【Tech Arch】Apache Flume海量日志采集的高速公路
Apache Flume是一个分布式、可靠且高可用的日志采集系统,专为收集、聚合和传输海量日志数据而设计。作为Apache软件基金会的顶级项目,Flume已成为大数据生态系统中不可或缺的组件,广泛应用于从Web服务器、应用服务器、数据库等系统中收集日志数据,并将其高效可靠地传输到HDFS、HBase、Kafka等存储或处理系统 。Flume的核心价值在于解决了分布式环境下日志数据的可靠传输问题,同时支持灵活的插件化扩展,使开发者能够根据需求定制数据采集流程。

一、Apache Flume的诞生背景
Flume最初由Cloudera公司的工程师团队于2010年左右开发,旨在解决海量日志数据的采集与传输难题。当时,随着Hadoop生态系统的日益成熟,企业面临如何将分散在不同节点的日志数据高效收集并传输到HDFS等存储系统的问题。传统方法如直接将日志文件传输到HDFS,存在数据丢失风险、无法处理突发流量以及缺乏统一管理等问题。为了解决这些挑战,Cloudera开发了Flume OG(Original Generation)版本,该版本基于分布式架构,包含Agent、Collector和Master三种角色,通过ZooKeeper实现配置同步和协调 。
然而,随着大数据技术的快速发展和应用场景的多样化,Flume OG版本逐渐暴露出一些局限性。OG版本架构复杂、依赖ZooKeeper、配置不够灵活,难以适应不断变化的业务需求 。为了解决这些问题,Cloudera在2011年对Flume进行了重大重构,推出了Flume NG(Next Generation)版本,并于2012年将其捐赠给Apache软件基金会 。NG版本移除了OG中的Master和Collector角色,简化了架构设计,提高了系统的灵活性和可扩展性。Flume NG通过轻量级设计和事务机制,实现了高可靠性的日志传输,成为大数据生态系统中日志收集的首选工具。
从OG到NG的演进过程中,Flume的核心定位始终是日志数据的采集和传输,但NG版本通过优化架构设计、简化配置方式和增强可靠性,使其更适合现代大数据环境的需求。这种演进反映了大数据技术从简单批处理向实时流处理、从单一系统向分布式生态系统的转变趋势。
二、Flume的架构设计
Apache Flume采用分层架构设计,其核心组件包括Agent、Source、Channel和Sink,这些组件共同构成了一个高效可靠的分布式日志采集系统。
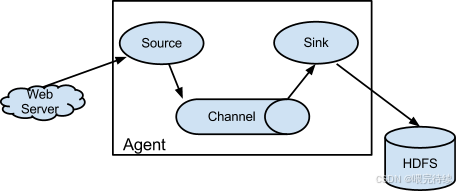
Agent是Flume的基本执行单元,每个Agent都是一个独立的Java进程,负责从数据源收集数据并将其传输到目标系统。在NG版本中,Agent取代了OG版本中的Agent、Collector和Master三种角色,成为唯一的核心组件 。这种简化设计降低了系统的复杂度,提高了部署和管理的便捷性。
每个Agent由三个关键组件构成:
| 组件 | 功能描述 | 主要类型 |
|---|---|---|
| Source | 负责接收数据或通过特殊机制产生数据 | Exec、Taildir、Netcat、HTTP、Avro等 2 |
| Channel | 作为缓冲区,临时存储来自Source的数据 | Memory、File、JDBC、Kafka等 |
| Sink | 负责将数据从Channel中取出并发送到目标系统 | HDFS、HBase、Kafka、Null等 2 |
Source组件负责从各种数据源接收数据,如文件系统、网络套接字、命令行输出等。根据数据源类型的不同,Flume提供了多种Source实现,包括:
- Exec Source:通过执行命令行获取数据,常用于监控日志文件变化
- Taildir Source:类似Unix的tail -F命令,持续监控指定目录下的文件变化
- Netcat Source:监听TCP/UDP端口,接收网络传输的数据
- HTTP Source:接收HTTP POST请求发送的数据
- Avro Source:接收来自其他Flume Agent或Avro客户端的数据
Channel组件位于Source和Sink之间,作为数据的缓冲区,确保数据在传输过程中的可靠性 。Flume提供了多种Channel实现,每种实现有不同的性能和可靠性特点:
- Memory Channel:将数据存储在内存中,性能高但可靠性低,系统崩溃会导致数据丢失
- File Channel:将数据存储在磁盘上,基于预写式日志(Write-Ahead Logging, WAL)实现持久化,可靠性高但性能较低
- JDBC Channel:将数据存储在关系型数据库中,可靠性高但性能受数据库影响
- Kafka Channel:将数据存储在Kafka消息队列中,结合了高性能和高可靠性
Sink组件负责将数据从Channel中取出并发送到目标系统。Flume支持多种Sink实现,包括:
- HDFS Sink:将数据写入Hadoop分布式文件系统
- HBase Sink:将数据写入HBase分布式数据库
- Kafka Sink:将数据发送到Kafka消息队列
- Null Sink:用于测试,不实际存储数据
- Avro Sink:将数据发送到其他Flume Agent或Avro客户端
Flume的架构设计基于管道模式,数据以Event为基本单位流动 。Event是Flume内部数据传输的最小单位,通常对应于一行日志记录,包含数据体和可选的元数据头信息 。这种管道模式使得Flume能够灵活地构建复杂的数据流,支持多种数据源和目标系统的对接。
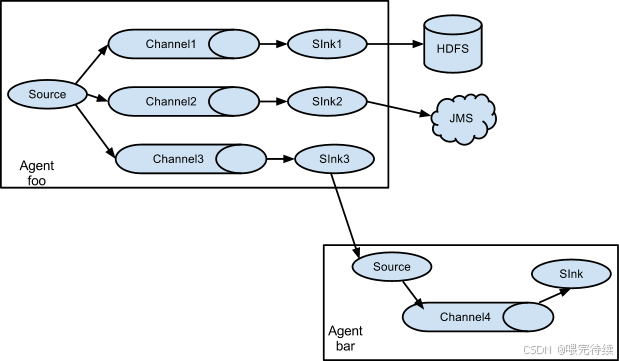
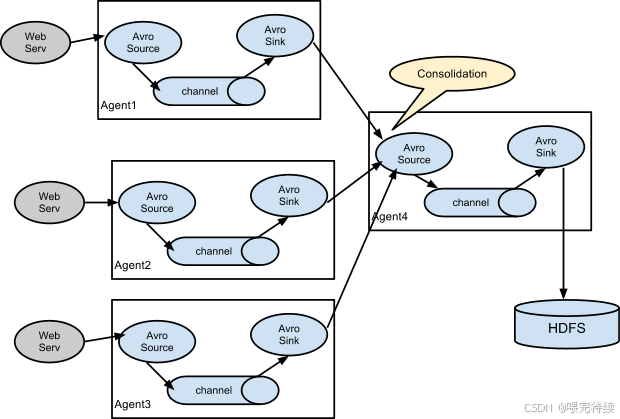
Flume的架构还支持多级Agent的级联配置,通过Avro协议实现Agent之间的通信。这种级联设计使得Flume能够构建分布式的数据采集网络,实现负载均衡和故障恢复。在级联配置中,一个Agent的Sink可以将数据发送到另一个Agent的Source,形成数据流的传递链。

三、Flume解决的核心问题
Apache Flume专为解决分布式环境下的日志采集与传输问题而设计,主要解决了以下核心挑战:
1. 分布式环境下的日志收集难题
在现代分布式系统中,日志数据通常分散在多个节点上,传统方法如直接复制或使用脚本收集,难以保证数据的完整性和一致性。Flume通过分布式Agent网络,能够从多个节点同时收集日志数据,并将其聚合到中央存储系统,解决了这一难题。
2. 高可靠性数据传输
日志数据对于系统监控、故障排查和安全审计至关重要,因此必须保证数据传输的可靠性。Flume通过事务机制和持久化Channel,确保即使在系统故障或网络中断的情况下,数据也不会丢失。这种可靠性机制使得Flume在大规模分布式系统中能够稳定运行。
3. 处理突发流量
在分布式系统中,日志数据的产生速率可能波动较大,特别是在系统出现异常或高负载时。Flume的Channel机制能够缓冲突发流量,避免因数据生产速率超过消费速率而导致的数据丢失 。这种缓冲能力使得Flume能够在数据源和接收方速率不匹配的情况下,仍然保证数据的可靠传输。
4. 灵活的数据路由与处理
Flume支持通过拦截器(Interceptor)对数据进行简单处理,如添加元数据、过滤数据或修改数据格式 。同时,它还支持多路径流量、多管道接入和多管道接出,使得开发者能够根据日志类型、来源或内容,将数据路由到不同的处理路径。
5. 高可扩展性
随着业务规模的扩大,日志数据量也会不断增长。Flume通过水平扩展的架构设计,能够轻松应对数据量的增长。开发者可以通过添加更多的Agent或调整现有Agent的配置,提高系统的整体吞吐量和处理能力。
四、Flume的关键特性
Apache Flume凭借其独特的设计和实现,具备以下关键特性:
1. 事务机制保证可靠性
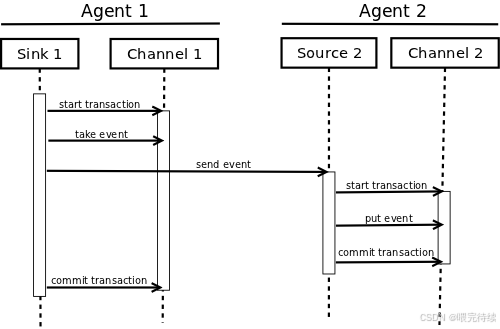
Flume的核心特性之一是其事务机制,通过Channel的缓存和提交/回滚操作,确保数据在传输过程中的可靠性。当数据从Source流入Channel时,会启动一个事务;数据从Channel流出到Sink时,会提交事务。如果数据在传输过程中失败,Channel会保留数据,直到传输成功。这种机制使得Flume能够在各种故障场景下保证数据不丢失。
对于File Channel,Flume采用预写式日志(WAL)技术,将数据先写入磁盘日志,再提交到Channel,确保即使在系统崩溃的情况下,数据也能恢复。而Memory Channel虽然不提供持久化保证,但通过事务机制确保数据在传输过程中的完整性。
2. 多种Channel类型适应不同场景
Flume提供了多种Channel实现,每种实现都有其独特的性能和可靠性特点,开发者可以根据具体需求选择适合的Channel类型:
- Memory Channel:适合对延迟敏感且数据量不大的场景,提供高吞吐量
- File Channel:适合对可靠性要求高的场景,即使系统崩溃也能恢复数据
- JDBC Channel:适合需要与数据库交互的场景,但性能受数据库影响
- Kafka Channel:适合需要与Kafka集成的场景,结合了高性能和高可靠性
3. 拦截器(Interceptor)实现数据处理
Flume允许在数据从Source到Sink的过程中,通过拦截器对数据进行处理 。拦截器可以添加元数据、过滤数据或修改数据格式,为后续的分析和处理提供便利。例如,可以使用TimestampInterceptor为每条日志添加时间戳,或使用HostInterceptor为日志添加来源主机信息。
Flume提供了多种内置拦截器,如:
- TimestampInterceptor:为Event添加时间戳
- HostInterceptor:为Event添加主机信息
- StaticInterceptor:为Event添加静态元数据
- RegexExtractorInterceptor:使用正则表达式提取日志中的特定字段
开发者也可以自定义拦截器,实现更复杂的处理逻辑 。
4. 多级Agent级联实现分布式采集
Flume支持多级Agent的级联配置,通过Avro协议实现Agent之间的通信。这种级联设计使得Flume能够构建分布式的数据采集网络,实现负载均衡和故障恢复。在级联配置中,一个Agent的Sink可以将数据发送到另一个Agent的Source,形成数据流的传递链。
这种级联架构使得Flume能够适应大规模分布式系统的需求,从数百个节点到数千个节点的日志数据收集。
5. 内置负载均衡与故障转移机制
Flume通过内建的负载均衡和故障转移机制,提高了系统的可用性。Channel和Agent都可以配置多个实体,实体之间可以使用负载分担等策略。一个Source可以连接到多个Channel,一个Channel也可以连接到多个Sink,从而实现负载均衡。当某个组件故障时,Flume能够自动将流量转移到其他可用组件,实现故障恢复。
五、Flume与同类产品对比
在大数据生态系统中,Apache Flume与Apache NiFi是两个常用的数据采集和传输工具,它们在功能定位、架构设计和使用场景上存在显著差异:
1. 功能定位对比
| 特性 | Flume | NiFi |
|---|---|---|
| 主要功能 | 专注于日志采集与传输 | 提供全面的数据流管理,包括采集、处理和传输 |
| 数据处理能力 | 基础数据处理,通过拦截器实现 | 强大的数据流处理能力,支持实时流处理、转换、过滤和路由 |
| 配置方式 | 通过文本配置文件定义数据流 | 提供可视化界面,通过拖拽组件构建数据流 |
| 社区活跃度 | 相对较为稳定,更新速度较慢 | 社区活跃度更高,更新和改进速度较快 |
2. 架构设计对比
Flume采用轻量级的Agent架构,每个Agent都是一个独立的Java进程,通过Source、Channel和Sink三个组件实现数据采集、缓冲和传输。Flume的架构设计简单但功能强大,特别适合日志数据的采集和传输 。
NiFi则采用更复杂的架构设计,包括FlowFile、Processor、Connection等多个组件,支持更复杂的流处理逻辑 。NiFi的架构设计更加灵活,适合需要复杂数据流处理的场景。
3. 适用场景对比
Flume最适用于以下场景:
- 大规模分布式系统的日志数据采集与传输
- 高吞吐量、低延迟的日志数据处理
- 与Hadoop生态系统组件(HDFS、HBase等)的集成
NiFi则更适用于以下场景:
- 需要复杂数据流处理的场景
- 多种数据源和目标系统的集成
- 实时数据流处理与分析
- 需要可视化界面构建和管理数据流的场景
4. 性能与可靠性对比
在性能方面,Flume通常能够提供更高的吞吐量,特别是在日志数据采集场景。Flume的批处理模式使其在处理大量日志数据时具有优势。而NiFi支持流处理模式,在低延迟场景下表现更好。
在可靠性方面,Flume通过事务机制和持久化Channel,提供了高可靠性的数据传输保证。NiFi也提供了类似的可靠性机制,但更侧重于数据流的整体管理。
六、Flume的安装与配置
Apache Flume的安装和配置相对简单,以下是基于最新版本的安装步骤:
1. 环境准备
安装Flume前,需要确保系统满足以下要求:
- Java 8或更高版本
- 2GB或更大的可用内存
- 磁盘空间根据数据量需求而定
2. 安装Flume
从Apache官网下载最新版本的Flume二进制包,解压并配置环境变量:
# 下载并解压Flume
wget https://dl.apache.org/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
tar -xzvf apache-flume-1.9.0-bin.tar.gz# 配置环境变量
echo 'export FLUME_HOME=/path/to/flume' >> ~/.bashrc
echo 'export PATH=$PATH:$FLUME_HOME/bin' >> ~/.bashrc
source ~/.bashrc3. 基本配置
Flume的配置文件采用Java属性文件格式,以下是简单的配置示例:
# 定义Agent组件
agent.sources = source1
agent.channels = channel1
agent.sinks = sink1# 配置Source
agent.sources.source1.type = exec
agent.sources.source1 command = tail -F /var/log/syslog
agent.sources.source1.channels = channel1# 配置Channel
agent.channels.channel1.type = memory
agent.channels.channel1.capacity = 10000
agent.channels.channel1.transactionCapacity = 1000# 配置Sink
agent.sinks.sink1.type = hdfs
agent.sinks.sink1.hdfs.path = hdfs://namenode:8020/logs/%Y-%m-%d
agent.sinks.sink1.hdfs.fileType = DataStream
agent.sinks.sink1.hdfs rollInterval = 300
agent.sinks.sink1.hdfs rollSize = 104857600
agent.sinks.sink1.hdfs rollCount = 10000
agent.sinks.sink1.channel = channel14. 启动与验证
启动Flume Agent并验证配置:
# 启动Agent
flume-ng agent -n agent -c $FLUME_HOME/conf -f $FLUME_HOME/conf/my-flume.conf -Dflume.root.logger=INFO,console# 验证数据是否写入HDFS
hdfs dfs -ls /logs七、Flume的使用方法与最佳实践
Apache Flume提供了多种使用方式,开发者可以根据具体需求选择合适的配置方案:
1. 单Agent简单配置
对于简单的日志采集场景,可以使用单个Agent的配置:
# 定义Agent组件
agent.sources = source1
agent.channels = channel1
agent.sinks = sink1# 配置Source
agent.sources.source1.type = taildir
agent.sources.source1.positionFile = /etc/flume/taildir_position.json
agent.sources.source1.filegroups = f1
agent.sources.source1.filegroups.f1 = /var/log/*.log
agent.sources.source1.channels = channel1# 配置Channel
agent.channels.channel1.type = file
agent.channels.channel1.dataDirs = /var/flume/channels/file-channel
agent.channels.channel1.checkpointDir = /var/flume/channels/file-channel-checkpoint
agent.channels.channel1.capacity = 1000000# 配置Sink
agent.sinks.sink1.type = hdfs
agent.sinks.sink1.hdfs.path = hdfs://namenode:8020/logs/%Y-%m-%d
agent.sinks.sink1.hdfs.fileType = DataStream
agent.sinks.sink1.hdfs rollInterval = 300
agent.sinks.sink1.hdfs rollSize = 104857600
agent.sinks.sink1.hdfs rollCount = 10000
agent.sinks.sink1.channel = channel12. 多级Agent级联配置
对于大规模分布式系统的日志采集,可以使用多级Agent的级联配置:
# Agent1配置(数据收集节点)
agent1.sources = source1
agent1.channels = channel1
agent1.sinks = sink1agent1.sources.source1.type = taildir
agent1.sources.source1.positionFile = /etc/flume/taildir_position.json
agent1.sources.source1.filegroups = f1
agent1.sources.source1.filegroups.f1 = /var/log/*.log
agent1.sources.source1.channels = channel1agent1.channels.channel1.type = memory
agent1.channels.channel1.capacity = 10000
agent1.channels.channel1.transactionCapacity = 1000agent1.sinks.sink1.type = avro
agent1.sinks.sink1.channel = channel1
agent1.sinks.sink1.port = 4545# Agent2配置(数据汇聚节点)
agent2.sources = source1
agent2.channels = channel1
agent2.sinks = sink1agent2.sources.source1.type = avro
agent2.sources.source1渠道 = channel1
agent2.sources.source1.bind = 0.0.0.0
agent2.sources.source1.port = 4545agent2.channels.channel1.type = file
agent2.channels.channel1.dataDirs = /var/flume/channels/file-channel
agent2.channels.channel1.checkpointDir = /var/flume/channels/file-channel-checkpoint
agent2.channels.channel1.capacity = 1000000agent2.sinks.sink1.type = hdfs
agent2.sinks.sink1.hdfs.path = hdfs://namenode:8020/logs/%Y-%m-%d
agent2.sinks.sink1.hdfs.fileType = DataStream
agent2.sinks.sink1.hdfs rollInterval = 300
agent2.sinks.sink1.hdfs rollSize = 104857600
agent2.sinks.sink1.hdfs rollCount = 10000
agent2.sinks.sink1.channel = channel13. 拦截器配置
在日志采集过程中,可以使用拦截器对数据进行处理:
# 配置拦截器
agent.sources.source1.interceptors = i1 i2
agent.sources.source1.interceptors.i1.type = timestamp
agent.sources.source1.interceptors.i2.type = host
agent.sources.source1.interceptors.i2preserveExisting = true4. 与Kafka集成
Flume可以与Kafka集成,将日志数据发送到Kafka消息队列:
# 配置Kafka Sink
agent.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.sink1.kafka.bootstrap.servers = broker1:9092,broker2:9092
agent.sinks.sink1.kafka话题 = flume_logs
agent.sinks.sink1.kafka flumeBatchSize = 20
agent.sinks.sink1.kafka.producer.acks = 0
agent.sinks.sink1.kafka.producer.compression.type = snappy
agent.sinks.sink1.channel = channel15. 与HBase集成
Flume也可以直接将日志数据写入HBase:
# 配置HBase Sink
agent.sinks.sink1.type = hbase
agent.sinks.sink1.hbase.table.name = logs_table
agent.sinks.sink1.hbase柱族.name = column族1
agent.sinks.sink1.hbase row.key = %host%
agent.sinks.sink1.hbase资格 = %time%
agent.sinks.sink1.hbase.value = %body%
agent.sinks.sink1.hbase.zookeeper地址 = zookeeper1:2181,zookeeper2:2181
agent.sinks.sink1.channel = channel1八、Flume的最佳实践
1. 配置合适的Channel类型
根据应用场景的需求,选择合适的Channel类型:
- 对于对可靠性要求高的场景,选择File Channel或JDBC Channel
- 对于对性能要求高的场景,选择Memory Channel
- 对于需要与Kafka集成的场景,选择Kafka Channel
2. 优化Channel容量
根据数据流量的大小,合理设置Channel的容量参数:
agent.channels.channel1.capacity = 100000
agent.channels.channel1.transactionCapacity = 100003. 使用多路径路由
通过多路径路由,将不同类型的日志数据路由到不同的处理路径:
agent.sources.source1.interceptors = i1
agent.sources.source1.interceptors.i1.type = regex_extractor
agent.sources.source1.interceptors.i1 regex = (\\d+\\.\\d+\\.\\d+\\.\\d+)\\s+(\\S+)\\s+(\\S+)\\s+(\\[.+]\\)\\s+(\\d+)\\s+(\\d+)\\s+(.+.+)
agent.sources.source1.interceptors.i1 serializers = s1 s2 s3 s4 s5 s6 s7
agent.sources.source1.interceptors.i1 serializers.s1.name = client_ip
agent.sources.source1.interceptors.i1 serializers.s2.name = log_level
agent.sources.source1.interceptors.i1 serializers.s3.name = timestamp
agent.sources.source1.interceptors.i1 serializers.s4.name = log_message4. 实现负载均衡
通过配置多个Sink和负载均衡策略,提高系统的整体吞吐量:
agent.sources.source1.channels = c1 c2
agent.sources.source1.channel.selector.type = multiplexing
agent.sources.source1.channel.selector header = log_type
agent.sources.source1.channelselector.headers.log_type.info = c1
agent.sources.source1.channelselector.headers.log_type.error = c25. 监控与调优
定期监控Flume Agent的运行状态,根据监控结果进行调优:
# 查看Agent状态
flume-ng agent -n agent -c $FLUME_HOME/conf -f $FLUME_HOME/conf/my-flume.conf status九、Flume的典型应用场景
1. 大规模Web服务器日志采集
在拥有数百或数千Web服务器的大型网站中,Flume可以部署在每个Web服务器上,收集访问日志、错误日志等,并将这些日志聚合到中央存储系统,供后续分析和处理 。
2. 分布式应用系统的日志监控
在微服务架构的分布式应用系统中,Flume可以收集各个服务节点的日志,实现统一监控和故障排查。通过配置适当的拦截器,可以为日志添加服务名称、实例ID等元数据,便于后续分析。
3. 数据库操作日志采集
在大型数据库系统中,Flume可以收集数据库的操作日志,如查询日志、错误日志等,为数据库性能优化和安全审计提供支持。
4. 物联网设备数据采集
在物联网应用中,Flume可以收集来自各种物联网设备的数据,如传感器数据、设备状态信息等,并将这些数据传输到大数据平台进行分析和处理。
5. 实时日志分析
Flume可以与实时计算框架(Kafka、Flink等)集成,将日志数据实时传输到分析系统,实现秒级响应的实时日志分析 。
十、Flume的未来发展趋势
随着大数据技术的不断发展,Apache Flume也在持续演进。未来的Flume可能会在以下方面取得进展:
1. 实时性增强
随着流处理技术的普及,Flume可能会增强其实时处理能力,提供更低的延迟和更高的吞吐量。
2. 更丰富的拦截器
Flume可能会引入更多内置拦截器,提供更强大的数据处理能力,减少对外部工具的依赖。
3. 更好的与云服务集成
随着云计算的普及,Flume可能会增强与各种云服务(AWS、Azure、阿里云等)的集成,提供更灵活的部署选项。
4. 更强大的监控和管理功能
Flume可能会引入更完善的监控和管理功能,提供更直观的界面和更丰富的指标,便于运维人员管理和优化系统。
5. 更好的与实时计算框架集成
随着实时分析需求的增长,Flume可能会增强与Flink、Spark Streaming等实时计算框架的集成,提供更无缝的数据流处理体验。
文末
Apache Flume作为分布式日志采集系统的代表,凭借其简洁的架构设计、强大的可靠性机制和灵活的插件化扩展,已成为大数据生态系统中不可或缺的组件。Flume通过Agent、Source、Channel和Sink的协同工作,实现了从各种数据源到目标系统的高效可靠数据传输。
在实际应用中,开发者可以根据具体需求选择合适的配置方案,从简单的单Agent配置到复杂的多级Agent级联网络。通过合理配置拦截器和Channel类型,可以满足不同场景下的数据处理和可靠性需求。
随着大数据技术的不断发展,Flume也在持续演进,未来可能会在实时性、数据处理能力和云服务集成等方面取得更多进展。对于需要构建分布式日志采集系统的开发者来说,Flume仍然是一个值得信赖的选择。
通过本文的全面解析,希望读者能够深入理解Apache Flume的架构设计和工作原理,掌握其配置和使用方法,并在实际项目中应用这一强大的日志采集工具。