【自然语言处理与大模型】多机多卡分布式微调训练的有哪些方式
一、分布式微调训练的有哪些方式?
多机多卡微调是指利用分布式训练框架,将模型、数据和计算任务分配到多个GPU节点上并行执行。其核心并行模式包括:
数据并行(Data Parallel, DP):将训练数据分块分发到不同GPU,解决批量过大的问题。(分数据,存全模型,同步梯度)
模型并行(Model Parallel, MP):将模型的不同层或权重切分到不同GPU,应对模型参数量过大的情况。(分模型,不同GPU放模型的不同部分)
张量并行(Tensor Parallel, TP):是一种将神经网络中的张量运算在多个设备(如GPU)之间进行水平分割的并行计算技术。(分层内,把大权重矩阵拆开计算)
流水线并行(Pipeline Parallel, PP):将神经网络模型按层或阶段分割到多个设备上,通过流水线化的方式执行前向和反向传播,以提高计算资源的利用率。(分阶段,像流水线一样按层分段处理数据)
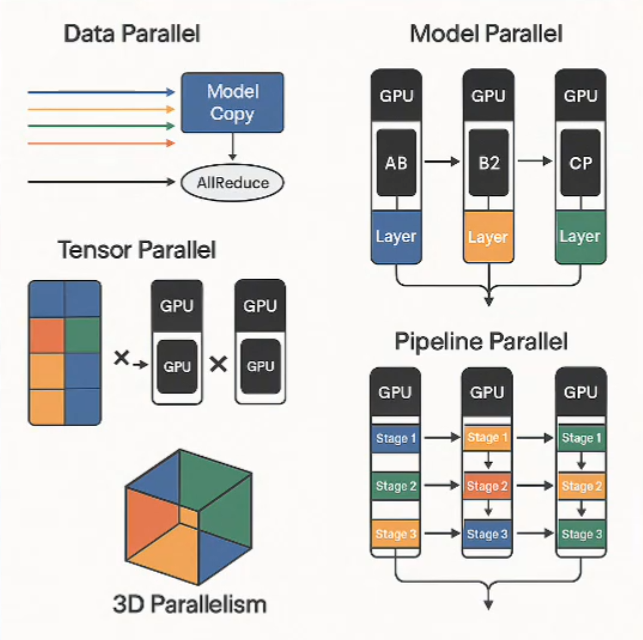
实际应用中,通常需要采用混合并行策略来突破单一模式的限制。例如:当单卡显存不足时,可先使用张量并行切分模型权重,再叠加数据并行保证吞吐量(如Megatron-LM的典型做法)对于更大规模的训练,可结合流水线并行,将不同网络层分布到不同GPU节点上,形成3D并行方案这种3D并行已成为当代大模型训练的标准配置。
要实现稳定高效的多机多卡微调,关键在于合理选择并行策略并深入理解底层通信与调度机制。当前行业普遍采用基于NCCL通信库和高性能互联网络的分布式集群方案,通过PyTorch Distributed、DeepSpeed或Megatron-LM等框架实现自动化调度和梯度同步功能。此外,工程实践中还需重点考虑容错机制、断点续训能力以及混合精度(FP16/BF16)优化等关键因素。
二、工程实践中通信带宽不足对分布式训练的影响?
在多机多卡微调场景下,通信带宽不足是最常见的性能瓶颈之一,主要表现为:梯度同步延迟明显、训练吞吐率下降以及GPU利用率偏低。在跨节点训练时,若仅使用万兆以太网而非InfiniBand或NVLink等高速互联技术,通信耗时可能占据总训练时长的50%以上,这会显著降低系统的扩展效率。
三、如何有效处理多机多卡训练中的单节点故障?
在多机多卡训练场景下,单节点故障可能导致整个训练过程中断,严重影响训练效率。目前主要有两种解决方案:
- 断点续训机制:通过定期保存模型检查点(checkpoint),在节点恢复或替换后能够快速恢复训练进度
- 分布式容错机制:部分主流框架(如DeepSpeed、Horovod)内置了自动容错功能,可在检测到节点故障时自动进行重试或动态调整并行策略
四、在多机多卡微调场景中,ZeRO优化器发挥着什么作用?
作为微软DeepSpeed框架中的核心技术,ZeRO(Zero Redundancy Optimizer,零冗余优化器)通过创新的参数存储方式实现了显著的内存优化。其核心原理是将模型参数(Parameters)、梯度(Gradients)和优化器状态(Optimizer States)分片存储于不同GPU,而非传统方式中每张GPU保存完整副本。这种设计使得单卡内存压力大幅降低,在同等硬件条件下可支持更大规模的模型训练,某些情况下甚至能将内存占用减少至1/8以下。正因如此,ZeRO已成为大模型分布式微调场景中的标配优化方案。