DETR:用Transformer革新目标检测的新范式
DETR:用Transformer革新目标检测的新范式
一种端到端集合预测做检测的突破性实践
引言:目标检测的范式革命
传统目标检测模型(如Faster R-CNN、YOLO)依赖手工设计的先验知识:
-
锚框(Anchor):预设不同尺度和比例的候选框
-
非极大值抑制(NMS):过滤冗余检测结果
-
区域提议网络(RPN):生成候选区域
这些组件增加了模型复杂性,成为性能提升的瓶颈。2020年Facebook AI提出的DETR(DEtection TRansformer) 彻底颠覆了这一传统,首次将Transformer架构引入目标检测领域,实现真正的端到端检测。
一、DETR核心思想解析
1. 集合预测(Set Prediction)
DETR将目标检测视为集合预测问题:
-
直接预测固定数量(如100个)的无序检测结果
-
每个结果包含:类别概率分布 + 边界框坐标
-
通过二分图匹配(Bipartite Matching) 将预测与真实标签对齐
2. 端到端架构
摒弃所有手工组件: ✅ 无需锚框设计 ✅ 无需NMS后处理 ✅ 无需区域提议
3. Transformer全局建模
利用Transformer的自注意力机制:
-
建模图像中所有元素间的全局依赖关系
-
解决传统卷积网络局部感受野的限制
二、模型架构详解
DETR由三个核心模块构成:Backbone、Transformer(encoder、decoder)、prediction heads~
图源:DETR论文 End-to-End Object Detection with Transformers
1. 卷积骨干网络(Backbone)
-
输入:原始图像
x(3×H×W) -
输出:低分辨率特征图
f(C×H/32×W/32) -
常用ResNet-50:
f.shape = [2048, 18, 25](输入800×1333时)
2. Transformer编码器-解码器
(1)特征转换
conv = nn.Conv2d(2048, 256, 1) # 1×1卷积降维z0 = conv(f) # [batch, 256, 18, 25]pos_enc = sine_position_encoding(z0) # 正弦位置编码z0 = z0.flatten(2).permute(0,2,1) # 展平: [batch, 450, 256]
(2)编码器(Encoder)
-
由6层标准Transformer编码器组成
-
每层含多头自注意力(Multi-head Self-Attention) 和 FFN
-
输出全局建模的特征:
memory = encoder(z0)
(3)解码器(Decoder)
-
核心创新:对象查询(Object Queries)!
-
可学习的嵌入向量(
nn.Embedding(100, 256)) -
每个查询对应一个预测槽位
-
物理意义:学习"目标可能存在的位置"的全局信息
-
query_embed = nn.Embedding(100, 256) # 100个查询向量tgt = torch.zeros(100, 256) # 初始输入hs = decoder(tgt, memory, query_pos=query_embed.weight) # 输出 [100, batch, 256]
3. 预测头(Prediction Heads)
# 分类头(输出92类+背景),利用nn.Linear简单映射class_head = nn.Linear(256, num_classes+1) # 回归头(预测框中心+宽高),利用MLP复杂坐标预测bbox_head = MLP(256, 256, 4, num_layers=3)
三、训练机制:二分图匹配损失
DETR的核心创新在于损失函数设计:
1. 二分图匹配(Hungarian Matching)
-
目标:为每个真实框分配唯一预测结果
-
代价函数:
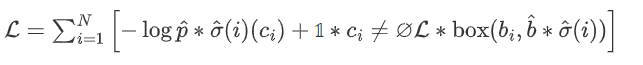
-
第一部分:类别预测概率
-
第二部分:边界框相似度(L1损失 + GIoU损失)
-
2. 匈牙利算法求解
cost_matrix = class_cost + bbox_l1_cost + giou_cost # 代价矩阵indices = linear_sum_assignment(cost_matrix) # 求解最优匹配
3. 最终损失计算
仅计算匹配对的损失:
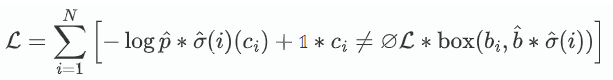
四、DETR的创新价值
1. 突破性优势
-
架构简化:去除所有手工设计组件
-
全局推理:自注意力建模目标间关系(如遮挡场景)
-
扩展性强:同一框架支持全景分割、姿态估计等任务
2. 实验表现(COCO数据集)
| 模型 | mAP | 参数量 | 推理速度 (FPS) |
|---|---|---|---|
| Faster R-CNN | 42.0 | 42M | 26 |
| DETR | 42.0 | 41M | 28 |
在大型目标检测上表现尤佳(+8.5 mAP)
3. 局限性
-
小目标检测弱:低分辨率特征限制细节感知
-
训练收敛慢:需500 epoch(Faster R-CNN仅需1/10时间)
-
计算开销大:自注意力复杂度 O(N^2)
五、DETR的后续演进
1. Deformable DETR(2021)
-
引入可变形注意力(Deformable Attention)
-
解决小目标检测问题,加速训练收敛
# Deformable Attention实现(简化版)deform_attn = DeformableAttn(embed_dim=256,num_heads=8,dropout=0.1,num_points=4 # 每个头采样4个点)
2. Conditional DETR(2021)
-
改进对象查询设计
-
显式学习空间位置与内容特征的解耦
3. DAB-DETR(2022):提出动态锚框查询
-
将查询表示为4D锚框(x,y,w,h)
-
提升定位精度和收敛速度
-
比较不错的博客分享:https://zhuanlan.zhihu.com/p/567496850
DAB-DETR 核心改进点:
https://pica.zhimg.com/v2-93dc557f19387cd0b4b2ff1b58a53aa0_1440w.jpg
-
直接学习anchor box作为query
-
使用正余弦编码后的x,y作为positional query
-
使用w,h调制注意力图
-
层与层更新anchor box
4.DN-DETR (2022):设计去噪训练机制
5.DINO(2022)
-
整合所有关键技术+对比学习,达到最佳效果!
六、DETR的实践意义
-
学术价值:
-
证明纯Transformer架构在目标检测的可行性
-
开创基于集合预测的端到端检测范式
-
-
工业影响:
-
被集成进MMDetection、Detectron2等框架
-
在自动驾驶(Waymo)、工业质检等场景落地
-
-
生态扩展:
-
ViT:引领视觉Transformer浪潮
-
MaskFormer:统一分割任务框架
-
OWL-ViT:推动开放世界检测
-
结语
DETR不仅是目标检测的技术革新,更是计算机视觉范式的转变~
随着后续改进模型不断涌现,DETR开创的端到端检测范式正在重塑计算机视觉的疆界。它的成功启示我们:简化即进化,统一即力量。