Kubernetes一Prometheus概述
前言:
在云原生和微服务架构中,可观测性已成为保障系统稳定性和快速故障排查的核心能力。Kubernetes的动态调度、弹性伸缩和分布式特性,使得传统的监控方式难以适应其快速变化的运行环境。Prometheus作为CNCF(云原生计算基金会)毕业项目,凭借其强大的时序数据存储、灵活的查询语言(PromQL)和与Kubernetes的深度集成,已成为容器化环境监控的事实标准。
本文档将深入探讨Kubernetes + Prometheus监控体系的架构设计、核心组件(如Prometheus Server、Alertmanager、Grafana等)的协同机制,以及如何利用Service Discovery自动发现监控目标、制定告警规则(Alerting Rules)和构建可视化仪表盘。通过该方案,运维团队可以实现从基础设施、Kubernetes集群到微服务的全栈监控,确保业务的高可用性和性能优化。
目录
1.1 时序数据定义与存储
1.2 数据采集方式
1.2.1 拉取方式(Pull-based)
1.2.2 推取方式(Push-based)与网关
1.3 服务发现与目标配置
1.4 监控平台设计思路
1.5 监控层面分类
1.6 数据来源与采集途径
1.7 核心组件架构
1.7.1 工作原理图
1.8 告警机制
1.8.1 告警组件
1.8.2 告警优化
1.9 可视化工具Grafana
1.10 PromQL查询语言
总结
1.1 时序数据定义与存储
时序数据是在一段时间内通过重复测量而获得的观测值的集合。这种数据需要存储在专门的时序数据库中,普罗米修斯内置了一个时序数据库用于存储时序数据。普罗米修斯本身就是一个时序数据库,其数据格式以键值对形式组织,类似于Elasticsearch的结构。
1.2 数据采集方式
1.2.1 拉取方式(Pull-based)
普罗米修斯基于拉取方式采集时序数据。在这种模式下:
-
客户端运行一个数据收集工具(如exporter),将本地数据收集并暂存。
-
普罗米修斯服务器主动从客户端拉取数据,而不是客户端推送。
-
优势:客户端无需复杂配置,只需部署exporter,所有配置集中在服务器端完成。
1.2.2 推取方式(Push-based)与网关
默认情况下,普罗米修斯使用拉取方式,但也支持推取方式:
-
推取方式需要中间组件Push Gateway。
-
数据流向:客户端 → Push Gateway → 普罗米修斯服务器。
-
优点:数据不中断,exporter持续工作并将数据暂存,直到连接恢复。
1.3 服务发现与目标配置
普罗米修斯支持两种目标发现方式:
-
静态配置:手动指定监控目标地址和端口。
-
服务发现:自动发现服务实例,例如在Kubernetes环境中动态识别Pod。
1.4 监控平台设计思路
运维监控平台需分层设计,实现多维度监控。层次结构如下:
-
数据收集层:监控不同应用的数据源。
-
动态展示层:生成时序数据的曲线图。
-
定时采集层:周期性地采集数据。
-
告警规则层:设置阈值和告警策略。
-
事件分析层:实时记录告警事件并生成分析图表。
-
用户管理层:统一用户权限和集中监控视图。
1.5 监控层面分类
普罗米修斯支持多层面监控:
-
系统层面监控:CPU、内存、磁盘等硬件指标。
-
网络层面监控:网络流量、连接状态等。
-
中间件监控:数据库、消息队列等中间件状态。
-
应用层面监控:
-
白盒监控:直接暴露内部指标供采集。
-
黑盒监控:通过探针(如SNMP)动态监测,不影响应用运行。
-
-
业务层监控:衡量应用业务价值的指标,例如:
-
电商场景:QPS(每秒查询数)、DAU(日活用户数)、转化率。
-
接口指标:登录数、注册数、订单数、搜索量、支付量。
-
1.6 数据来源与采集途径
普罗米修斯支持三种数据采集途径:
-
Exporter:标准组件(如Node Exporter)暴露指标。
-
Push Gateway:用于推取方式的数据中转。
-
自定义工具:用户自研工具,只要输出数据满足普罗米修斯格式即可被识别。
1.7 核心组件架构
普罗米修斯系统包含以下核心组件:
-
服务器(Server):主服务,负责数据拉取、存储和查询。
-
存储网关(Storage Gateway):扩展存储能力。
-
告警组件(Alertmanager):处理告警规则和通知。
-
服务发现(Service Discovery):动态识别监控目标。
-
客户端库(Client Libraries):集成到应用中以暴露指标。
1.7.1 工作原理图
普罗米修斯工作流程如下:
-
Exporter或Push Gateway收集数据。
-
数据经过处理组件(如Trio)预处理。
-
处理后的数据存入时序数据库(TSDB)。
-
用户可通过Web UI或API查询数据,或通过Grafana可视化。
-
告警触发时,数据推送至Alertmanager。
1.8 告警机制
1.8.1 告警组件
普罗米修斯本身不提供告警功能,依赖Alertmanager实现。告警流程:
-
普罗米修斯检测阈值违规,触发告警事件。
-
事件推送至Alertmanager。
-
Alertmanager通过邮件、钉钉或电话通知用户。
1.8.2 告警优化
为防止信息轰炸,需设置合理的告警间隔和阈值。告警规则通过配置文件定义,无需图形界面。
1.9 可视化工具Grafana
普罗米修斯的原生UI功能简陋,主要用于数据存储。Grafana是其核心可视化工具:
数据源支持:兼容普罗米修斯、Elasticsearch、MySQL、PostgreSQL等多种数据库。
仪表板功能:
预置模板(如Kubernetes集群监控仪表板)。
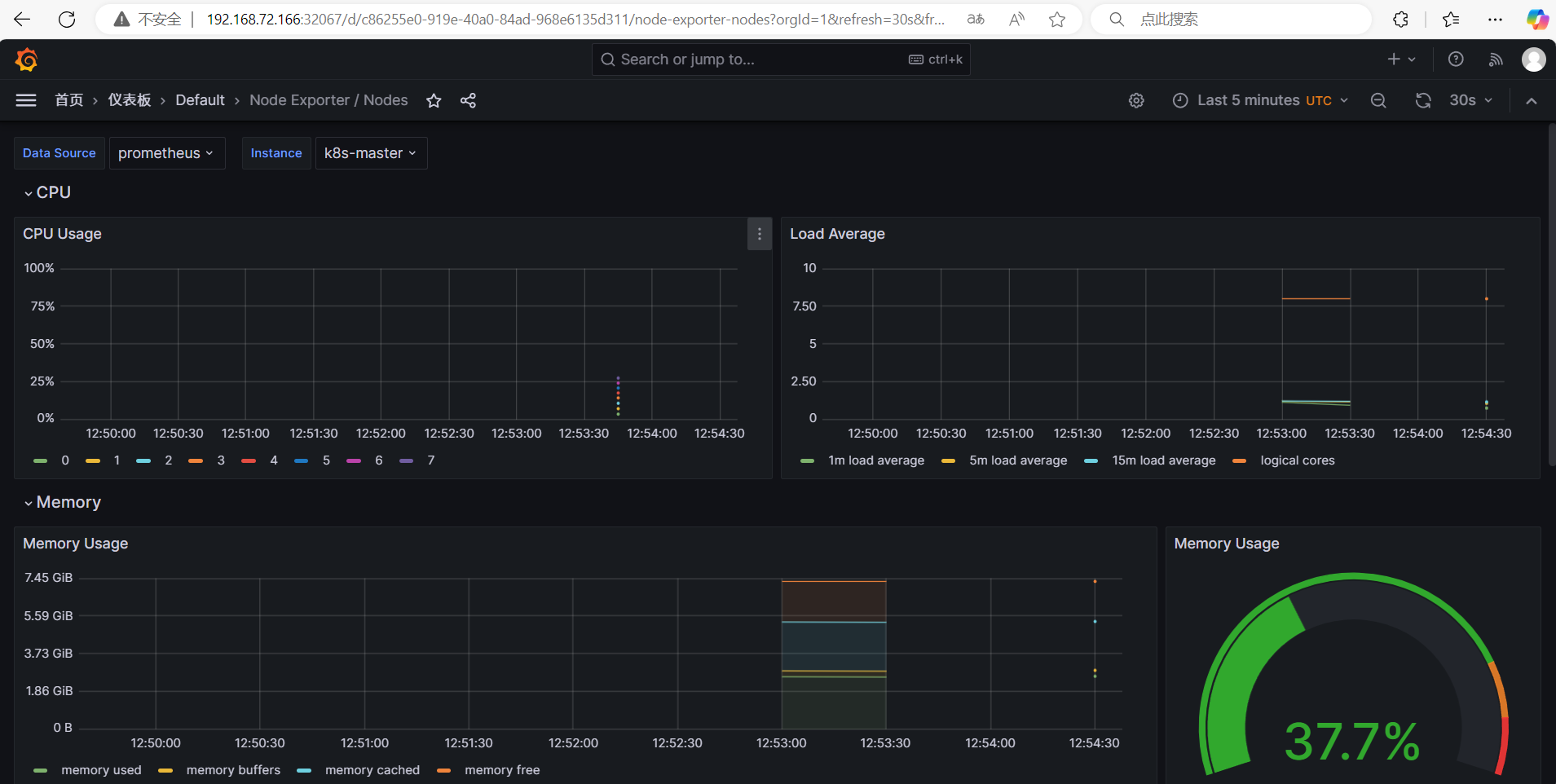
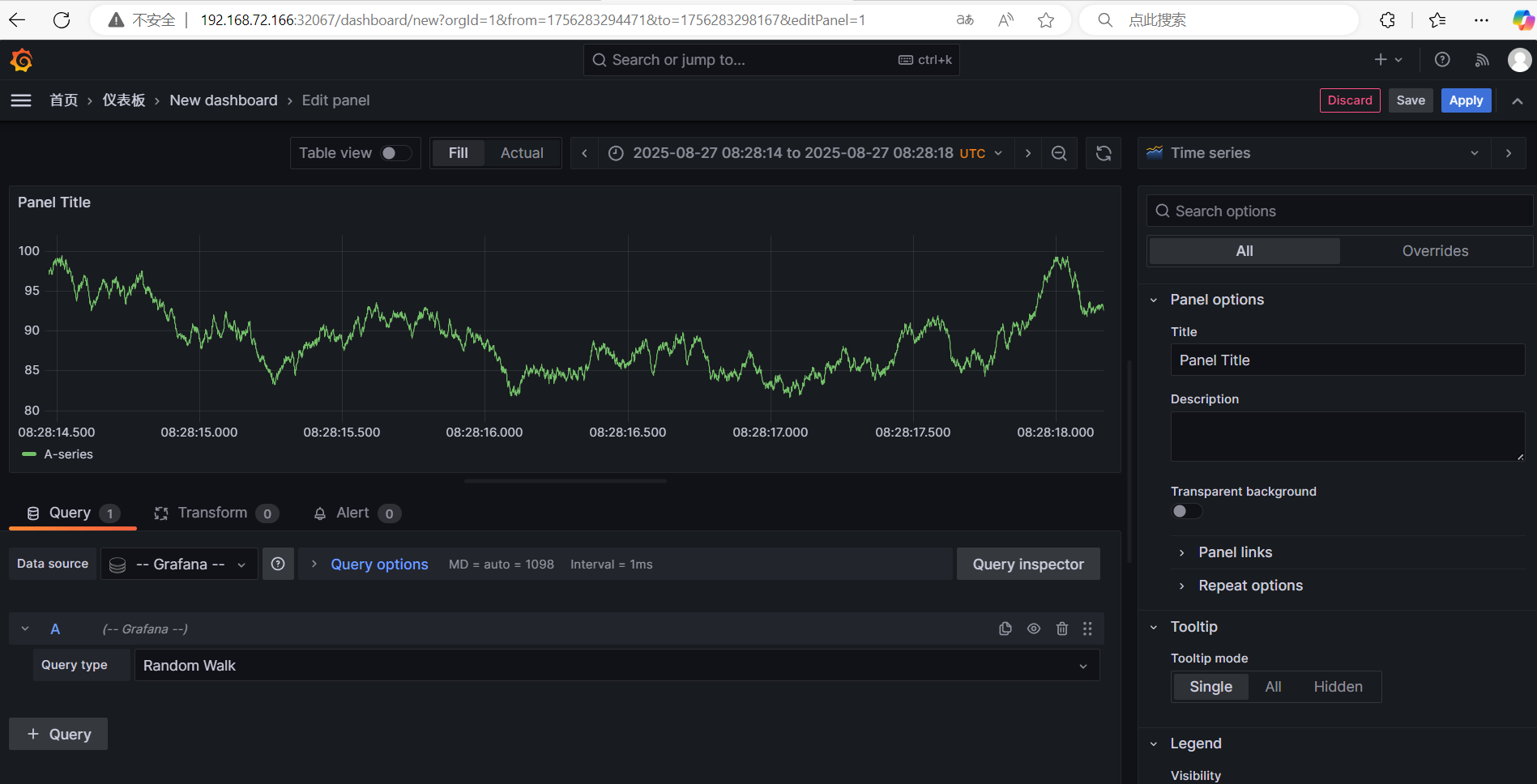
自定义视图:用户可创建图表并编写PromQL查询表达式。
告警集成:内置告警联络点配置,但通常与Alertmanager结合使用。
1.10 PromQL查询语言
普罗米修斯使用PromQL语言查询时序数据。特点包括:
-
语法类似SQL,但专注于时序数据处理。
-
支持函数操作(如
rate()计算速率)和偏移(如offset 5m获取五分钟前数据)。 -
复杂表达式需理解指标含义和函数用法。
总结:
Kubernetes与Prometheus的结合,为云原生环境提供了一套自动化、可扩展且高度集成的监控解决方案。该体系不仅能够实时采集集群指标(如CPU、内存、网络)、Kubernetes对象状态(如Pod、Deployment、Service),还能通过PromQL进行多维数据分析,帮助团队快速定位性能瓶颈和异常情况。
该监控架构的核心价值在于:
1.自动化发现与监控:利用Prometheus的Kubernetes服务发现机制,动态适应Pod的创建和销毁,无需手动配置监控目标。
2.高效存储与查询:Prometheus的时序数据库(TSDB)针对监控数据优化,支持高吞吐写入和快速查询,适用于大规模集群监控。
3.智能告警与可视化:通过Alertmanager实现多级告警(如邮件、Slack、Webhook),并结合Grafana构建直观的监控仪表盘,提升运维效率。
4.生态兼容性:支持与kube-state-metrics、Node Exporter等组件集成,覆盖从节点到应用的完整监控维度。
综上所述,Kubernetes + Prometheus监控体系不仅解决了传统监控工具在动态环境中的局限性,还通过强大的数据分析和告警能力,为运维团队提供了实时洞察和主动运维的能力,是保障云原生业务稳定性的关键基础设施。