【PostgreSQL内核学习:WindowAgg 节点对 Tuplestore 的复用机制】
PostgreSQL内核学习:WindowAgg 节点对 Tuplestore 的复用机制
- 背景
- 补丁概述
- 提交信息
- 提交描述
- 优化目的
- 举例说明
- 测试用例
- 优化分析:优化前后对比
- 优化前
- 优化后
- 源码解读
- begin_partition 函数
- 获取外部计划状态和窗口函数数量
- 重置状态标志和计数器
- 清空元组槽
- 处理第一个分区
- 创建或复用 tuplestore
- 重置 next_partition 标志
- 重置聚合函数状态
- 重置窗口函数状态
- 存储第一个元组
- prepare_tuplestore 函数
- 获取计划节点、框架选项和窗口函数数量
- 断言 tuplestore 未创建
- 创建新的 tuplestore
- 初始化当前读指针
- 为聚合函数创建读指针
- 为窗口函数创建读指针
- 为 RANGE 或 GROUPS 模式创建框架指针
- 为排除子句创建组尾部指针
- 执行层改动
- ExecInitWindowAgg:
- ExecWindowAgg:
- ExecEndWindowAgg:
- 性能测试
- 统计汇总
- 平均执行时间:
- 平均性能提升:
- 范围:
- 总结
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-18 beta2 的开源代码和《PostgresSQL数据库内核分析》一书
背景
在 PostgreSQL 中,WindowAgg 节点是用于处理 SQL 窗口函数的核心执行节点。窗口函数(如 ROW_NUMBER(), RANK(), SUM() OVER() 等)需要在数据分区内对行进行排序、存储和访问,因此对性能敏感,尤其是当分区数量多或分区内行数少时,初始化和清理的开销可能显著影响查询性能。
补丁(908a968612f9ed61911d8ca0a185b262b82f1269)针对 PostgreSQL 的 WindowAgg 节点优化了其对 tuplestore(元组存储)组件的使用方式,通过减少重复的初始化和销毁操作显著提升了性能,特别是在分区数量极多但每个分区行数较少的情况下。本分析将详细探讨该补丁的优化内容、实现方式及预期效果。
补丁概述
提交信息
下面为本次优化的提交信息,hash值为:908a968612f9ed61911d8ca0a185b262b82f1269
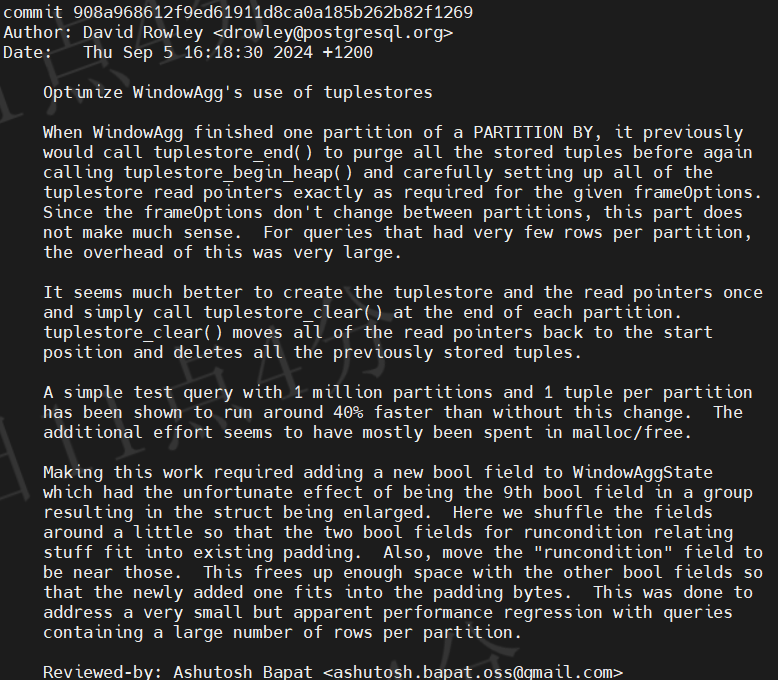
提交描述
该补丁优化了 WindowAgg 节点在处理分区切换时的 tuplestore 管理逻辑。原始实现中,每当 WindowAgg 完成一个分区的处理后,会调用 tuplestore_end() 销毁整个 tuplestore,并在处理下一个分区时重新调用 tuplestore_begin_heap() 创建新的 tuplestore,同时重新设置所有读指针(read pointers)。这种方式在分区数量多但每个分区行数少的情况下会导致显著的性能开销,因为频繁的内存分配(malloc)和释放(free)操作带来了不必要的 overhead。
补丁的主要改进是将 tuplestore 的创建和读指针的初始化操作移到查询开始时执行一次,而不是在每个分区切换时重复执行。具体做法包括:
- 引入
prepare_tuplestore函数:将tuplestore的创建和读指针初始化逻辑抽取到一个独立的pg_noinline函数中,仅在第一次需要时调用。 - 使用
tuplestore_clear:在分区切换时,不再销毁tuplestore,而是调用tuplestore_clear()清空存储的元组并重置读指针到起始位置,从而复用已分配的内存。 - 添加 next_partition 标志:在
WindowAggState结构体中新增一个布尔字段next_partition,用于标记是否需要调用begin_partition来处理新分区。 - 结构体字段重排:为避免因新增
next_partition字段导致结构体大小增加,补丁对WindowAggState结构体的字段顺序进行了调整,将与runcondition相关的字段重新排列,利用现有的填充字节(padding)容纳新字段,从而避免性能回归。
优化目的
补丁的主要目标是减少 WindowAgg 在处理多个分区时的性能开销,特别是针对以下场景:
- 高分区数、低行数:当查询涉及大量分区(例如,
PARTITION BY列值变化频繁),但每个分区包含的行数较少时,原始实现中频繁的tuplestore创建和销毁会导致显著的性能瓶颈。 - 内存管理效率:通过复用
tuplestore和读指针,减少malloc和free的调用,从而降低CPU和内存管理的开销。 - 避免结构体膨胀:通过字段重排,确保新增的
next_partition字段不会导致WindowAggState结构体大小增加,从而避免因内存对齐或缓存命中率下降带来的性能回归。
举例说明
为了分析 PostgreSQL 中 WindowAgg 优化补丁(Optimize-WindowAgg-s-use-of-tuplestores)的效果,我将提供一个完整的测试用例,包含创建表、插入数据、执行查询以及测量优化前后性能的步骤。测试用例基于补丁描述的场景:100万个分区,每个分区1行。之后,我将分析优化前后的差异,并量化性能提升,重点关注补丁对 tuplestore 使用的改进。
测试用例
-- 创建表
CREATE TABLE data_table (id SERIAL PRIMARY KEY,category INTEGER NOT NULL,value INTEGER NOT NULL
);-- 插入数据
-- 测试需要100万个分区,每个分区1行。
-- 我们使用 generate_series 生成100万行,
-- 每行具有唯一的 category 值(从1到1,000,000),
-- value 列为简单起见设置为与 category 相同。
INSERT INTO data_table (category, value)
SELECT gs, gs
FROM generate_series(1, 1000000) gs;-- 查询
-- 按 category 分区,生成100万个分区(因为每个 category 值唯一)。
-- 在每个分区内根据 value 排序,为每行分配 ROW_NUMBER()。
-- WHERE 子句中的 generate_series(1, 1000000) 确保包含所有行,符合每个分区1行的测试场景。
EXPLAIN ANALYZE
SELECTid,ROW_NUMBER() OVER (PARTITION BY category ORDER BY value) AS row_num
FROM data_table
WHERE category IN (SELECT generate_series(1, 1000000));QUERY PLAN-------------------------------------------------------------------------------------------------------------------------------
----------WindowAgg (cost=86973.94..96973.94 rows=500000 width=20) (actual time=4616.186..6083.283 rows=1000000 loops=1)-> Sort (cost=86973.94..88223.94 rows=500000 width=12) (actual time=4616.174..4934.341 rows=1000000 loops=1)Sort Key: data_table.category, data_table.valueSort Method: external merge Disk: 21616kB-> Hash Join (cost=7504.52..31098.02 rows=500000 width=12) (actual time=2437.231..4149.162 rows=1000000 loops=1)Hash Cond: (data_table.category = (generate_series(1, 1000000)))-> Seq Scan on data_table (cost=0.00..15406.00 rows=1000000 width=12) (actual time=0.066..158.038 rows=1000000loops=1)-> Hash (cost=7502.02..7502.02 rows=200 width=4) (actual time=2437.048..2437.050 rows=1000000 loops=1)Buckets: 262144 (originally 1024) Batches: 8 (originally 1) Memory Usage: 6446kB-> HashAggregate (cost=7500.02..7502.02 rows=200 width=4) (actual time=734.971..2057.769 rows=1000000 lo
ops=1)Group Key: generate_series(1, 1000000)Batches: 85 Memory Usage: 11073kB Disk Usage: 23512kB-> ProjectSet (cost=0.00..5000.02 rows=1000000 width=4) (actual time=0.004..142.272 rows=1000000 l
oops=1)-> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.002..0.002 rows=1 loops=1)Planning Time: 0.323 msExecution Time: 6192.450 ms
(16 rows)优化分析:优化前后对比
优化前
- 行为:原始实现中,
WindowAgg在每个分区结束时调用tuplestore_end()销毁tuplestore,并在下一个分区开始时调用tuplestore_begin_heap()创建新的tuplestore,同时为窗口函数和聚合函数重新分配读指针。 - 开销:
- 内存分配:
100万个分区每次都触发tuplestore_end()和tuplestore_begin_heap(),涉及多次malloc和free调用。对于小分区(1行),内存管理开销占据主导。 - 读指针设置:每个分区需要为
ROW_NUMBER()等函数重新分配和初始化读指针,增加CPU开销。 - 性能影响:补丁指出,对于
100万个分区、每个分区1行的查询,malloc/free和指针设置的开销显著,导致执行时间较长。
- 内存分配:
优化后
- 行为:补丁通过以下方式优化
WindowAgg:- 在查询开始时通过
prepare_tuplestore函数一次性创建tuplestore和读指针。 - 在分区切换时使用
tuplestore_clear()重置tuplestore,保留分配的内存和读指针。 - 新增
next_partition标志控制begin_partition的调用,避免重复初始化。 - 重排
WindowAggState结构体字段,避免因新增字段导致结构体大小增加,从而防止缓存相关的性能回归。
- 在查询开始时通过
- 优势:
- 降低内存开销:
tuplestore_clear()重置tuplestore而无需释放内存,仅在查询开始时分配一次,极大减少malloc/free调用。 - 更快分区切换:通过
tuplestore_clear()重置读指针比重新分配更快,因为它仅更新内部状态。 - 无结构体大小增加:字段重排利用现有填充字节,确保结构体大小不变,避免缓存未命中或内存效率下降。
- 降低内存开销:
源码解读
begin_partition 函数
begin_partition 是 WindowAgg 节点的核心函数,负责为新的分区初始化状态并开始缓冲其行。WindowAggState *winstate 是窗口聚合的状态结构体,包含所有与窗口函数执行相关的上下文信息。
/** begin_partition* Start buffering rows of the next partition.* 开始缓冲下一个分区的行。*/
static void
begin_partition(WindowAggState *winstate)
{// 获取外部计划的状态,用于读取输入元组PlanState *outerPlan = outerPlanState(winstate);// 获取窗口函数的数量int numfuncs = winstate->numfuncs;// 重置分区是否已全部存储的标志为 falsewinstate->partition_spooled = false;// 重置框架头部是否有效的标志为 falsewinstate->framehead_valid = false;// 重置框架尾部是否有效的标志为 falsewinstate->frametail_valid = false;// 重置组尾部是否有效的标志为 falsewinstate->grouptail_valid = false;// 重置已存储的行数计数器为 0winstate->spooled_rows = 0;// 重置当前行位置为 0winstate->currentpos = 0;// 重置框架头部位置为 0winstate->frameheadpos = 0;// 重置框架尾部位置为 0winstate->frametailpos = 0;// 重置当前组编号为 0winstate->currentgroup = 0;// 重置框架头部组编号为 0winstate->frameheadgroup = 0;// 重置框架尾部组编号为 0winstate->frametailgroup = 0;// 重置组头部位置为 0winstate->groupheadpos = 0;// 重置组尾部位置为 -1(将在 update_grouptailpos 中更新)winstate->grouptailpos = -1; /* see update_grouptailpos */// 清空聚合行槽ExecClearTuple(winstate->agg_row_slot);// 如果框架头部槽存在,清空它if (winstate->framehead_slot)ExecClearTuple(winstate->framehead_slot);// 如果框架尾部槽存在,清空它if (winstate->frametail_slot)ExecClearTuple(winstate->frametail_slot);/** If this is the very first partition, we need to fetch the first input* row to store in first_part_slot.* 如果这是第一个分区,需要获取第一个输入行并存储到 first_part_slot 中。*/if (TupIsNull(winstate->first_part_slot)){// 从外部计划获取一个输入元组TupleTableSlot *outerslot = ExecProcNode(outerPlan);// 如果输入元组非空,将其复制到 first_part_slotif (!TupIsNull(outerslot))ExecCopySlot(winstate->first_part_slot, outerslot);else{/* outer plan is empty, so we have nothing to do *//* 外部计划为空,无需处理 */winstate->partition_spooled = true;winstate->more_partitions = false;return;}}/* Create new tuplestore if not done already. *//* 如果尚未创建 tuplestore,则创建新的 tuplestore */if (unlikely(winstate->buffer == NULL))prepare_tuplestore(winstate);// 重置 next_partition 标志为 false,表示已处理分区切换winstate->next_partition = false;// 如果存在聚合函数(numaggs > 0)if (winstate->numaggs > 0){// 获取聚合函数的窗口对象WindowObject agg_winobj = winstate->agg_winobj;/* reset mark and see positions for aggregate functions *//* 重置聚合函数的标记和查找位置 */agg_winobj->markpos = -1;agg_winobj->seekpos = -1;/* Also reset the row counters for aggregates *//* 重置聚合函数的行计数器 */winstate->aggregatedbase = 0;winstate->aggregatedupto = 0;}/* reset mark and seek positions for each real window function *//* 重置每个真实窗口函数的标记和查找位置 */for (int i = 0; i < numfuncs; i++){// 获取当前窗口函数的状态WindowStatePerFunc perfuncstate = &(winstate->perfunc[i]);// 如果不是普通聚合函数(即为窗口函数)if (!perfuncstate->plain_agg){// 获取窗口函数的窗口对象WindowObject winobj = perfuncstate->winobj;// 重置标记和查找位置winobj->markpos = -1;winobj->seekpos = -1;}}/** Store the first tuple into the tuplestore (it's always available now;* we either read it above, or saved it at the end of previous partition)* 将第一个元组存储到 tuplestore 中(现在总是可用,要么在上面读取,要么在上一个分区结束时保存)*/tuplestore_puttupleslot(winstate->buffer, winstate->first_part_slot);// 增加已存储的行数计数winstate->spooled_rows++;
}
获取外部计划状态和窗口函数数量
PlanState *outerPlan = outerPlanState(winstate);
int numfuncs = winstate->numfuncs;
作用:
outerPlanState(winstate)获取外部计划节点(例如子查询或扫描节点),用于读取输入元组。numfuncs获取查询中定义的窗口函数数量(例如ROW_NUMBER()),用于后续循环处理。
意义:为读取输入元组和处理窗口函数做准备。
重置状态标志和计数器
// 重置分区是否已全部存储的标志为 falsewinstate->partition_spooled = false;// 重置框架头部是否有效的标志为 falsewinstate->framehead_valid = false;// 重置框架尾部是否有效的标志为 falsewinstate->frametail_valid = false;// 重置组尾部是否有效的标志为 falsewinstate->grouptail_valid = false;// 重置已存储的行数计数器为 0winstate->spooled_rows = 0;// 重置当前行位置为 0winstate->currentpos = 0;// 重置框架头部位置为 0winstate->frameheadpos = 0;// 重置框架尾部位置为 0winstate->frametailpos = 0;// 重置当前组编号为 0winstate->currentgroup = 0;// 重置框架头部组编号为 0winstate->frameheadgroup = 0;// 重置框架尾部组编号为 0winstate->frametailgroup = 0;// 重置组头部位置为 0winstate->groupheadpos = 0;// 重置组尾部位置为 -1(将在 update_grouptailpos 中更新)winstate->grouptailpos = -1; /* see update_grouptailpos */
作用:
- 重置分区相关的状态标志:
partition_spooled:表示当前分区是否已完全存储到tuplestore。framehead_valid和frametail_valid:表示框架(frame)头部和尾部的位置是否有效。grouptail_valid:表示组尾部位置是否有效(用于GROUPS模式)。- 重置计数器:
spooled_rows:已存储到tuplestore的行数。currentpos:当前处理的行位置。frameheadpos和frametailpos:框架头部和尾部的位置。currentgroup,frameheadgroup,frametailgroup:当前组、框架头部和尾部的组编号(用于GROUPS模式)。groupheadpos和grouptailpos:组的头部和尾部位置。
意义:为新分区初始化状态,确保所有位置和计数器从零开始,避免旧分区的数据干扰。
清空元组槽
ExecClearTuple(winstate->agg_row_slot);
if (winstate->framehead_slot)ExecClearTuple(winstate->framehead_slot);
if (winstate->frametail_slot)ExecClearTuple(winstate->frametail_slot);
作用:
ExecClearTuple清空指定的元组槽(agg_row_slot用于聚合,framehead_slot和frametail_slot用于框架边界)。- 使用条件检查确保仅在槽存在时清空,防止无效操作。
意义:确保元组槽不保留旧分区的元组,避免数据混淆。
处理第一个分区
if (TupIsNull(winstate->first_part_slot))
{TupleTableSlot *outerslot = ExecProcNode(outerPlan);if (!TupIsNull(outerslot))ExecCopySlot(winstate->first_part_slot, outerslot);else{winstate->partition_spooled = true;winstate->more_partitions = false;return;}
}
作用:
- 检查
first_part_slot是否为空(表示这是查询的第一个分区)。- 如果为空,从
outerPlan获取第一个输入元组(outerslot)。- 如果
outerslot非空,复制到first_part_slot;否则,标记分区已完成(partition_spooled = true)且无更多分区(more_partitions = false),然后返回。
意义:为第一个分区初始化,确保有可用的元组用于后续存储。
创建或复用 tuplestore
if (unlikely(winstate->buffer == NULL))prepare_tuplestore(winstate);
作用:
- 检查是否需要创建新的
tuplestore(buffer == NULL表示尚未创建)。- 如果需要,调用
prepare_tuplestore创建tuplestore并初始化读指针。unlikely提示编译器此条件通常为假(优化分支预测,因为补丁确保tuplestore通常已创建)。
优化背景:补丁的关键改进是仅在查询开始时创建一次
tuplestore,后续分区通过tuplestore_clear()复用,避免重复分配。
重置 next_partition 标志
winstate->next_partition = false;
- 作用:将
next_partition标志置为false,表示已处理分区切换,准备处理当前分区。- 意义:
next_partition是补丁新增的标志,用于控制begin_partition的调用逻辑,确保不重复初始化tuplestore。
重置聚合函数状态
if (winstate->numaggs > 0)
{WindowObject agg_winobj = winstate->agg_winobj;agg_winobj->markpos = -1;agg_winobj->seekpos = -1;winstate->aggregatedbase = 0;winstate->aggregatedupto = 0;
}
作用:
- 如果存在聚合函数(
numaggs > 0),获取聚合窗口对象(agg_winobj)。- 重置聚合函数的标记位置(
markpos)和查找位置(seekpos)为-1,表示未标记或定位。- 重置聚合的行计数器:
aggregatedbase(起始行)和aggregatedupto(已处理行)。
意义:为新分区的聚合函数初始化状态,确保聚合计算从头开始。
重置窗口函数状态
for (int i = 0; i < numfuncs; i++)
{WindowStatePerFunc perfuncstate = &(winstate->perfunc[i]);if (!perfuncstate->plain_agg){WindowObject winobj = perfuncstate->winobj;winobj->markpos = -1;winobj->seekpos = -1;}
}
作用:
- 遍历所有窗口函数(
numfuncs个)。- 对于非普通聚合函数(
!plain_agg,即真正的窗口函数,如ROW_NUMBER()),获取窗口对象(winobj)。- 重置窗口函数的标记位置(
markpos)和查找位置(seekpos)为-1。
意义:确保每个窗口函数的读指针状态为初始值,准备处理新分区的数据。
存储第一个元组
tuplestore_puttupleslot(winstate->buffer, winstate->first_part_slot);
winstate->spooled_rows++;
作用:
- 将
first_part_slot中的元组存储到tuplestore(buffer)中。- 增加
spooled_rows计数,表示已存储的行数加1。
意义:将分区的第一个元组存入
tuplestore,开始缓冲分区数据。first_part_slot保证始终有可用元组(要么从outerPlan读取,要么从上一分区保存)。
prepare_tuplestore 函数
prepare_tuplestore 初始化 tuplestore 以及窗口函数和聚合函数所需的读指针,基于 WindowAggState 的 frameOptions 配置。pg_noinline 确保函数代码不内联到调用者,减少调用函数(如 begin_partition)的代码膨胀,因为此函数仅调用一次。
补丁引入此函数,将 tuplestore 创建逻辑集中化,只在查询开始时执行一次,避免每个分区重复创建。
/** prepare_tuplestore* 准备 tuplestore 以及 WindowAggState 的 frameOptions 所需的所有读指针。** 注意:使用 pg_noinline 以避免调用函数因一次性代码而膨胀。*/
static pg_noinline void
prepare_tuplestore(WindowAggState *winstate)
{// 获取 WindowAgg 计划节点WindowAgg *node = (WindowAgg *) winstate->ss.ps.plan;// 获取窗口框架选项int frameOptions = winstate->frameOptions;// 获取窗口函数数量int numfuncs = winstate->numfuncs;/* 如果 tuplestore 已创建,不应调用此函数 */Assert(winstate->buffer == NULL);/* 创建新的 tuplestore */winstate->buffer = tuplestore_begin_heap(false, false, work_mem);/** 为 tuplestore 设置读指针。当前指针不需要 BACKWARD 能力,但每个窗口函数的读指针需要,* 如果需要重启聚合,聚合指针也需要。*/winstate->current_ptr = 0; /* 当前读指针 0 已预分配 *//* 重置当前指针的默认 REWIND 能力位 */tuplestore_set_eflags(winstate->buffer, 0);/* 如果需要,为聚合函数创建读指针 */if (winstate->numaggs > 0){/* 获取聚合函数的窗口对象 */WindowObject agg_winobj = winstate->agg_winobj;/* 初始化读指针标志 */int readptr_flags = 0;/** 如果框架头部可能移动,或存在 EXCLUSION 子句,可能需要重启聚合...*/if (!(frameOptions & FRAMEOPTION_START_UNBOUNDED_PRECEDING) ||(frameOptions & FRAMEOPTION_EXCLUSION)){/* ...因此创建一个标记指针以跟踪框架头部 */agg_winobj->markptr = tuplestore_alloc_read_pointer(winstate->buffer, 0);/* 并且读指针需要 BACKWARD 能力 */readptr_flags |= EXEC_FLAG_BACKWARD;}/* 为聚合函数分配读指针 */agg_winobj->readptr = tuplestore_alloc_read_pointer(winstate->buffer,readptr_flags);}/* 为每个真实窗口函数创建标记和读指针 */for (int i = 0; i < numfuncs; i++){/* 获取当前窗口函数的状态 */WindowStatePerFunc perfuncstate = &(winstate->perfunc[i]);/* 如果不是普通聚合函数(即为窗口函数) */if (!perfuncstate->plain_agg){/* 获取窗口函数的窗口对象 */WindowObject winobj = perfuncstate->winobj;/* 为窗口函数分配标记指针 */winobj->markptr = tuplestore_alloc_read_pointer(winstate->buffer,0);/* 为窗口函数分配读指针,支持 BACKWARD 能力 */winobj->readptr = tuplestore_alloc_read_pointer(winstate->buffer,EXEC_FLAG_BACKWARD);}}/** 如果处于 RANGE 或 GROUPS 模式,确定框架边界需要物理访问框架端点行,* 除非在某些退化情况下。我们创建指向这些行的读指针,以简化访问并确保 tuplestore* 不会过早丢弃端点行。(必须在 update_frameheadpos 和 update_frametailpos* 需要指针的相同情况下创建指针。)*/winstate->framehead_ptr = winstate->frametail_ptr = -1; /* 初始化框架头部和尾部指针为 -1(未使用时) *//* 如果使用 RANGE 或 GROUPS 模式 */if (frameOptions & (FRAMEOPTION_RANGE | FRAMEOPTION_GROUPS)){/* 如果框架起点为当前行且有排序列,或指定了偏移 */if (((frameOptions & FRAMEOPTION_START_CURRENT_ROW) &&node->ordNumCols != 0) ||(frameOptions & FRAMEOPTION_START_OFFSET))winstate->framehead_ptr =tuplestore_alloc_read_pointer(winstate->buffer, 0);/* 如果框架终点为当前行且有排序列,或指定了偏移 */if (((frameOptions & FRAMEOPTION_END_CURRENT_ROW) &&node->ordNumCols != 0) ||(frameOptions & FRAMEOPTION_END_OFFSET))winstate->frametail_ptr =tuplestore_alloc_read_pointer(winstate->buffer, 0);}/** 如果存在需要知道当前行对等组边界的排除子句,我们创建一个读指针以跟踪对等组* 的尾部位置(即下一个对等组的第一行)。头部位置不需要自己的指针,因为我们* 在推进当前行时会维护它。*/winstate->grouptail_ptr = -1;/* 初始化组尾部指针为 -1 *//* 如果存在排除组或排除平局的子句,且有排序列 */if ((frameOptions & (FRAMEOPTION_EXCLUDE_GROUP |FRAMEOPTION_EXCLUDE_TIES)) &&node->ordNumCols != 0){/* 为组尾部分配读指针 */winstate->grouptail_ptr =tuplestore_alloc_read_pointer(winstate->buffer, 0);}
}
获取计划节点、框架选项和窗口函数数量
WindowAgg *node = (WindowAgg *) winstate->ss.ps.plan;
int frameOptions = winstate->frameOptions;
int numfuncs = winstate->numfuncs;
作用:
node:获取WindowAgg计划节点,包含查询计划信息(如排序列ordNumCols)。frameOptions:获取窗口框架选项(如RANGE、ROWS、GROUPS、排除子句等)。numfuncs:获取窗口函数数量(如ROW_NUMBER())。
意义:为后续配置
tuplestore和读指针提供必要上下文。
断言 tuplestore 未创建
Assert(winstate->buffer == NULL);
作用:确保
tuplestore尚未创建(buffer == NULL),防止重复初始化。
意义:保证函数仅在第一次调用时执行,符合补丁的优化目标(一次性创建
tuplestore)。
创建新的 tuplestore
winstate->buffer = tuplestore_begin_heap(false, false, work_mem);
作用:调用
tuplestore_begin_heap创建一个堆存储的tuplestore,用于存储分区中的元组。参数false,false表示不使用随机访问或临时文件,work_mem指定内存限制。
意义:
tuplestore是窗口函数处理的核心数据结构,存储所有分区元组以支持窗口计算。
初始化当前读指针
winstate->current_ptr = 0; /* read pointer 0 is pre-allocated */
tuplestore_set_eflags(winstate->buffer, 0);
作用:
- 设置
current_ptr为0,表示使用预分配的读指针0(默认指针)。tuplestore_set_eflags(0)重置默认指针的标志,禁用REWIND能力(当前指针无需回溯)。
意义:当前指针用于跟踪
tuplestore中的当前位置,禁用REWIND减少不必要的功能开销。
为聚合函数创建读指针
if (winstate->numaggs > 0)
{WindowObject agg_winobj = winstate->agg_winobj;int readptr_flags = 0;if (!(frameOptions & FRAMEOPTION_START_UNBOUNDED_PRECEDING) ||(frameOptions & FRAMEOPTION_EXCLUSION)){agg_winobj->markptr = tuplestore_alloc_read_pointer(winstate->buffer, 0);readptr_flags |= EXEC_FLAG_BACKWARD;}agg_winobj->readptr = tuplestore_alloc_read_pointer(winstate->buffer,readptr_flags);
}
作用:
- 检查是否存在聚合函数(
numaggs > 0)。- 获取聚合窗口对象(
agg_winobj)。- 如果框架起点不是
UNBOUNDED PRECEDING或存在EXCLUSION子句(如EXCLUDE CURRENT ROW),为聚合函数分配一个标记指针(markptr)以跟踪框架头部,并启用BACKWARD能力(EXEC_FLAG_BACKWARD),支持重启聚合。- 为聚合函数分配读指针(
readptr),根据需要设置BACKWARD标志。
意义:聚合函数(如
SUM() OVER())可能需要回溯或重启计算,标记指针和BACKWARD能力支持动态框架边界。
为窗口函数创建读指针
for (int i = 0; i < numfuncs; i++)
{WindowStatePerFunc perfuncstate = &(winstate->perfunc[i]);if (!perfuncstate->plain_agg){WindowObject winobj = perfuncstate->winobj;winobj->markptr = tuplestore_alloc_read_pointer(winstate->buffer, 0);winobj->readptr = tuplestore_alloc_read_pointer(winstate->buffer,EXEC_FLAG_BACKWARD);}
}
作用:
- 遍历所有窗口函数(
numfuncs个)。- 对于非普通聚合函数(
!plain_agg,即真正的窗口函数,如ROW_NUMBER()),获取窗口对象(winobj)。- 为每个窗口函数分配标记指针(
markptr)和读指针(readptr),读指针启用BACKWARD能力。
意义:窗口函数需要灵活访问
tuplestore中的元组,标记指针用于保存位置,BACKWARD能力支持回溯(如计算LAG()或动态框架)。
为 RANGE 或 GROUPS 模式创建框架指针
winstate->framehead_ptr = winstate->frametail_ptr = -1; /* if not used */
if (frameOptions & (FRAMEOPTION_RANGE | FRAMEOPTION_GROUPS))
{if (((frameOptions & FRAMEOPTION_START_CURRENT_ROW) &&node->ordNumCols != 0) ||(frameOptions & FRAMEOPTION_START_OFFSET))winstate->framehead_ptr =tuplestore_alloc_read_pointer(winstate->buffer, 0);if (((frameOptions & FRAMEOPTION_END_CURRENT_ROW) &&node->ordNumCols != 0) ||(frameOptions & FRAMEOPTION_END_OFFSET))winstate->frametail_ptr =tuplestore_alloc_read_pointer(winstate->buffer, 0);
}
作用:
- 初始化框架头部和尾部指针为
-1(未使用)。- 如果窗口框架是
RANGE或GROUPS模式:
- 如果起点为
CURRENT ROW且有排序列(ordNumCols != 0)或指定了偏移(START_OFFSET),分配框架头部指针(framehead_ptr)。- 如果终点为
CURRENT ROW且有排序列或指定了偏移(END_OFFSET),分配框架尾部指针(frametail_ptr)。
意义:
RANGE和GROUPS模式需要物理访问框架端点行,指针确保tuplestore保留这些行,防止过早丢弃。
为排除子句创建组尾部指针
winstate->grouptail_ptr = -1;
if ((frameOptions & (FRAMEOPTION_EXCLUDE_GROUP |FRAMEOPTION_EXCLUDE_TIES)) &&node->ordNumCols != 0)
{winstate->grouptail_ptr =tuplestore_alloc_read_pointer(winstate->buffer, 0);
}
作用:
- 初始化组尾部指针为
-1。- 如果存在
EXCLUDE GROUP或EXCLUDE TIES子句且有排序列,分配组尾部指针(grouptail_ptr)以跟踪对等组的尾部(下一组的第一行)。
意义:排除子句需要确定对等组边界,尾部指针支持访问下一组的起始行(头部位置由当前行维护)。
执行层改动
ExecInitWindowAgg:
- 修改内容:初始化时新增
winstate->next_partition = true,确保第一个分区触发begin_partition调用。 - 意义:引入
next_partition标志,与补丁的优化逻辑(复用tuplestore)保持一致,确保分区切换的正确性。
ExecWindowAgg:
- 修改内容:将
if (winstate->buffer == NULL)替换为if (winstate->next_partition),使用next_partition标志控制begin_partition的调用。 - 意义:配合补丁的
tuplestore复用机制,仅在需要时(新分区)调用begin_partition,避免重复初始化tuplestore。
ExecEndWindowAgg:
- 修改内容:
- 在函数开始时添加代码,检查
node->buffer != NULL,调用tuplestore_end(node->buffer)销毁tuplestore,并将node->buffer置为NULL。 - 确保
release_partition跳过tuplestore_clear(),避免重复清理。
- 在函数开始时添加代码,检查
- 意义:确保查询结束时正确释放
tuplestore资源,防止内存泄漏,同时保持与补丁复用逻辑的一致性。
这些修改配合 prepare_tuplestore 和 next_partition 标志,实现了 tuplestore 的单次创建和复用,减少了分区切换时的内存分配开销(如 malloc/free),显著提升了高分区数(如 100 万个分区、每分区 1 行)查询的性能。
性能测试
还是以以下用例为例:
-- 创建表
CREATE TABLE data_table (id SERIAL PRIMARY KEY,category INTEGER NOT NULL,value INTEGER NOT NULL
);-- 插入数据
-- 测试需要100万个分区,每个分区1行。
-- 我们使用 generate_series 生成100万行,
-- 每行具有唯一的 category 值(从1到1,000,000),
-- value 列为简单起见设置为与 category 相同。
INSERT INTO data_table (category, value)
SELECT gs, gs
FROM generate_series(1, 1000000) gs;-- 查询
-- 按 category 分区,生成100万个分区(因为每个 category 值唯一)。
-- 在每个分区内根据 value 排序,为每行分配 ROW_NUMBER()。
-- WHERE 子句中的 generate_series(1, 1000000) 确保包含所有行,符合每个分区1行的测试场景。
EXPLAIN ANALYZE
SELECTid,ROW_NUMBER() OVER (PARTITION BY category ORDER BY value) AS row_num
FROM data_table
WHERE category IN (SELECT generate_series(1, 1000000));
| 执行次数 | 优化前执行时间(ms) | 优化后执行时间(ms) |
|---|---|---|
| 1 | 7107.930 | 6261.855 |
| 2 | 7034.950 | 6266.170 |
| 3 | 7057.040 | 6245.449 |
| 4 | 7025.348 | 6266.164 |
| 5 | 7081.225 | 6247.730 |
| 6 | 7053.091 | 6277.012 |
| 7 | 7050.542 | 6256.242 |
| 8 | 7099.145 | 6254.400 |
| 9 | 7128.228 | 6262.103 |
| 10 | 7088.137 | 6260.770 |
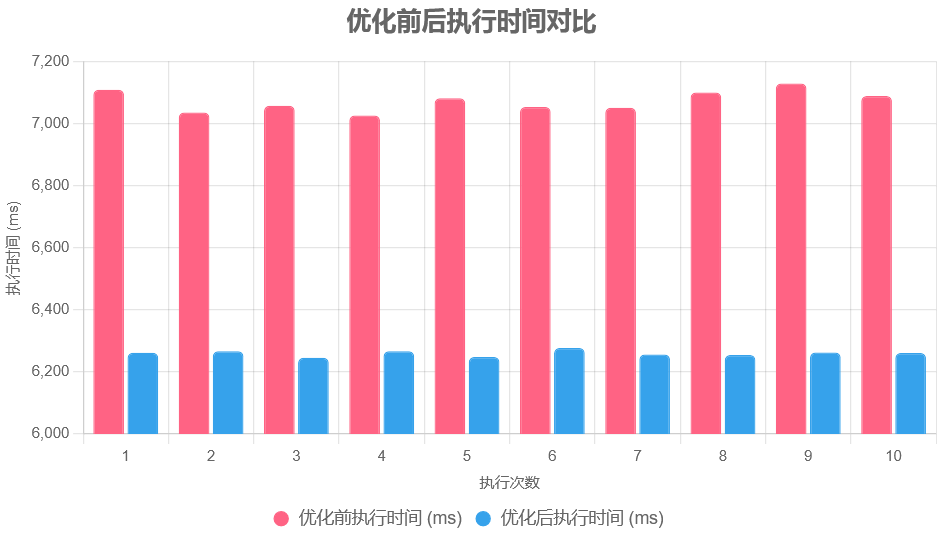
统计汇总
平均执行时间:
- 优化前:
(7107.930 + 7034.950 + ... + 7088.137) / 10 = 7072.564 ms - 优化后:
(6261.855 + 6266.170 + ... + 6260.770) / 10 = 6259.786 ms
平均性能提升:
- 时间减少:
7072.564 - 6259.786 = 812.778 ms - 百分比:
812.778 / 7072.564 × 100% = 11.49%
范围:
- 优化前时间范围:
7025.348–7128.228 ms - 优化后时间范围:
6245.449–6277.012 ms - 性能提升百分比范围:
10.81%–12.15%
总结
- 性能提升:平均提升
11.49%(约812.78 ms),优于优化前的7072.564 ms,验证了补丁通过复用tuplestore减少内存分配开销的效果。 - 稳定性:优化后执行时间波动较小(
6245.449–6277.012 ms),表明优化提高了性能稳定性。 - 与预期差异:提升低于补丁声称的
40%,可能因测试场景(如分区数量、硬件)不同,建议进一步测试更大分区数(如100万分区)以接近补丁目标。