大模型微调示例三之Llama-Factory_Lora
大模型微调示例三之Llama-Factory_Lora
- 一、安装必要环境
- 二、数据准备
- 三、模型微调
- 3.1、准备微调配置文件
- 3.2、配置微调训练文件
- 3.2.1、lora微调
- 3.2.2、全量微调
- 四、模型合并以及部署
- 4.1、模型合并
- 4.2、VLLM部署
一、安装必要环境
llamafactory安装参考:llamafactory安装
vllm安装参考:vllm安装
我们还需要安装bitsandbytes库:pip install bitsandbytes
二、数据准备
⽤华佗数据集 https://github.com/FreedomIntelligence/Huatuo-26M 中的百科问答数据集来(huatuo_encyclopedia_qa)来训练⼀个医疗百科问答模型。
Llama-Factory⽀持两种格式的数据集:Alpaca格式和sharegpt 格式。需要将华佗百科问答数据集转化为这两种格式其中之⼀,这里选择转化为alpaca数据集,
import jsondef format_data(filepath):data_list = []with open(filepath, "r", encoding="utf-8") as f:for line in f:new_obj = {}obj = json.loads(line.strip("\n"))new_obj["instruction"] = ",".join(obj["questions"][0])new_obj["input"] = ""new_obj["output"] = ",".join(obj["answers"])data_list.append(new_obj)return data_listdef write_json(data_list, filename):writer = open(filename, "w", encoding="utf-8")json.dump(data_list, writer, ensure_ascii=False, indent=4)data_path = "/root/autodl-tmp/huatuo-encyclopedia-qa/"
new_data_path = "/root/autodl-tmp/huatuo-encyclopedia-qa-alpaca/"filename = "train_datasets.jsonl"
filepath = data_path + filename
data_list = format_data(filepath)
write_json(data_list, new_data_path + filename)filename = "test_datasets.jsonl"
filepath = data_path + filename
data_list = format_data(filepath)
write_json(data_list, new_data_path + filename)filename = "validation_datasets.jsonl"
filepath = data_path + filename
data_list = format_data(filepath)
write_json(data_list, new_data_path + filename)
转化为sharegpt数据集,这里不用。仅解释一下
主要的区别在于结构:
● Alpaca 每条是一个独立的字典(单轮指令-输出)。
● ShareGPT 更偏向 对话形式,每条数据通常是一个字典,包含:
{"id": "唯一id","conversations": [{"from": "human","value": "用户的问题"},{"from": "gpt","value": "模型的回答"}]
}
也就是说,每条数据是一个“对话”,并且支持多轮对话。
主要修改点:
1. 每条数据增加 id 字段(用 uuid.uuid4())。
2. 改成 "conversations" 列表,"human" 对应原来的 "instruction","gpt" 对应原来的 "output"。
3. 支持多轮对话的结构(现在是一轮,你可以扩展)。
import json
import uuid # 用于生成唯一iddef format_data_sharegpt(filepath):data_list = []with open(filepath, "r", encoding="utf-8") as f:for line in f:obj = json.loads(line.strip("\n"))human_text = ",".join(obj["questions"][0])gpt_text = ",".join(obj["answers"])new_obj = {"id": str(uuid.uuid4()), # 生成唯一id"conversations": [{"from": "human","value": human_text},{"from": "gpt","value": gpt_text}]}data_list.append(new_obj)return data_listdef write_json(data_list, filename):with open(filename, "w", encoding="utf-8") as writer:json.dump(data_list, writer, ensure_ascii=False, indent=4)data_path = "/root/autodl-tmp/huatuo-encyclopedia-qa/"
new_data_path = "/root/autodl-tmp/huatuo-encyclopedia-qa-sharegpt/"for split in ["train_datasets.jsonl", "test_datasets.jsonl", "validation_datasets.jsonl"]:filepath = data_path + splitdata_list = format_data_sharegpt(filepath)write_json(data_list, new_data_path + split)
alpaca数据集内容如下:

接下来,将新⽣成的train等⽂件copy⾄Llama-factory⽬录的data⽂件夹下,并重新命名为"huatuoencyclopedia-qa.json"
在Llama-Factory中进⾏数据配置
接下来,我们还需要在llama-factory中进⾏数据配置。在Llama-Factory/data下找到dataset_info.json,在json list中加⼊下⾯的配置:
"huatuo": {"file_name": "huatuo-encyclopedia-qa.json", "columns": {"prompt": "instruction", "query": "input", "response": "output"}
}
这样,我们就可以在sft的配置⽂件中直接使⽤数据集名字“huatuo”来指定制作好的华佗百科问答数据集了。
三、模型微调
3.1、准备微调配置文件
LLaMa-Factory已经集成好了训练、推理、部署的⼯具,⽀持图形化以及命令⾏式的调⽤,只需要 进⾏简单的配置即可使⽤。
现在基本上市⾯上的主流模型LLaMa-Factory都⽀持,网址 中列出的模型。
3.2、配置微调训练文件
3.2.1、lora微调
### model
model_name_or_path: ZhipuAI/glm-4-9b-chat
quantization_bit: 8
quantization_method: bitsandbytes # choices: [bitsandbytes (4/8), hqq (2/3/4/5/6/8), eetq (8)]### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all### dataset
dataset: huatuo
template: glm4
cutoff_len: 1024
max_samples: 10000
overwrite_cache: true
preprocessing_num_workers: 16### output
output_dir: /root/autodl-tmp/checkpoints/huatuo-glm-qlora
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 1.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
下⾯分别解释下每⼀段配置的含义:
1. model部分 ● model_name_or_path: 指定了LLama-Factory⽀持的模型名字,可以从constant.py⽂件中查看详细列表:网址 值得注意的是除了huggingface源,还可以⽀持modelscope源,⽹络友好。 ● quantization_bit:指定了qlora的量化位 ● quantization_method:这⾥指定了量化⽅式
2. method部分 ● stage: sft,指定我们的训练阶段是微调阶段 ● do_train: true,是否训练 ● finetuning_type: lora,微调⽅式除了lora,Llama-Factory还⽀持全量参数微调。 ● lora_target: all,指定lora_target参与训练的部分
3. dataset部分 ● dataset: huatuo,指定训练集,可以多个数据集直接拼接起来,逗号分隔就可以 ● template: glm4,模板,因为我们使⽤的是chatglm4的模型,所以使⽤glm4作为模板这⾥和constant.py中的model_name是对应的。 ● max_samples: 10000,如果配置了这个参数,会按照这个参数对训练数据集的⻓度进⾏截断。
4. output部分 ● output_dir: /root/autodl-tmp/checkpoints/huatuo-glm-qlora,指定训练好的模型保存的位置 ● logging_steps: 10,每10个steps打印⼀次⽇志 ● save_steps: 500,每500个steps保存⼀次checkpoint
5. train部分 ● per_device_train_batch_size: 1,每个device上的batch数,此时的batch_size =num_of_devices * per_device_train_batch_size. ● gradient_accumulation_steps: 8: 每8个steps计算⼀次梯度 ● learning_rate: 1.0e-4:初始学习率 ● num_train_epochs: 1.0:训练的epoch,也就是数据集迭代多少次 ● lr_scheduler_type: cosine:lr 调度器类型,设置为cosine
6. eval部分 ● val_size: 0.1:将训练集中的10%的数据切分出来作为验证集 ● per_device_eval_batch_size: 1:每个device上验证的batch_size ● eval_strategy: steps,eval_steps: 500:这两个参数结合起来是每500个step验证⼀次。
配置完成后,我们可以运⾏llamafactory-cli train命令直接开始训练,如果本地没有下载过预训练
模型,会⾃动下载模型,命令如下:
llamafactory-cli train ../code/llama_facroty_configs/glm4_full_sft.yaml

3.2.2、全量微调
### model
model_name_or_path: ZhipuAI/glm-4-9b-chat### method
stage: sft
do_train: true
finetuning_type: full
deepspeed: examples/deepspeed/ds_z3_config.json### dataset
dataset: huatuo
template: glm4
cutoff_len: 1024
max_samples: 100000
overwrite_cache: true
preprocessing_num_workers: 16### output
output_dir: /root/code/checkpoints/qwen
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-5
num_train_epochs: 1.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000### eval
val_size: 0.05
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
四、模型合并以及部署
4.1、模型合并
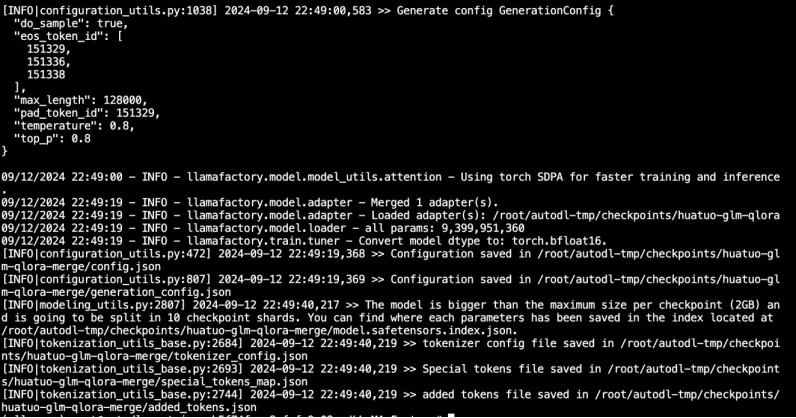
使⽤qlora/lora⽅式训练得到的checkpoints是lora部分的参数,如果部署模型的话,需要将lora部分的参数和base模型参数merge起来,llama-factory也提供了合并功能,配置⽂件(对应⽂件:llama_facroty_configs/glm4_lora_merge.yaml):### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: ZhipuAI/glm-4-9b-chat
adapter_name_or_path: /root/autodl-tmp/checkpoints/huatuo-glm-qlora
template: glm4
finetuning_type: lora### export
export_dir: /root/autodl-tmp/checkpoints/huatuo-glm-qlora-merge
export_size: 2
export_device: cpu
export_legacy_format: false
在llama-factory主⽬录下运⾏以下命令(注意yaml配置⽂件的相对路径替换为⾃⼰服务器的路径)
llamafactory-cli export ../code/llama_facroty_configs/glm4_lora_merge.yaml
4.2、VLLM部署
VLLM部署配置文件
model_name_or_path: /root/autodl-tmp/checkpoints/huatuo-glm-qlora-merge
template: glm4
infer_backend: vllm
vllm_enforce_eager: true
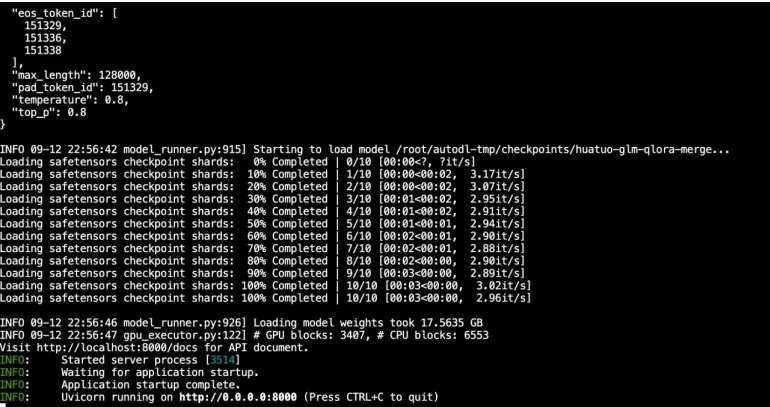
运⾏以下命令进⾏模型部署
API_PORT=8000 llamafactory-cli api ../code/llama_facroty_configs/glm4_lora_vllm.yaml
关于vllm openai调⽤⽅式参考这个的Blog