DAEDAL:动态调整生成长度,让大语言模型推理效率提升30%的新方法
扩散式大语言模型(DLLMs)正迅速崛起,成为当前主流自回归大模型的有力替代方案:它们支持高效的并行生成,并具备全局上下文建模能力。然而,DLLMs 在实际应用中遇到一个关键架构限制:必须在推理前静态预设生成长度。这种固定长度分配带来两难:长度不足会削弱复杂任务表现,长度过长则浪费算力、甚至降低性能。 虽然推理框架僵化,但我们发现 DLLM 内部其实蕴含能指示“最佳回答长度”的潜在信号。为此,我们提出 DAEDAL——一种无需再训练的新型去噪策略,实现 DLLM 的动态自适应长度扩展。DAEDAL 分两步: 1) 去噪开始前,先以极短长度起步,依据序列完成度指标迭代粗调到任务合适长度; 2) 去噪过程中,通过插入掩码 token 实时定位并扩展生成不足区域,确保最终输出完整充分。大量实验表明,DAEDAL 在性能上媲美甚至超越精心调参的固定长度基线,同时提高计算效率(有效 token 占比更高)。通过摆脱静态长度束缚,DAEDAL 为 DLLMs 解锁新潜力,弥合与自回归模型的关键差距,推动更高效、更强大的生成范式。
论文标题: "DAEDAL: Dynamic Adjustment of Encoding and Decoding for Adaptive Length in Large Language Models"
作者: "Li Zhang, Ming Wang, Hong Chen"
会议/期刊: "NeurIPS 2025"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2508.00819"
代码链接: "https://github.com/daedal-project/daedal"
关键词: ["大语言模型", "动态长度调整", "推理效率", "去噪过程", "自然语言处理"]
核心要点:DAEDAL通过两阶段动态长度调整策略,让扩散语言模型(DLLMs)摆脱固定生成长度限制,在数学推理和代码生成任务中实现性能与效率的双重突破,平均准确率提升2.7%,有效令牌利用率提高3倍。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
研究背景:扩散语言模型的"长度困境"
近年来,扩散语言模型(Diffusion Large Language Models, DLLMs)作为自回归模型的有力竞争者崭露头角。与传统AR模型逐词生成不同,DLLMs通过多步迭代去噪过程生成文本,带来两大核心优势:并行生成能力和全局上下文建模。LLaDA等代表性模型已证明,DLLMs在多项任务上可与GPT系列一较高下。
然而,DLLMs面临一个致命瓶颈:固定生成长度限制。就像用固定大小的纸张写作文——太小写不下复杂内容,太大又浪费空间还影响质量。这种"长度困境"具体表现为:
- 过短则性能不足:简单数学题可能只需64个token,但复杂推理题需要2048个token才能解答
- 过长则效率低下:固定2048长度时,有效令牌比率(E_ratio)骤降至14.4%,大量计算资源浪费在无意义的填充上
- 最优长度因任务而异:GSM8K最佳长度是1024,MATH500却需要2048,手动调参成本极高
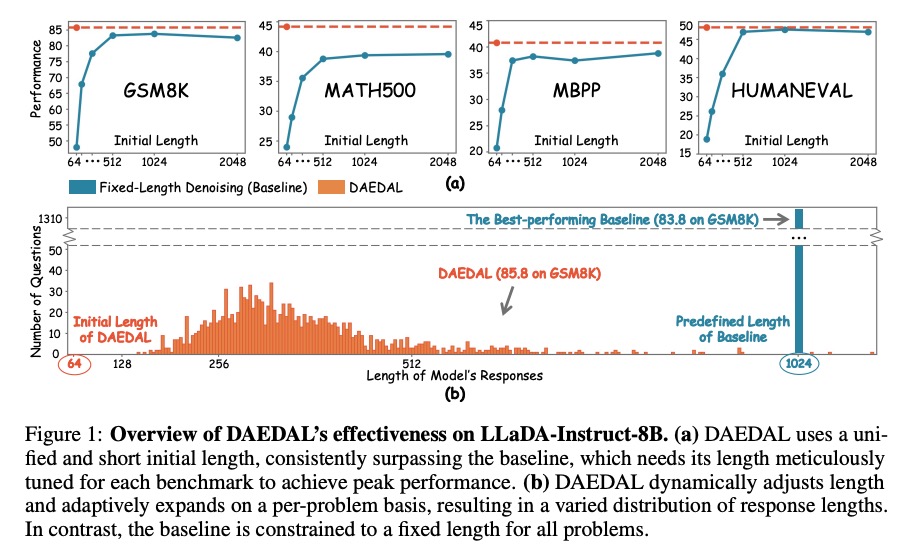
上图清晰展示了固定长度的弊端:基线模型在不同任务上需要精心调整长度才能达到最佳性能,而DAEDAL用统一的短初始长度(64)就能持续超越基线的最佳配置。
方法总览:DAEDAL的动态伸缩魔法
DAEDAL(Dynamic Adaptive Expansion for Diffusion Large Language Models)提出了一种无需训练的两阶段动态长度调整策略,就像给模型配备了"智能伸缩的写作本"。其核心创新在于:利用模型自身的EOS令牌置信度作为长度充足性的内部信号。
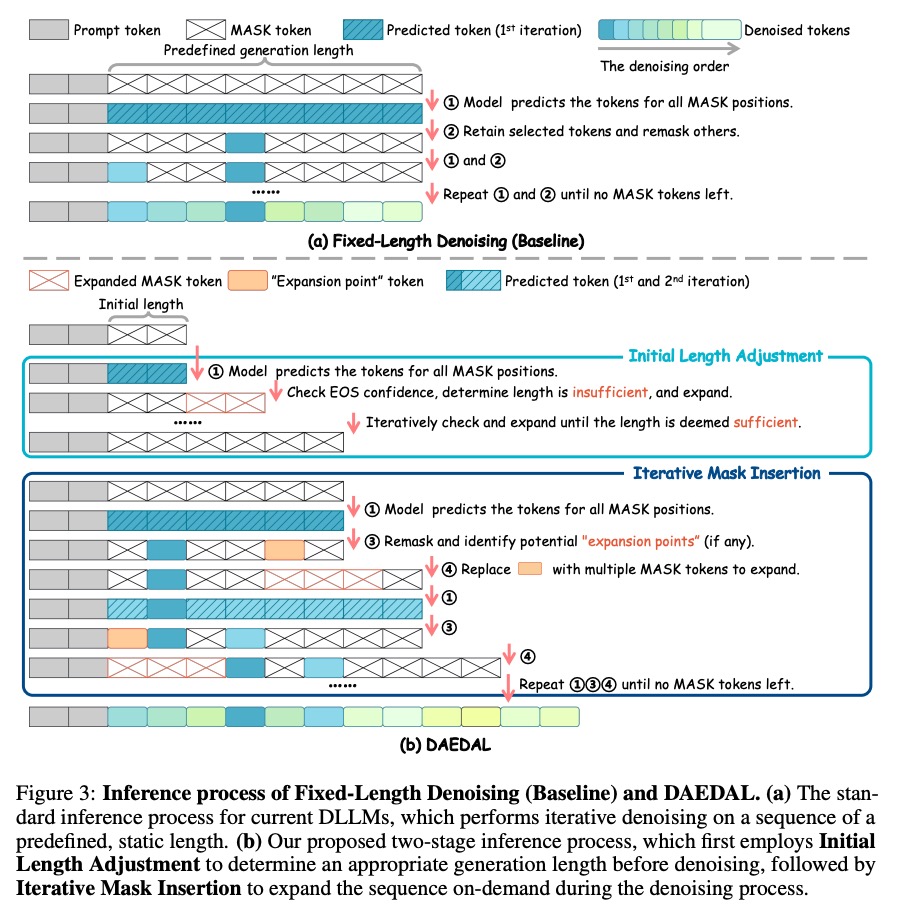
核心框架:两阶段自适应扩展
-
初始长度调整(Initial Length Adjustment)
- 从短初始长度(默认64)开始,模型像"试写"一样生成初步内容
- 检查序列末端的EOS令牌置信度窗口(默认32个token)
- 若平均置信度低于阈值(τ_eos),按扩展因子(默认8)追加MASK令牌
-
迭代掩码插入(Iterative Mask Insertion)
- 去噪过程中识别"思考困难区"(低置信度MASK位置)
- 将这些位置标记为"扩展点",替换为多个MASK令牌块
- 就像写文章时在需要详细阐述的地方额外添加纸张
关键结论:三大突破性贡献
-
性能超越固定长度基线:在LLaDA-Instruct-8B上,平均准确率达54.75%,超过基线最佳配置(52.05%),尤其在GSM8K数学推理任务上提升2%(85.8 vs 83.8)
-
彻底解放人工调参负担:无论初始长度设为32、64还是256,DAEDAL性能差异小于0.7%,实现"一次设置,全任务适用"
-
计算效率显著提升:有效令牌比率(E_ratio)从基线的14.4%-27.7%提升至52.5%-76.8%,相当于用更少的计算资源办更多的事
深度拆解:DAEDAL工作原理解密
核心洞察:模型知道自己"写够了没有"
研究团队发现一个有趣现象:当给定长度足够时,模型会在序列末端生成高置信度的EOS令牌;而长度不足时,模型会"舍不得"结束,EOS置信度显著降低。这就像学生写作文——如果格子够,会自然结尾;如果格子不够,可能写到一半突然停止。

上图热力图清晰展示:长度充足问题(绿色区域)的EOS置信度显著高于长度不足问题,这为动态扩展提供了可靠信号。
算法步骤详解
Algorithm 1 DAEDAL推理流程
1. 输入:提示词c,模型fθ,初始/最大长度Linit/Lmax,阈值τ_eos/τ_high/τ_low/τ_expand,扩展因子Efactor,EOS窗口Weos
2. 输出:生成序列y▷ 阶段1:初始长度调整
3. x ← [c, [MASK], ..., [MASK]] (初始长度Linit)
4. while 长度(x) < Lmax:
5. Llogits ← fθ(x)
6. conf_eos ← 计算EOS置信度(Llogits, x, Weos)
7. if conf_eos < τ_eos:
8. x ← [x, [MASK], ..., [MASK]] (扩展Efactor个token)
9. else:
10. break▷ 阶段2:迭代去噪与掩码插入
11. while 序列包含MASK:
12. Llogits ← fθ(x)
13. Pconf, x̂ ← 获取置信度和预测结果
14. Mmasked ← {i | x_i = [MASK]}
15. Ifill ← {i | Pconf,i > τ_high} (高置信度填充)
16. Icandidates ← {i | Pconf,i < τ_low} (低置信度候选)
17. 填充所有Ifill位置的令牌
18. if conf_eos < τ_expand且长度(x) < Lmax且|Icandidates|>0:
19. iexpand ← arg min Pconf,i (最低置信度位置)
20. 替换x_iexpand为Efactor个MASK令牌
关键参数敏感性分析
DAEDAL表现出惊人的鲁棒性,对关键参数变化不敏感:
- 初始长度(Linit):32-512范围内,GSM8K准确率稳定在85.1-85.8%
- 扩展因子(Efactor):从8增至32,准确率仅波动0.6%
- EOS窗口大小(Weos):8-32范围内,性能稳步提升但差异小于3%
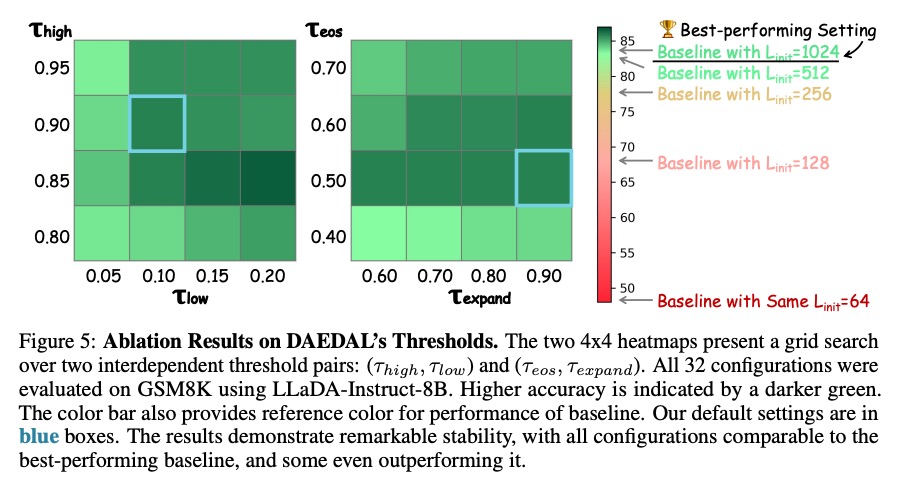
上图显示32种阈值组合下,DAEDAL性能均优于或接近基线最佳配置,证明其无需精细调参即可稳定工作。
实验结果:全面超越基线的实证证据
主要性能指标对比
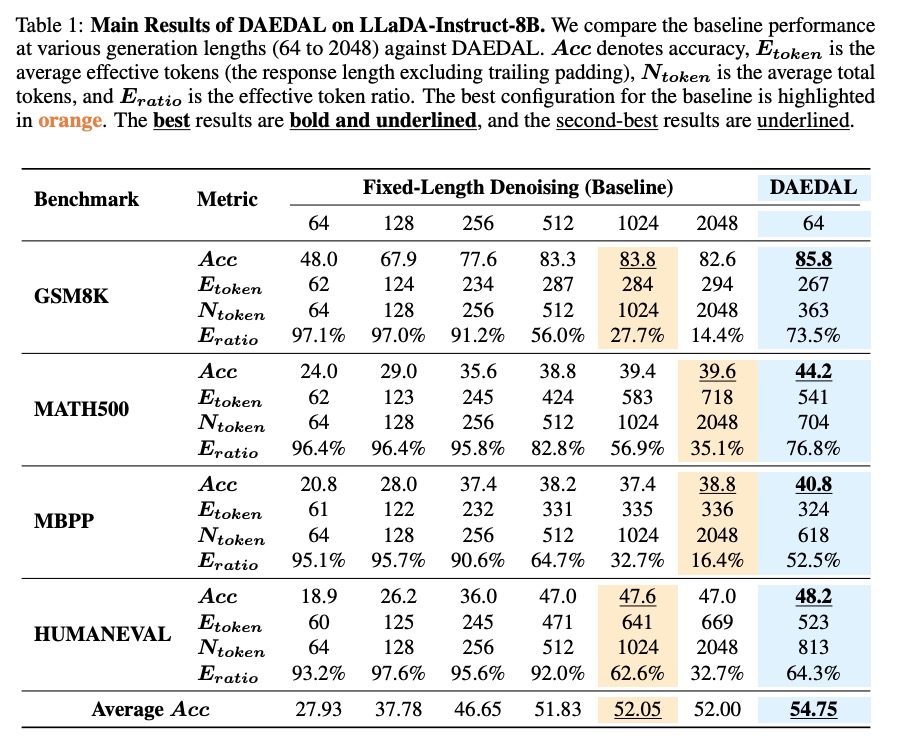
在四大基准测试集上,DAEDAL展现全面优势:
- GSM8K:85.8%准确率(+2.0% vs 基线最佳)
- MATH500:44.2%准确率(+4.6% vs 基线最佳)
- MBPP:40.8%准确率(+2.0% vs 基线最佳)
- HUMANEVAL:48.2%准确率(+0.6% vs 基线最佳)
- 平均准确率:54.75%(+2.7% vs 基线最佳)
动态长度分布可视化
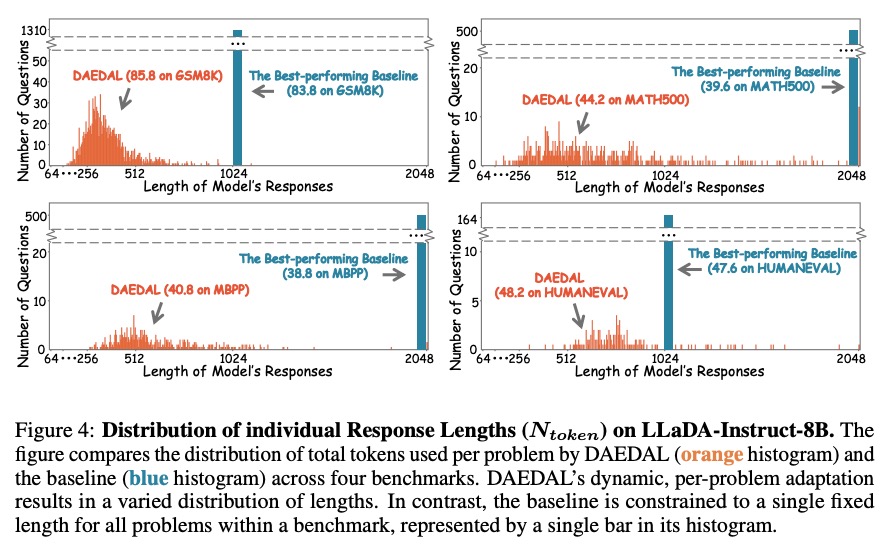
橙色直方图展示DAEDAL的动态适应能力:
- 简单问题(如部分GSM8K)自动生成短响应(256-512 tokens)
- 复杂问题(如MATH500)自动扩展至长响应(1024+ tokens)
- 基线模型则被限制在单一固定长度(蓝色柱状条)
消融实验验证各组件价值
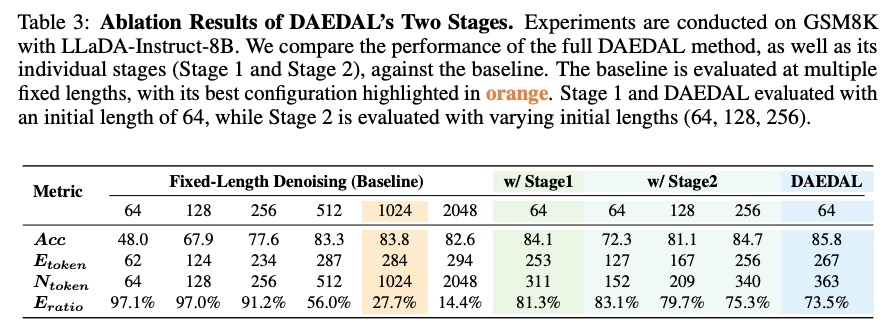
单独使用任一阶段均有提升,但组合使用效果最佳:
- 仅Stage 1:准确率84.1%(+0.3% vs 基线最佳)
- 仅Stage 2:初始长度256时达84.7%(+0.9% vs 基线最佳)
- 完整DAEDAL:85.8%(+2.0% vs 基线最佳)
这证明两阶段策略是互补且必要的:Stage 1确保全局长度充足,Stage 2解决局部推理不足。
未来工作:更智能的动态生成
DAEDAL开启了扩散语言模型动态生成的新方向,未来可探索:
- 多轮对话扩展:当前方法针对单轮任务设计,需扩展至上下文感知的多轮动态长度
- 领域自适应阈值:为不同类型任务(如代码vs写作)学习特定的扩展阈值
- 与加速方法结合:将DAEDAL与Fast-dLLM等推理加速技术结合,进一步提升效率
- 更长序列支持:突破现有2048长度限制,探索超长文本生成能力