BEVDepth
1. 算法动机及开创性思路
1)BEVDepth算法动机
- 核心目标:解决现有方法深度估计不可靠的问题,通过引入深度监督和相机参数来提升深度预测准确性
- 创新点:首次在BEV感知任务中引入显式深度监督信号,并设计轻量级网络结构
2)2D到3D的映射方法
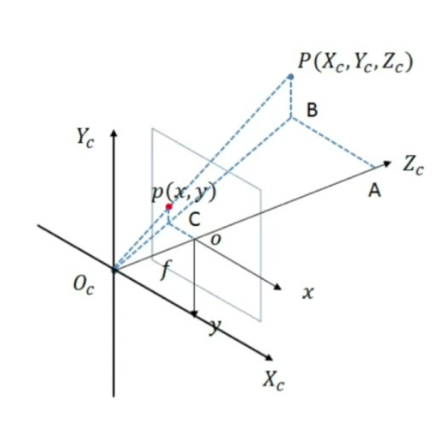
- 离散深度分布:将射线划分为多个深度网格,预测像素点落在各深度段的概率分布(如LSS方法)
- 连续深度估计:直接预测像素点的确定深度值(如伪点云方法)
- 投影原理:已知相机内参P、外参矩阵和2D像素坐标p(x,y),通过深度值d可唯一确定3D点P(Xc,Yc,Zc)
3)现有方法的缺点
- 监督缺失:缺乏明确的深度监督信号,网络难以学习准确的深度感知
- 参数利用不足:深度子网络未能充分利用相机内外参数,影响深度推断精度
- 效率问题:基于伪点云的方法需要额外深度估计网络,计算开销大
4)BEVDepth的预测与LSS结构的对比
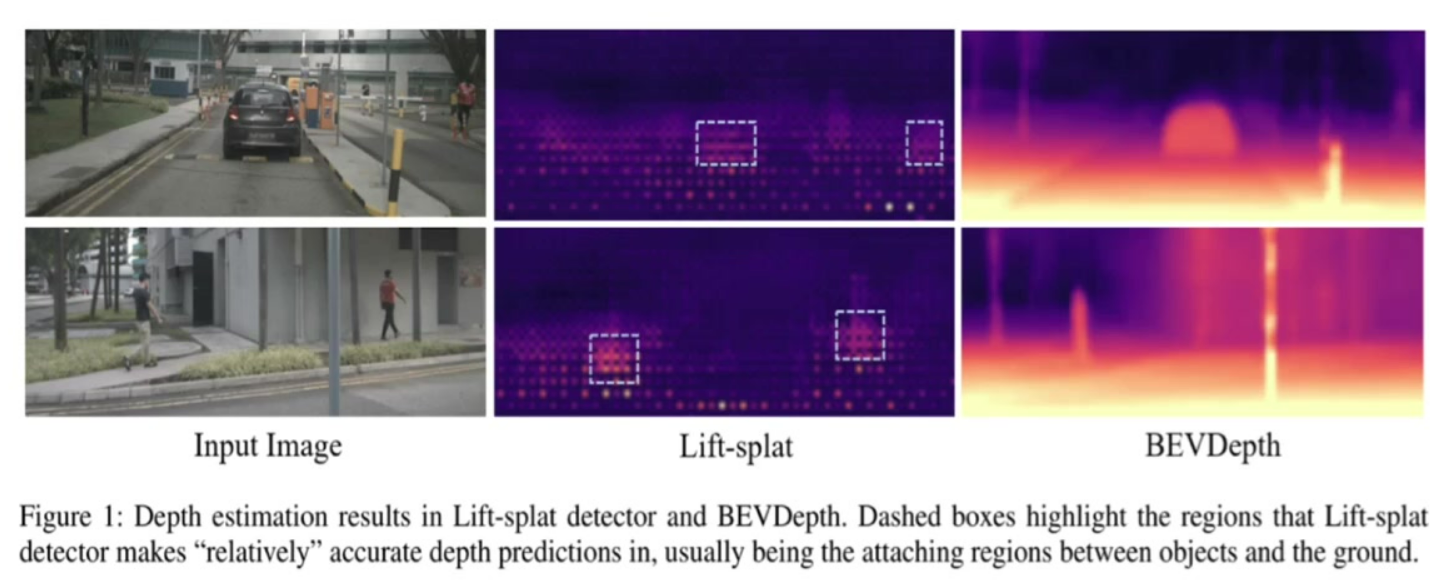
可视化优势:BEVDepth的深度图更连续清晰,能明显区分前景物体(如车辆、行人)轮廓
监督效果:LSS仅在物体与地面接触区域预测相对准确,而BEVDepth整体预测更可靠
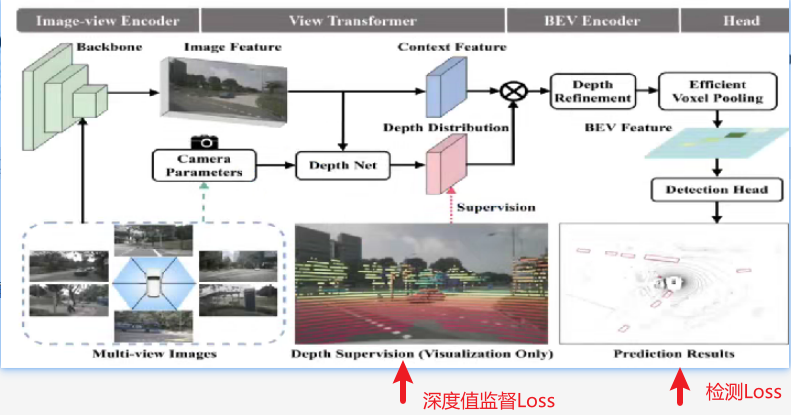
2. 主体结构
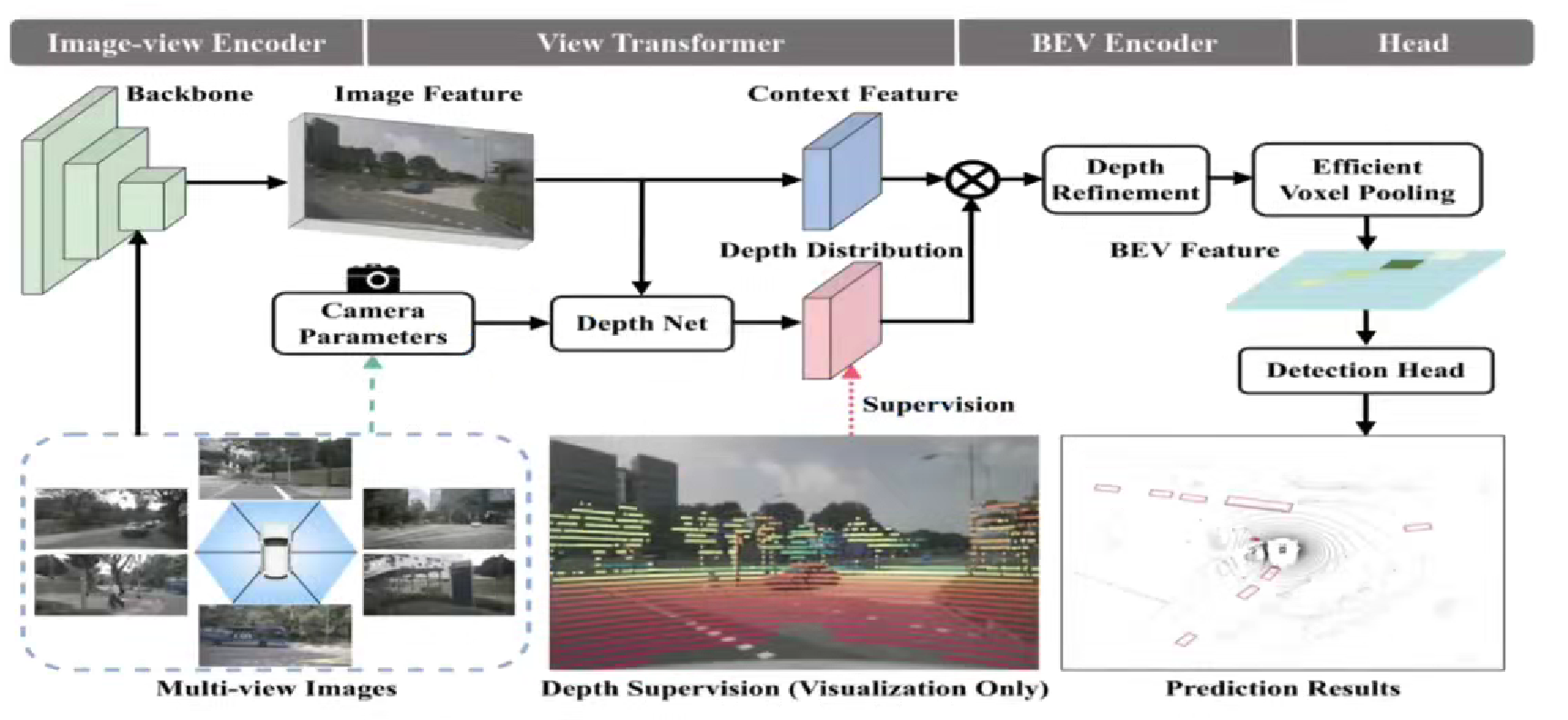
1)图像编码器设计流程
- 输入输出:多视角图像→2D Backbone→图像特征
- 实现方式:可采用ResNet、Swin Transformer等主流Backbone,支持多尺度特征金字塔
2)视角转换设计流程
- 深度估计模块设计流程
-
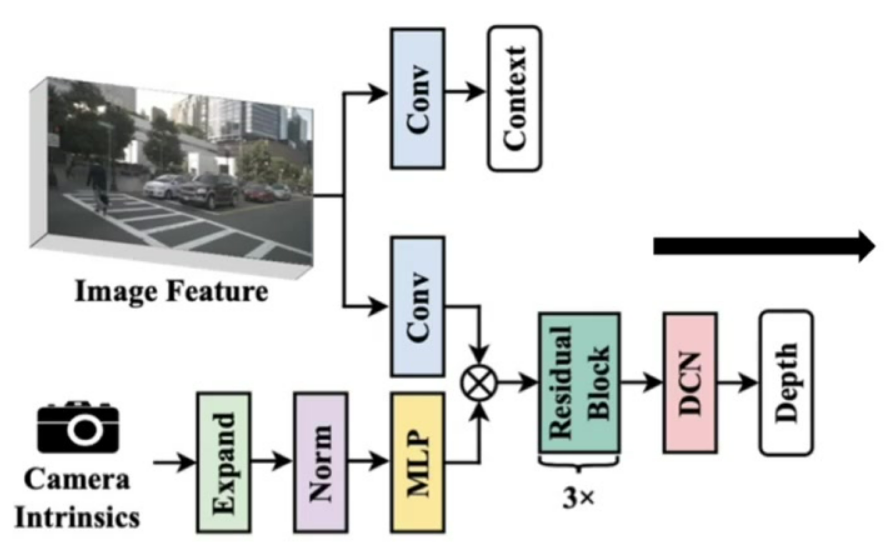
双路输入:
图像特征:通过常规卷积处理
相机参数:通过MLP扩展维度实现特征化 -
核心机制:
通道注意力:相机参数作为权重对图像特征通道加权
残差连接:保持特征表达能力
DCN操作:增强空间适应性 -
监督信号:利用激光雷达点云投影提供像素级深度真值
-
参数处理:将低维相机参数扩展到与图像特征通道相同维度
-
效率优化:整体网络设计轻量,避免引入过大计算负担
-
3)BEV特征编码设计流程
-
深度修正:通过Refinement网络校正外参扰动带来的深度偏差
-
高效体素池化:
- 传统方式:顺序处理各视锥特征
- 优化方案:为每个视锥分配CUDA线程并行处理
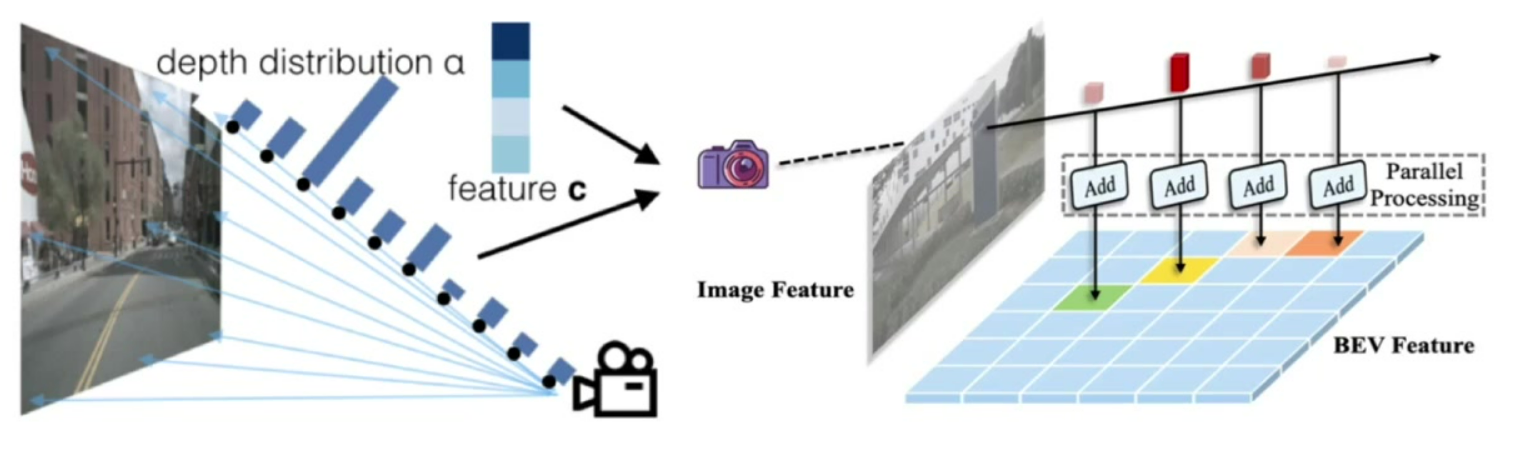
-
加速原理:并行化处理所有BEV网格特征,实测可加速3倍
-
实现细节:保持特征加和操作的一致性,确保映射精度不受影响
3. 损失函数
- 组成模块:包含深度估计损失和3D预测损失两个部分
- 监督信息:深度监督信息效果显著,使用ground truth替换后mAP从28.2提升至47.0(提升近20个点)
- 随机替换实验:
将学习到的离散深度分布替换为随机量(soft随机含中间值/hard随机为one-hot编码)
性能仅小幅下降(soft随机:28.2→24.5;hard随机:28.2→22.4)
4. 性能对比
1)整体性能
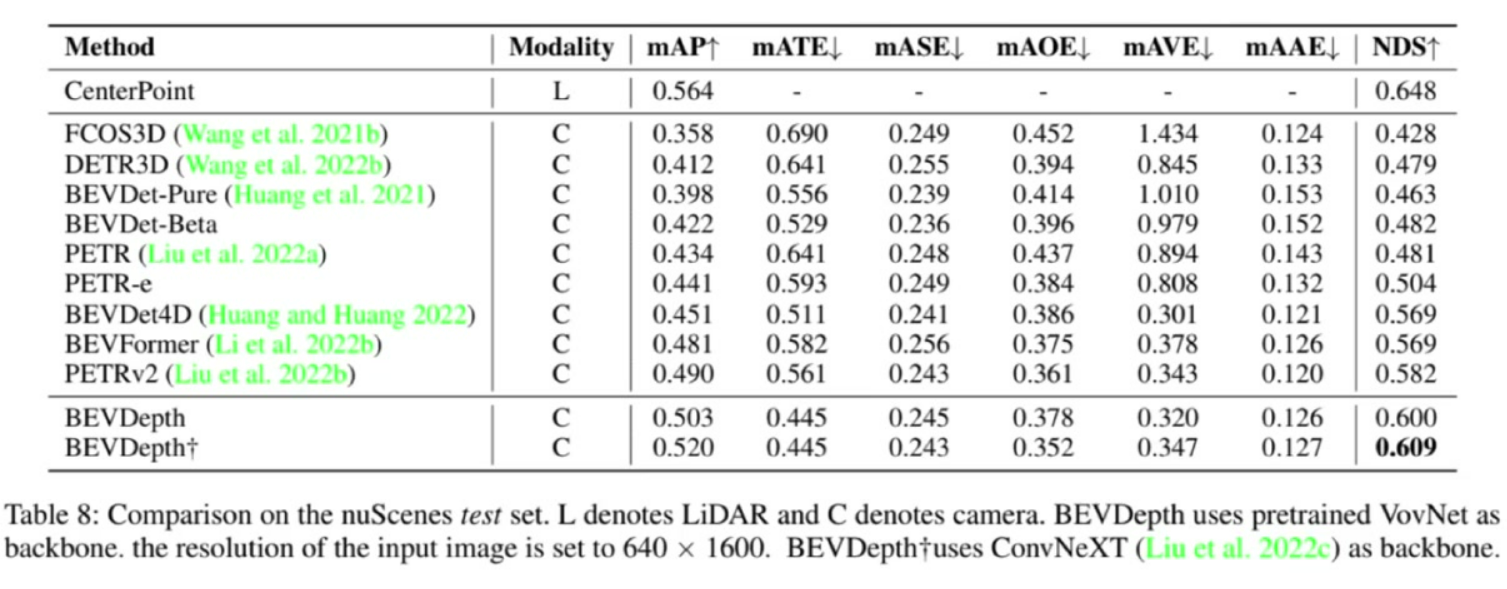
- 最佳表现:BEVDepth达到mAP 0.520,NDS 0.609
- 输入配置:使用640×1600分辨率,VovNet+ConvNeXT双主干网络
2)消融实验
-
模块有效性验证
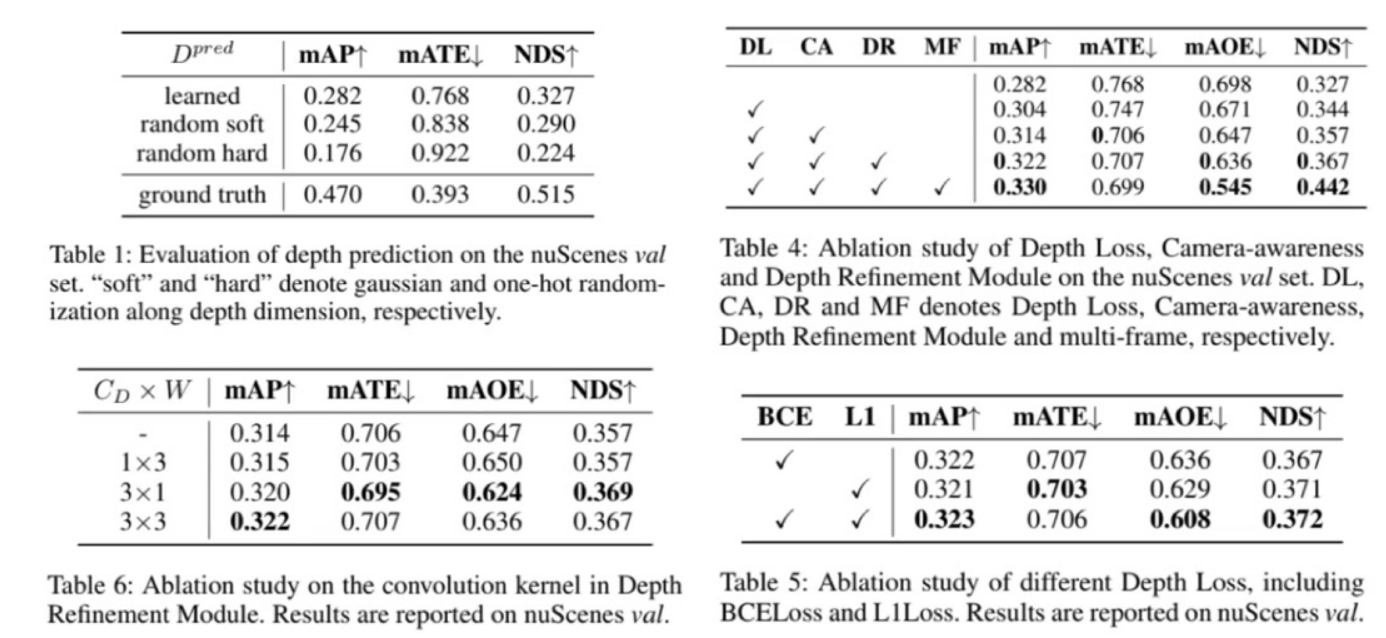
- 关键模块:
DL(Depth Loss):深度监督模块
CA(Camera-awareness):引入相机参数的深度监督
DR(Depth Refinement):深度值校正模块
MF(Multi-frame):时序信息模块 - 性能增益:完整配置(√√√√)达到mAP 0.330,相比baseline提升4.8个点
- 关键模块:
-
深度校正模块优化
- 卷积核选择:3×3卷积性能最优(mAP 0.322)
- 损失函数对比:BCE+L1组合效果最佳(mAP 0.323)
3)鲁棒性分析
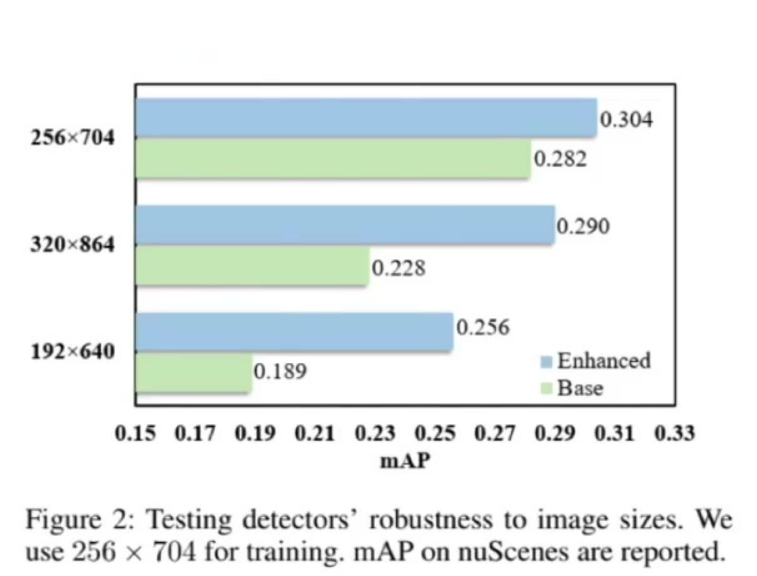
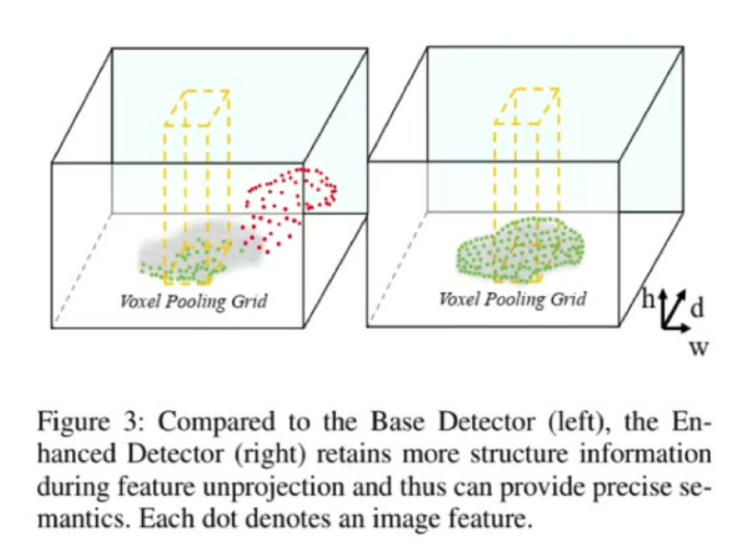
- 训练配置:固定训练尺寸256×704
- 测试表现:
同尺寸测试:BEVDepth(30.4) vs Base Detector(28.2)
小尺寸测试(192×640):BEVDepth(25.6) vs Base Detector(18.9) - 可视化对比:传统方法投影点误差显著(红色区域),BEVDepth投影位置准确(绿色区域)