【ElasticSearch】ElasticSearch Overview
ES Overview

ES中的核心概念
首先需要了解Lucene,是一套信息检索工具包,就是一个jar包,但是不包含搜索引擎。她里面有一些索引结构(相当于数据库中的表)、读写索引的工具、排序、搜索规则等等工具类那么我们的ES就是基于Lucene工具包做了一些增强和封装。ES是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RestFul API来隐藏Lucene的复杂性,从而让全文检索变得简单。
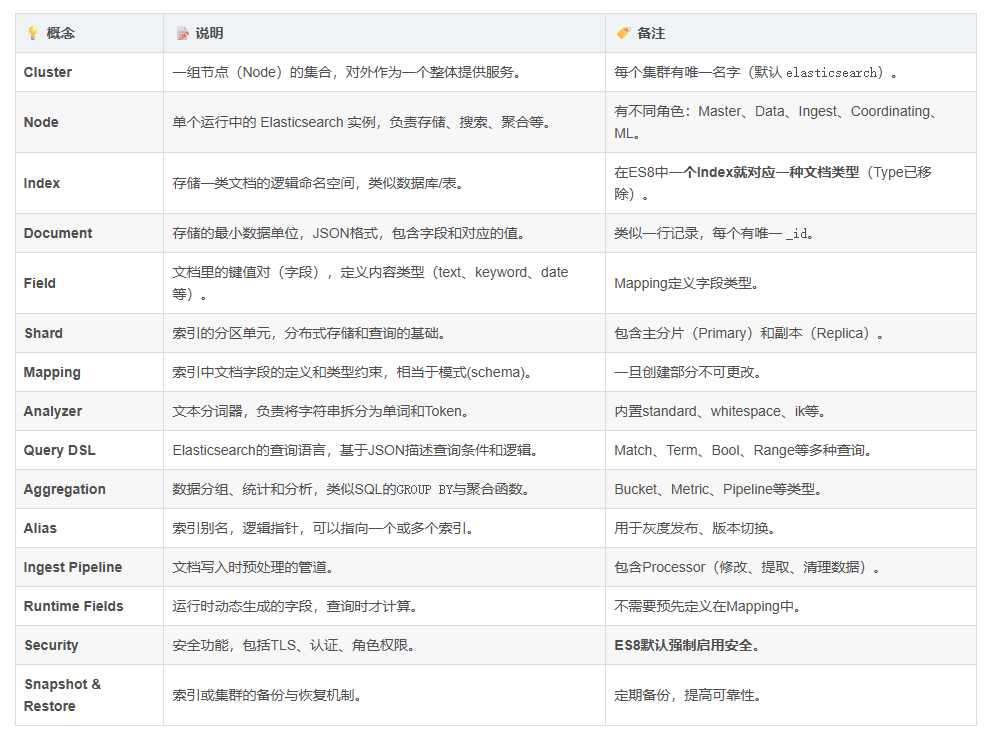
ES物理架构
Distributed architecture | Elastic Docs
Node
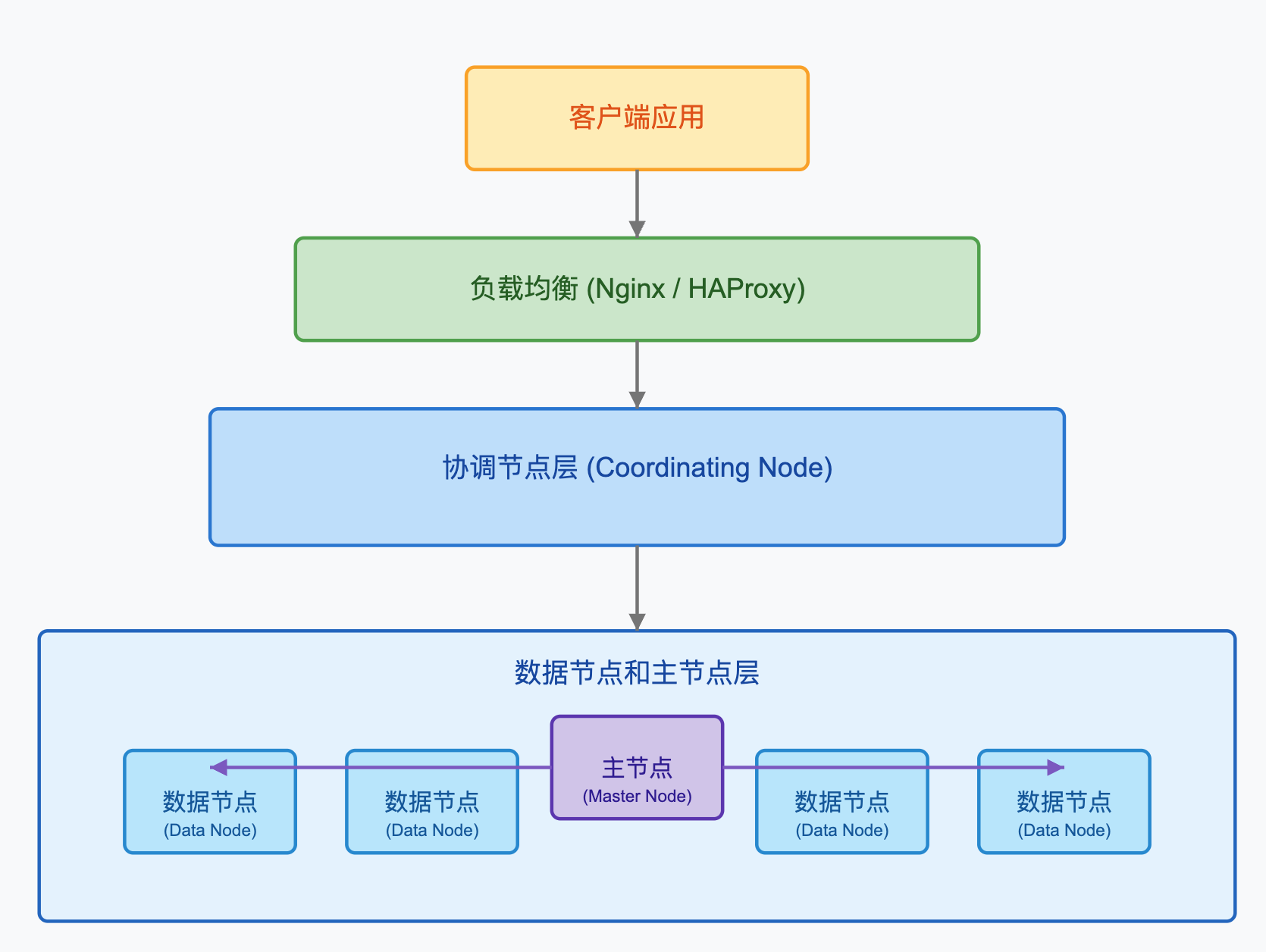
在ES集群中,节点根据其配置和用途可以分为以下几种类型:
主节点(Master Node):负责轻量级集群管理操作,如创建或删除索引,跟踪集群中的节点,以及决定将分片分配给哪个节点。
数据节点(Data Node):存储数据并执行数据相关操作,如CRUD,搜索和聚合。
协调节点(Coordinating Node):将请求路由到正确的节点,例如,将批量索引请求路由到数据节点。
ingest节点(Ingest Node):对文档进行预处理操作,构成一个ingest pipeline。
机器学习节点(ML Node):专门用于机器学习任务。
Master Node选举
主节点的选举是通过一种名为Zen Discovery的机制完成的,在ES 7.0之后,使用了新的基于Raft算法的集群协调层。
主节点选举过程:
- 每个节点启动时,会尝试加入集群
- 如果是第一个节点,它将自动成为主节点
- 如果集群已经存在,它将尝试联系现有的主节点
- 如果现有主节点不可用,符合主节点资格的节点将通过投票选举新的主节点
这里有个常见的问题是脑裂(Split-Brain),即由于网络问题,集群分裂成两部分,各自认为对方已经下线,进而各自选出自己的主节点。ES通过设置最小主节点数(minimum_master_nodes)解决这个问题(在7.0之后通过discovery.zen.minimum_master_nodes参数设置)
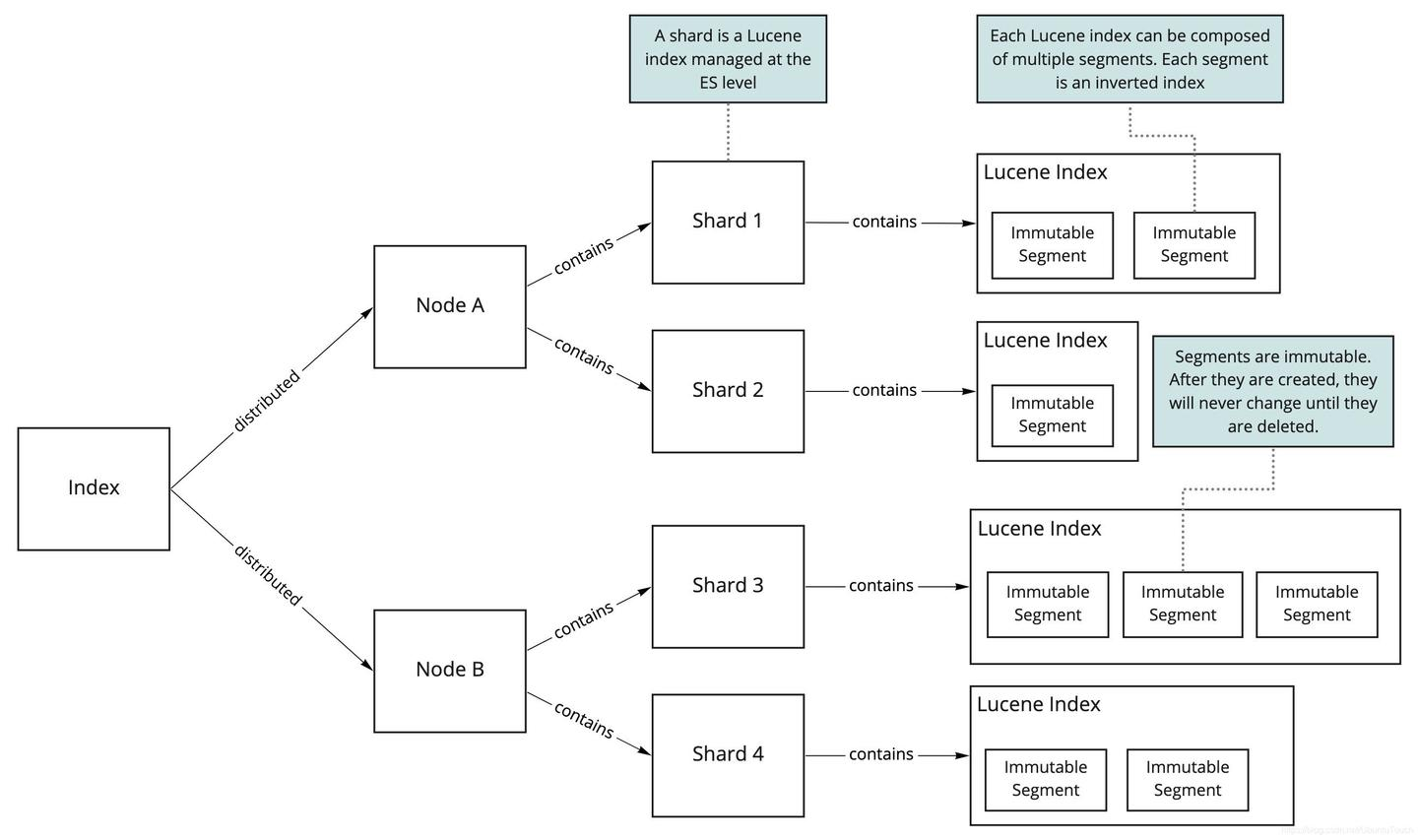
Shard
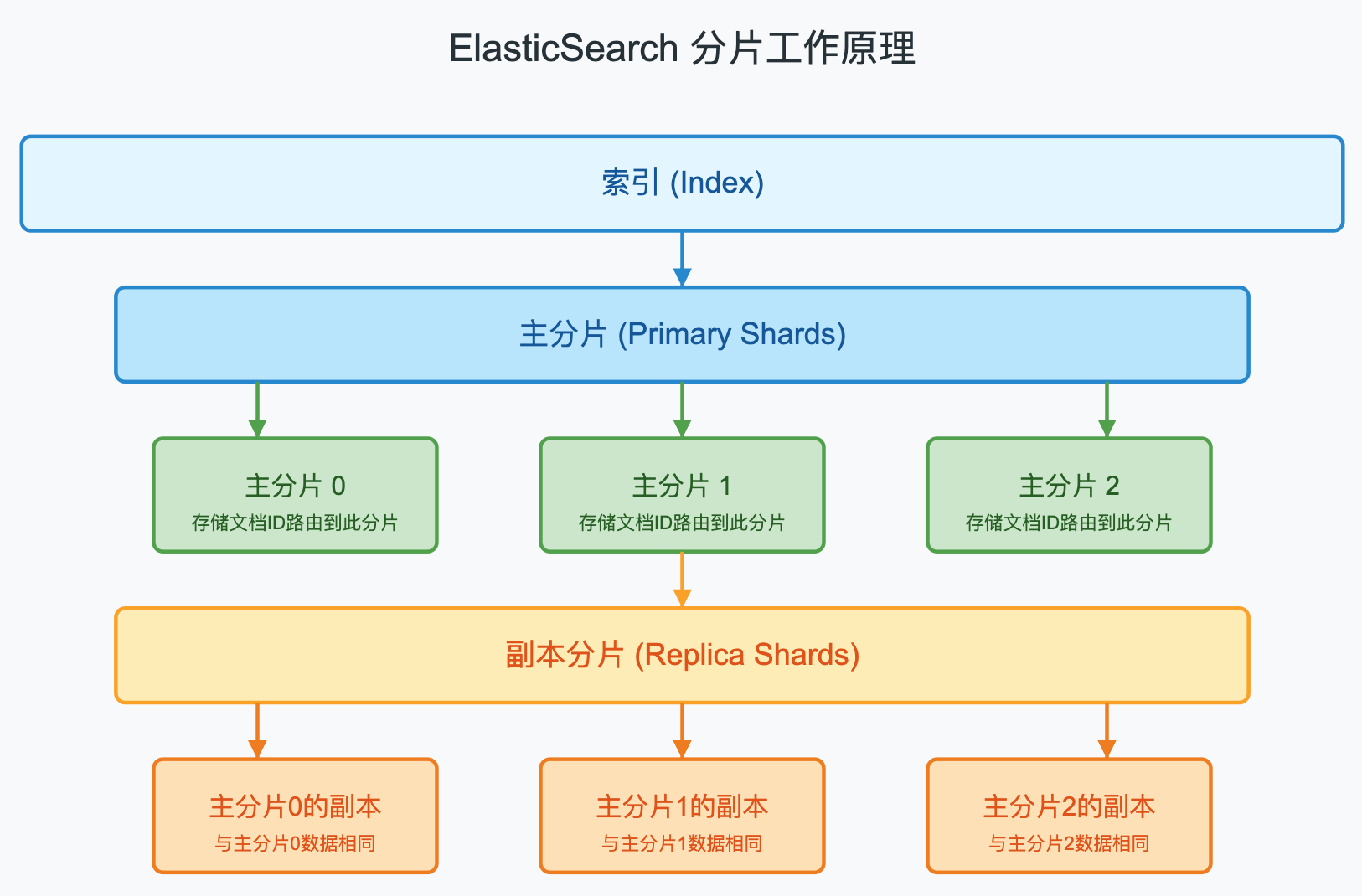
Index是ES存储数据的逻辑单元,而Shard是物理存储单元。一个索引可以包含多个分片,这些分片分布在集群中的不同节点上。
在ES中,当创建索引时,需要指定分片数量,默认情况下一个索引有5个主分片。分片数量是在索引创建时确定的,一旦创建,无法更改,只能通过重建索引的方式进行修改。
每个分片都是一个完整的Lucene索引实例,包含了一部分数据。ES通过分片实现数据的分布式存储,提高系统的吞吐量和可用性。
分片路由的过程如下:
shard_num = hash(routing_key) % num_primary_shards
其中,routing_key默认是文档的ID,也可以自定义;num_primary_shards是主分片的数量。通过这个公式,ES可以确定一个文档应该存储在哪个分片上。
副本分片是主分片的完整拷贝,它们有两个主要作用,并且副本分片不会和主分片存在于同一个节点上,这是为了防止单点故障。每个分片都是一个 Lucene 索引,这些索引中的每个索引都可以具有多个 segment,每个 segement 都是一个反向索引。
- 提高系统的容错性:如果某个节点失效,导致上面的主分片丢失,副本分片可以提升为主分片,保证数据不丢失。
- 提高系统的查询性能:查询请求可以由主分片或副本分片处理,从而提高系统的查询性能。
ES创建索引与检索
创建索引
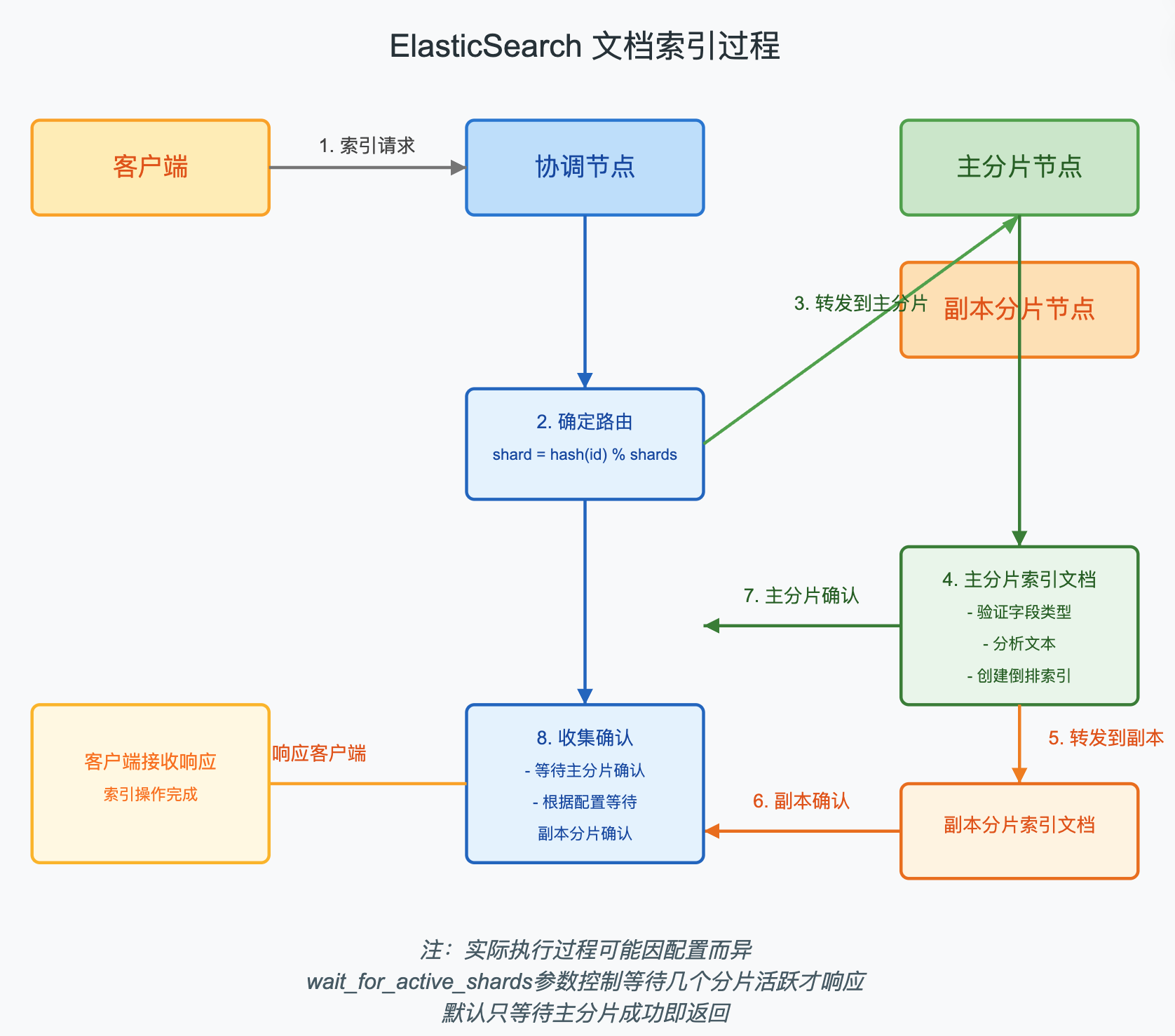
- 客户端发送索引请求到集群中的一个节点(协调节点)
- 协调节点根据文档ID确定文档应该存储到哪个分片上
- 协调节点将请求转发到主分片所在的节点
- 主分片节点执行索引操作,成功后将索引操作转发到副本分片
- 所有副本分片成功后,主分片向协调节点报告成功,协调节点向客户端报告成功
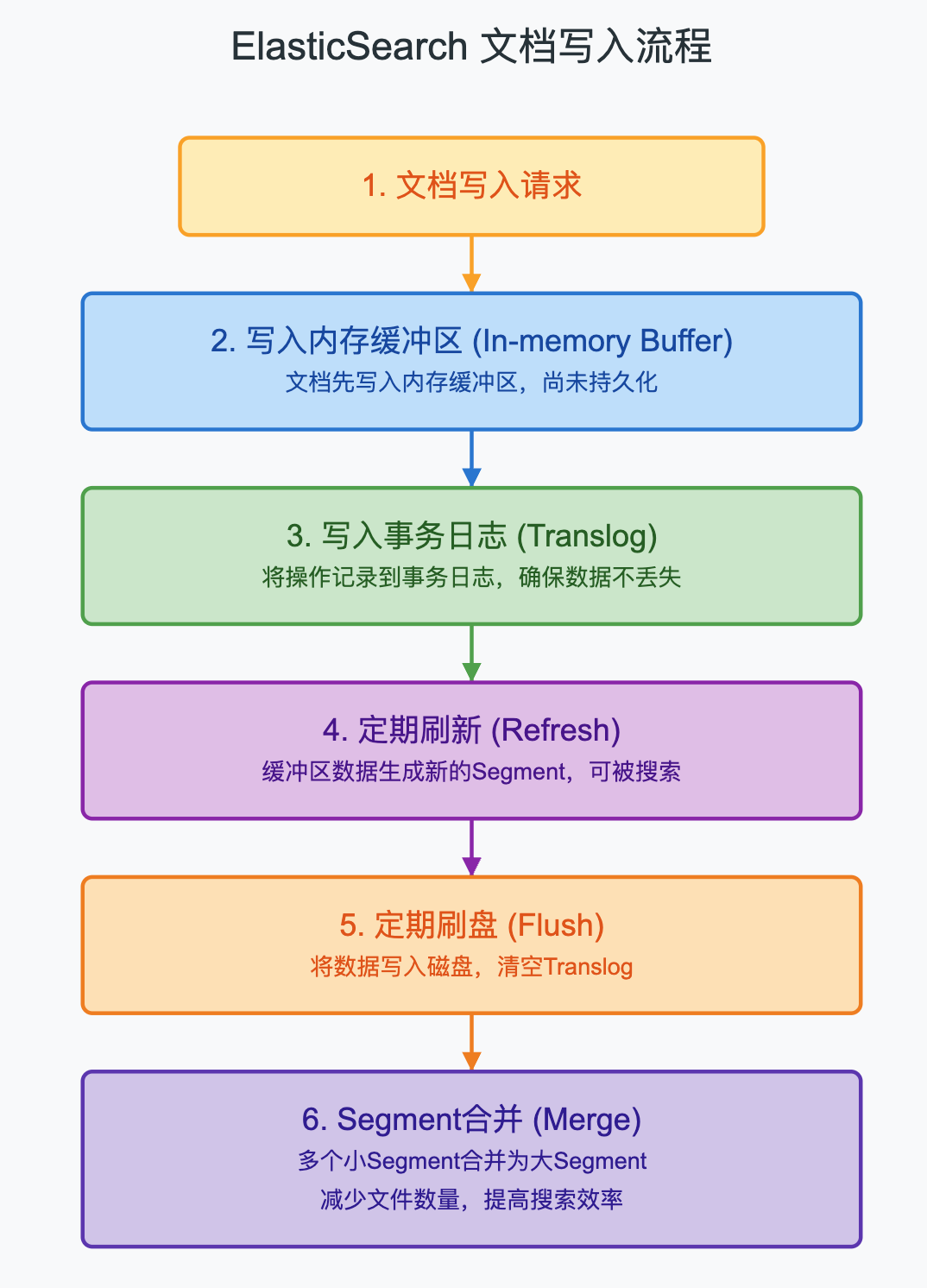
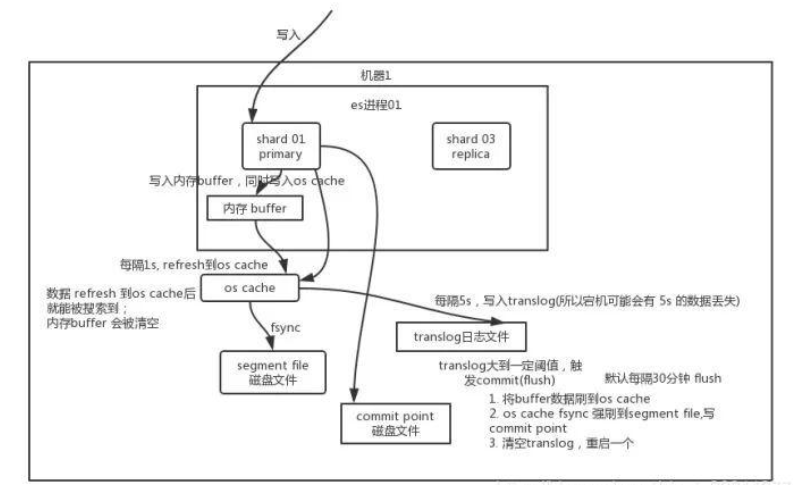
- 内存缓冲区:当文档被索引时,首先被写入内存缓冲区。
- Translog:同时写入事务日志,以防内存数据丢失。
- Refresh:定期(默认每1秒)将内存缓冲区的数据写入一个新的Segment,使其对搜索可见,但此时还未真正持久化到磁盘。
- Flush:定期(默认每30分钟或当Translog过大时)将缓存的数据写入磁盘,并清空Translog。
- Merge:随着时间推移,Segment会越来越多,ES会在后台自动合并多个小的Segment为一个大的Segment,提高搜索效率。
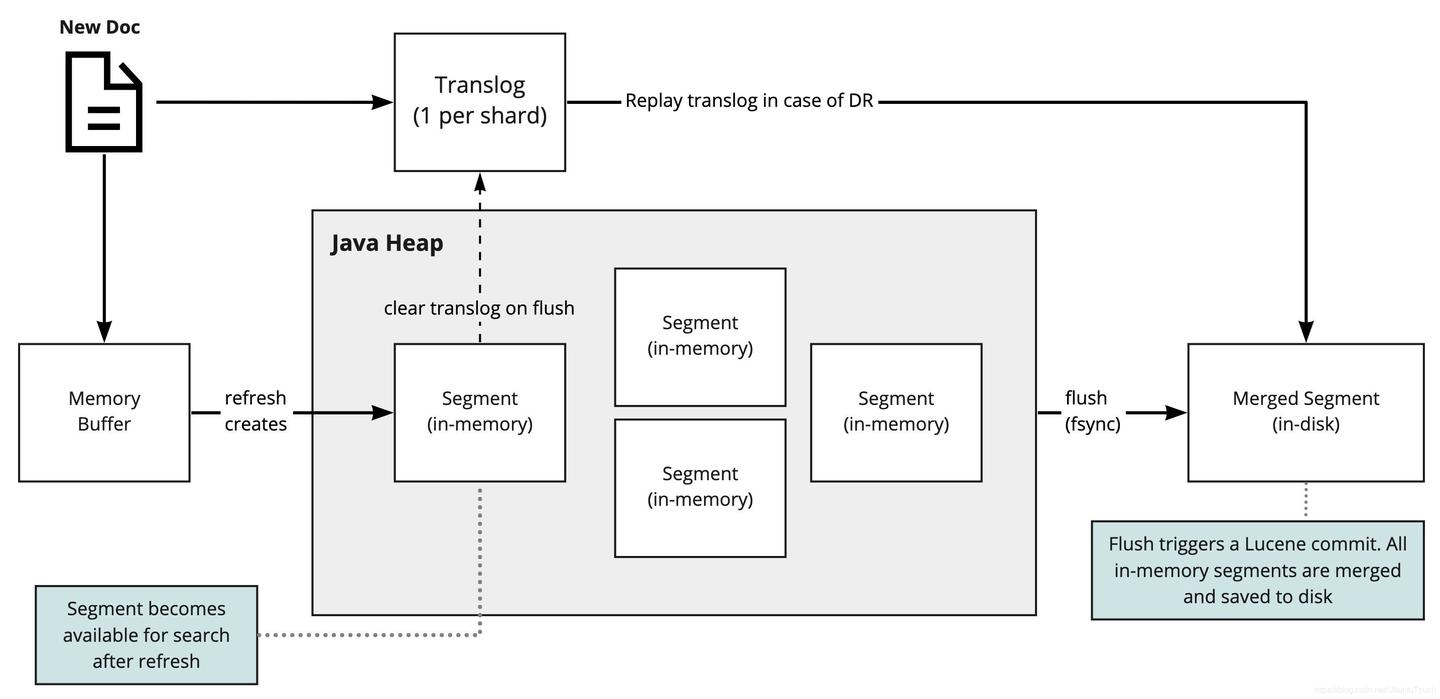
在此图中,我们可以看到 Elasticsearch 如何存储新文档。一旦文档到达,它将被提交到一个称为 “translog” 的事务日志和一个内存缓冲区。
事务日志是ES如何恢复仅在发生故障时在内存中的数据的方式。当 “刷新/refresh” 操作发生时,内存缓冲区中的所有文档将生成一个内存中的 Lucene segment。此操作用于使新文档可供搜索。
最终,根据不同的触发条件(稍后将对此进行详细介绍),所有这些段都合并为一个 segment 并保存到磁盘中,并且清除了事务日志。
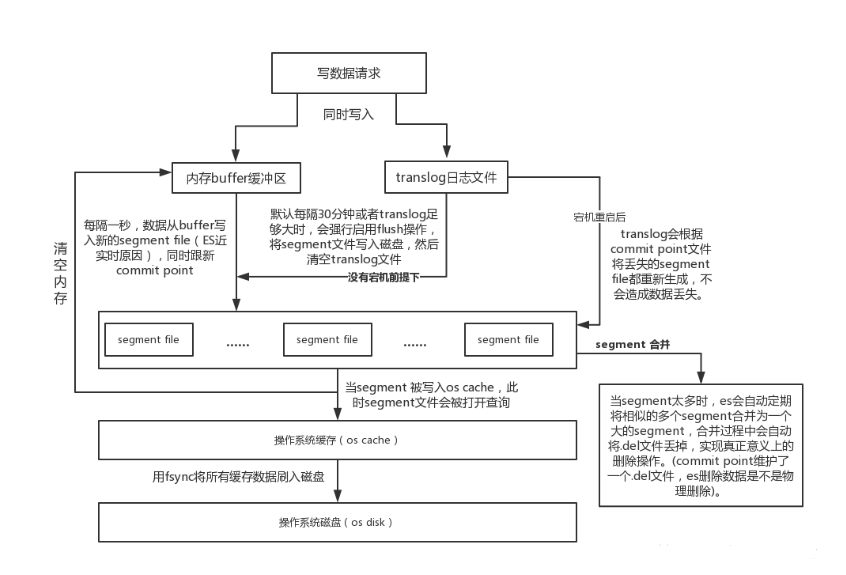
数据写入ES集群,主要是经过以下2个主要步骤:
1. 读取数据 -> 验证(master节点分发给data节点处理,或直接访问data节点主分片)
2. 同时写入buffer缓冲区和translog日志文件 -> 生成segment file -> 合并小segment file生成大segment file -> 将合并的segment file刷写到系统缓存,此时可以数据可以被搜索到(refresh) -> 用fsync将所有缓存数据刷写到磁盘(flush)。
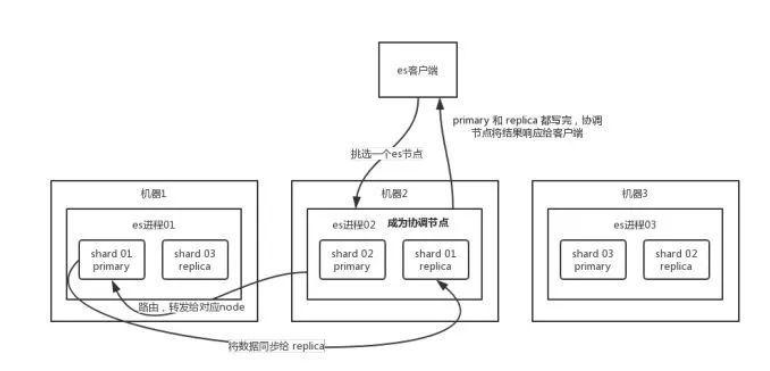
客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node(协调节点)。
coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)。
实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node。
coordinating node 如果发现 primary node 和所有 replica node 都搞定之后,就返回响应结果给客户端。
检索 Search
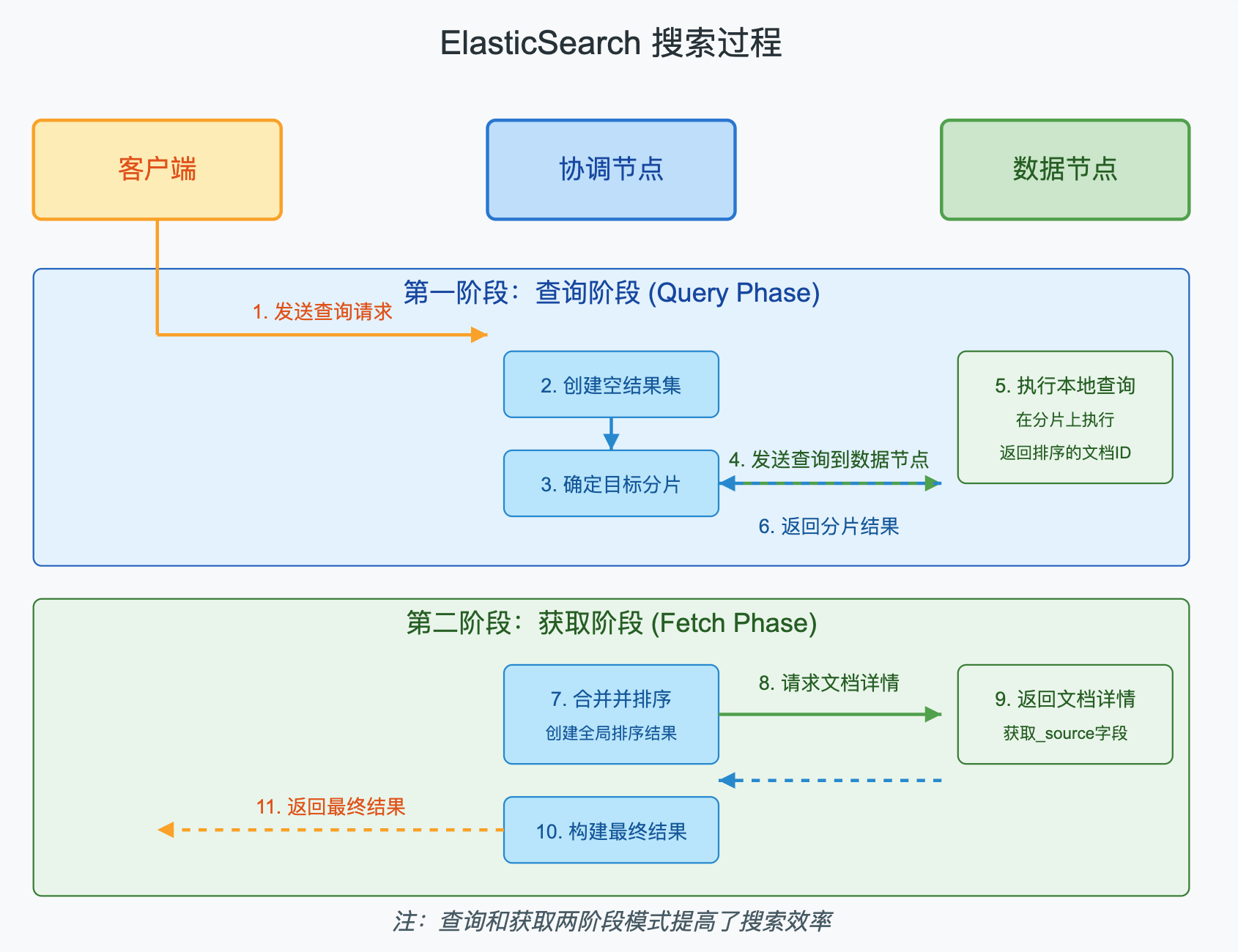
ElasticSearch的搜索过程分为两个阶段:查询阶段和获取阶段。
查询阶段:
- 客户端发送搜索请求到协调节点
- 协调节点创建一个空的优先队列,用于存储排序后的文档
- 协调节点确定要查询的分片,并向相关数据节点发送查询请求
- 每个数据节点在本地执行查询,并返回一个包含文档ID和排序值的轻量级结果集
获取阶段:
- 协调节点合并所有分片的结果,并根据指定的排序条件对文档进行排序
- 协调节点向相关数据节点请求详细的文档内容
- 数据节点返回文档详情
- 协调节点构建最终的搜索结果,并返回给客户端
客户端发送请求到一个 coordinate node。
协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard,都可以。
query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
写请求是写入 primary shard,然后同步给所有的 replica shard;
读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
ES REST API
Elasticsearch8(ES)保姆级菜鸟入门教程_elasticsearch菜鸟教程-CSDN博客
Lucene
Apache Lucene - Welcome to Apache Lucene
Lucene的原理我说白话一点,就是先把被搜索内容按照一定规则进行分词并存储,生成一个目录,然后把你输入的搜索关键词也进行分词,然后与前面生成的目录中的关键词进行匹配,如果匹配到,就可以快速定位到该被搜索内容的存储位置,从而实现搜索。
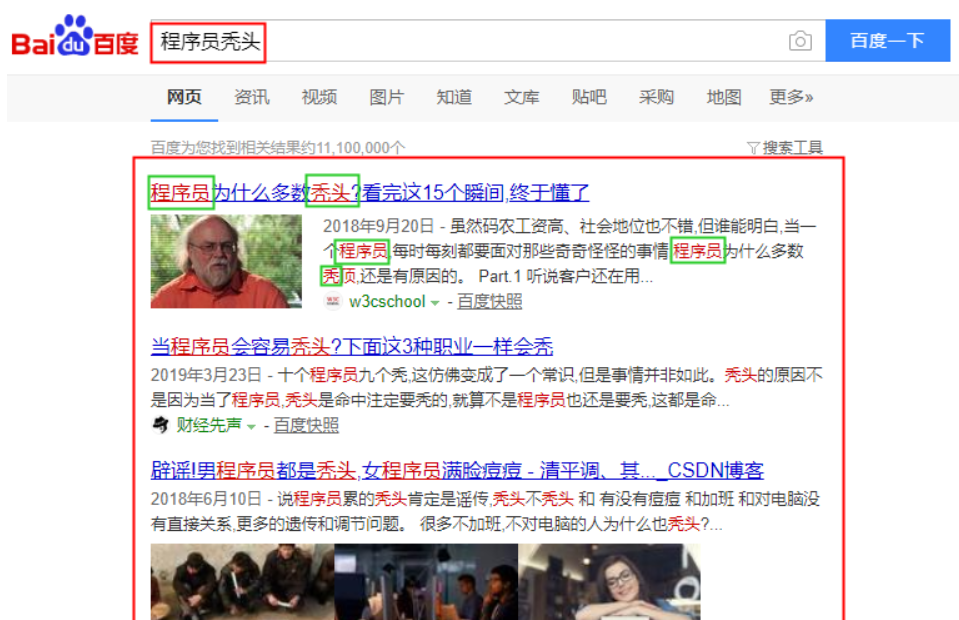
如图,比如我搜索了程序员秃头,搜索引擎一般会根据一定的拆分规则,把我输入的“程序员秃头”拆分成:程序员,秃头,头等关键字。然后与爬虫爬取到的大量文档里的关键词进行匹配(这些大量文档会按照一定规则预先分词,建立索引,然后存储起来),如果匹配到了就可以返回给用户了,返回的结果可以对关键词添加一些“高亮”,标红等特效,也可以按照一定规则对搜索结果进行排序。
正向索引
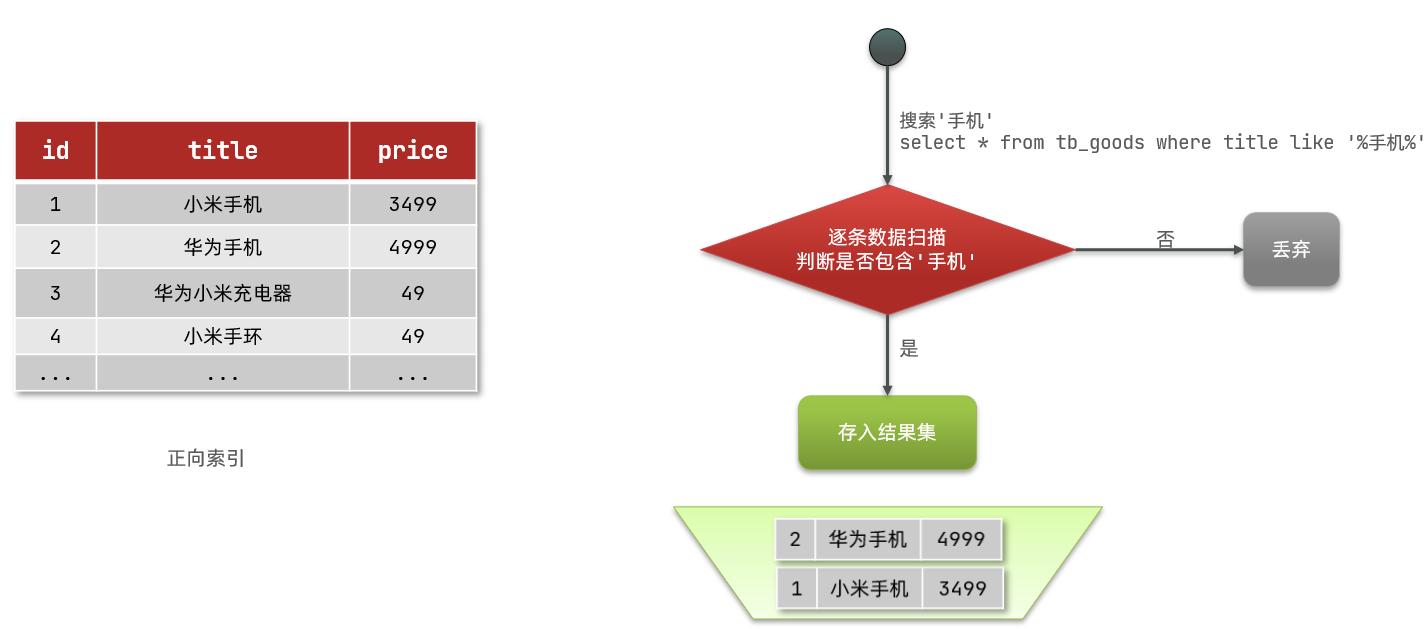
如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。
倒排索引
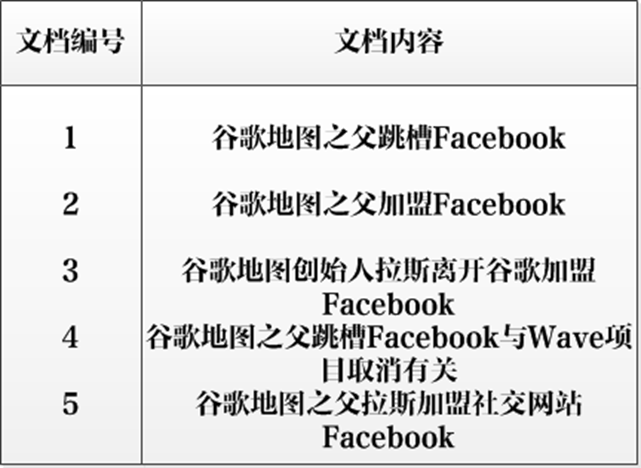
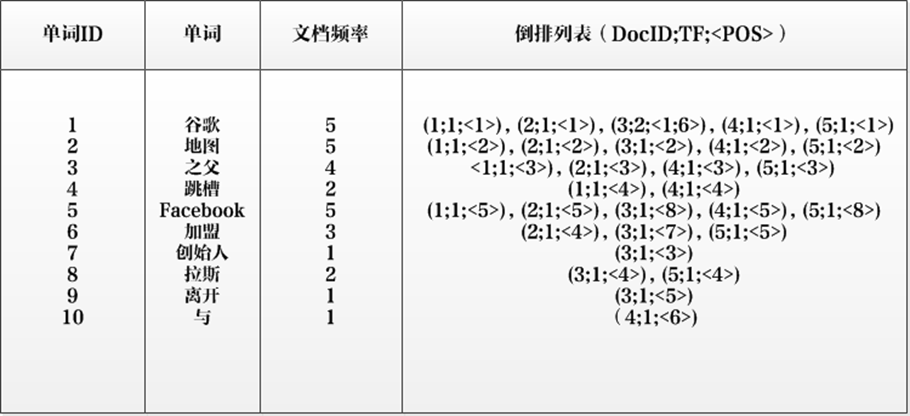
倒排索引的建立步骤:
①先对原始文档中的内容按照一定规则进行分词,至于如何分先不用管,我后面会讲到。
②然后对分词后的单词在原始文档中进行定位,比如“谷歌”在原始文档中的1-5号文档都有出现过,所以谷歌的倒排列表就是:1,2,3,4,5. 其它倒排列表以此类推。
有了这样一套对应列表之后,下次用户如果输入了“网站”这个关键词,系统就可以通过倒排列表快速定位到原始文档中的第5项数据,类似于生成了一本书的一个目录,告诉你几个关键词,可以在目录中快速定位具体的文档在多少页,不用再一页一页翻了。
看到这里你应该明白倒排索引的原理了,可以先思考下为啥叫“倒排”索引,而不是别的名字?
回答这个问题前,先看下什么是正向索引:正向索引建立的关系是由文档->关键词的,也就是给定一篇文档,记录关键词在文档中出现的位置,通过文档来关联关键词的,这种方式在数据量小的情况下完全OK,但互联网这片大海中,文档的量及是宇宙级的,这种方式要扫描的文档驴辈子都扫不完。倒排索引正好是逆向思维,把文档的关键词提取,然后通过关键词取关联文档,这样就极大的减轻了扫描的量级。
关于倒排索引就提这么多,实际上要比这个复杂一些,感兴趣的建议读完之后可以回头来深入研究,以免打断思路,这里直接给出我援引的博主图片的博客地址:
倒排索引原理-CSDN博客
【大数据】Lucene全文搜索引擎入门篇(零基础小白也适用)_lucene入门教程-CSDN博客
IK分词器
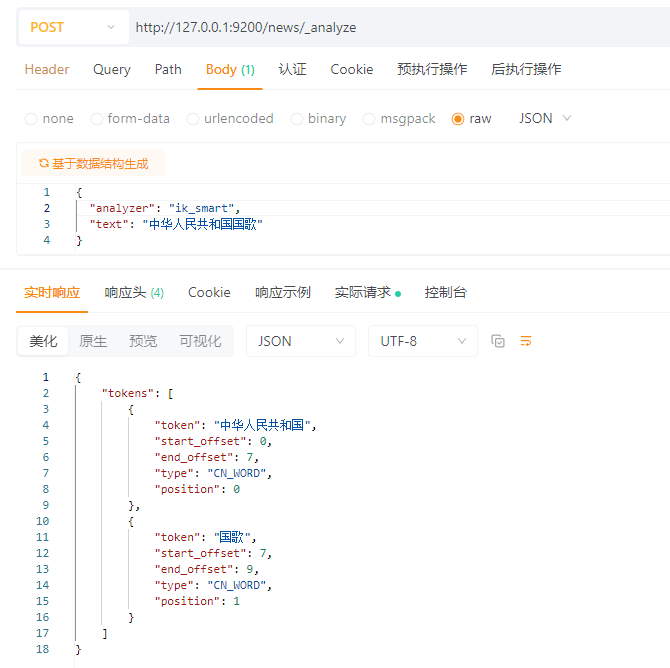
ik分词器支持两种模式,ik_max_word,ik_smart

ik_max_word:
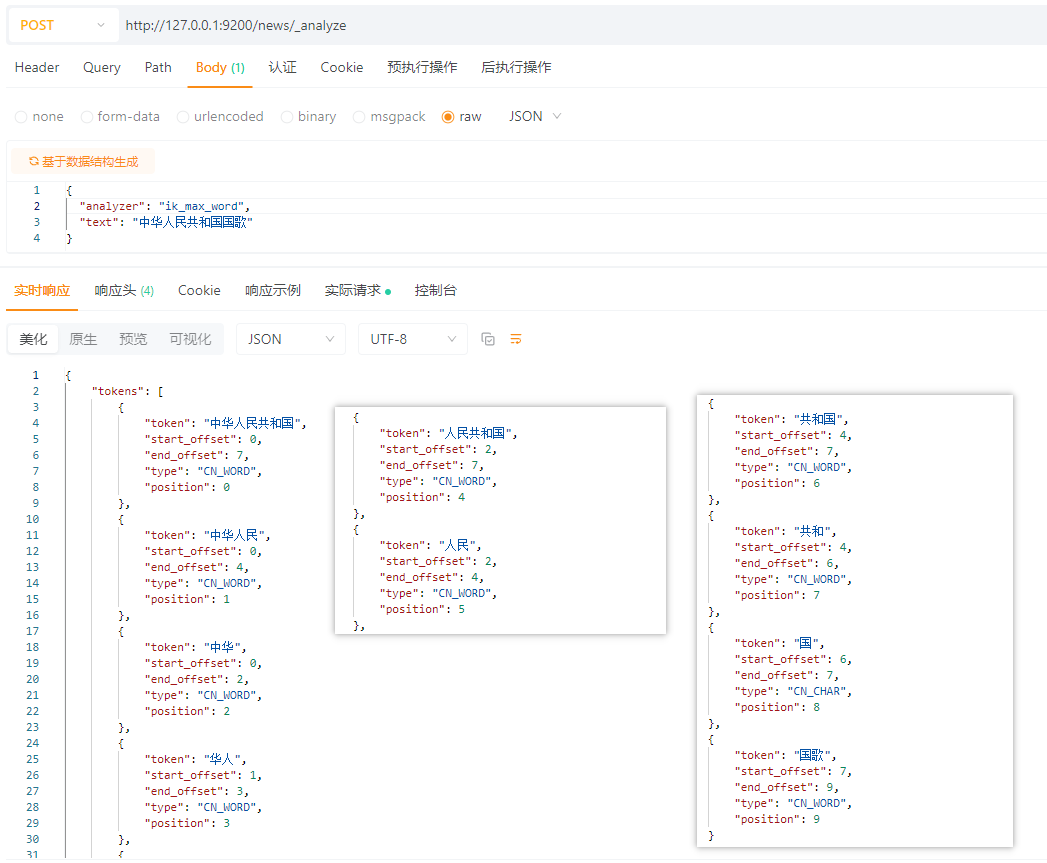
ik_smart
Lucene quick start
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.hanson</groupId><artifactId>lucene-spike</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>21</maven.compiler.source><maven.compiler.target>21</maven.compiler.target><org.apache.lucene>8.3.0</org.apache.lucene><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>${org.apache.lucene}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>${org.apache.lucene}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>${org.apache.lucene}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queries</artifactId><version>${org.apache.lucene}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>${org.apache.lucene}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-memory</artifactId><version>${org.apache.lucene}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-smartcn</artifactId><version>${org.apache.lucene}</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-join</artifactId><version>${org.apache.lucene}</version></dependency></dependencies>
</project>create index
package com.hanson;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;import java.io.IOException;
import java.nio.file.Paths;public class Search {private final static String IDX_DIR = "C:\\lucene";public static void main(String[] args) {try {//创建索引库对象Directory directory = FSDirectory.open(Paths.get(IDX_DIR));//索引读取工具IndexReader indexReader = DirectoryReader.open(directory);//索引搜索工具IndexSearcher indexSearcher = new IndexSearcher(indexReader);//创建查询解析器QueryParser parser = new QueryParser("content", new SmartChineseAnalyzer());//创建查询对象Query query = parser.parse("浓眉");// WildcardQuery 通配符查询
// Query query = new WildcardQuery(new Term("title", "*三*"));//获取搜索结果 第二个参数n是返回多少条,可以根据情况限制// 创建模糊查询对象:允许用户输错。但是要求错误的最大编辑距离不能超过2// 编辑距离:一个单词到另一个单词最少要修改的次数 loohan --> laohan 需要编辑1次,编辑距离就是1// 可以手动指定编辑距离,区间[0,2]
// Query query = new FuzzyQuery(new Term("title","laohan"),1);// 针对数值字段的范围查询,参数:字段名称,最小值、最大值、是否包含最小值、是否包含最大值
// Query query = NumericRangeQuery.newLongRange("id", 2L, 2L, true, true);/*** 布尔查询:* 布尔查询本身没有查询条件,可以把其它查询通过逻辑运算进行组合* 交集:Occur.MUST + Occur.MUST* 并集:Occur.SHOULD + Occur.SHOULD* 非:Occur.MUST_NOT*/
// Query query1 = NumericRangeQuery.newLongRange("id", 1L, 3L, true, true);
// Query query2 = NumericRangeQuery.newLongRange("id", 2L, 4L, true, true);
//// 创建布尔查询的对象
// BooleanQuery query = new BooleanQuery();
//
//// 组合其它查询
// query.add(query1, BooleanClause.Occur.MUST_NOT);
// query.add(query2, BooleanClause.Occur.SHOULD);
//
// search(query);// 设置HTML格式化样式
// Formatter formatter = new SimpleHTMLFormatter("<em>", "</em>");
// QueryScorer scorer = new QueryScorer(query);
//// 创建高亮工具
// Highlighter highlighter = new Highlighter(formatter, scorer);
//
////省略对socre[]循环部分...
//
////通过分词器确定需要高亮显示的关键词
// String highlight = highlighter.getBestFragment(new SmartChineseAnalyzer(), "content", "浓眉哥");
////展示效果
// System.out.println("高亮展示的关键词:" + highlight);//老版本的Lucene可以采用这种方式排序
//设置排序字段
// Sort sort = new Sort(new SortField("id", Type.LONG,true));
////获取搜索结果
//设置排序字段
// Sort sort = new Sort(new SortField("title", Type.LONG,true));
//获取搜索结果 两个布尔类型参数,第一个是:doDocScores,第二个是doMaxScore
// TopDocs docs = indexSearcher.search(query,10,sort,true,true); TopDocs docs = indexSearcher.search(query, 10);TopDocs docs = indexSearcher.search(query, 10);//获取总条数System.out.println("本次查询共搜索到:" + docs.totalHits + " 条相关数据");//获取得分对象ScoreDoc[] scoreDocs = docs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {//获取文档编号int docId = scoreDoc.doc;//根据文档编号获取文档内容Document document = indexReader.document(docId);System.out.println("id: " + docId);System.out.println("title: " + document.getField("title"));System.out.println("content: " + document.getField("content"));System.out.println("搜索得分: " + scoreDoc.score);}} catch (IOException e) {e.printStackTrace();} catch (ParseException e) {e.printStackTrace();}}
}
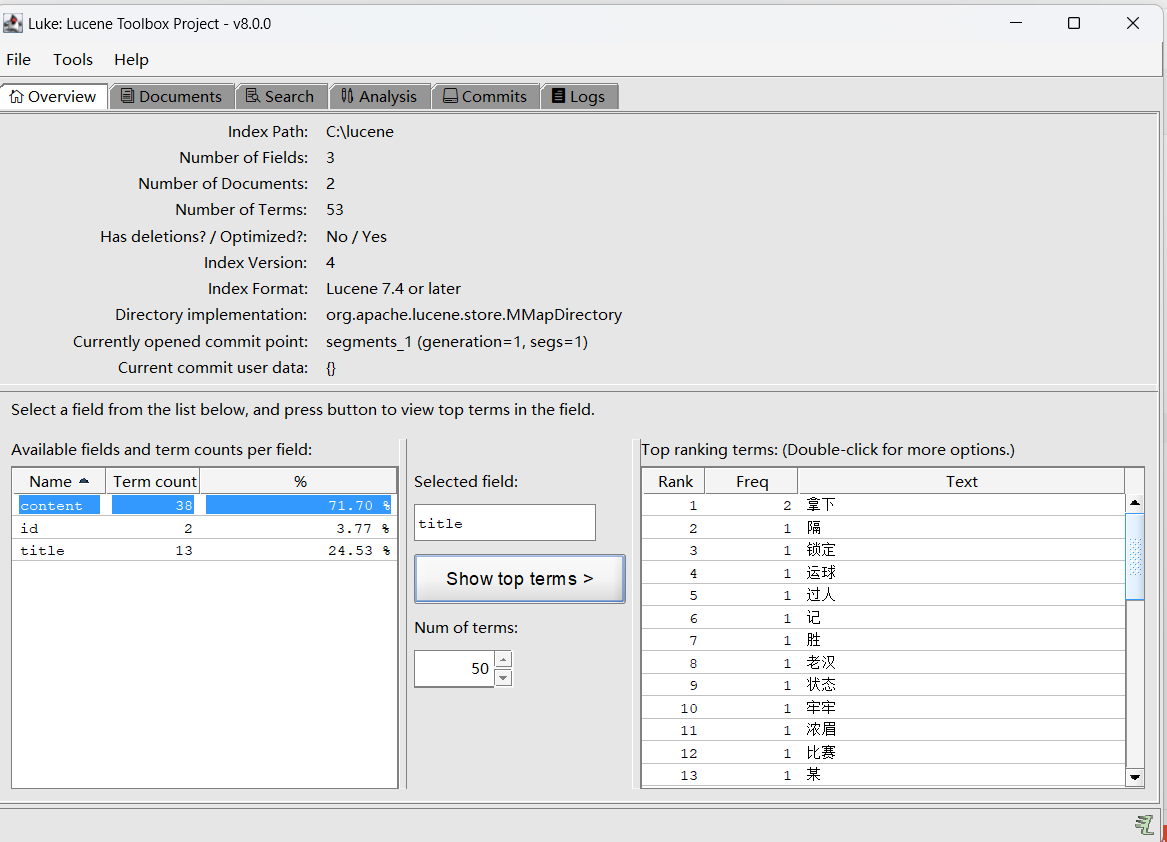
到这里说明索引文件已被创建,那么索引里到底有啥玩意,想窥探一下但发现根本打不开,这个时候lukeall大哥就登场了:下载地址:https://github.com/DmitryKey/luke/releases
一定要匹配你使用的lucene版本,否则可能解析报错。
下载后解压打开,然后选择你索引所在目录,就可以看到分词详情了:
update
package com.hanson;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;import java.io.IOException;
import java.nio.file.Paths;public class Update {private final static String IDX_DIR = "C:\\lucene";public static void main(String[] args) {IndexWriter indexWriter = null;try {//创建目录Directory directory = FSDirectory.open(Paths.get(IDX_DIR));//创建配置对象IndexWriterConfig config = new IndexWriterConfig(new SmartChineseAnalyzer());//创建索引写出工具indexWriter = new IndexWriter(directory, config);//创建新的文档数据Document document = new Document();document.add(new StringField("id","1L", Field.Store.YES));document.add(new TextField("title","湖人三大核心全面爆发,仅两节比赛就领先对手三十分!", Field.Store.YES));//修改索引,修改指定文档中所有的匹配字段的索引,一般选id,因为id唯一indexWriter.updateDocument(new Term("id","1L"),document);indexWriter.commit();// //根据匹配关键词来删除
// writer.deleteDocuments(new Term("id", "1L"));
//
////根据匹配数字范围来删除
// Query query = NumericRangeQuery.newLongRange("id", 1L, 2L, true, true);
// writer.deleteDocuments(query);
//
////删除全部
// write.deleteAll();
// } catch (IOException e) {e.printStackTrace();}finally {try {indexWriter.close();} catch (IOException e) {e.printStackTrace();}}}
}