Map 和 Set
在本文将介绍集合框架中最重要的两个部分,需要掌握 Map/Set 及实际实现类 HashMap / TreeMap / HashSet / TreeSet 的使用,重点掌握 HashMap 和 HashSet 背后的数据结构哈希表的原理和简单实现。
目录
一、二叉搜索树
1.1 概念
1.2 搜索实现
1.3 插入实现
1.4 删除实现(难点)
1.5 性能分析
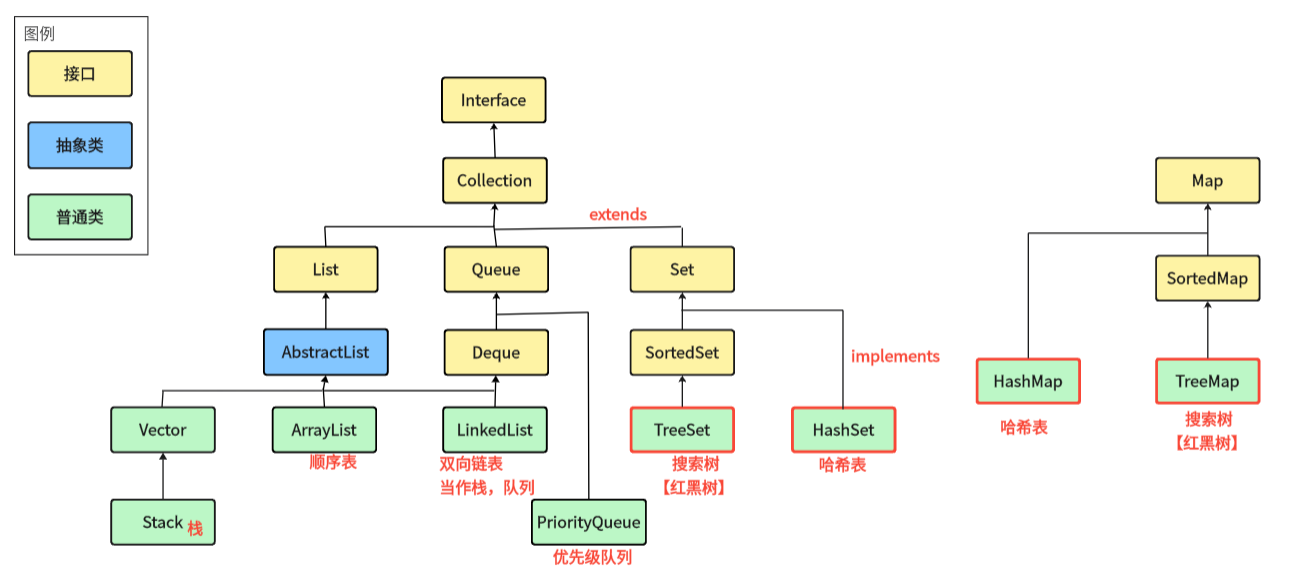
1.6 二叉搜索树与Java类集合的关系
1.7 二叉搜索树与双向链表
二、搜索
2.1 概念
2.2 模型
三、Map
四、Set
一、二叉搜索树
1.1 概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值;
若它的右子树不为空,则右子树上所有节点的值都大于根节点的值;
它的左右子树也分别为二叉搜索树。
1.2 搜索实现
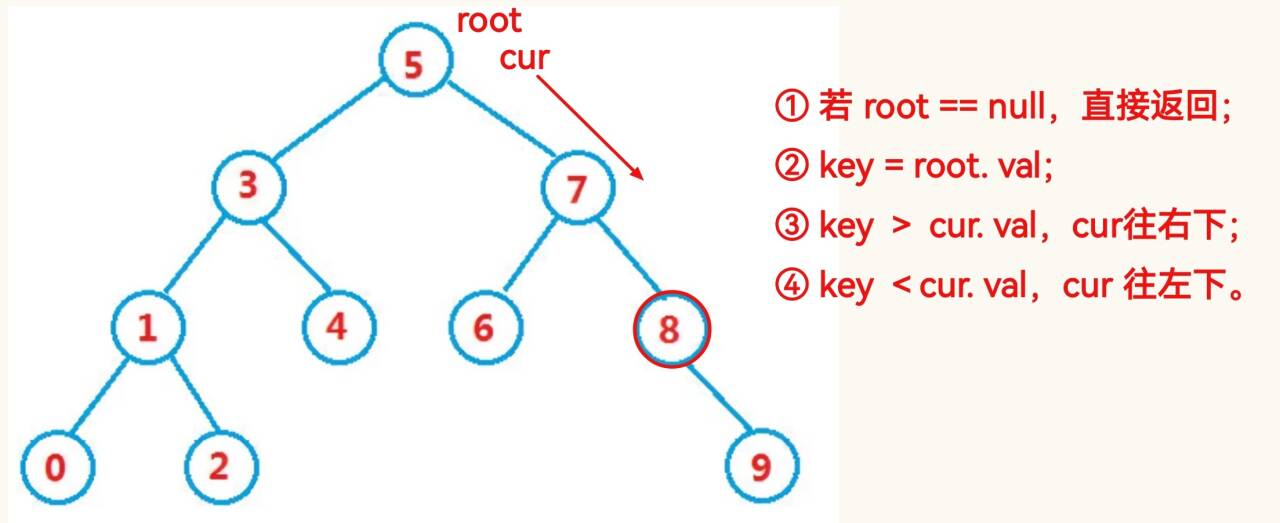
public TreeNode search(int key){TreeNode cur = root;while (cur != null) {if (cur.val > key) {cur = cur.left;} else if (cur.val == key){return cur;}else{cur = cur.right;}}return null;}1.3 插入实现
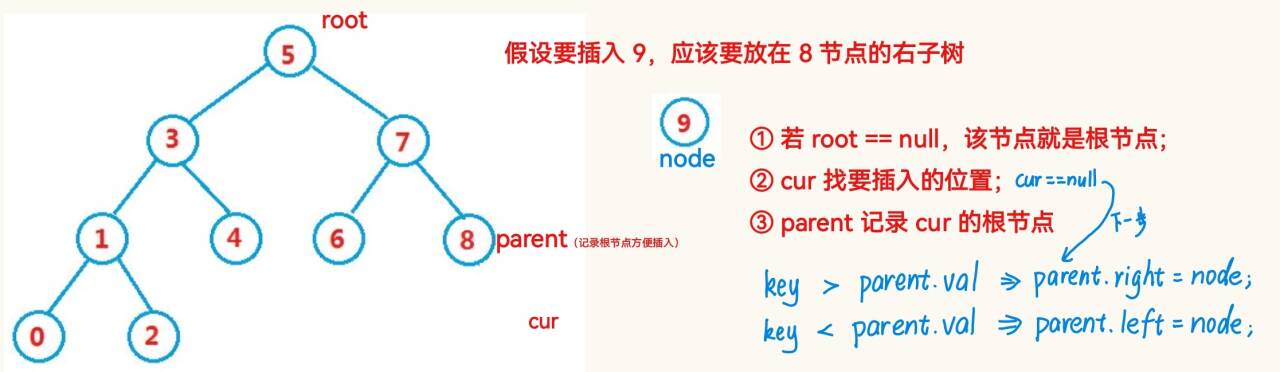
public void insert(int key){if (root == null){root = new TreeNode(key);return;}TreeNode cur = root;TreeNode parent = null;TreeNode node = new TreeNode(key);while (cur != null){if (key > cur.val){parent = cur;cur = cur.right;}else if (key < cur.val){parent = cur;cur = cur.left;}else {// 不能插入2个相同的数据return;}}if (parent.val > key){parent.left = node;}else{parent.right = node;}}1.4 删除实现(难点)
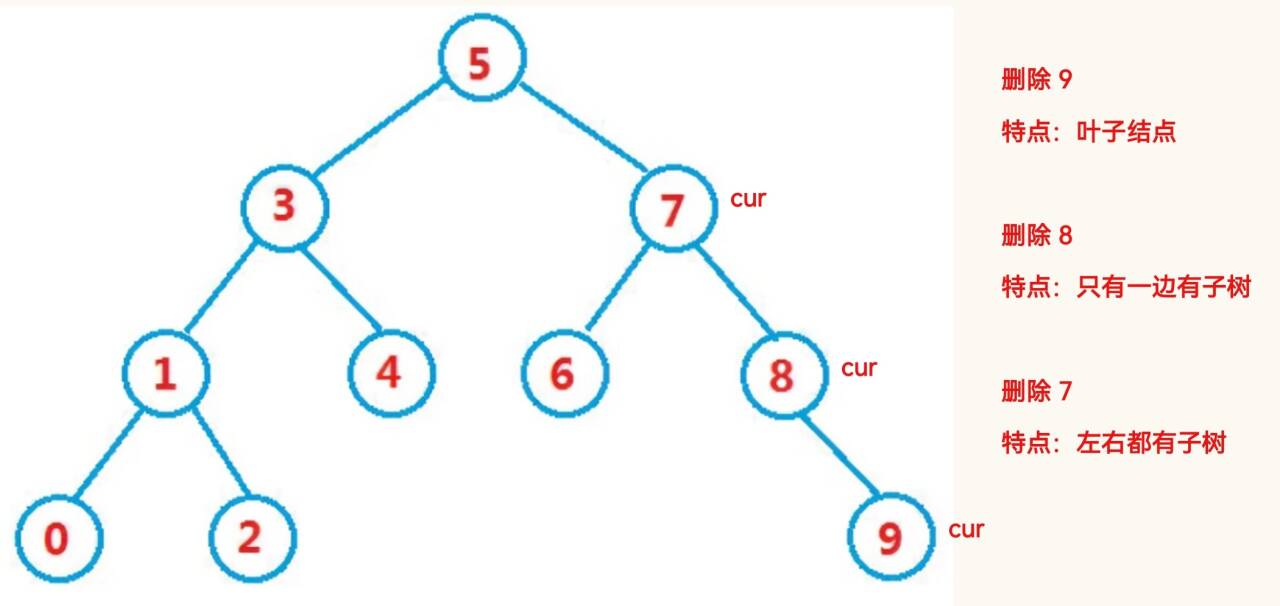
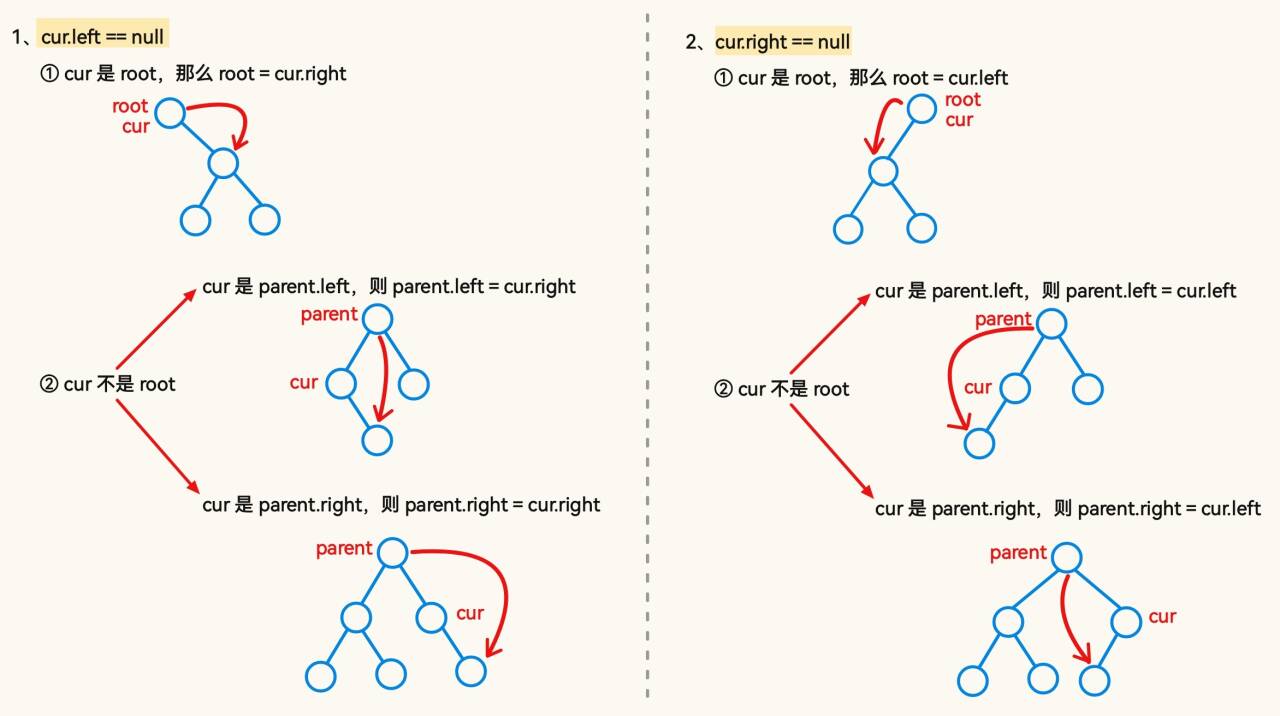
对于要删除的节点只有一个子树的情况如上图,但是如果要删除的节点满足 cur.left != null && cur.right != null; 的情况,应该使用替换法进行删除,即找一个合适的数据替换 cur.val ,这个“合适的数据,可以是 左树(都比 cur.val 小)找到的最大值,也可以是右树找最小值:
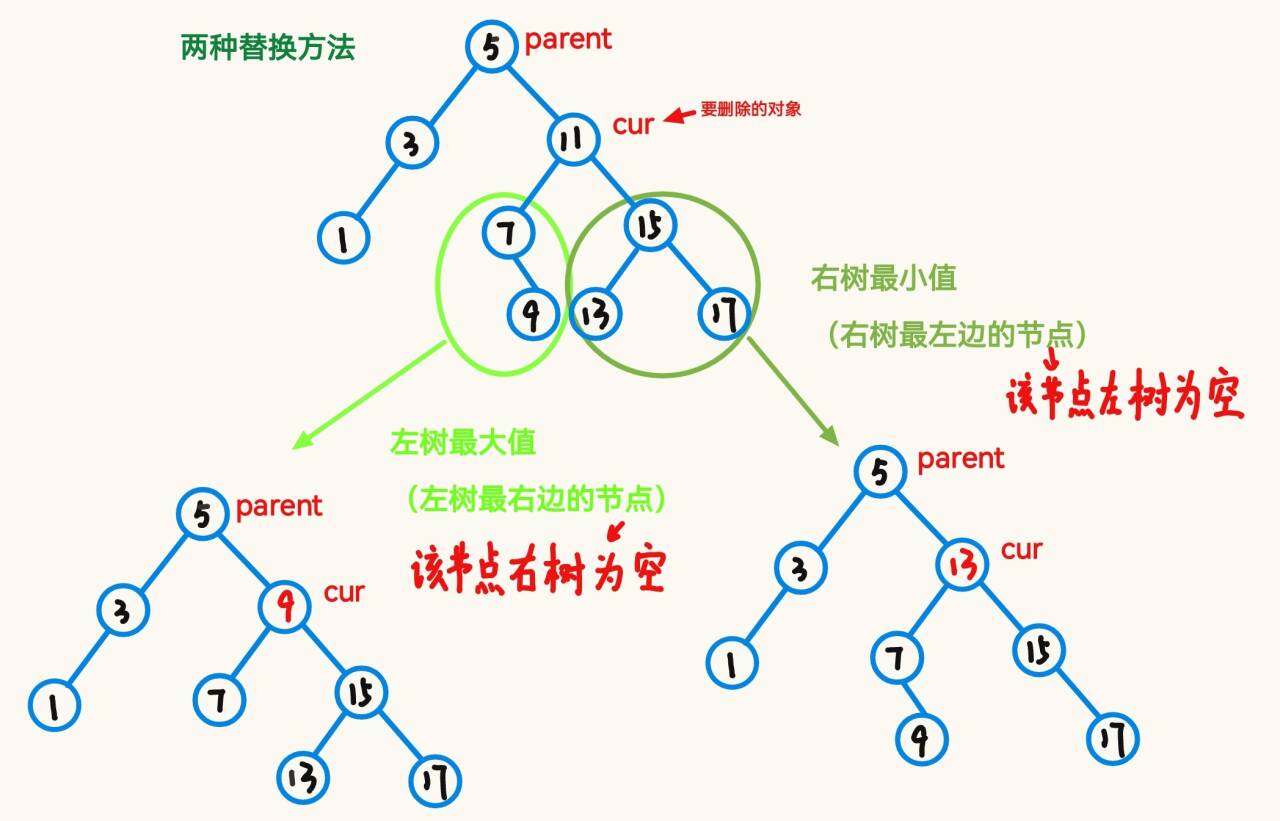
我们一找右数最小值为例:
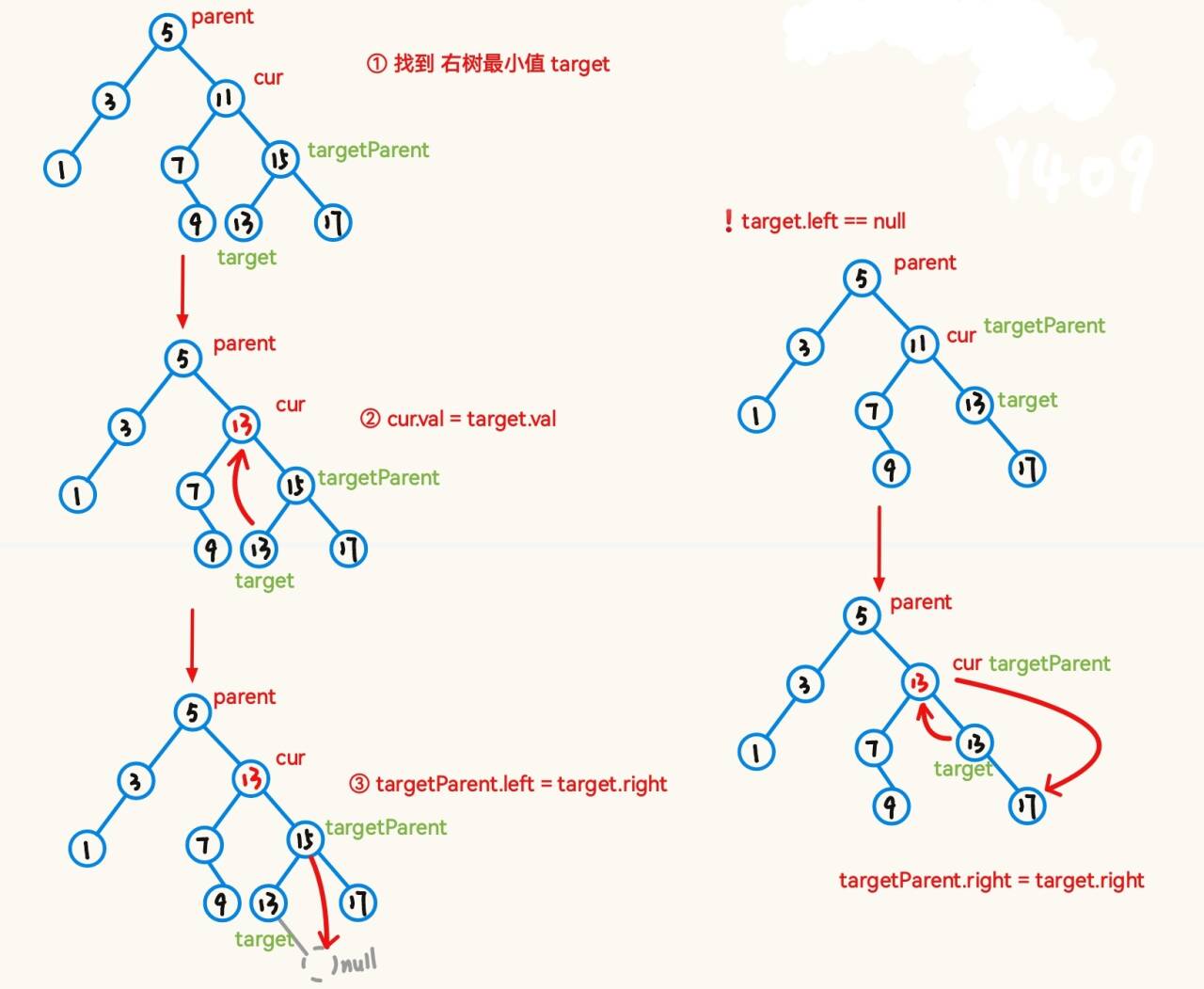
public void remove(int key){TreeNode cur = root;TreeNode parent = null;while (cur != null){if (key > cur.val){parent = cur;cur = cur.right;}else if(key < cur.val){parent = cur;cur = cur.left;}else {removeNode(parent, cur);return;}}}private void removeNode(TreeNode parent, TreeNode cur) {if (cur.left == null){if (cur == root){root = cur.right;}else if (cur == parent.left){parent.left = cur.right;}else {parent.right = cur.right;}}else if (cur.right == null){if (root == cur.left){root = cur.left;}else if(cur == parent.left){parent.left = cur.left;}else {parent.right = cur.left;}}else {removeReplace(cur);}}private void removeReplace(TreeNode cur) {TreeNode targetParent = cur;TreeNode target = cur.right;while (target.left != null){targetParent = target;target = target.left;}cur.val = target.val;if (targetParent.left == target){targetParent.left = target.right;}else {targetParent.right = target.right;}}1.5 性能分析
插入和删除操作都必须先查找,查找的效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深 的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树(如完全二叉树和单分支树)
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:log₂N
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:N/2
1.6 二叉搜索树与Java类集合的关系
TreeMap 和 TreeSet 即 java 中利用搜索树实现的 Map 和 Set;实际上用的是红黑树,而红黑树是一棵近似平衡的 二叉搜索树,即在二叉搜索树的基础之上 + 颜色以及红黑树性质验证。
1.7 二叉搜索树与双向链表
这里补充一个知识点,利用中序遍历将二叉搜索树转换成一个排序的双向链表
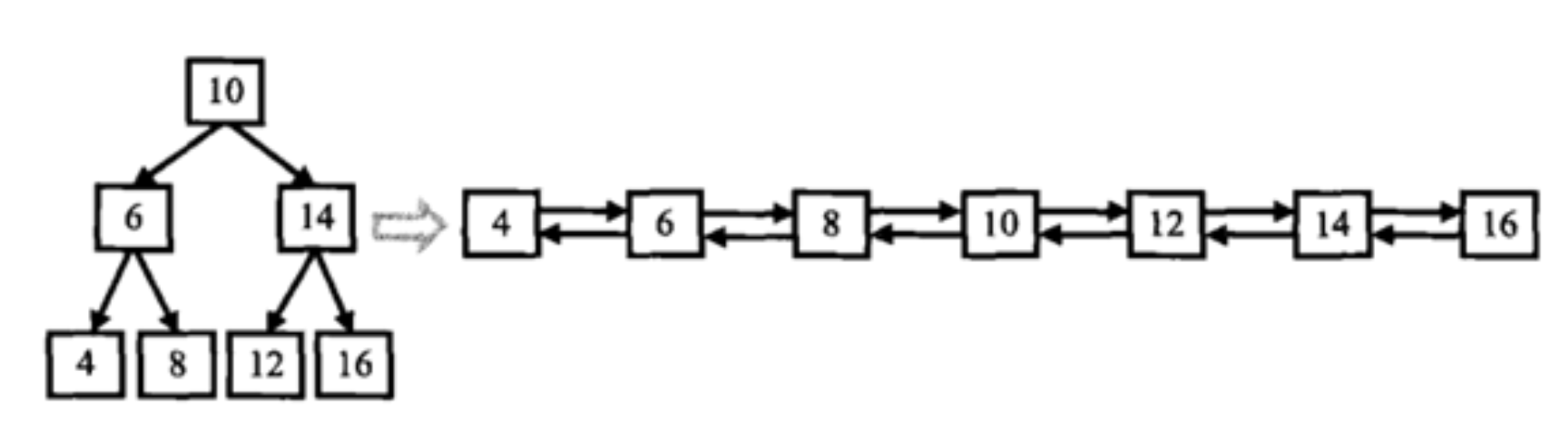
处理逻辑:
1、递归处理左子树;
2、处理当前节点 (root):
-
将当前节点的左指针 (
left) 指向前驱节点 (prev)。 -
如果前驱节点 (
prev) 不为空,则将前驱节点的右指针 (right) 指向当前节点。 -
将前驱节点 (
prev) 更新为当前节点,为处理下一个节点做准备。
3、递归处理右子树。
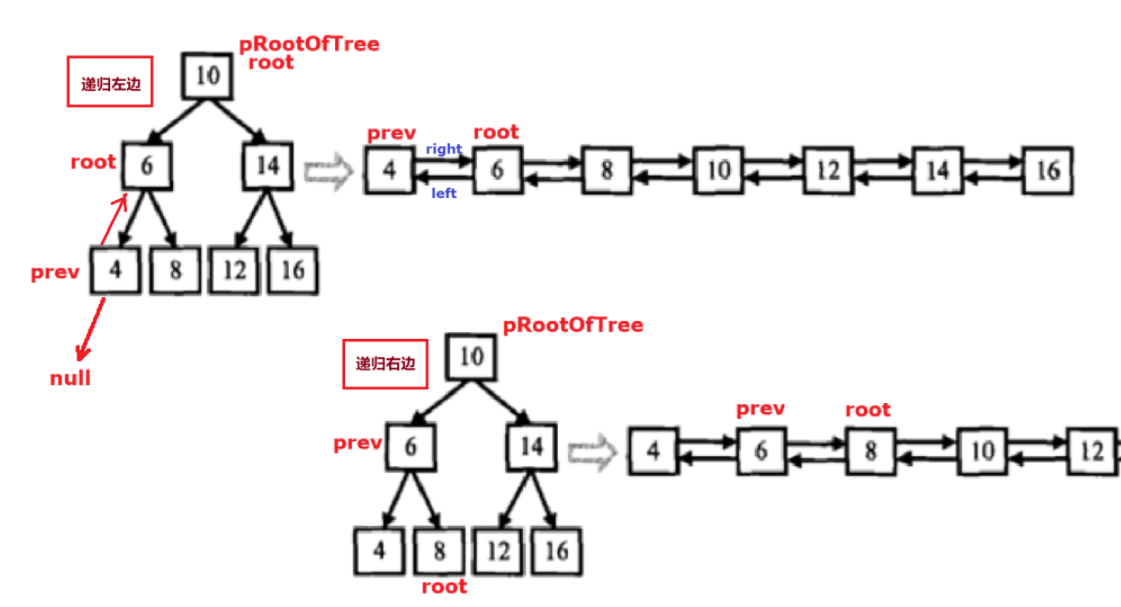
public TreeNode prev = null; // 成员变量public TreeNode Convert(TreeNode pRootOfTree) {if(pRootOfTree == null) return null;ConvertChild(pRootOfTree);TreeNode head = pRootOfTree;while(head.left != null){head = head.left;}return head;}public void ConvertChild(TreeNode root){if(root == null){return;}ConvertChild(root.left); // 遍历左边root.left = prev;if(prev != null){ // 得有 prev 才有 prev.rightprev.right = root;}prev = root;ConvertChild(root.right); // 遍历右边}Debug调试:
public static void main(String[] args) {// 二叉搜索树转为双向链表BinarySearchTree bst = new BinarySearchTree();// 按层次顺序插入节点bst.insert(10);bst.insert(6);bst.insert(14);bst.insert(4);bst.insert(8);bst.insert(12);bst.insert(16);bst.convert(bst.root);}二、搜索
2.1 概念
静态查找,一般不会对区间进行插入和删除操作
1、直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
2、二分查找,时间复杂度为 O(log₂N) ,但搜索前必须要求序列是有序的
动态查找,可能在查找时进行一些插入和删除操作
(更广泛适用于现实中的一些场景,如 1. 考试系统,根据姓名查询考试成绩 2. 通讯录,根据姓名查询联系方法 3. 不重复集合,即需要先搜索关键字是否已经在集合中)
本文涉及的 Map 和 Set 是一种适用动态查找的、专门用来进行搜索的集合容器或者数据结构,其搜索效率与其具体的实例化子类有关。
2.2 模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以模型会有两种:
1、纯 key 模型,比如:
有一个英文词典,快速查找一个单词是否在词典中
快速查找某个名字在不在通讯录中
2、Key-Value 模型,比如:
统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号
Map中存储的就是key-value的键值对,Set中只存储了Key。
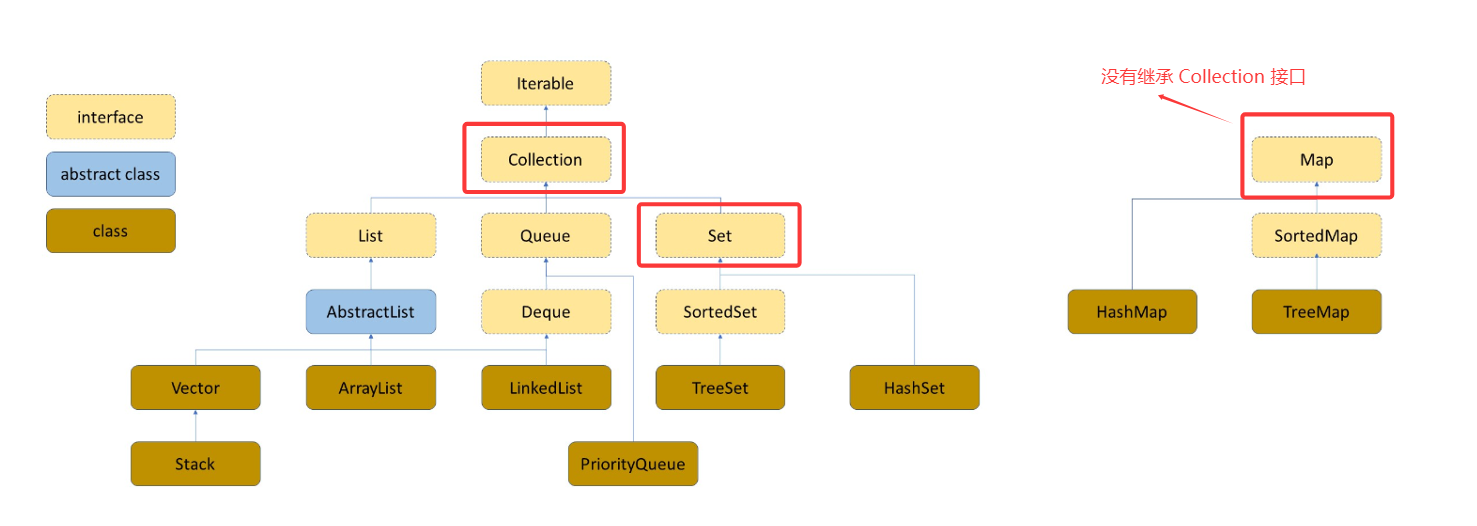 三、Map
三、Map
Map 是一个接口类,该类没有继承自 Collection,该类中存储的是结构的键值对,并且K一定是唯一的,不能重复。
| 常用方法 | 解释 |
|---|---|
| V get(Object key) | 返回 key 对应的 value |
| V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
| V put(K key, V value) | 设置 key 对应的 value |
| V remove(Object key) | 删除 key 对应的映射关系 |
| Set<K> keySet() | 返回所有 key 的不重复集合 |
| Collection<V> values() | 返回所有 value 的可重复集合 |
| Set<Map.Entry<K,V>> entrySet() | 返回所有的 key-value 映射关系 |
| boolean containsKey(Object key) | 判断是否包含 key |
| boolean containsValue(Object value) | 判断是否包含 value |
TreeMap 使用示例:
public class Test {public static void main(String[] args) {TreeMap<String, Integer> map = new TreeMap<>();map.put("mango",11);map.put("XiaoHei",10);map.put("WuXian",3600);System.out.println(map.get("WuXian")); // 输出11//int ret = map.get("hello"); // 相当于拆箱,底层直接调用了 Integer.intValue(),但是该语句会抛出“NullPointerException”异常// 解决上面的问题办法1:不拆箱,输出 nullInteger ret1 = map.get("world");System.out.println(ret1);// 解决办法2:getOrDefault(Object key, V defaultValue)Integer ret2 = map.getOrDefault("nice",100);System.out.println(ret2); // 输出后面设置的默认值100map.remove("mango"); // 剩下2map.put("WuXian",3601);System.out.println(map.size()); // 长度还是 2// 打印所有的 key// keySet 是将map中的所有key放置在 Set 中返回for (String key: map.keySet()) {System.out.print(key + " ");}System.out.println();// 打印所有的 value// values 是将map中的value放置在 Collection 的一个集合中返回for (Integer val : map.values()){System.out.print(val + " ");}System.out.println();// 打印所有的键值对// entrySet(): 将Map中的键值对放在 Set 中返回for(Map.Entry<String, Integer> entry : map.entrySet()){System.out.println(entry.getKey() + "-->" + entry.getValue());}}
}注意:
1、Map 是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类 TreeMap 或者 HashMap;
2、Map 中存放键值对中的 key 是唯一的,value 是可以重复的;
3、在 TreeMap 中插入键值对时,key 不能为空,否则抛出 NullPointerException 异常,value 可以为空。但是 HashMap 的 key 和 value 都可以为空;
4、Map 中的 key 可以全部分离出来,存储到 Set 中来进行访问;
5、Map 中的 value 可以全部分离出来,存储在 Collection 的任何一个子集合中;
6、Map 中键值对的 key 不能直接修改,value 可以修改,如果要修改 key ,只能先将该 key 删除掉,然后再来进行重新插入;
7、TreeMap 和 HashMap 的区别
| Map 底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找 时间复杂度 | O(log₂N) | O(1) |
| 是否有序 | 关于 Key 有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key 必须能够比较,否则会抛出 ClassCastException 异常 | 自定义类型需要覆写 equals 和 hashCode 方法 |
| 应用场景 | 需要 Key 有序场景下 | Key 是否有序不关心,需要更高的 时间性能 |
四、Set
Set 与 Map 主要的不同有两点:Set 是继承自 Collection 的接口类,Set 中只存储了 Key。
(遍历方法的不同在于 Set 可以使用迭代器遍历,而 Map 没有迭代器)
| 常用方法 | 解释 |
|---|---|
| boolean add(E e) | 头插法添加元素,但重复元素不会被添加成功 |
| void clear() | 清空集合 |
| boolean contains(Object o) | 判断 o 是否在集合中 |
| Iterator iterator() | 返回迭代器 |
| boolean remove(Object o) | 删除集合中的 o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object[] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection c) | 集合c中的元素是否在set中全部存在,是返回true,否则返回 false |
| boolean addAll(Collection c) | 将集合c中的元素添加到set中,可以达到去重的效果 |
TreeSet 的使用示例:
public static void main(String[] args) {TreeSet<String> set = new TreeSet<>();set.add("联系人1");set.add("母上大人");set.add("父亲");set.add("啰嗦老太婆");set.add("联系人1");Iterator<String> it = set.iterator(); // 迭代器while (it.hasNext()){System.out.print(it.next() + " ");}System.out.println();System.out.println(set.remove("啰嗦老太婆"));//set.add(null); // 抛出空指针异常Object[] tmp = set.toArray(); // 将 set 中的元素转换成数组返回for (Object o: tmp) {System.out.println(o);}}注意:
1、Set 是继承自 Collection 的一个接口类;
2、Set 中只存储了 key,并且要求 key 一定要唯一;
3、TreeSet 的底层是使用 Map 来实现的,其使用 key 与 Object 的一个默认对象作为键值对插入到 Map 中的;
4、Se t最大的功能就是对集合中的元素进行去重:
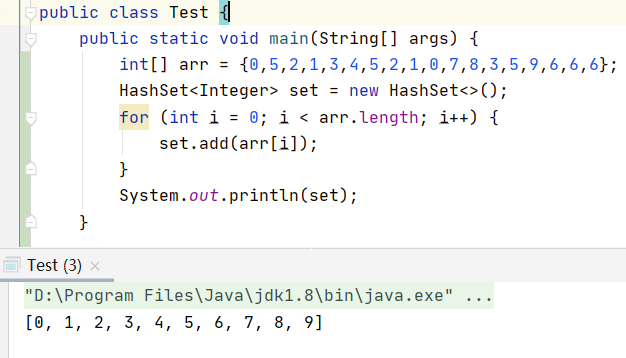
扩展简单使用方法:得到数组中第一个重复出现的元素:
public static void main5(String[] args) {int[] arr = {0,5,2,1,3,4,5,2,1,0,7,8,3,5,9,6,6,6};HashSet<Integer> set = new HashSet<>();// 得到第一次重复出现的值for (int i = 0; i < arr.length; i++) {if (!set.contains(arr[i])){set.add(arr[i]);}else{System.out.println(arr[i]);return;}}}5、 实现 Set 接口的常用类有 TreeSet 和 HashSet,还有一个 LinkedHashSet,LinkedHashSet 是在 HashSet 的基础上维护了一个双向链表来记录元素的插入次序;
6、Set 中的 Key 不能修改,如果要修改,先将原来的删除掉,然后再重新插入;
7、TreeSet 中不能插入 null 的 key,HashSet 可以;
8、TreeSet 和 HashSet 的区别:
| Set 底层结构 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找 时间复杂度 | O(log₂N) | O(1) |
| 是否有序 | 关于Key有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 1. 先计算key哈希地址 2. 然后进行插入和删除 |
| 比较与覆写 | key 必须能够比较,否则会抛出 ClassCastException 异常 | 自定义类型需要覆写 equals 和 hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的 时间性能 |
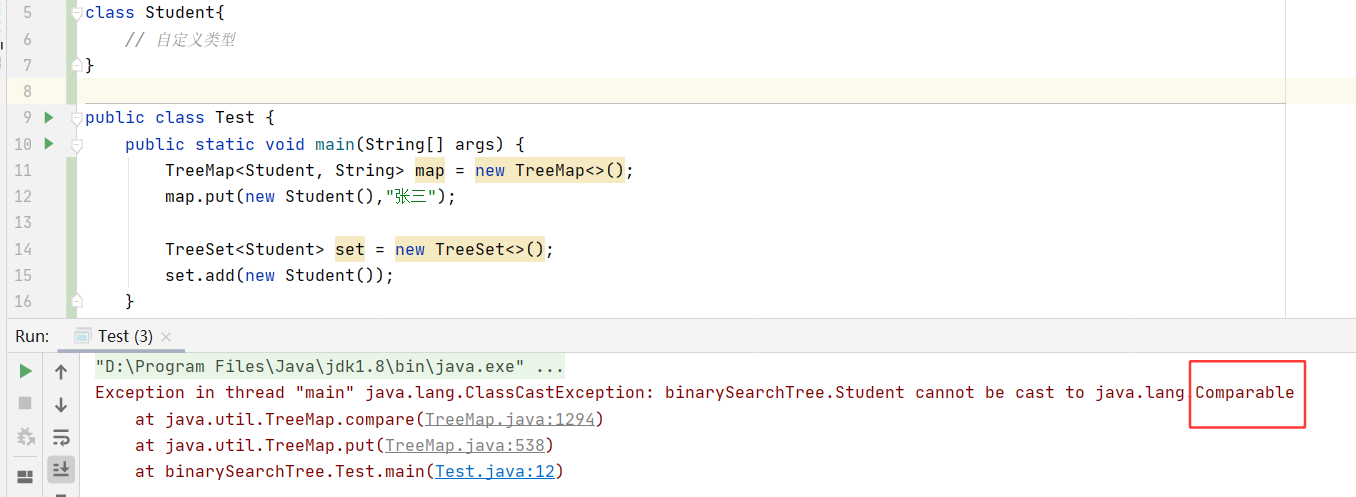
=> TreeMap 和 TreeSet 中 的值类型只要是自定义类型,涉及比较大小的,必须实现 Comparable / Compartor 接口,并重新比较方法。
因为哈希表内容比较重要,因此,哈希表 实现与oj题放到下一篇文章。