如何理解 nacos 1.x 版本的长轮询机制
一直有这样一个问题:
Q:什么叫长轮询?每隔30s就发送一次http请求么?一个http 请求只能请求一件事,比如说:心跳,如果这个时间段还有其他请求又复用不了这个http请求,只能重新发一个,但是这又有什么意义呢?
A:
Nacos 1.x 的 长轮询(Long Polling),核心是要区分它与 “每隔 30 秒发一次普通 HTTP 请求” 的本质差异 —— 长轮询并非 “定时短请求”,而是一种 “请求挂起 + 按需响应” 的机制,目的是在 HTTP 协议的局限性下,尽可能实现 “准实时推送”,同时减少无效请求开销。下面从定义、原理、与普通轮询的区别,以及 Nacos 1.x 中的具体应用(服务发现、心跳)展开说明:
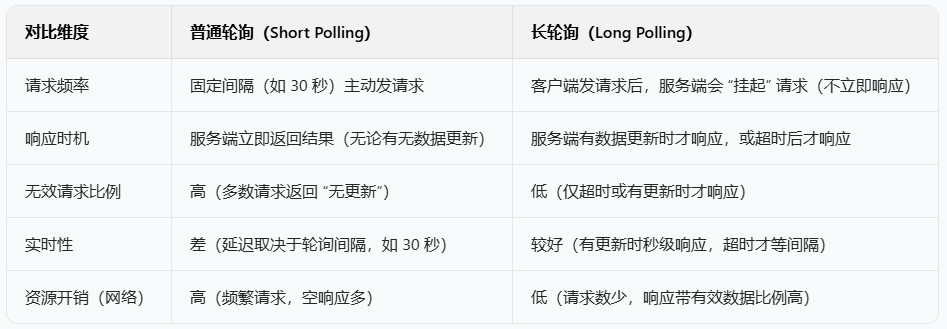
一、先明确:长轮询 ≠ 定时发普通 HTTP 请求
“每隔 30 秒发一次 HTTP 请求” 是 普通轮询(Short Polling),而长轮询是对普通轮询的优化,核心差异在于 “请求是否会被服务端挂起”:
二、长轮询的核心原理:“挂起请求 + 按需唤醒”
长轮询的本质是利用 HTTP 的 “请求 - 响应” 模型,但通过服务端延迟响应,把 “客户端频繁问” 变成 “服务端有消息再答”,流程如下(以 Nacos 1.x 服务发现为例):
- 客户端发起请求:
- 客户端(如微服务 A)向 Nacos 服务端发送一个 HTTP 请求,目的是 “查询服务 B 的实例列表是否有更新”,并在请求中带上 “超时时间”(比如 30 秒)。
- 服务端判断是否有更新:
- 如果服务 B 的实例列表有更新(如新增 / 下线实例),服务端立即返回最新的实例列表,客户端拿到结果后,处理完立即发起下一次长轮询请求(保持 “持续监听”)。
- 如果服务 B 的实例列表无更新,服务端不会立即响应,而是把这个请求 “挂起”(放入一个 “等待队列”),同时开始计时。
- 服务端 “唤醒” 挂起的请求:
- 在 30 秒超时前,如果服务 B 的实例列表突然有更新(如服务 B 某个实例下线),服务端会从 “等待队列” 中找到监听服务 B 的所有挂起请求,立即返回最新的实例列表,客户端处理后再发起下一次长轮询。
- 如果 30 秒超时了,服务 B 的实例列表仍无更新,服务端会返回一个 “无更新” 的空响应,客户端拿到空响应后,不做业务处理,直接发起下一次长轮询请求(避免断连)。
简单说:长轮询是 “客户端发一次请求,服务端 hold 住 30 秒,期间有更新就答,没更新到点再答”,而非 “客户端每 30 秒发一次请求”。
三、Nacos 1.x 用长轮询做什么?解决了什么问题?
Nacos 1.x 的核心场景(服务发现、心跳)都依赖长轮询,目的是在 HTTP 协议下,平衡 “实时性” 和 “资源开销”:
- 服务发现:解决 “实例更新实时推送” 问题
- 微服务需要实时知道依赖的服务实例是否可用(如服务 B 下线,服务 A 要立即感知,避免发请求到死节点)。如果用普通轮询:客户端每 30 秒问一次,若服务 B 在第 5 秒下线,服务 A 要等 25 秒后才能感知,延迟太高;若把轮询间隔缩到 1 秒,会导致大量无效请求(99% 的请求返回 “无更新”),浪费网络和服务端资源。
- 而长轮询的优势在此体现:
实时性:服务 B 下线时,服务端立即唤醒挂起的请求,服务 A 秒级感知;
低开销:30 秒内只发 1 次请求,无论有无更新,请求数远少于普通轮询。
- 心跳:解决 “实例存活检测” 问题
Nacos 1.x 的客户端心跳也是基于长轮询优化的(本质是 “带存活确认的长轮询”):
客户端发起心跳请求时,服务端同样会挂起请求(30 秒超时);
若 30 秒内客户端正常,会在本次请求响应后立即发起下一次心跳请求(相当于 “续期”);
若服务端 30 秒内没收到客户端的下一次心跳请求(或客户端挂了),则判定实例下线。
这种方式比 “客户端每 30 秒发一次普通心跳请求” 更高效 —— 避免了大量 “空心跳”(仅确认存活,无业务数据)的网络传输。
四、 “一个 HTTP 请求只能做一件事”:长轮询如何处理多场景?
“一个 HTTP 请求只能说明一件事” 是对的 ——HTTP 是 “单请求单响应” 模型,一个长轮询请求只能对应一个 “监听场景”(如监听服务 B 的实例更新)。但 Nacos 1.x 会通过多个独立的长轮询请求,分别处理不同场景,而非复用一个请求:
监听服务 B 的实例更新:一个长轮询请求(路径:/nacos/v1/ns/instance/list);
客户端自身的心跳:另一个长轮询请求(路径:/nacos/v1/ns/instance/beat);
监听服务 C 的实例更新:再一个长轮询请求。
这些请求是独立的,但都是 “挂起 30 秒” 的长轮询模式 —— 虽然不能复用一个请求处理多件事,但相比普通轮询,每个请求的 “有效价值” 更高(要么带更新数据,要么确认存活),整体资源开销更低。
五、为什么 Nacos 2.x 要换成 gRPC?(对比长轮询的局限性)
长轮询是 HTTP 协议下的 “折中方案”,但仍有明显缺点,这也是 2.x 改用 gRPC 的原因:
连接无法复用:每个长轮询请求都是一个独立的 HTTP 连接(即使复用 TCP 连接,HTTP/1.1 的连接复用也有限制),客户端若监听多个服务,会建立多个连接,开销比 gRPC 的 “单连接多路复用” 高。
实时性仍有上限:长轮询的最大延迟是 “超时时间”(如 30 秒),若服务端在超时前 1 秒才更新,客户端仍要等 1 秒才能感知;而 gRPC 基于 HTTP/2 的流(Stream),可以实现 “实时推送”,延迟接近 0。
协议 overhead 高:HTTP 头信息(如 Cookie、Header)比 gRPC 的 Protobuf 大很多,同样的业务数据,HTTP 传输的字节数更多,效率更低。
总结
- 长轮询不是 “定时发 HTTP 请求”,而是 “客户端发请求,服务端挂起 30 秒,有更新就响应,超时才返回空”,核心是 “按需响应”,减少无效请求。
- Nacos 1.x 用长轮询解决服务发现的 “实时更新” 和心跳的 “存活检测”,平衡了 HTTP 协议下的实时性和资源开销。
- 长轮询的局限性(连接无法复用、实时性有上限),促使 Nacos 2.x 改用 gRPC(基于 HTTP/2 多路复用、Protobuf 高效序列化),进一步提升性能和实时性。
- 如果想直观感受,可在 Nacos 1.x 客户端发起服务发现请求时,用 Fiddler 抓包 —— 会看到请求发出后,服务端不会立即响应,而是等有更新或 30 秒后才返回,这就是长轮询的典型特征。
👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉👉
在 http 请求中,想要确定请求哪个接口是通过 url 路径来确定的,比如说:auth/login ,那么在 grpc中,也是这样确定的么?
GRPC 中的接口定位机制
GRPC 使用 Protocol Buffers(protobuf)定义服务和方法,与 HTTP 不同,GRPC 不依赖 URL 路径定位接口。接口的调用通过 服务名和方法名 的组合实现,具体机制如下:
服务与方法定义
在 .proto 文件中,服务和方法通过 service 和 rpc 关键字定义。例如:
service AuthService {rpc Login (LoginRequest) returns (LoginResponse);
}
- 服务名:
AuthService - 方法名:
Login
调用时,客户端通过 完整方法路径(/服务名/方法名)指定目标接口,如 /AuthService/Login。
与 HTTP 的对比
-
HTTP 接口定位
- 通过 URL 路径(如
auth/login)和 HTTP 方法(GET/POST 等)确定接口。 - 路径通常由后端路由框架解析(如 RESTful 设计)。
- 通过 URL 路径(如
-
GRPC 接口定位
- 通过 protobuf 定义的 服务名和方法名 组合定位。
- 底层由 HTTP/2 传输,但路径格式固定为
/包名.服务名/方法名(如包名为example,则路径为/example.AuthService/Login)。
GRPC 的 URL 形式
尽管 GRPC 基于 HTTP/2,其 URL 的路径部分仅用于内部路由,格式为:
http://host:port/{package}.{service}/{method}
例如:
http://localhost:50051/example.AuthService/Login
但实际编程中,客户端通常直接调用生成的 stub 方法,无需手动拼接 URL。
关键区别
- 显式性:GRPC 的接口定义通过 protobuf 显式声明,编译器会生成强类型客户端代码,避免路径拼写错误。
- 协议依赖:HTTP 依赖文本路径,而 GRPC 依赖二进制协议和代码生成,路径仅用于底层传输。
如果需要类似 HTTP 的路径映射(如 RESTful GRPC),可通过 google.api.http 注解实现(需使用 gRPC Gateway 等工具)。