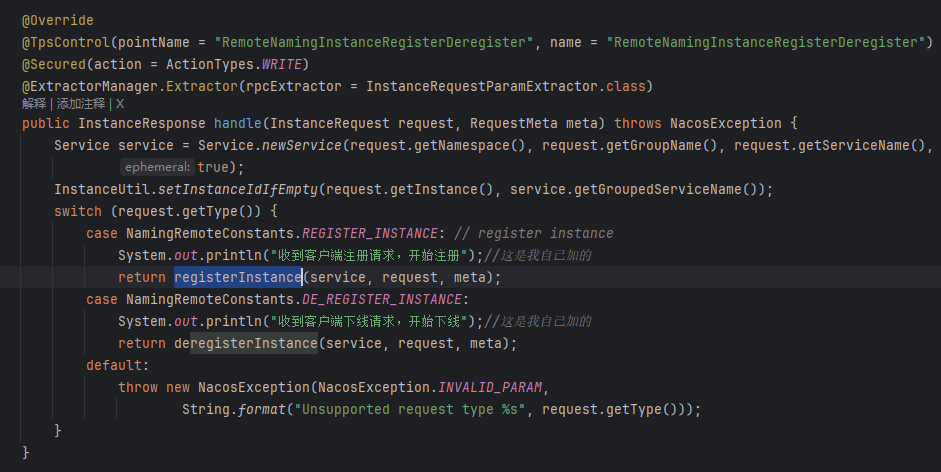
👇
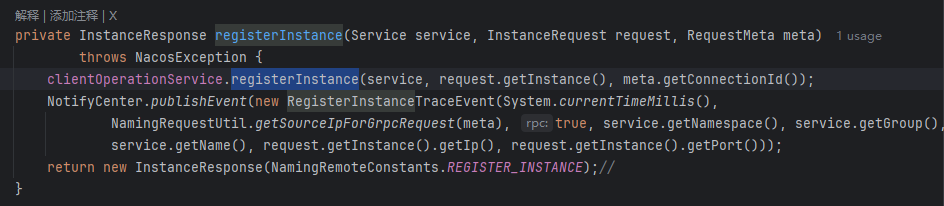
👇
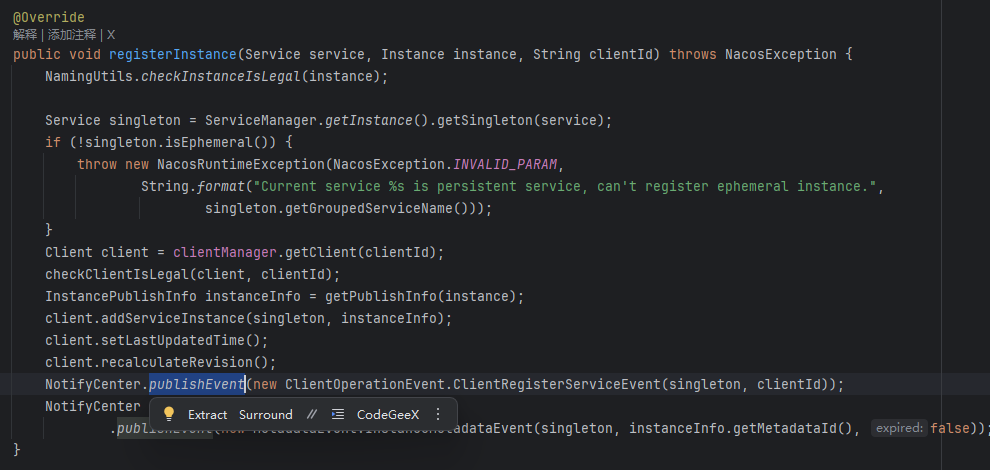
到了这里,我们会发现,这里其实并没有我们想象的,往 某个数据结构中存些什么,反而是发布了一个事件。
这就是 nacos 2和1之间的另外一个重要区别,事件驱动
那么谁来消费这个事件呢?我们定位到
ClientServiceIndexesManager.handleClientOperation 方法
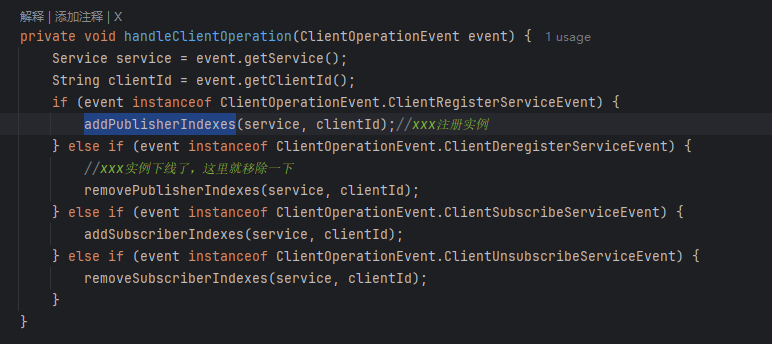
👇

至此,注册结束,实际上注册并不难,就是 put 一下,然后发布各种事件。当然这些事件包括:通知其他客户端更新实例列表等等
处理心跳
依旧是回到这里
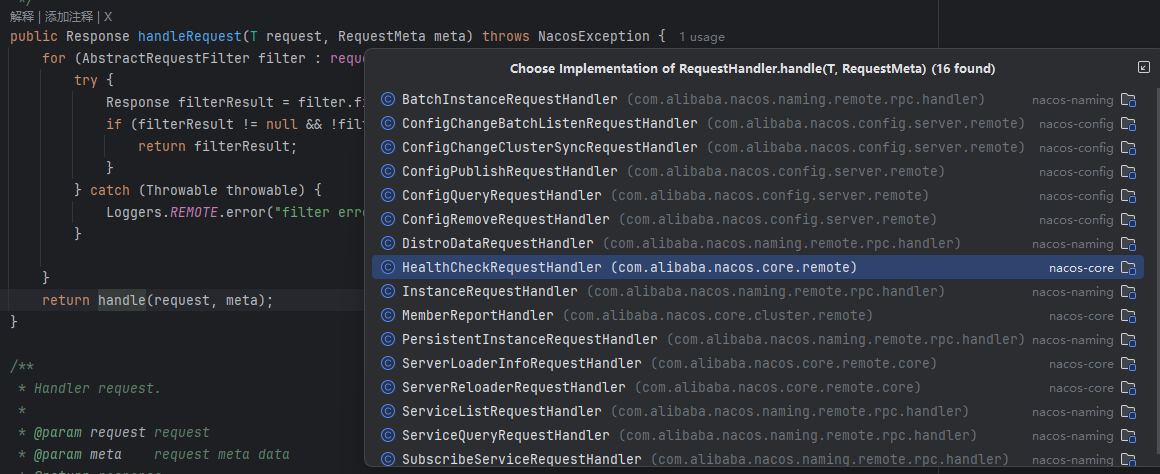
只不过这次我们要看的是 HealthCheckRequestHandler
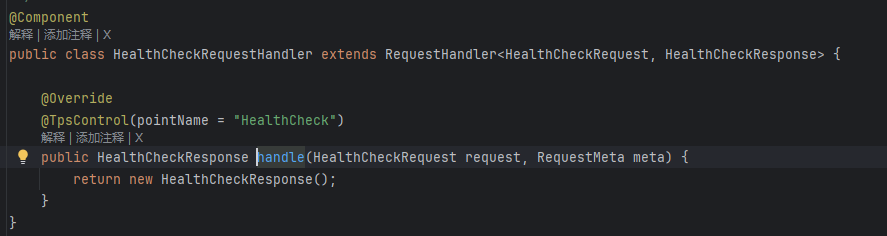
👇
什么也没干
ok,至此心跳也完成了。但是别急,我知道还有很多疑问,我们一个一个来看。
为什么心跳机制如此简单,就回复一个 code=200 就够了,不去刷新一下 lastBeatTime 么?
其实已经刷新了,只不过不在 HealthCheckRequestHandler 里面,而是在统一入口里面:
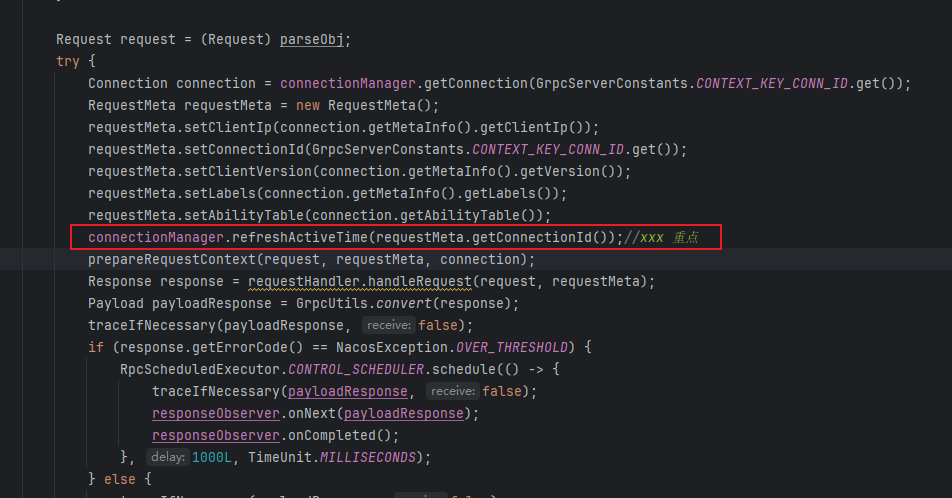
在真正的 handleRequest 之前,已经刷新了,而且在 nacos2里面不叫 lastBeatTime,叫做 lastActiveTime
假如客户端挂了,服务端如何感知到?
这就要分情况了,如果客户端是正常关闭,那么在关闭之前, grpc 其实是会发送一个“我要下线了”的请求的,服务端收到这个请求后去处理下线逻辑即可,代码和 注册 在同一个位置
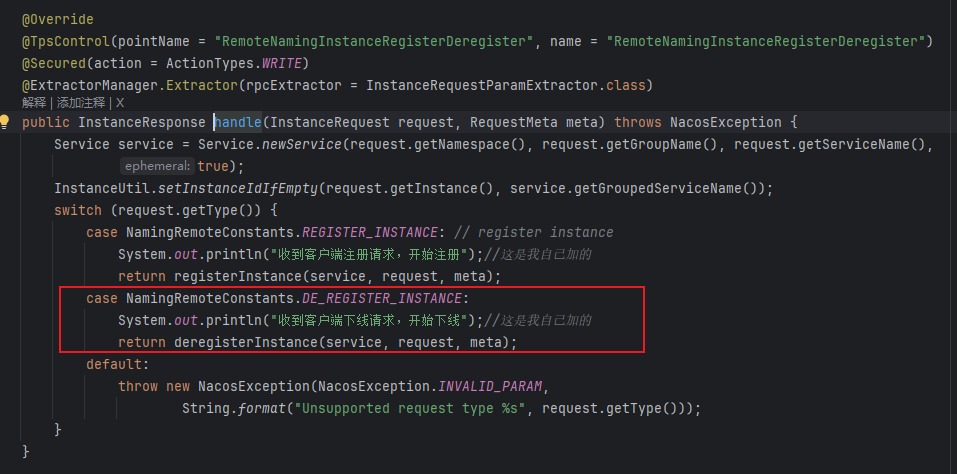
如果是 kill-9 这种结束进程的方式来下线客户端,也就是说,客户端下线前没有发送 “我要下线了”的请求,服务端如何将客户端踢掉?
那么这个时候 LastActiveTime 就开始起作用了:
我们定位到 ConnectionManager.start 方法
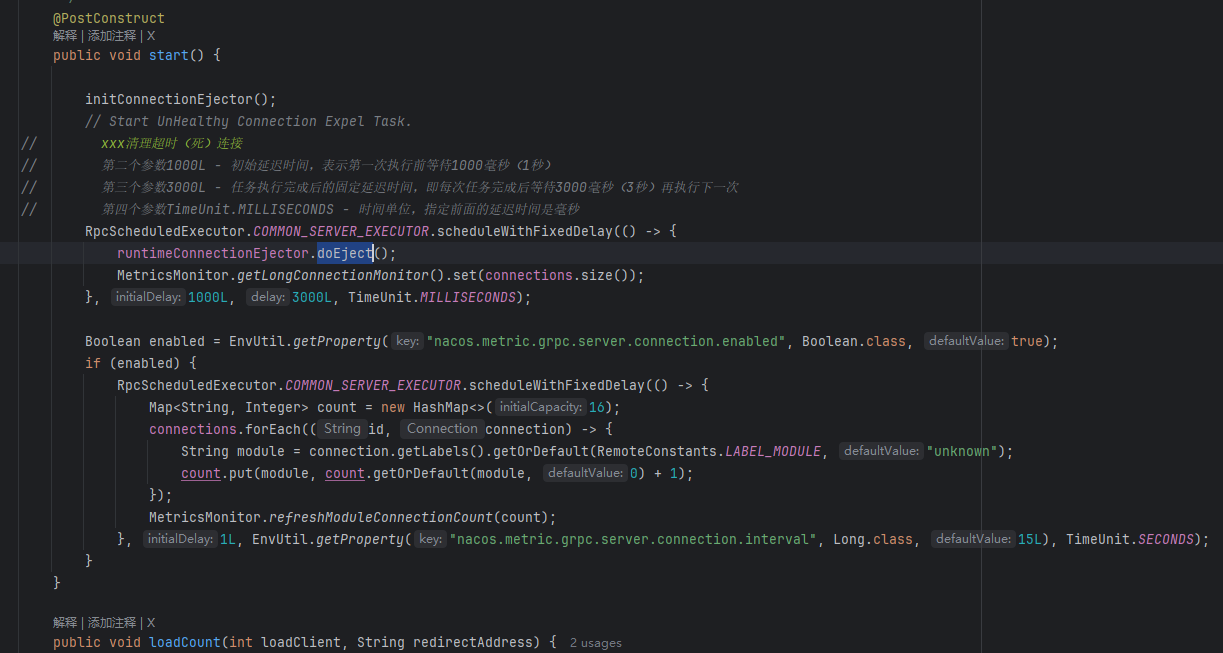
看到了 @PostConstruct 和
RpcScheduledExecutor.COMMON_SERVER_EXECUTOR.scheduleWithFixedDelay(() -> {runtimeConnectionEjector.doEject();MetricsMonitor.getLongConnectionMonitor().set(connections.size());}, 1000L, 3000L, TimeUnit.MILLISECONDS);
这段代码,应该就明白了吧,不明白的话我们继续看
👇
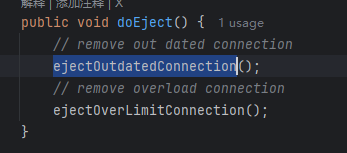
👇
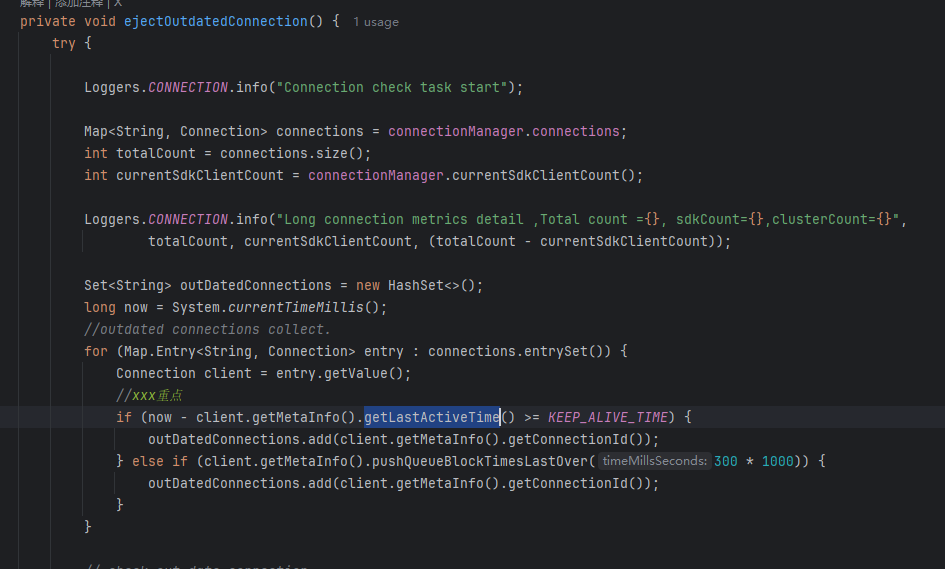
这里就出现了我们最开始的想法:
有一个定时任务,去比较 if(now-xxxx.getLastBeatTime>规定的时间差){踢掉} 的想法
ok,下面更是重点中的重点
如果此时我说,在 grpc 中,通信的双方其实是可以感知到对方是否还在线的,你是否有更多的疑问?
既然客户端和服务端能够感知到对方的状态,还要心跳干嘛?
如果想到了这个问题,那么恭喜,你已经触及了网络通信和健康检查设计的核心矛盾。
答案是:TCP/IP 协议栈并不能在所有情况下都“立即”可靠地通知应用程序连接已断开。
这就是为什么我们还需要应用层心跳。具体来说,网络故障分为几种情况,心跳就是为了解决其中一种最“狡猾”的情况:
情况一:连接正常断开(如进程杀死、机器重启)
- 现象:客户端进程消失,操作系统会发送 FIN 包来正常关闭 TCP 连接。
- 服务端感知:是的,服务端几乎能立即感知到。gRPC 底层会收到连接关闭的通知,从而立刻触发回调函数,标记该实例下线。在这种情况下,确实不需要等待心跳。
情况二:网络物理中断(如网线被拔、Wi-Fi断开)
- 现象:客户端和服务端之间的物理路径完全不通。
- 服务端感知:TCP 有重传机制,不能立即感知。当服务端尝试发送数据时,数据包会失败,TCP 会进行多次重试,这个过程可能会持续几分钟(取决于系统配置),最终才会放弃并通知应用程序连接已断开。这个过程太慢了。
情况三:“哑巴”连接(或称“半连接”、“僵尸连接”)【这是心跳要解决的核心问题!】
- 现象:这是最棘手的情况。物理连接是通的,但客户端应用已经死了(例如,虚拟机假死、操作系统卡死、进程被
kill -9强杀未来得及发FIN包、机器断电)。 - 服务端感知:服务端完全无法感知! 从 TCP 协议层的角度看,这个四元组(源IP、源端口、目标IP、目标端口)的连接依然好好地存在着。因为没有数据包交换,所以网络设备不会把它踢掉。服务端会一直以为这个连接是健康的,但实际上后面的客户端早已“魂飞魄散”。
- 解决方案:这就是应用层心跳的使命。服务端有一个逻辑:“如果我超过15秒(3个心跳间隔)既没有收到客户端发来的任何消息,也没有收到它对我
HealthCheckRequest的回复,那么我就有理由认为,尽管TCP连接可能还在,但客户端应用已经死了,我要把这个实例标记为下线。”
总结与类比
可以把 gRPC 长连接想象成一条电话线:
- 正常挂断(情况一):对方说“再见”然后挂机。你立刻知道通话结束了。
- 线路被剪断(情况二):你听到忙音或噪音,需要一点时间确认对方不在。
- 对方突然昏迷(情况三):电话通着,但对方一直不说话。你怎么知道他还在不在?
- 你的做法就是:每隔几秒问一句“喂,你还在吗?”(这就是
ClientDetectionRequest/HealthCheckRequest)。 - 如果连续问了几次都没回应,你就断定他出事了,然后挂断电话(将实例标记为不健康)。
- 你的做法就是:每隔几秒问一句“喂,你还在吗?”(这就是
所以,结论是:
- 通道状态检测:用于快速处理正常关闭(情况一)。
- 应用层心跳:用于检测网络中断(情况二)和最重要的**“哑巴”连接**(情况三)。
两者是互补关系,而不是重复劳动。心跳是建立在长连接之上的、必不可少的应用层健康探测协议,它弥补了底层TCP协议无法感知对端应用状态的缺陷。这就是为什么在有了长连接之后,仍然需要心跳机制的原因。
就按照正常的关闭来说,既然 channel 能感知到对方的线下,为什么客户端还要在下线前主动的发送信息告诉服务端,直接下线就好了,反正服务端能感知到
之前我们说道:“通过Channel状态感知下线”是gRPC长连接模式下的一种理论上的能力和兜底机制。而“客户端主动发送下线请求”是Nacos选择的主动优化策略。
这两者并不矛盾,而是协同工作的。
为什么选择“主动通知”而非“依赖Channel断开”?
尽管gRPC Channel能感知断开,但依赖它作为主要的下线通知方式有几个缺点,而主动通知则完美规避了它们:
| 方面 | 依赖Channel断开 (被动感知) | 客户端主动通知 (Nacos采用的方式) |
|---|---|---|
| 速度 | 相对慢。即便正常关闭,FIN包的传输、协议栈的处理、回调的触发也需要一个微小的过程。 | 极快。客户端决定下线的瞬间,消息就已经组装好并准备发送。这是应用层的立即通知。 |
| 可靠性 | 不可靠。如果客户端进程被kill -9强杀或机器断电,根本无法发送FIN包,只能依赖心跳超时,发现延迟很高(~15秒)。 | 可靠。只要网络在断开的瞬间还通,就能把请求发出去。这是优雅关闭流程的一部分。 |
| 控制力 | 无控制力。服务端只能知道“连接断了”,但不知道为什么断了。是正常下线?是网络故障?还是客户端崩溃? | 有控制力。客户端可以明确地告诉服务端:“我是主动下线(instance.setEphemeral(false))”,服务端可以立即、无误地清理实例,无需任何等待。 |
| 数据完整性 | 只能清理。服务端仅仅能执行删除操作。 | 可以完成更多逻辑。一次主动请求可以成为一个完整的事务,除了删除实例,还可能包含日志记录、通知其他组件等。 |
那么,“Channel状态感知”还用吗?什么时候用?
它的主要作用不再是处理正常下线,而是处理异常情况:
- 客户端非正常下线:也就是之前提到的“哑巴”连接场景。客户端进程突然崩溃(
kill -9)、机器断电、网络完全中断。在这种情况下,客户端根本没有机会发送那个“主动下线”的请求。 - 此时,服务端怎么办?
- 它还在维护着那个gRPC连接,但对方已经“死”了。
- 服务端会同时启动两套检测机制:
- 机制A(应用层心跳):服务端发现,既收不到客户端的
ClientDetectionRequest,客户端也不回复自己的HealthCheckRequest。 - 机制B(连接状态检测):操作系统/Netty最终(可能在多次重试后)会报告这个TCP连接已经失效。
- 机制A(应用层心跳):服务端发现,既收不到客户端的
- 无论哪个机制先触发,都会通知到
ConnectionManager,然后执行我们之前讨论过的清理流程:查找该连接关联的所有实例,并将它们强制删除。
总结
对于正常下线,Nacos客户端选择了效率更高、更可靠的主动通知模式。 而服务端对Channel状态的监听,是一张为了处理各种意外状况而准备的、必不可少的安全网。