CFBench评测
一、研究背景与动机
大语言模型(LLMs)在理解和遵循自然语言指令方面的能力对其在实际应用中的表现至关重要。然而,现有的评估基准往往只关注单一类型或有限场景下的约束,缺乏对真实用户指令中复杂、多样、多层次约束的系统性覆盖。
为此,作者提出了 CFBench,旨在填补以下空白:
全面性:覆盖10大类、25+子类的约束类型;
真实性:基于200+真实场景和50+ NLP任务;
系统性:构建了约束分类体系,并引入多维度评估指标。
二、CFBench 的构建
1. 约束系统(Constraint System)
作者从真实场景和NLP任务中收集了大量指令,通过LLM提取和人工筛选,构建了一个包含10大类、25+子类的约束系统
1. 内容约束 (Content Constraint)
控制输出内容的范围和深度,通过指定某些条件来实现。
词汇约束 (Lexical): 强制要求使用或避免使用特定的词语、短语或符号。
示例: “必须包含‘可持续发展’这个词。”
元素约束 (Element): 要求回应中必须包含特定的元素、概念或对象。
示例: “总结这篇文章,并突出其关于人工智能伦理的讨论。”
语义约束 (Semantic): 对回应的主题、观点、情感或深层含义提出要求。
示例: “写一首关于孤独的诗。”
2. 数量约束 (Numerical Constraint)
确保输出内容满足长度、数量、次数等数值上的要求。
词数约束 (Word Count): 限制回答的总词数或令牌数。
示例: “用50个字总结。”
句数约束 (Sentence Count): 限制回答的句子数量。
示例: “用三句话说明。”
段落约束 (Paragraph Count): 限制回答的段落数量。
示例: “请分为三个段落进行阐述。”
文档约束 (Document Count): 限制列举的项目数量。
示例: “列出3篇相关文献。”
3. 风格约束 (Stylistic Constraint)
为输出内容赋予独特的风格和色彩,体现作者特质或社会目的。
语气与情感 (Tone and emotion): 要求回应的语气符合特定标准,如严肃、愤怒、喜悦、幽默、礼貌等。
示例: “用愤怒和讽刺的语气写一封信。”
形式与风格 (Form and style): 要求文本的表达方式符合特定的文体风格。
示例: “以百科全书条目的风格写一段介绍。”
受众特定 (Audience-specific): 要求文本根据特定受众(如儿童、专家)进行调整,确保清晰度和相关性。
示例: “给一个6岁的孩子解释什么是光合作用。”
作者风格 (Authorial style): 要求模仿特定作者的写作风格。
示例: “以鲁迅的风格写一段评论。”
4. 格式约束 (Format Constraint)
标准化表达形式,以引导生成复杂的内容结构。
基础格式 (Fundamental): 广泛接受的标准格式,如 JSON, XML, LaTeX, HTML, 表格, Markdown 等。
示例: “提取关键词并以JSON格式输出。”
定制格式 (Bespoke): 为特定需求定制的信息表达协议,如分点、标题、文本强调、示例、项目符号等。
示例: “总结要点,并以无序列表的形式输出。”
专业领域格式 (Specialized): 专门为特定领域(如医疗、法律)设计的格式化标准。
示例: “按照电子病历的格式输出诊断报告。”
5. 语言约束 (Linguistic Constraint)
通过控制语言的内在特征和逻辑来适应各种场景。
语用约束 (Pragmatic): 涉及语言在上下文中的使用,如言语行为、含义、方言、社会语言变体等。
示例: “用英语输出,但使用文言文的风格。”
句法约束 (Syntactic): 涉及句子结构,如短语、从句、“把”字句、祈使句等。
示例: “使用祈使句和名词短语。”
词法约束 (Morphological): 涉及单词的内部结构和构成规则,如词根、词缀、形态变化等。
示例: “所有内容使用小写英文输出。”
语音约束 (Phonological): 涉及语音结构,如音位、音调、时长、强度等(常见于诗歌、绕口令)。
示例: “创作一个押韵的绕口令。”
6. 情境约束 (Situation Constraint)
通过背景或情境参数来引导回应的 appropriateness(适宜性)。
角色扮演 (Role-based): 模拟特定角色的特质、语言和行为。
示例: “如果你是孔子,你会如何决定?”
任务特定 (Task-specific): 基于对情境需求的细致理解提供定制化的解决方案。
示例: “必须在家工作,如何向公司汇报?”
复杂情境 (Complex context): 在错综复杂的情境中进行推理和解决问题。
示例: “左边有4个,总共10个,右边有多少个?” (这是一个包含歧义或隐含信息的指令)
7. 示例约束 (Example Constraint)
通过提供少量示例,让模型学习其中的内在模式来规范新回应。重点评估模型的上下文约束学习能力。
示例: “示例1: 输入: A, 输出: X。 示例2: 输入: B, 输出: Y。 那么输入: C, 输出?”
8. 逆向约束 (Inverse Constraint)
通过禁止或排除某些内容来间接缩小回答的范围。
示例: “禁止讨论政治话题。”
9. 矛盾约束 (Contradictory Constraint)
指令中包含相互排斥的条件,使得回应无法同时满足所有要求。这类约束在真实场景中常见且容易被忽略。
示例: “写一首五言绝句,字数不少于1000字。” (五言绝句固定为20字,与1000字要求矛盾)
10. 规则约束 (Rule Constraint)
定义逻辑流程或动作,通过精心设计的规则来标准化回应的路径。
示例: “从数字1开始,每次加1。如果当前数字是3,则输出‘猫’;如果是5,则输出‘狗’。请输出前10次的结果。”
2. 数据集构建
来源:真实场景 + NLP任务;
规模:1000条高质量样本(500简单 + 500困难);
构建方式:人机协同迭代生成与标注,确保指令、参考答案、检查清单、约束类型、优先级等信息的完整性和一致性。
整个过程采用了人机协同迭代式构建(Human-Machine Collaborative Iterative Construction) 的方法,深度融合了大型语言模型(LLM)的生成能力与人类专家的校验和 refinement 能力。
其核心构建流程如下图所示,遵循一个清晰的“约束系统 -> 数据集 -> 评估” pipeline:
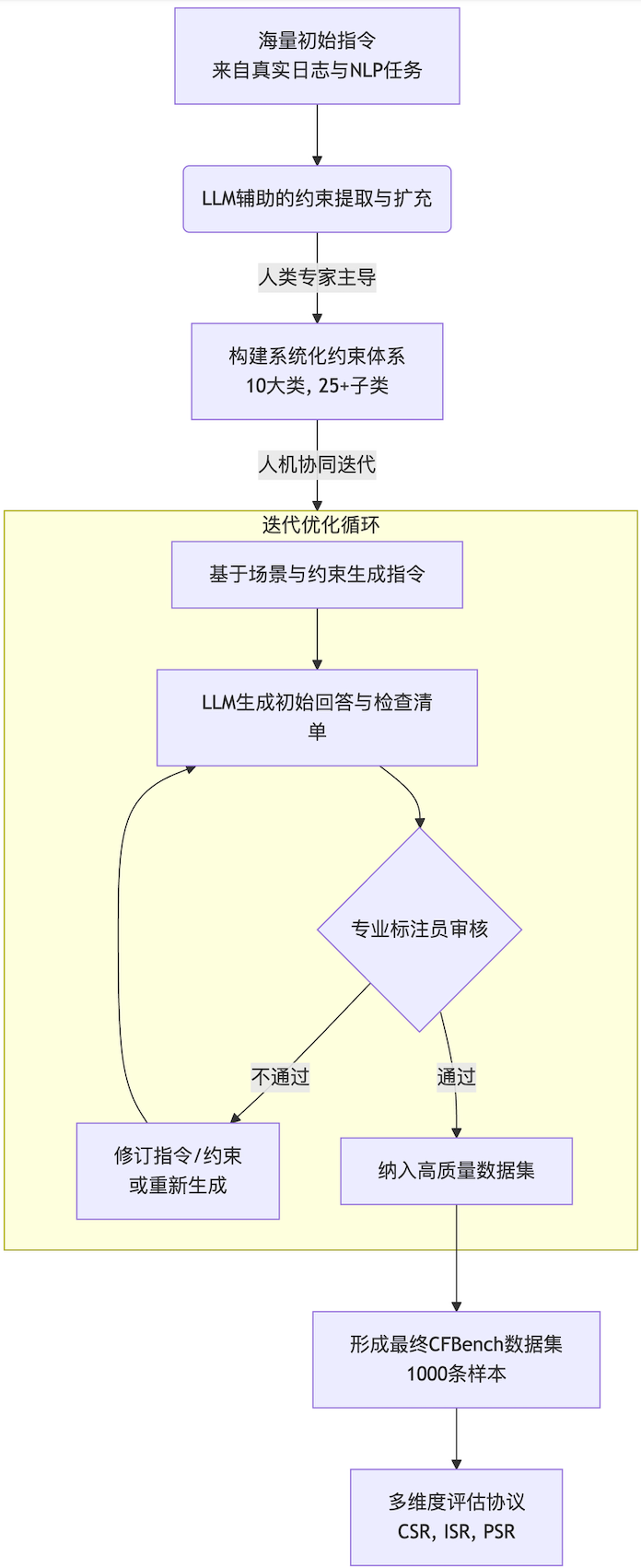
以下是该流程每个关键阶段的详细说明:
第一阶段:数据来源与初始筛选
数据源 (Data Sources):
真实用户指令: 从大模型产品的在线日志中收集了超过80万条用户查询。
NLP任务指令: 从各类NLP数据集中收集了超过30万条结构化任务指令。
初始清洗与筛选 (Initial Filtering):
过滤掉过长或过短的指令。
使用向量聚类去重算法,对指令进行去重和语义层面的筛选。
最终得到一个包含约 30,000条 高质量指令的种子库。
第二阶段:约束提取与系统构建(与数据集构建并行)
原子约束提取 (Atomic Constraint Extraction):
利用 GPT-4 等先进LLM,从上述30,000条指令中自动提取出“原子约束”(不可再分的最小约束单元)。
Prompt示例: “请从以下指令中提取出所有的约束条件:[Instruction]”
此过程提取出了约 5,000个 独特的原子约束。
专家归纳与分类 (Expert Categorization):
由领域专家对5000个约束进行人工筛选,剔除不合理或无意义的约束。
专家团队运用分类学、统计学和语言学原理,将剩余的约束归纳、整合,构建成上文介绍的10大类、25+子类的层级化约束系统。
第三阶段:人机协同迭代构建(核心环节)
这是最关键的循环过程,如下图所示,旨在不断优化数据质量:
指令增强 (Instruction Augmentation):
从真实场景和NLP任务中选出初始指令。
利用LLM(如GPT-4, Claude),根据构建好的约束系统,为指令自动添加多样化的、合理的约束,增加其复杂性和多样性。
Prompt示例: “请为以下指令添加2-3个不同类别的约束条件,使其更复杂:[Instruction]”
生成回答与检查清单 (Response & Checklist Generation):
LLM生成回答: 让LLM根据增强后的复杂指令生成一个“参考答案”。
LLM生成检查清单 (Checklist): 让另一个LLM(如GPT-4o)根据指令和约束系统,自动生成一个详细的、可评估的检查清单,将复杂指令分解为多个独立的、可二进制判断(是/否)的检查点。
Prompt示例: “你是一个专家。请根据指令和约束系统,生成一个评估回答的检查清单,每条检查点一行。”
人工审核与修正 (Human Review & Correction):
专业标注员对LLM生成的“指令-回答-检查清单”三元组进行严格审核。
审核重点:
指令和约束是否合理、自然?
回答是否正确且严格遵循了所有约束?
检查清单是否完整、客观、可评估?
如果任何一项不达标,标注员会:
修正指令或约束。
手动编写或修正参考答案。
修正检查清单。
甚至将样本打回,让LLM重新生成。
迭代循环 (Iterative Loop):
经过人工修正后的样本,会再次输入给LLM进行生成和评估,直到产出质量达到专家认可的标准为止。
这个过程确保了数据的高质量和高可靠性。
第四阶段:质量控制与平衡
为了确保CFBench的权威性和全面性,团队实施了严格的质量控制措施:
标注员培训 (Annotator Training):
从公众中招募并筛选出21名候选人。
由资深数据科学家进行为期一周的培训,并进行多轮试标注。
最终选出9名准确率最高的标注员参与项目。
交叉验证 (Cross-Validation):
每条数据由3名标注员独立审核。
计算标注者间信度(Inter-annotator agreement),达到了94% 的高一致性。
出现的分歧由专家仲裁解决。
批量验证 (Batch Validation):
将数据分成小批量(50->100->200->400)进行处理和验收。
每批完成后,由标注团队负责人抽查50%,由专家抽查20%,确保质量流程被严格执行。
数据平衡 (Data Balancing):
确保约束类型的分布均匀(覆盖所有10个大类)。
确保场景和领域的覆盖全面(20个领域,200+场景)。
确保NLP任务类型的平衡(50+任务)。
最终数据集包含 1000条 样本,其中500条来自真实场景,500条来自NLP任务。
第五阶段:最终数据项构成
经过上述流程,每一条最终进入CFBench的数据样本都包含以下完整信息:
指令 (Instruction): 融合了多种约束的复杂自然语言指令。
参考答案 (Gold Answer): 严格遵循所有约束的理想回答。
检查清单 (Checklist): 分解后的可评估检查点列表。
约束类型标签 (Constraint Types): 标注了每个检查点对应的约束类别(如“格式约束->JSON”)。
优先级标签 (Priority Levels): 标注了每个需求是“主要”还是“次要”。
3. 数据统计
平均每条指令包含4.24个约束,涵盖3.2种类型;
覆盖20个领域(如医疗、教育、金融、法律等)和200+场景;
涵盖4大类NLP任务(分类、生成、序列标注、句子关系)。
三、评估方法
1. 评估协议(Evaluation Protocol)
将复杂指令分解为多个可独立判断的检查点(checklist);
使用GPT-4o作为评估模型,对每个检查点进行二值判断(0/1)。
2. 评估指标
CSR(Constraint Satisfaction Rate):约束满足率;
ISR(Instruction Satisfaction Rate):指令整体满足率;
PSR(Priority Satisfaction Rate):考虑需求优先级的满足率,更贴近用户真实感受。
四、实验结果
1. 主流模型表现
DeepSeek-R1 表现最佳,其次是 GPT-4o 和 DeepSeek-V3;
开源模型中 Qwen2-72B-Instruct 表现突出;
所有模型在“困难集”上表现均显著下降,尤其在矛盾约束上表现最差。
2. 约束类型分析
模型在“词数限制”、“句式限制”、“风格一致性”等细粒度约束上表现较差;
不同模型在不同约束类型上各有优劣,没有模型在所有类型上领先。
3. 领域与任务分析
模型在“就业”、“心理”等领域表现较差,在“科技”、“招聘”等领域表现较好;
在NLP任务中,句子关系任务表现最佳,序列标注次之。
五、讨论与发现
1. 与其他基准对比
CFBench 与 MMLU(知识)和 GSM8K(数学)的排名不一致,说明它提供了新的评估维度,更贴近真实应用需求。
2. 影响因素分析
指令长度、约束数量、约束类型、主要需求数量均与模型表现正相关;
约束数量对ISR影响最大,主要需求数量对PSR影响最大。
3. 提升策略
监督微调(SFT) 显著提升模型表现;
模型规模越大,表现越好;
使用复杂约束指令进行训练可进一步提升能力。
六、局限性与伦理声明
局限性
主要关注中文模型,缺乏对英文模型的广泛评估;
对推理型模型(如R1)的研究不足;
评估依赖GPT-4o,可能存在模型偏差。
伦理声明
研究遵循ACL伦理准则,确保数据收集、使用和发布过程符合隐私保护和知情同意原则。
七、贡献总结
首个系统化的指令约束分类体系;
大规模、高质量、多场景的中文约束遵循基准;
多维度、用户中心化的评估框架;
对当前主流模型的全面评估与分析,揭示其短板与提升方向。
总结
CFBench 是一个具有系统性、真实性、可扩展性的基准测试集,不仅为评估LLMs的约束遵循能力提供了新标准,也为模型优化指明了方向。该工作对推动LLMs在实际应用中的落地具有重要价值。