MinerU本地化部署
github:https://github.com/opendatalab/MinerU
官网:MinerU
是什么?
MinerU 专注于高效解析和提取复杂的 PDF 文档、网页和电子书,并将其转换为易于分析的 Markdown 或 JSON 格式。由 上海人工智能实验室OpenDataLab 团队 开发。
主要功能包括
• PDF 转 Markdown
支持多模态 PDF(含图片、表格、公式等)的结构化转换。 自动去除页眉、页脚、脚注等干扰信息,保留标题、段落、列表等结构。 公式识别并转换为 LaTeX 格式,表格转换为 HTML 或 Markdown。
• 网页内容提取:从网页中剔除广告等干扰信息,精准提取正文、评论、视频文字等内容。
• 电子书转换:支持epub、mobi、docx、pptx、chm、azw等格式批量转Markdown。
• 多语言OCR:自动检测扫描版PDF和乱码,支持84种语言的OCR识别
核心技术
-
布局检测:基于LayoutLMv3微调,识别文本、表格、图片等区域。
-
公式识别:使用YOLOv8检测公式,UniMERNet模型转换LaTeX。
-
OCR 增强:采用 PaddleOCR 提高文本识别准确率
应用场景
-
大模型训练:为书生·浦语等模型提供高质量语料。
-
学术研究:提取论文、教材中的关键信息。
-
法律与金融:解析合同、研报等结构化数据。
MinerU使用
在线使用
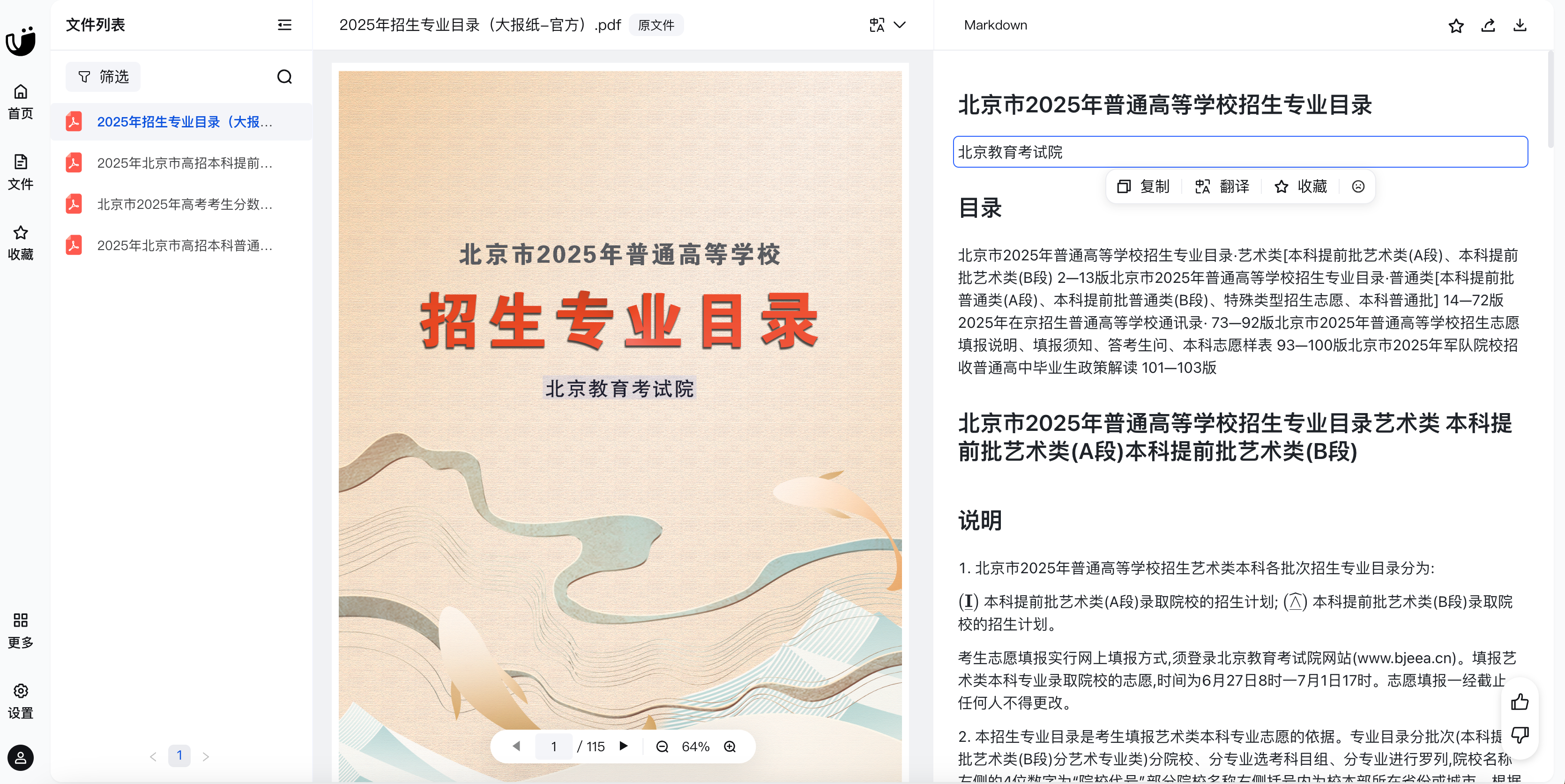
链接为:https://mineru.net/OpenSourceTools/Extractor,把相应的文件拖到下面的框中,就能解析。

例如把《2025年招生专业目录(大报纸-官方).pdf》传到MinerU中,就能解析成功,如下图所示:
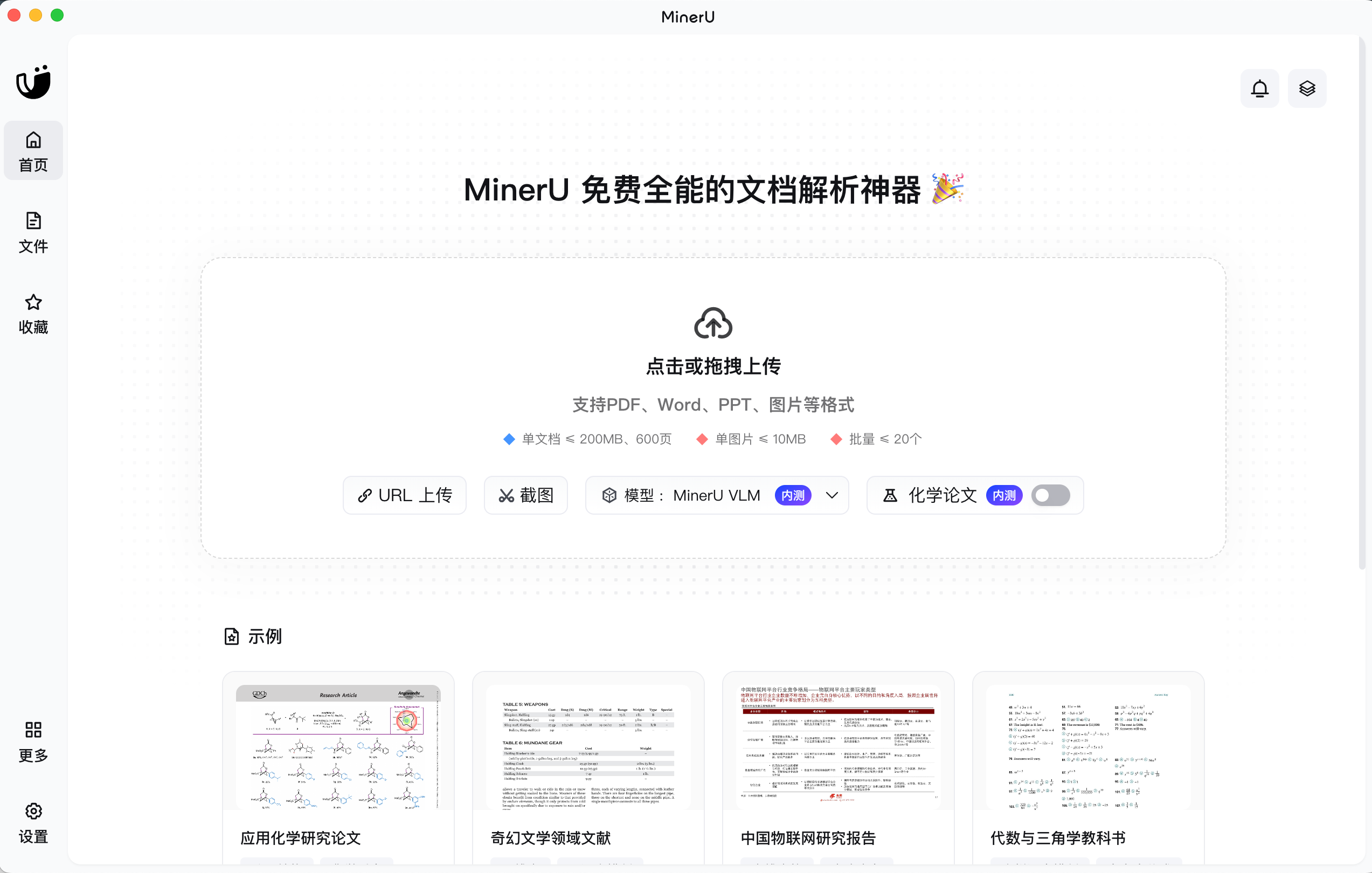
客户端
链接:https://mineru.net/client
下载之后 ,安装,就能在本地进行解析文档了
API
链接:https://mineru.net/apiManage
1、申请API TOKEN
2、代码
通过API(https://mineru.net/api/v4/extract/task),提交PDF,获取task_id
import requeststoken = "官网申请的api token"
url = "https://mineru.net/api/v4/extract/task"
header = {"Content-Type": "application/json","Authorization": f"Bearer {token}"
}
data = {"url": "https://cdn-mineru.openxlab.org.cn/demo/example.pdf","is_ocr": True,"enable_formula": False,
}res = requests.post(url,headers=header,json=data)
print(res.status_code)
print(res.json())
print(res.json()["data"])本地化部署
由于线上的方式,涉及到安全,所以一般公司都会私有化部署。私有化部署的方式如下:
1、pip install -U "magic-pdf[full]"
2、下载依赖的models
3、分析pdf
magic-pdf -p 三国演义.pdf -o ./output
总结
- 大的文档解析能力
多格式支持:支持PDF、PPT、DOCX、EPUB、MOBI 复杂布局处理:精准识别单栏、多栏、跨页排版,并按照人类阅读顺序输出文本 多模态提取:提取文本、图片、表格、公式、页眉、页脚、脚注等元素,并智能去除无关内容(如广告、页码)。
- 智能转换与结构化输出
Markdown/JSON输出:支持将PDF转换为机器可读的Markdown或JSON格式,保留标题、段落、列表等原始结构。 公式与表格处理:自动识别数学公式并转换为LaTeX格式,表格可转换为HTML或LaTeX格式。 OCR多语言支持:内置OCR功能,支持84种语言(包括繁简中文),可自动检测扫描版PDF并启用OCR。
- 高性能与优化 硬件加速:
支持CPU、GPU(CUDA)、NPU(华为Ascend)加速,优化显存使用(最低8GB显存需求)。 模型升级:集成先进模型(如LayoutLMv3、YOLOv8、UniMERNet),提升布局检测、公式识别和表格解析速度。 批量处理:支持多文件批量上传和自动化处理,适合大规模文档解析任务。