Science:机器学习模型进行遗传变异外显率预测
模型代码已公开:https://data.mendeley.com/datasets/p47ws8kn36/1
研究聚焦的是遗传变异外显率的精准评估——即携带某一基因变异的个体实际发病的概率。传统方法多依赖于疾病高发家系或病例队列,但样本量小且存在选择偏倚,同时“病例-对照”式的二元分类也难以反映疾病的连续谱特征。为此,研究团队提出利用机器学习,将大规模电子健康记录(EHR)与基因数据结合,构建可扩展、数据驱动且精确的外显率预测模型。
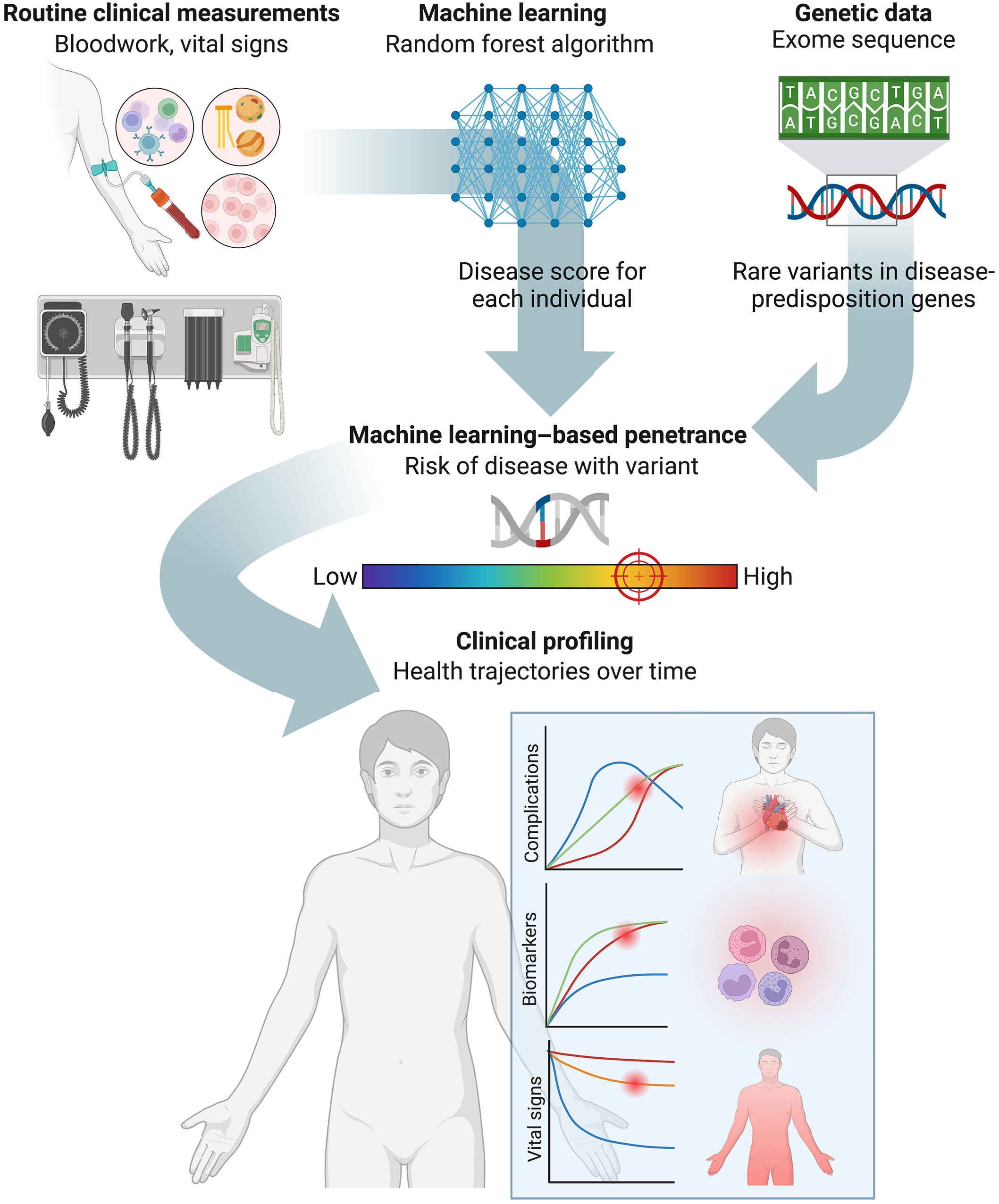
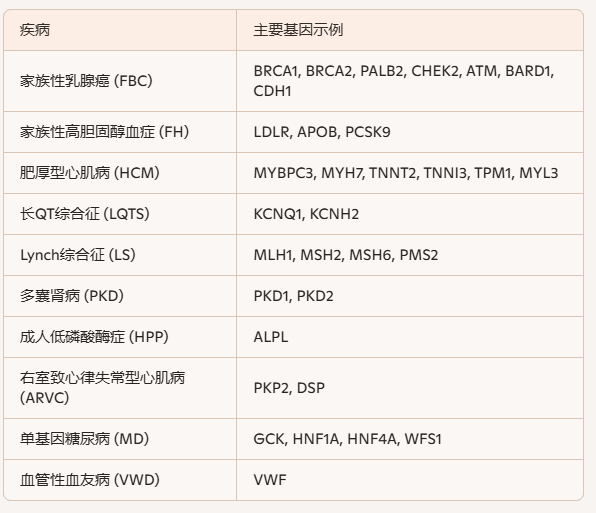
研究人员基于 1,347,298 名参与者的 EHR 数据,针对 10 种遗传性疾病(如家族性乳腺癌、家族性高胆固醇血症、肥厚型心肌病、多囊肾病等)建立了机器学习模型,并在独立的外显组测序队列中验证。模型生成的疾病概率分数与基因型信息结合后,计算出 31 个常染色体显性疾病易感基因中 1648 个罕见变异的外显率,涵盖致病性(P)、良性(B)、意义不明(VUS)及新发现的功能缺失(LoF)变异。
研究尝试了多种算法,最终选择 极端梯度提升树(Extreme Gradient Boosted Trees, XGBoost) 作为主模型,因为它在内部验证和独立测试集中的 AUROC、Brier分数 等指标表现最佳。模型输入为连续型临床数据(实验室检查、生命体征)+ 人口学信息(年龄、性别等)。不使用诊断编码等容易引入偏倚的特征。使用 Shapley Additive Explanations (SHAP) 分析特征重要性,解释模型决策。
不同疾病的模型使用的关键特征各不相同,但都来自 常规体检和化验项目:
- 血脂指标:低密度脂蛋白胆固醇(LDL-C)、总胆固醇(TC)、高密度脂蛋白胆固醇(HDL-C) → 对 FH 模型最重要
- 血糖与代谢:空腹血糖、体质指数(BMI) → 对 MD 模型最重要
- 肾功能:肾小球滤过率(GFR)、血肌酐 → 对 PKD 模型重要
- 心脏功能:心率、心电图参数(QT间期、PR间期等) → 对 HCM、LQTS 模型重要
- 血液学指标:血红蛋白(Hb)、血细胞计数 → 对多种疾病有贡献
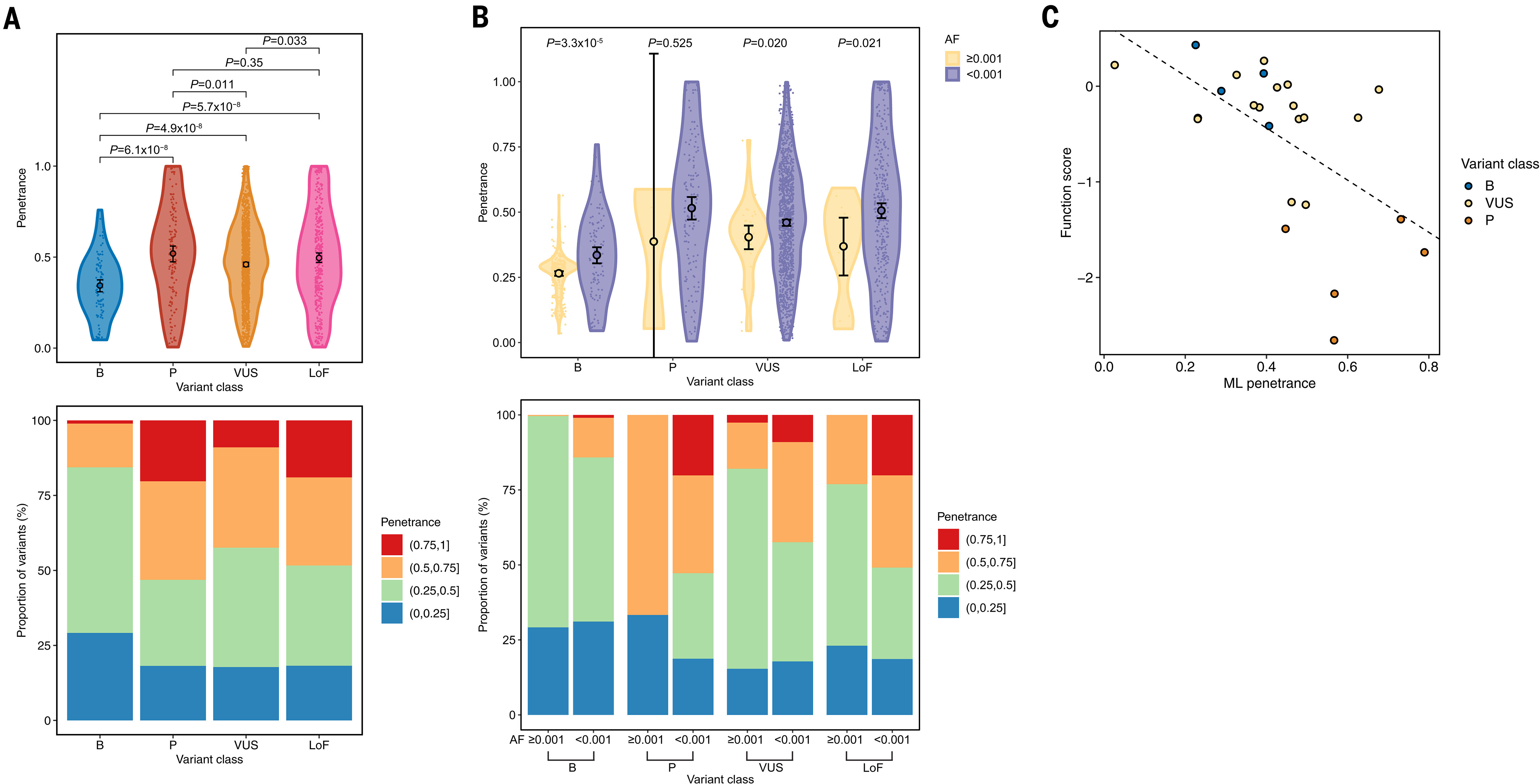
结果显示,P 和 LoF 变异的外显率最高,其次是 VUS,良性B 变异最低。这些外显率与疾病相关的临床结局高度相关,例如高外显率的家族性高胆固醇血症变异携带者 LDL-C 水平高出 119 mg/dl,高外显率的多囊肾病变异携带者肾小球滤过率低 40 ml/min。此外,外显率还与实验室功能测定结果一致,证明其生物学有效性,并能帮助评估 VUS 和新 LoF 变异的临床风险轨迹。
研究结论认为,这一机器学习框架为大规模系统性评估遗传变异外显率提供了蓝图。通过整合基因组与临床表型数据,它不仅能提供更精细、个体化的疾病风险估计,还可改进变异解读、指导临床决策,并推动精准医学的发展。

研究使用的是BioMe Biobank和UKB的数据集,UKB的数据集大家比较熟悉啦,BioMe Biobank是BioMe 由查尔斯·布朗夫曼个性化医学研究所资助的一个与病历相关的电子生物样本库,使研究人员能够快速有效地对与医学信息相关的大量研究标本进行遗传、流行病学、分子和基因组研究。其是纽约市唯一一家与 EHR 相关的生物和数据存储库,可进行不受限制的患者入组(在性别、种族、民族、年龄、医疗状况或疾病状态方面不具有选择性),从而形成一个在种族、社会经济和医学多样性方面无与伦比的队列,并准备好用于尽可能广泛的生物医学和基因研究。
参考文献:
- Iain S. Forrest et al. ,Machine learning–based penetrance of genetic variants. Science389, eadm7066(2025). DOI:10.1126/science.adm7066
- https://icahn.mssm.edu/research/ipm/programs/biome-biobank