用户态网络缓冲区设计
目录
一、用户态缓冲区的由来
(1)生产者消费者模型
(2)协议粘包问题
二、定长缓冲区
三、环形缓冲区
四、链式缓冲区
五、缓冲区的选取建议
1. 简单应用:选择定长缓冲区,实现简单,易于调试
2. 高性能服务器:选择环形缓冲区,减少内存拷贝,提高效率
3. 大数据传输:选择链式缓冲区,灵活应对数据量变化
4. 多线程环境:确保缓冲区实现线程安全,优先选择无锁设计或轻量级锁
六、不同的协议对用户态缓冲区设计的影响
(1)TCP与UDP
在Linux网络通信中,我们使用recv、send等函数的时候会填入一个参数---缓冲区buf,这个是让内核可以把数据从sock结构体中的sk_buff拿出来,拷贝到用户态供上层应用使用。在早期,我们都是使用vector这种简单的容器来测试的,但是随着网络通信场景逐渐复杂,实际生产中并不是简单的使用vector,而会根据不同场景定制合适的缓冲区。本篇文章介绍了常见的3种。
一、用户态缓冲区的由来
(1)生产者消费者模型
网络通信的read和write线程构成了典型的生产、消费模型。网卡作为生产者持续接收网络数据,并通过协议栈写入sock缓冲区中;而应用程序作为消费者从sk_buff中拿数据进行处理,但是两者的速度往往不匹配。
若读缓冲区较小,当应用程序消费的速度慢于生产速度,新数据将无处存放,可能导致数据丢失或者阻塞。如果写缓冲区较小,当write的速度快于网卡发送的时候,新数据也无处存放。这两种情况都导致了网络通信的低效。
用户态缓冲区就好像一个中间仓库,暂存数据并协调平衡两者的速度差异,保证通信流畅。
(2)协议粘包问题
在UDP中一次read就是读取一个skbuff的数据,天然有着数据帧之间的区分。而在TCP协议是面向字节流的协议,可能发送方发送的多个数据包可能合并成一个大数据包到达接收方,或接收方收到的数据包不完整,这就是粘包现象。
想要处理粘包问题则需要把数据从skbuff读取出来后才方便用户程序区分。用户态缓冲区天然适合处理这类问题,且它做到了与上层应用解耦,符合程序设计逻辑。
二、定长缓冲区
设计思路:
预先分配固定大小的内存块,使用简单的数组存储数据,通过记录已使用长度管理读写操作。在这里我们直接使用了原生的数组来实现,当然使用vector则更加方便。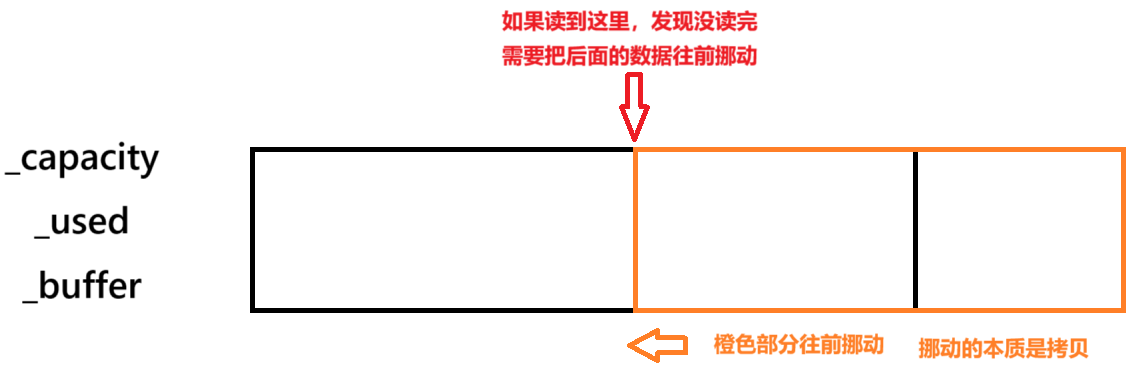
优点:
- 实现简单,内存连续,访问速度快。
- 适合初学者理解缓冲区基本原理。
缺点:
- 大小固定,难以适应数据量变化。扩容拷贝效率低。
- 读取后的数据移动操作有性能开销,效率降低。
- 高并发场景下内存利用率低。
class FixedBuffer
{
private:char* _buffer;size_t _capacity;size_t _used;public://构造函数FixedBuffer(size_t capacity):_capacity(capacity),_used(0){_buffer = new char[capacity];if (_buffer==nullptr){std::cout << "创建buffer失败" << std::endl;throw std::bad_alloc();}}//析构函数~FixedBuffer(){_capacity = _used = 0;delete[] _buffer;}//禁止拷贝构造和赋值运算符重载FixedBuffer(const FixedBuffer&) = delete;FixedBuffer& operator=(const FixedBuffer&) = delete;public://写入数据到缓冲区size_t write(const char* data,size_t len){//计算最大可写长度size_t write_len = std::min(len,_capacity-_used);if (write_len>0){memcpy(_buffer+_used,data,write_len);_used += write_len;}return write_len;}//从缓冲区读数据size_t read(char* out,size_t len){size_t read_len = std::min(len,_used);if (read_len>0){memcpy(out,_buffer,read_len);//如果这次读完之后,还有数据遗留,则把遗留的数据往前挪动if (_used>read_len){memmove(_buffer,_buffer+read_len,_used-read_len);}_used -= read_len;}return read_len;}// 获取缓冲区已使用大小size_t size() const { return _used; }// 获取缓冲区总容量size_t capacity() const { return _capacity; }// 清空缓冲区void clear() { _used = 0; }// 检查缓冲区是否已满bool is_full() const { return _used == _capacity; }// 检查缓冲区是否为空bool is_empty() const { return _used == 0; }// 获取缓冲区数据指针(用于直接操作)const char* data() const { return _buffer; }};三、环形缓冲区
正是因为定长缓冲区有着挪动数据时候的拷贝消耗问题,环形缓冲区利用指针直接规避了这个消耗。
设计思路:
采用首尾相连的环形结构,通过读指针和写指针管理数据,避免数据移动,提高操作效率。
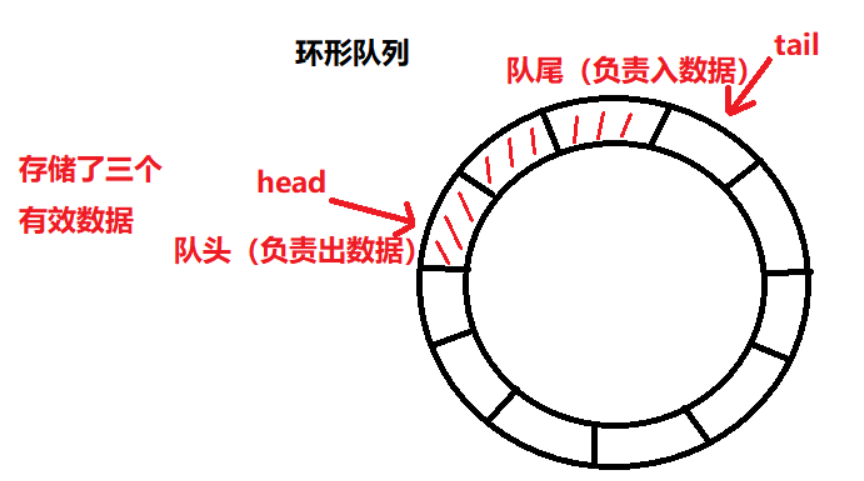

优点:
- 无需移动数据,而是移动指针,读写效率高
- 适合异步读写场景
- 线程安全实现可用于多线程环境
缺点:
- 实现相对复杂
- 实际可用容量比分配的少 1 个单位
- 不适合需要随机访问的场景
#include <cstring>
#include <stdexcept>
#include <mutex>// 线程安全的环形缓冲区
class RingBuffer {
private:char* buffer_; // 缓冲区数据size_t capacity_; // 缓冲区总容量(实际可用capacity_-1)size_t read_pos_; // 读指针size_t write_pos_; // 写指针mutable std::mutex mtx_; // 互斥锁,保证线程安全// 计算下一个位置索引size_t next_pos(size_t pos) const {return (pos + 1) % capacity_;}public:// 构造函数:初始化指定大小的环形缓冲区RingBuffer(size_t capacity) : capacity_(capacity + 1), // 预留一个空位区分满和空read_pos_(0), write_pos_(0) {if (capacity == 0) {throw std::invalid_argument("Capacity must be greater than 0");}buffer_ = new char[capacity_];if (!buffer_) {throw std::bad_alloc();}}// 析构函数:释放缓冲区内存~RingBuffer() {delete[] buffer_;buffer_ = nullptr;}// 禁止拷贝构造和赋值操作RingBuffer(const RingBuffer&) = delete;RingBuffer& operator=(const RingBuffer&) = delete;// 写入数据到缓冲区size_t write(const char* data, size_t len) {if (data == nullptr || len == 0) return 0;std::lock_guard<std::mutex> lock(mtx_);// 计算可写入的最大长度size_t free_space;if (write_pos_ >= read_pos_) {free_space = (capacity_ - write_pos_) + (read_pos_ - 1);} else {free_space = read_pos_ - write_pos_ - 1;}if (free_space == 0) return 0; // 缓冲区已满size_t write_len = std::min(len, free_space);if (write_len == 0) return 0;// 分两种情况写入数据if (write_pos_ + write_len <= capacity_) {// 无需环绕,直接写入memcpy(buffer_ + write_pos_, data, write_len);write_pos_ += write_len;} else {// 需要环绕,分两部分写入size_t first_part = capacity_ - write_pos_;memcpy(buffer_ + write_pos_, data, first_part);size_t second_part = write_len - first_part;memcpy(buffer_, data + first_part, second_part);write_pos_ = second_part;}return write_len;}// 从缓冲区读取数据size_t read(char* out, size_t len) {if (out == nullptr || len == 0) return 0;std::lock_guard<std::mutex> lock(mtx_);// 计算可读取的最大长度size_t data_len;if (write_pos_ >= read_pos_) {data_len = write_pos_ - read_pos_;} else {data_len = (capacity_ - read_pos_) + write_pos_;}if (data_len == 0) return 0; // 缓冲区为空size_t read_len = std::min(len, data_len);if (read_len == 0) return 0;// 分两种情况读取数据if (read_pos_ + read_len <= capacity_) {// 无需环绕,直接读取memcpy(out, buffer_ + read_pos_, read_len);read_pos_ += read_len;} else {// 需要环绕,分两部分读取size_t first_part = capacity_ - read_pos_;memcpy(out, buffer_ + read_pos_, first_part);size_t second_part = read_len - first_part;memcpy(out + first_part, buffer_, second_part);read_pos_ = second_part;}return read_len;}// 获取缓冲区已使用大小size_t size() const {std::lock_guard<std::mutex> lock(mtx_);if (write_pos_ >= read_pos_) {return write_pos_ - read_pos_;} else {return (capacity_ - read_pos_) + write_pos_;}}// 获取缓冲区总容量size_t capacity() const {return capacity_ - 1; // 减去预留的一个空位}// 清空缓冲区void clear() {std::lock_guard<std::mutex> lock(mtx_);read_pos_ = 0;write_pos_ = 0;}// 检查缓冲区是否已满bool is_full() const {std::lock_guard<std::mutex> lock(mtx_);return next_pos(write_pos_) == read_pos_;}// 检查缓冲区是否为空bool is_empty() const {std::lock_guard<std::mutex> lock(mtx_);return read_pos_ == write_pos_;}
};
四、链式缓冲区
设计思路:
由多个固定大小的缓冲区节点通过链表连接而成,可动态扩展,适应数据量变化。采用与环形队列类似的指针移动方式管理数据,避免物理数据搬移,提高效率。
设计亮点:
- 节点内部采用指针管理:每个节点包含
read_pos(读指针)和data_len(数据长度),避免了直接复用定长缓冲区中memmove的数据拷贝消耗 - 高效的读写操作:
- 写入时从当前节点的有效数据末尾开始
- 读取时直接移动读指针,不改变实际数据位置
- 只有当节点数据完全读完时才销毁节点
优点:
- 可动态扩展,适应数据量变化
- 内存利用率高,按需分配
- 采用指针移动方式,避免数据拷贝,性能优异
- 适合处理大尺寸或大小不确定的数据
缺点:
- 链表结构增加了一定内存开销
- 读取数据可能需要跨节点操作
- 实现复杂度高于定长缓冲区
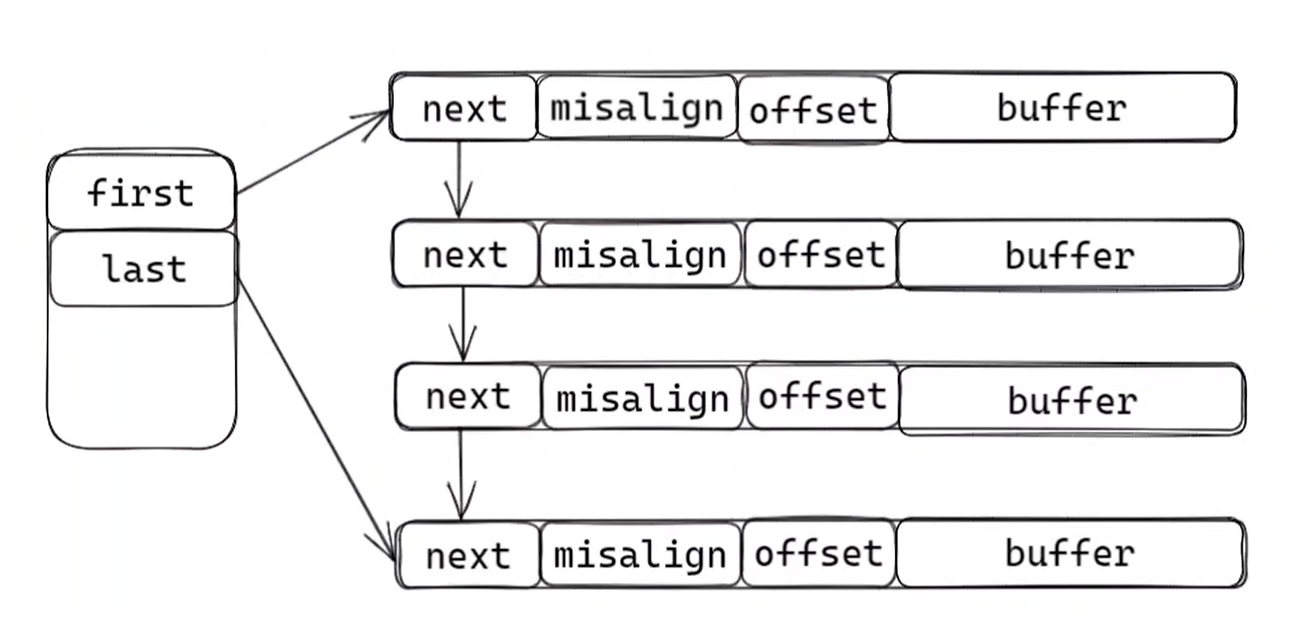
链式缓冲区的设计与C++容器的双端队列极为类似。它的底层实现采用了 “分段数组 + 指针管理” 的方式。但是网络中往往不能直接使用这个容器,这是因为该容器没有封装对粘包问题的函数,同时自定义的链式缓冲区还能对不同的网卡MTU设计合适的内存块大小(双端队列是标准库决定的),最后deque不是线程安全的,不适用于多线程环境。
#include <cstring>
#include <stdexcept>
#include <mutex>// 缓冲区节点
struct BufferNode {char* data; // 节点数据size_t capacity; // 节点容量size_t read_pos; // 读指针:当前数据的起始位置size_t data_len; // 剩余数据长度:当前节点还有多少数据可读BufferNode* next; // 下一个节点BufferNode(size_t cap) : capacity(cap), read_pos(0), data_len(0), next(nullptr) {data = new char[capacity];if (!data) {throw std::bad_alloc();}}~BufferNode() {delete[] data;data = nullptr;next = nullptr;}// 获取可写入的空间大小size_t writeable() const {return capacity - (read_pos + data_len);}
};// 链式缓冲区
class ChainBuffer {
private:BufferNode* head_; // 头节点(读取数据)BufferNode* tail_; // 尾节点(写入数据)size_t node_size_; // 每个节点的大小size_t total_size_; // 总数据大小mutable std::mutex mtx_; // 互斥锁// 创建新节点BufferNode* create_node() {try {return new BufferNode(node_size_);} catch (...) {throw;}}public:// 构造函数:指定节点大小ChainBuffer(size_t node_size = 4096) : node_size_(node_size), total_size_(0),head_(nullptr), tail_(nullptr) {if (node_size == 0) {throw std::invalid_argument("Node size must be greater than 0");}// 创建第一个节点head_ = tail_ = create_node();}// 析构函数:释放所有节点~ChainBuffer() {clear();}// 禁止拷贝构造和赋值操作ChainBuffer(const ChainBuffer&) = delete;ChainBuffer& operator=(const ChainBuffer&) = delete;// 写入数据到缓冲区size_t write(const char* data, size_t len) {if (data == nullptr || len == 0) return 0;std::lock_guard<std::mutex> lock(mtx_);size_t remaining = len;const char* p = data;while (remaining > 0) {// 当前尾节点可写入的空间size_t writeable = tail_->writeable();if (writeable == 0) {// 当前节点已满,创建新节点BufferNode* new_node = create_node();tail_->next = new_node;tail_ = new_node;writeable = tail_->writeable();}// 写入数据size_t write_len = std::min(remaining, writeable);memcpy(tail_->data + tail_->read_pos + tail_->data_len, p, write_len);tail_->data_len += write_len;total_size_ += write_len;p += write_len;remaining -= write_len;}return len - remaining;}// 从缓冲区读取数据(采用指针移动方式,避免数据拷贝)size_t read(char* out, size_t len) {if (out == nullptr || len == 0 || total_size_ == 0) return 0;std::lock_guard<std::mutex> lock(mtx_);size_t remaining = len;char* p = out;BufferNode* current = head_;while (remaining > 0 && current != nullptr) {// 从当前节点读取数据size_t readable = std::min(remaining, current->data_len);if (readable > 0) {memcpy(p, current->data + current->read_pos, readable);current->data_len -= readable;current->read_pos += readable;total_size_ -= readable;p += readable;remaining -= readable;}// 如果当前节点数据已读完,删除并移动到下一个节点if (current->data_len == 0) {BufferNode* old_node = current;current = current->next;delete old_node;} else {// 当前节点还有数据,跳出循环break;}}// 更新头节点head_ = current ? current : create_node();// 如果头节点为空,重置尾节点if (head_ == nullptr) {tail_ = head_;}// 如果所有节点都被删除了,创建一个新节点if (head_ == nullptr) {head_ = tail_ = create_node();}return len - remaining;}// 获取缓冲区总数据大小size_t size() const {std::lock_guard<std::mutex> lock(mtx_);return total_size_;}// 清空缓冲区void clear() {std::lock_guard<std::mutex> lock(mtx_);BufferNode* current = head_;while (current != nullptr) {BufferNode* next = current->next;delete current;current = next;}head_ = tail_ = create_node();total_size_ = 0;}// 检查缓冲区是否为空bool is_empty() const {std::lock_guard<std::mutex> lock(mtx_);return total_size_ == 0;}
};
五、缓冲区的选取建议
1. 简单应用:选择定长缓冲区,实现简单,易于调试
- 实现简单:定长缓冲区通常基于数组来实现,其数据结构和操作逻辑都相对直观。例如,在一些简单的串口通信程序中,可能只是周期性地接收少量固定格式的数据。使用定长缓冲区,只需预先分配好足够大小的数组,通过简单的读写指针移动来管理数据的存入和取出。相比环形缓冲区需要处理读写指针循环以及边界条件判断,或者链式缓冲区涉及节点的动态创建与销毁,定长缓冲区的代码量更少,开发难度更低。
- 易于调试:由于结构简单,在调试过程中更容易定位问题。当出现数据读写错误时,开发人员可以很直观地查看数组中数据的存储情况,以及读写指针的位置,快速判断是写入越界、读取空数据等哪种类型的错误。而复杂的缓冲区结构,如链式缓冲区中可能出现的指针指向错误等问题,调试起来会相对麻烦。
2. 高性能服务器:选择环形缓冲区,减少内存拷贝,提高效率
- 减少内存拷贝:在高性能服务器场景下,网络数据流量大且要求快速处理。环形缓冲区是连续的内存空间,数据的写入和读取只需要移动读写指针,不需要像在普通缓冲区中频繁地进行移动带来的内存拷贝操作。例如,在一个高并发的 Web 服务器中,当处理大量的 HTTP 请求时,使用环形缓冲区可以直接将接收到的数据按顺序写入缓冲区,读取时也能快速定位数据位置,减少了内存拷贝带来的开销,从而提升了数据处理的速度。
- 提高效率:环形缓冲区的连续内存特性还能提高 CPU 缓存命中率。CPU 在读取数据时,会将相邻的数据预读到缓存中,由于环形缓冲区数据连续存储,后续数据读取命中缓存的概率更高,减少了从内存中读取数据的时间,进一步提高了处理效率。此外,环形缓冲区的固定大小特性也使得内存管理相对简单,避免了频繁的内存分配和释放操作带来的性能损耗。
3. 大数据传输:选择链式缓冲区,灵活应对数据量变化
- 灵活调整大小:在大数据传输场景中,数据量的大小往往是不确定的,可能会出现突发的大流量数据。链式缓冲区由多个节点组成,每个节点可以根据实际存储需求动态分配内存。例如,在文件传输服务器中,当传输大文件时,链式缓冲区可以不断添加新的节点来存储文件数据,而无需预先分配一个巨大的固定大小缓冲区,避免了内存浪费;当数据传输结束后,又可以方便地释放不再使用的节点,回收内存资源。
- 适应数据量变化:对于数据量时大时小的情况,链式缓冲区的优势更加明显。比如在视频监控数据的传输中,不同时间段视频数据的流量会有所波动,链式缓冲区能够根据实际数据量动态调整自身大小,保证数据的正常传输,不会因为缓冲区大小固定而出现数据丢失或缓冲区空间浪费的情况。
4. 多线程环境:确保缓冲区实现线程安全,优先选择无锁设计或轻量级锁
- 线程安全的重要性:在多线程环境下,多个线程可能同时对缓冲区进行读写操作,如果缓冲区没有实现线程安全,就会出现数据竞争、脏读、数据不一致等问题。例如,一个线程正在写入数据,另一个线程同时读取数据,可能导致读取到不完整或者错误的数据。因此,确保缓冲区的线程安全是多线程环境下使用缓冲区的关键。
- 无锁设计或轻量级锁:无锁设计(如使用无锁队列、原子操作等技术)可以避免传统锁机制带来的线程阻塞和上下文切换开销,提高多线程并发访问的性能。在一些对性能要求极高的多线程场景中,无锁缓冲区能够充分利用多核 CPU 的性能,让多个线程高效地同时访问缓冲区。而轻量级锁(如自旋锁)相比于重量级锁(如互斥锁),在短时间内获取锁的成功率更高,线程等待时间更短,也适用于多线程对缓冲区访问冲突较少的场景,在保证线程安全的同时,尽量减少性能损耗。
六、不同的协议对用户态缓冲区设计的影响
(1)TCP与UDP
TCP是面向字节流的协议,需要处理粘包问题,所以缓冲区要考虑:
- 数据聚合能力:能缓存不完整消息,等待后续完整消息到达后再交付应用层
- 协议解析接口:支持根据自定义协议(如长度前缀、特殊分隔符)提取完整消息
而UDP则是面向数据报的协议,天然没有粘包问题,这就要求我们对每次的read单独管理一块内存,而非堆积在一起,同时需要记录每个报文的五元组信息。
- 按消息粒度存储:每个 UDP 报文作为独立单元存储,避免跨消息读取
- 消息元数据管理:需记录每个消息的发送方地址、端口等信息