KDD 2025 | CMA:一次训练,预测任意过去与未来!元学习+扩散模型颠覆时序预测!
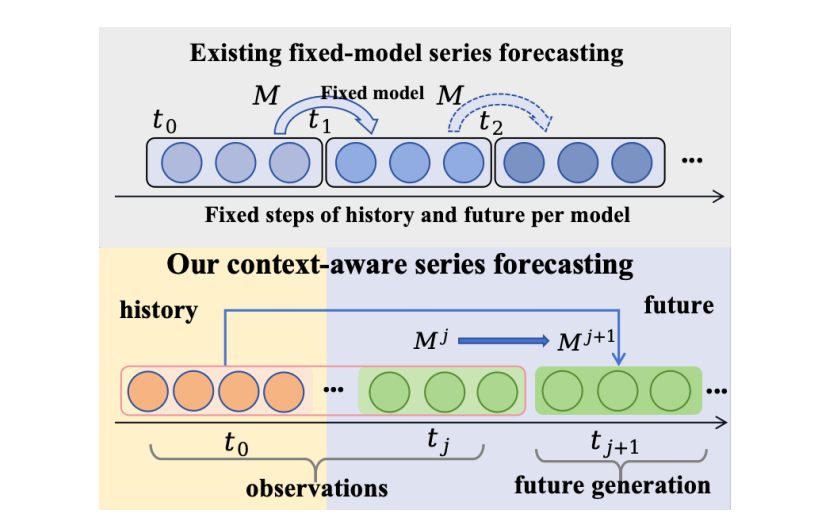
经典的时间序列预测方法依赖于从固定的历史窗口中学习并向固定的未来范围进行推断,这限制了它们在处理不同长度历史或未来范围任务时的灵活性和有效性,并且每种设置都需要重新训练。
为解决此问题,本文提出了上下文元自适应(Contextual Meta-Adaptation, CMA),一种统一的方案,通过单次训练即可捕获并适应变化的上下文。CMA融合了去噪扩散过程(denoising diffusion process),能够以最大似然方式序列化地生成未来序列,并与已观测的历史保持一致。挑战在于如何高效地使模型适应不断变化的上下文。
本文的方法是开发一种基于梯度的元学习(meta-learning)策略,在训练时进行全参数调优,在测试时则采用高效的低秩测试时自适应(Low-Rank Test-Time Adaptation, LoRTA)。这项工作的核心贡献在于提供了一个统一的框架,该框架将持续学习和测试时自适应通过元学习驱动的扩散过程结合起来,实现了在上下文内学习(in-context learning)、**扩展上下文学习(ex-context learning)和跨上下文学习(cross-context learning)**三种场景下的高性能预测,同时保持了主干模型的灵活性和计算效率。
另外,我整理了2025 KDD 时间序列相关论文+源码,感兴趣的可以dd哦~
论文这里
一、论文基本信息

基本信息
- 论文标题:CMA: A Unified Contextual Meta-Adaptation Methodology for Time-Series Denoising and Prediction
- 作者:Haiqi Jiang, Ying Ding, Chenjie Pan, Aimin Huang, Rui Chen, Chenyou Fan
- 作者单位:South China Normal University, Hangzhou Rose Technology Co., Ltd
- 代码链接:https://github.com/FancyAI-SCNU/CMA_KDD_2025
- 论文链接:https://doi.org/10.1145/3711896.3736881
摘要精炼
本文旨在解决传统时间序列预测模型在处理可变长度历史和未来预测范围时的局限性,即模型架构僵化、需要为每个预测范围重新训练。为应对此挑战,论文提出了一个名为**上下文元自适应(CMA)**的统一框架。
该框架的核心技术贡献在于:
- 将去噪扩散过程与基于梯度的元学习相结合,通过一个迭代的“预测-适应”循环,使模型能够实时适应变化的上下文;
- 设计了高效的模型更新策略,训练时进行全参数微调,而在测试时采用轻量级的LoRTA,仅更新少量参数即可快速适应。
实验结果表明,在六个学术数据集上,CMA相较于现有方法平均提升了7%的性能;在四个真实的营销数据集上,性能提升高达16%。关键发现是,CMA框架通过单次训练即可有效处理多种上下文学习任务(如图1所示),显著优于需要针对特定范围进行训练的基线模型和现有的自适应方法。
二、研究背景与相关工作
研究背景
当前主流的时间序列预测方法,无论是自回归模型(如RNN、Transformer)还是非自回归模型(如扩散模型),通常都依赖于固定的历史输入长度和预设的未来预测范围。这种刚性结构使其难以应对真实世界数据的复杂性,例如非平稳模式、长期依赖和动态演化的数据分布。当预测任务的需求(如预测未来7天变为预测未来30天)发生变化时,这些模型往往需要重新训练,这在工业应用中是不切实际且成本高昂的。
因此,研究领域面临的核心挑战是:如何构建一个单一、灵活的模型,使其能够动态适应任意长度的历史观测数据,并能泛化到不同的未来预测范围,甚至在不同数据域之间进行迁移,而无需昂贵的再训练。
相关工作
该领域已有的解决方案主要分为几类:
- 基于季节性趋势分解的深度学习模型,如Autoformer和Fedformer,它们通过傅里叶变换或小波基显式分解序列;
- 时间序列生成模型,如TimeGAN和TimeGrad,它们利用GAN或扩散过程来合成新序列;
- 时间序列基础模型,如Moirai和TimesFM,它们展现了在不同设定下的零样本泛化能力。
此外,为了处理分布变化,研究者们探索了领域自适应(Domain Adaptation, DA)、**持续学习(Continual Learning)和测试时自适应(Test-Time Adaptation, TTA)**等技术。例如,CoTTA通过权重平均来适应非平稳的目标域。然而,这些方法要么仍受限于固定的预测范围,要么在持续适应过程中可能面临误差累积的问题。本文提出的CMA框架则通过将元学习与扩散过程统一起来,旨在更系统地解决上述所有挑战。
三、主要贡献与创新
- 统一框架的提出:首次将持续学习和测试时自适应通过一个由元学习驱动的扩散过程统一起来,创建了一个灵活的框架(见图2),提升了预测性能并确保了对不同主干模型的兼容性。
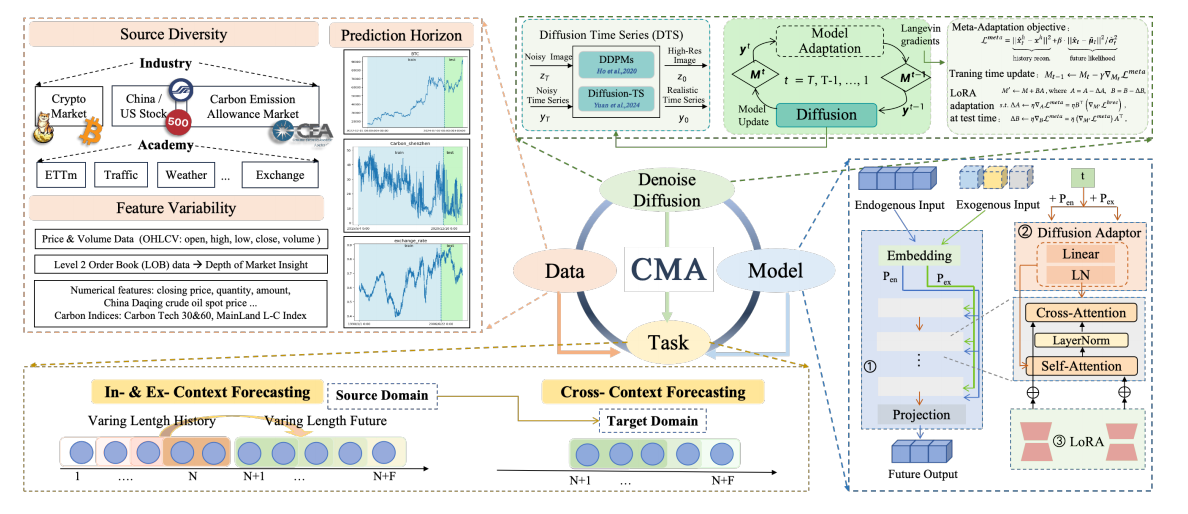
- 泛化能力:提出的CMA方案能够泛化到多种学习场景,包括处理可变历史长度的上下文内学习、灵活预测未来范围的扩展上下文学习,以及通过高效元学习方案实现的跨域适应。
- 高效的推理时自适应:在推理阶段实现了高效的LoRTA(低秩测试时自适应),与全参数微调相比,计算成本降低了98.8%,推理速度提升了27%。
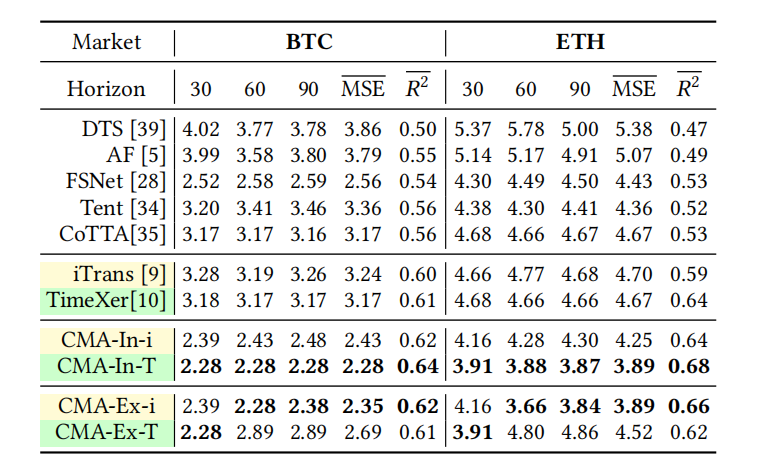
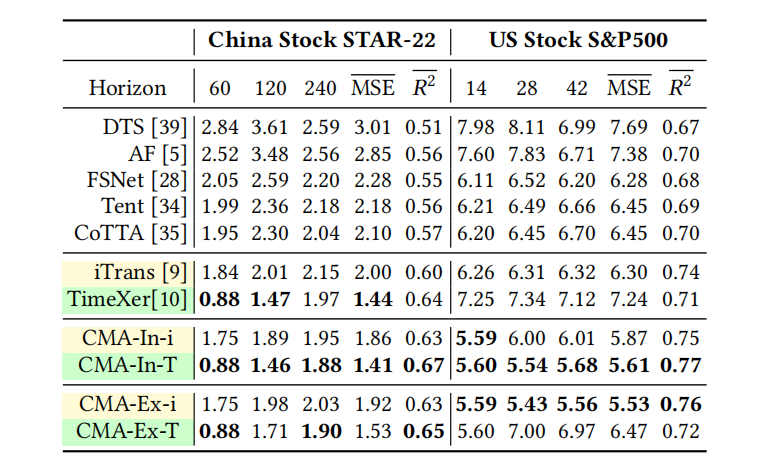
- 卓越的性能表现:在6个学术数据集上,性能平均提升7%;在4个金融市场数据集上,性能平均提升16%,取得了当前最优的成果,效果如表1、表2、表3所示。
四、研究方法与原理
总体框架与核心思想
本文提出的CMA(上下文元自适应)框架的核心思想是通过迭代式的“生成-适应”循环,使单一模型能够处理任意长度的历史和未来序列。这是一个统一了“序列生成”和“模型自适应”的过程。
其总体框架如图2所示,包含三个核心元素:
- 一个可插拔的生成器模块:在现有的时间序列模型(如TimeXer)中嵌入一个扩散适配器(Diffusion Adapter),使其具备按步去噪的能力,从而能够执行时间序列的生成和去噪任务。具体实现如图3所示。
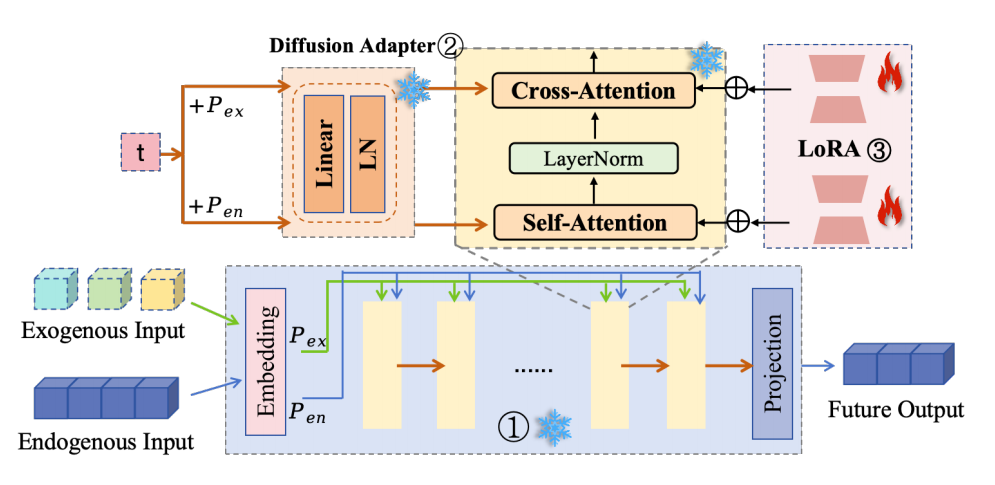
- 一个联合上下文学习流程:通过一个迭代循环(见算法1),模型交替执行两个动作——(1)基于当前观测到的历史数据去噪生成未来序列;(2)利用元学习更新自身参数以更好地拟合当前数据的模式。

- 一个高效的模型更新策略:在训练时进行全参数更新,在测试时则采用轻量化的LoRTA,实现了效率与性能的平衡。
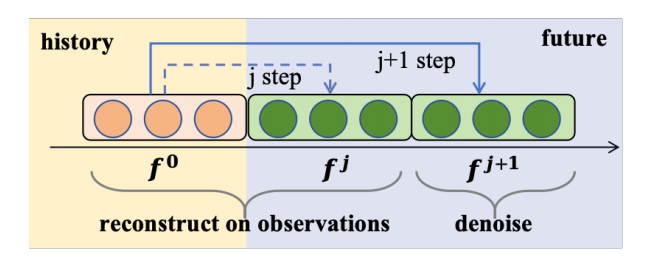
其核心创新在于,它不把模型看作是静态的,而是动态的,能够在每次预测中根据最新的上下文进行“微调”,从而持续捕获时序数据中的演化模式(如图4所示的扩展预测过程)。
关键实现与评估原理
关键实现细节:
- 元自适应损失函数:CMA过程的核心驱动力是一个元自适应损失函数
L_meta,它由两部分组成:观测重构损失和负对数似然。该损失确保生成序列与近期观测历史对齐,同时符合数据本身的分布。
Lmeta=∣∣x^ht−xh∣∣2+β⋅∣∣x^t−μ~t∣∣2/σ~t2\mathcal{L}_{meta} = ||\hat{\mathbf{x}}_h^t - \mathbf{x}_h||^2 + \beta \cdot ||\hat{\mathbf{x}}^t - \tilde{\boldsymbol{\mu}}_t||^2 / \tilde{\boldsymbol{\sigma}}_t^2 Lmeta=∣∣x^ht−xh∣∣2+β⋅∣∣x^t−μ~t∣∣2/σ~t2 - 迭代模型更新:在每个去噪步骤
t中,模型M根据L_meta进行梯度更新,从而实现对当前上下文的快速适应。
Mt−1←Mt−γ∇MtLmeta,∀t=T,T−1,…,1M_{t-1} \leftarrow M_t - \gamma \nabla_{M_t} \mathcal{L}_{meta}, \quad \forall t=T, T-1, \dots, 1 Mt−1←Mt−γ∇MtLmeta,∀t=T,T−1,…,1 - 训练与测试的非对称适应:训练阶段,采用全参数更新以充分学习数据域的内在模式。测试阶段,为实现高效率,仅更新附加的LoRA权重(LoRTA),预训练的主干参数保持冻结。LoRTA的秩
r被设为8,远小于隐藏层维度d=512。如表 9所示,LoRTA的性能与全参数微调(FPT)相当,但效率更高。
核心评估原理与指标:
- 评估原理:通过在多种上下文学习任务(上下文内、扩展上下文、跨上下文)中评估模型的预测精度,来衡量CMA框架的有效性和泛化能力。
- 评估指标:主要使用两个标准的时间序列预测指标:
- 均方误差(Mean Squared Error, MSE):衡量预测值与真实值之间的差异,值越小表示模型越准确。
- R²(决定系数):表示模型解释数据变异性的能力,值越接近1表示模型拟合效果越好。
五、实验结果与分析
实验设置
- 数据集: 6个学术数据集 (ETTm2, Electricity, Exchange, Traffic, Weather, ILI) 和 4个工业数据集 (CEA-Carbon, Crypto, STAR-22, USS&P500)。
- 评估指标: MSE (均方误差) 和 R² (决定系数)。
- 对比基线: 包括iTransformer (iTrans), TimeXer等SOTA预测模型,Diffusion-TS等生成模型,以及FSNet, Tent, CoTTA等在线学习/TTA方法。
- 关键超参: 元自适应损失中的权重
β=0.02,随机性控制因子η=1.0,自适应学习率γ=6.0×10⁻⁵,LoRTA的秩r=8。
核心实验与结论
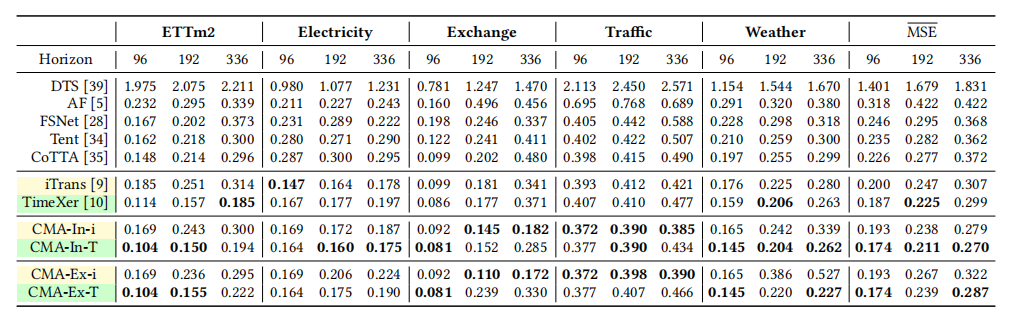
【核心实验:学术数据集上的上下文内学习(In-Context)与扩展上下文学习(Ex-Context)】 (见表1)
-
实验目的:
- 上下文内学习:验证CMA在适应比原始训练更长的历史序列时,能否提升预测精度。
- 扩展上下文学习:验证CMA能否使用一个在短预测范围(如96步)上训练的基础模型,直接泛化到更长的预测范围(如192步、336步),而无需重新训练。
-
关键结果:
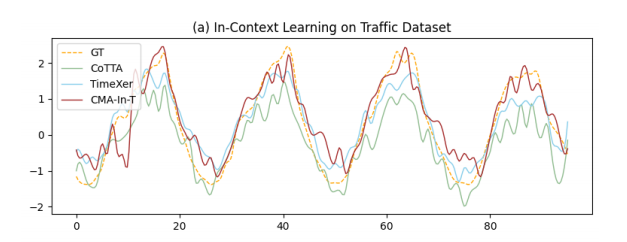
- 上下文内学习:表1显示,CMA-In-T(以TimeXer为骨干)在所有数据集和预测范围上均达到SOTA性能。与它的骨干模型TimeXer相比,在F96/192/336的预测任务上,MSE分别降低了7%、6%和10%,尤其是在更长的预测范围上改进更为显著。可视化结果如图5(a)所示,CMA能更准确地捕捉季节性模式。
2.扩展上下文学习:CMA-Ex-T使用F96的基础模型进行推理,在F336任务上,其性能比专门为F336训练的rimexer模型还要好4%(MSE 0.287 vs0.299)。图6显示,随着预测范围增加,CMA方法的性能(虚线)下降平缓,优于基线模型。
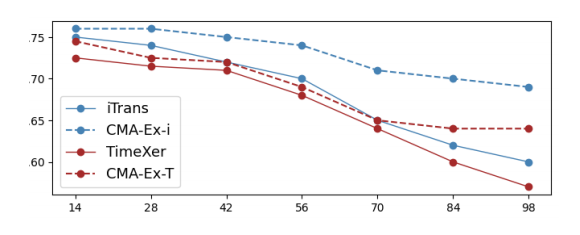
- 作者结论:
该实验证明了CMA框架的有效性。它不仅能通过适应更丰富的历史信息来提升模型性能(上下文内学习),还能让一个单一模型在无需重新训练的情况下,有效外推到任意长度的未来,显著超越了传统方法的“一任务一模型”范式,也优于现有的TTA方法。
六、论文结论与启示
总结
本文直面传统时间序列模型在处理动态、可变长度的预测任务时的僵化弊端,提出了一种名为CMA的统一上下文元自适应方法。该方法巧妙地将去噪扩散过程和元学习融合在一个迭代框架中,使模型能够在预测过程中持续地从当前数据中学习和适应。通过在训练时进行全参数优化,并在测试时采用高效的LoRTA,CMA在上下文内学习、扩展上下文学习和跨上下文学习三大场景中均取得了SOTA的性能,如表1-5所示。
实验结果有力地证明,CMA不仅提升了预测的准确性,更重要的是,它为时间序列预测提供了一个高度灵活、高效且泛化能力强的统一解决方案。
展望
根据论文的讨论,未来的研究方向可以集中于将CMA框架应用到更广泛的实际问题中。例如,在更复杂的金融分析领域,利用其动态适应能力来捕捉瞬息万变的市场信号;或是在能源节约等社会公益领域,通过精准的负荷预测来优化资源配置,从而提升社会福祉。