C++进阶-----C++11
作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言、C++和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
C++11
- **作者前言**
- {}初始化
- auto
- decltype
- nullptr
- STL 的一些变换
- 右值引用和移动语义
- 左右值
- 左右值引用的比较
- 左右值引用解决的问题
- 完美转发
- 新的类功能
- 可变参数模板
- lambda表达式
- 包装器
- function包装器
- bing包装器
{}初始化
C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。可以理解为一切可以使用{}初始化
#include<iostream>
struct MyStruct
{int _x;int _y;
};
class Date
{
public:Date(int year = 0, int mothon = 0, int day = 0):_year(year),_mothon(mothon),_day(day){}Date(const Date& date){_year = date._year;_mothon = date._mothon;_day = date._day;}
private:int _year;int _mothon;int _day;
};
int main()
{//内置类型初始化int a = 10;int b{ 10 };//数组初始化int arr[] = { 1,2,3,4,7,9 };int arr1[]{ 1,2,3,4,5,8 };//结构体初始化MyStruct pion = { 1,2 };MyStruct pionOne{ 1,2 };//new的初始化int* stataArr = new int[4]();//初始化为0;int* stataArr1 = new int[4]{ 1,2,3,4 };//自定义类型初始化Date date1(10,10,10);//c++98Date date2 = { 10,10,10 };//C++11Date date3{ 10,10,10 };//c++11Date* dates = new Date[3];Date* dates1 = new Date[3]{date1,date2,date3 };Date* dates2 = new Date[3]{{10,10,10},{10,10,10},{10,10,10}};return 0;
}
还有一些特殊情况,SLT容器使用的
std::vector<int> vet = { 1,2,3,4,5,6,8 };
//相当于vet(std::initializer_list<int>{1,2,3,4,5,6,8 })
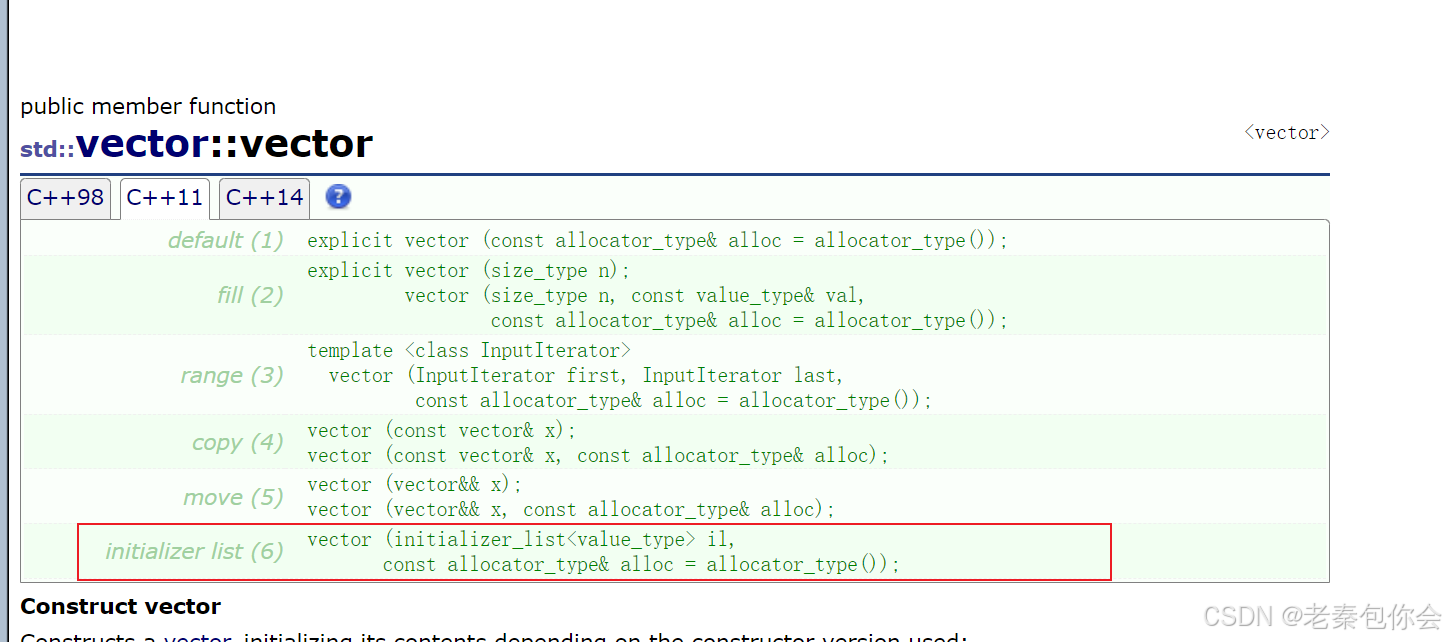
如图,这是因为在vector的调用了std::initializer_list这个,std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加
std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值。
auto
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将其用于实现自动类型腿断。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
decltype
关键字decltype将变量的类型声明为表达式指定的类型。这个一般用于推导出表达式的类型
int Funtion()
{return 1;
}
int main()
{int x = 0;int y = 10;decltype(x+y) z = 1;vector<decltype(Funtion())> vet;return 0;
}
一般的使用场景是不知道表达式的类型或变量的类型,可以使用这个进行推导出来
nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
STL 的一些变换
- unordered_map和unordered_set以及array和forward_list的增加(新容器增加)
- 提供了cbegin和cend方法返回const迭代器等等,(增加新接口)
右值引用和移动语义
左右值
前面的学习中,会有一种认识误区就是可以修改的就是左值, 不能修改的是右值,这个说法不完全正确。
左值和左值引用
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址,一般情况下可以对它赋值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址。
简单理解左值的特性一般是, 可以被取地址
函数的左值引用返回时左值
左值引用就是给左值的引用,给左值取别名。
int& Funtion()//函数的左值引用返回时左值
{static int x = 0;return x;
}
int main()
{//左值int a = 10;int b = 10;const int c = 10;const int* p = nullptr;//左值引用int& ra = a;int& rb = b;const int& rc = c;const int*& rp = p;return 0;
}
代码中的a、b、c就是左值,对应的引用就是左值引用 ,funtion()函数的返回值也是左值
右值和右值引用
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址。右值引用就是对右值的引用,给右值取别名。
在C++中对右值有进行更具体的区分
- 纯右值: 如2
- 将亡值:如匿名对象、传值返回函数
int main()
{int a = 10;int b = 10;//右值10,下面的也是a + b;Funtion(a , b);//右值引用,这里使用的&&int&& rr = 10;return 0;
}
如果查看反汇编就会知道
00BF18BD mov dword ptr [ebp-30h], 0Ah ; 将 10 (0xA) 存入栈地址 [ebp-30h]
00BF18C4 lea eax, [ebp-30h] ; 将 [ebp-30h] 的地址加载到 eax
00BF18C7 mov dword ptr [rr], eax ; 将 eax 的值(即地址)存入变量 rr
总结:
语法上, 引用就是别名,左值引用就是給左值取别名,右值引用就是给右值取别名,别名不开空间
底层上:引用就是指针的实现,左值引用就是存储左值的地址,右值引用就是把右值拷贝到栈的空间上,存储的是这个临时变量的地址
左右值引用的比较
左值引用总结
- 左值引用只能引用左值,不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值。
右值引入总结:
- 右值引用只能右值,不能引用左值。
- 但是右值引用可以move以后的左值。
总代码如下:
int main()
{//左值为a ,右值为10int a = 10; //左值引用不能引用右值,但是const可以int& r = 10;//出错const int& rr = 10;//右值引用不能引用左值, 但是move后的可以int&& ra = a;//报错int&& rb = move(a);return 0;
}
左右值引用解决的问题
左值引用:
- 解决了传参拷贝等问题,(传参为引用)
- 解决部分传返回值,(静态变量返回值)
无法解决的问题:
当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回,只能传值返回。
代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include<assert.h>
#include<iostream>
#include<string.h>
#include<string>
using namespace std;
namespace bit
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);}//移动拷贝构造string(bit::string&& s):_str(nullptr),_size(0),_capacity(0){cout << "string(const string& s) -- 移动拷贝" << endl;swap(s);//不再进行深拷贝,直接获取s的所有资源}~string(){delete[] _str;_str = nullptr;}// 赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(const char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}void Reversal(bit::string::iterator stat, bit::string::iterator end){bit::string strOne;for (bit::string::iterator stat1 = stat; stat1 != end; stat1++){strOne.push_back(*stat1);}bit::string::iterator ro = strOne.end()-1;for (; stat != end; stat++){*stat = *ro;ro--;}}int size(){return _size;}friend std::ostream& operator<<(std::ostream& os, bit::string& str);private:char* _str;//创建的数组size_t _size;//需要创建的大小size_t _capacity; // 不包含最后做标识的\0 当前的长度};std::ostream& operator<<(std::ostream& os, const bit::string& str) {return os;}template<class T = int>string To_String(T a){bit::string str{""};if (a < 0){a = 0 - a;str.push_back('-');}int num = (str.size() > 0 ? 1 : 0);while (a / 10){str.push_back('0' + (a % 10));a /= 10;}str.push_back('0' + a);str.Reversal(str.begin() + num , str.end());for (bit::string::iterator stat = str.begin(); stat != str.end(); stat++){cout << *stat;}cout << endl;return str;}
}
int main()
{bit::string ret = bit::To_String(-123456);//调用的是深拷贝构造,因为拷贝构造的参数是一个const左值引用,可以引用左值和右值return 0;
}
图如下:
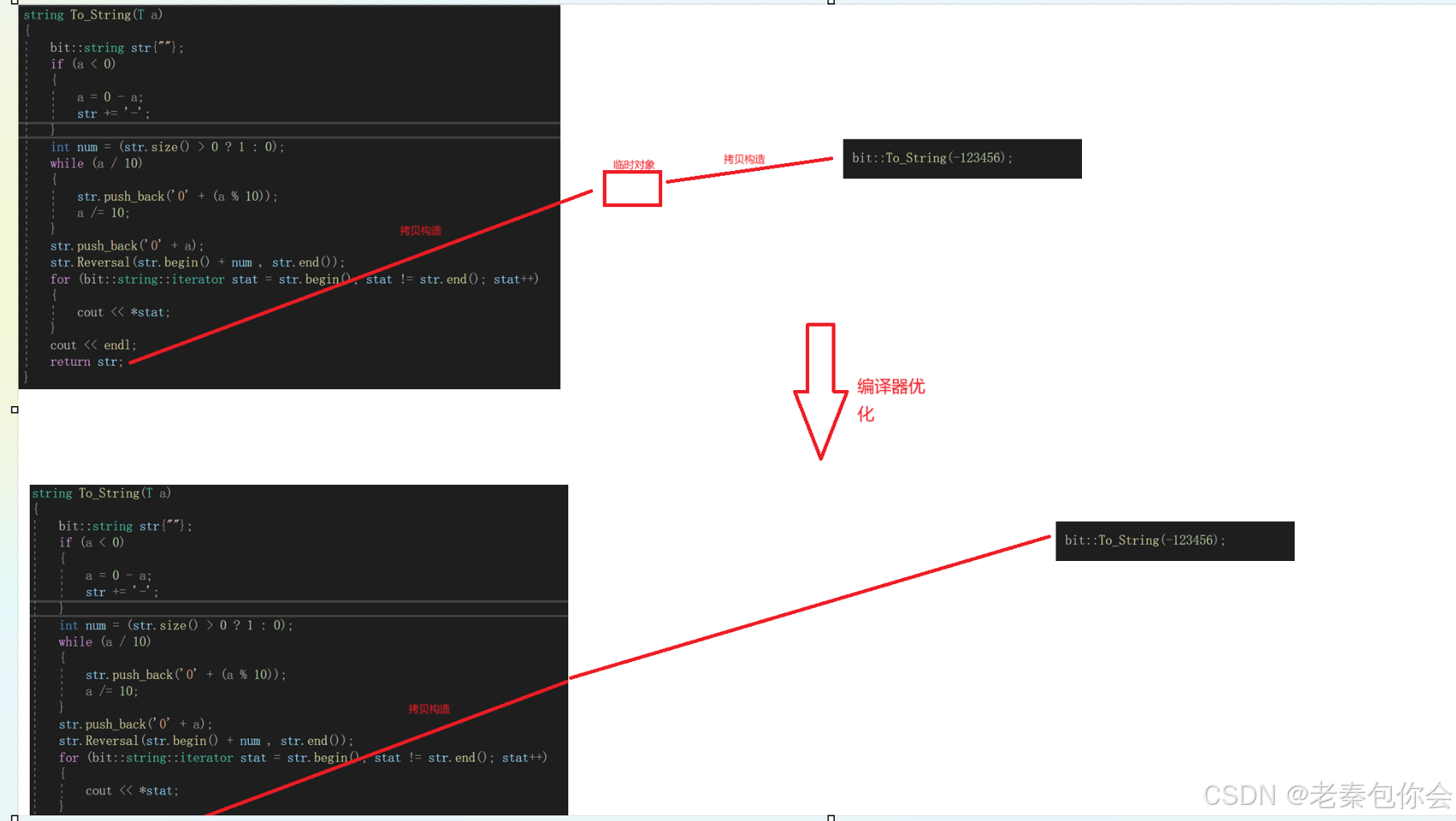
在To_String函数中,返回的是局部对象,出作用域就会销毁, 进行两次拷贝构造,在新的编译器中,会对几步进行优化,优化为1次拷贝构造,,这就是左值引用的优化过程
右值引用和移动语义
在上面的 代码中,如果使用 使用To_String函数的返回值,进行如下操作
bit::string ret = bit::To_String(-123456);
会发现调用的仍然是拷贝构造,因为拷贝构造函数的参数是一个const左值引用,可以引用左值,To_String函数的返回值就是一个右值,我们知道,一个右值是一个即将消亡的对象,如果再去进行深拷贝,就会浪费时间和空间,为此,我们可以写一个移动拷贝函数进行把这个对象对应的资源拿过来使用,
移动拷贝:通常指的是 移动语义(Move Semantics),它通过 std::move和移动构造函数/移动赋值运算符实现,用于高效转移资源所有权,避免不必要的深拷贝。
当运行代码的时候,编译器会把返回值识别为右值,
在这个过程中,编译器也经历了一部分的优化,在C++11把右值引用引入后,编译器会把局部的返回值调用拷贝构造生成对应的临时变量, 这个临时变量就是右值, 然后右值再进行一次移动构造,这是编译器在引入右值引用的优化之前的过程,在优化之后,就会进行默认的move左值,变成右值,然后调用一次移动构造

移动赋值拷贝
bit::string s;
bit::string r;//假设z是一个将亡值
bit::string&& z = r;//z为右值引用
s = z

z赋值给s,而z为一个右值引用,s可以把z的资源拿过来,s把属于自己的资源(原本要释放的)给z,由z进行销毁。
具体如下:
//移动赋值拷贝string& bit::strig::operator=(string&& s){cout << "string& operator=(string s) -- 移动赋值拷贝" << endl;swap(s);return *this;}int main(){bit::string ret1;ret = bit::To_String(-6);return 0;}
注意: 右值不能被修改,但是右值引用可以被修改,并且右值引用是一个左值属性,这样才能被修改,如果是直接传右值引用为函数参数就会被当成左值。如果要不想为左值,可以把这个右值引用进行move
如图:
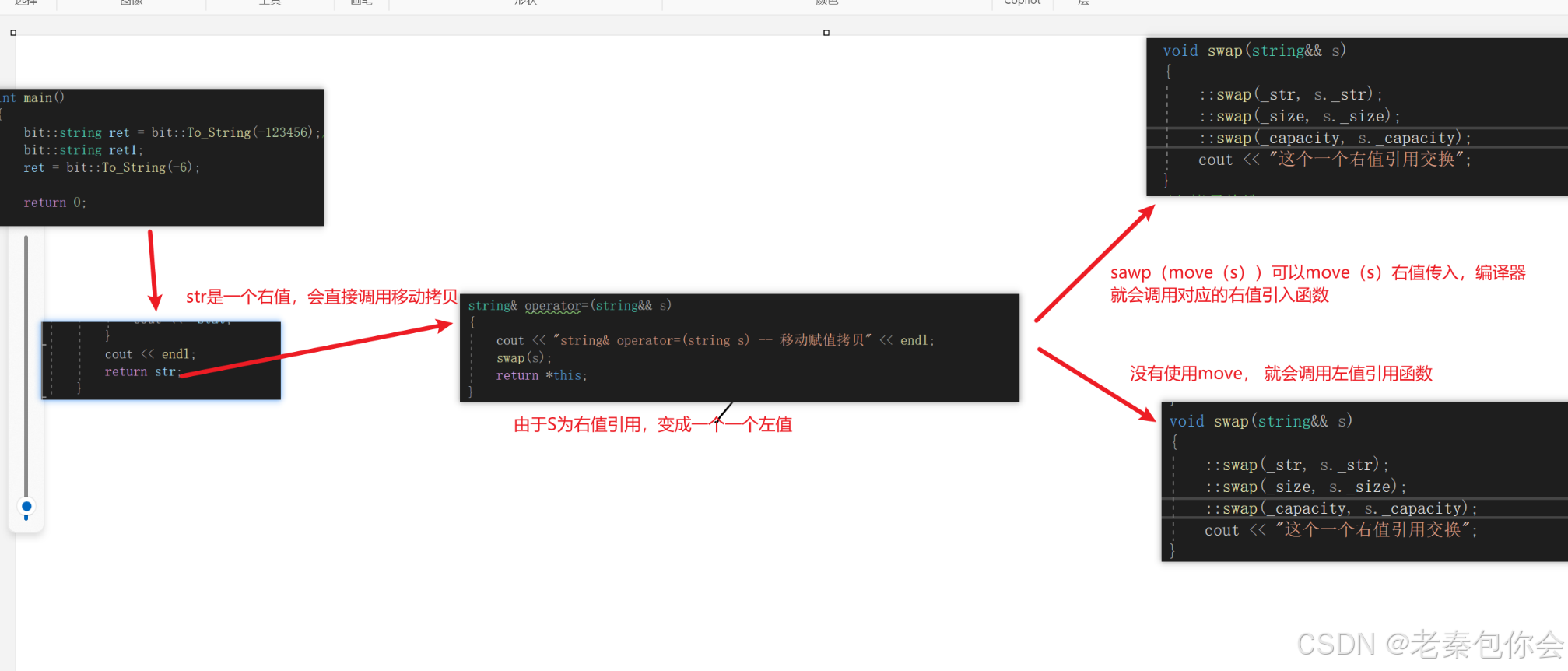
这也就能解释出来,为啥右值不可以修改,右值引用可以修改,
完美转发
写法:搭配函数模板使用
在模板中的 万能引用
void Fun(int& t)
{cout << "左值引用" << endl;
}
void Fun(const int& t)
{cout << "const 左值引用" << endl;
}
void Fun(int&& t)
{cout << "右值引用" << endl;
}
void Fun(const int&& t)
{cout << "const 右值引用" << endl;
}
template<class T>
void Funtion(T && t)
{Fun(t);
}
int main()
{int a = 10;Funtion(10);//右值Funtion(a);//左值Funtion(move(a));//右值// constconst int b = 20;Funtion(b);//左值Funtion(move(b));//右值return 0;
}
代码中的Funtion函数的使用了函数模板,参数类型T&&t只是一个参数, 模板中的&&不代表右值引用,而是万能引用,
万能引用的定义条件
万能引用(Universal Reference)必须满足以下两个条件:
模板类型推导上下文:T&&必须直接参与模板参数推导。
精确的 T&&形式:不能有 const修饰或其他变化。
模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力,当传入的是左值,这个参数就是左值引用,如果是右值就是右值引用。
写法如下:
void Funtion(T && t)
{Fun(std::forward<T>(t));
}
forward是一个函数模板 传入类型和参数就行
新的类功能
前面我们在学习类的默认成员函数知道,有六大成员函数:
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
现在C++11引入了两个:移动构造函数和移动赋值运算符重载。
针对移动构造函数和移动赋值运算符重载有一些需要注意的点如下:
- 如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
- 如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)
- 如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
类成员变量初始化
C++11允许在类定义时给成员变量初始缺省值,默认生成构造函数会使用这些缺省值初始化。
强制生成默认函数的关键字default
C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以使用default关键字显示指定移动构造生成。
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}Person(const Person& p):_name(p._name), _age(p._age){}Person(Person&& p) = default;//强制生成移动构造
private:bit::string _name;int _age;
};
如果 强制生成移动构造,如果没有写拷贝构造,编译器是不会去生成拷贝构造,这样可以约束一下写法,避免在生成移动构造,就忽略不写拷贝构造。
禁止生成默认函数的关键字delete:
在C++98之前,如果不想让类对象被拷贝往往就会把拷贝构造函数私有化+声明
class A
{
public:A():_s(){}
private:A(const A& de);//防止被好心办坏事Person _s;
};
int main()
{A s;A ss(s);//报错return 0;
}
但是在C++11之后,就进行引入关键字delete,如下:
class A
{
public:A():_s(){}A(const A& de) = delete;
private://防止被好心办坏事Person _s;
};
int main()
{A s;A ss(s);//报错}继承和多态中的final与override关键字
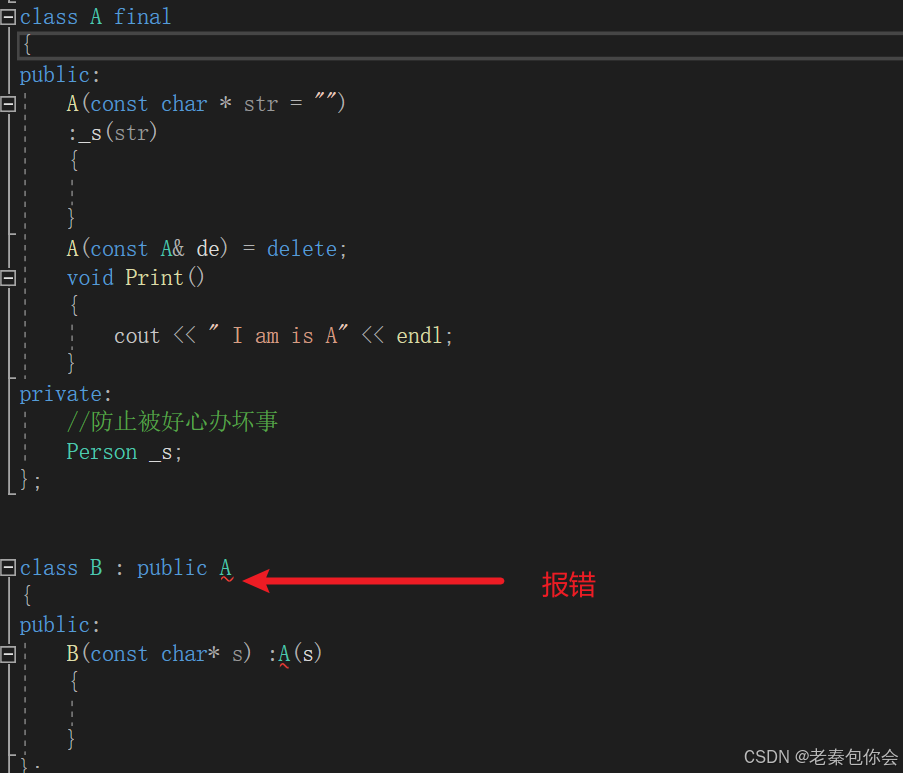
final关键字,作用于虚函数和类。作用于虚函数的时候,让虚函数不能重写,如图:
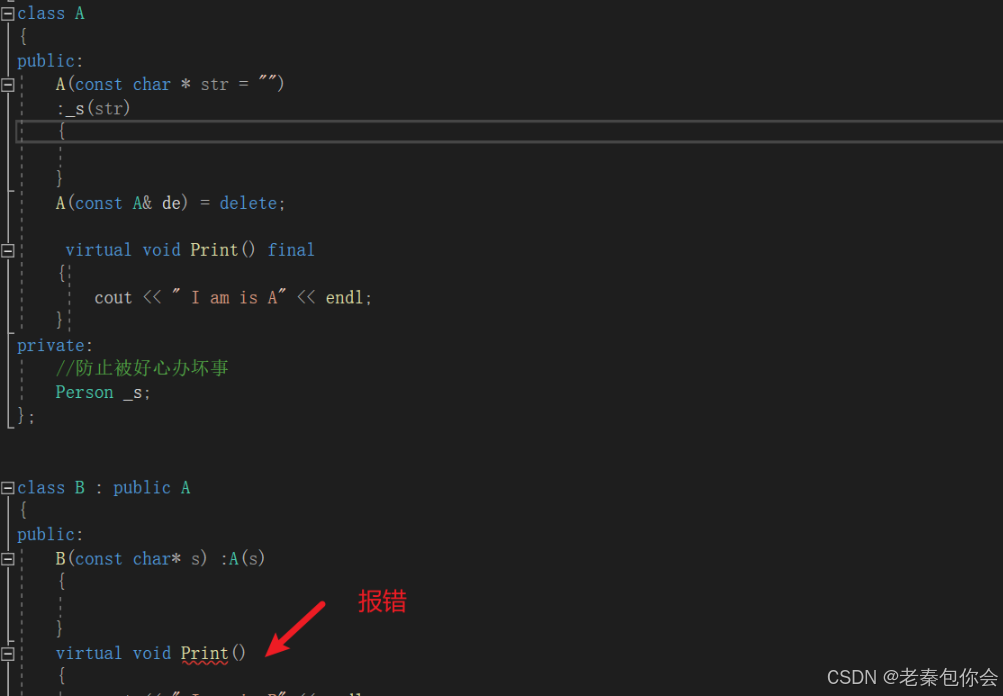
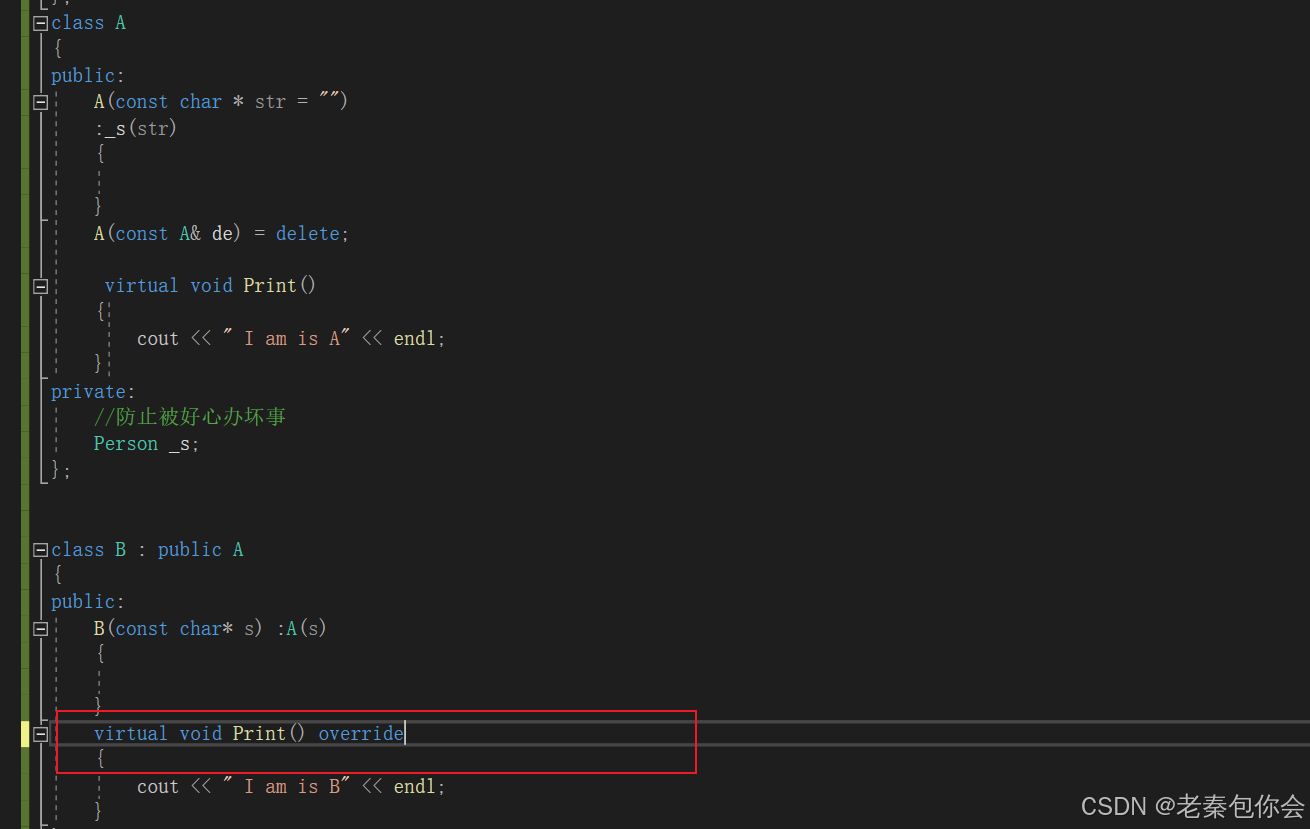
作用于类的时候,让类不能被继承。如图
override关键字作于于虚函数,主要作用于子类的虚函数重写,如果没有重写父类的虚函数就会报错
可变参数模板
C++11的新特性可变参数模板能够让您创建可以接受可变参数的函数模板和类模板
比如printf函数的形参就是可变参数
一个基本可变参数的函数模板如下:
// Args是一个模板参数包,args是一个函数形参参数包
// 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。
template <class ...Args>
void ShowList(Args... args)
{}
上面的参数args前面有省略号,所以它就是一个可变模版参数,我们把带省略号的参数称为“参数包”,它里面包含了0到N(N>=0)个模版参数。
如果我们想要知道我们往这个函数传入的参数有多少个,可以使用sizeof…
template<class ...x>//表示有多个类型
void FunOne(x... a)//表示可以传入多个x类型的参数
{cout << sizeof...(a) << endl;
}
int main()
{FunOne<int>(10);FunOne(10,20);FunOne(10,30,40,50);return 0;
}
如图:

如果使用可变参数类型模板,我们往往需要知道怎么获取到参数及其类型
在C语言中的可变参数中,进行参数的解析是在运行时解析的,但是我们这里时模板,模板需要在编译时解析,在编译时解析的时候,编译器会写一个递归解析。长啥样?
下面写一个相似的:
void FunTwo()//编译解析的结束条件
{cout << "运行结束" << endl;
}
template<typename T,class ...X>
void FunTwo(T&& t, X&&... arg)
{cout << typeid(t).name() << t << endl;//if (sizeof...(arg) == 0)//这样写是在运行时起效果,但是可变参数类型模板是在编译时解析的// return;FunTwo(arg...);//当参数为0个,就会调用FunTwo()函数
}template<class ...x>//表示有多个类型
void FunOne(x&&... a)//表示可以传入多个x类型的参数
{cout << sizeof...(a) << endl;FunTwo(forward<x>(a)...);
}
这个递归写法,主要是为例解析参数有多少个和获取到对应参数的写法,采用万能引用和完美转发进行写的递归解析,这个递归解析的结束条件不能像普通递归函数的结束条件一样,需要写一个无参数的FunTwo函数重载,因为到最后递归到一定是
编译器在编译会对模板对进行推演,例如FunOne(10,20);在编译期间的推演就是如下:
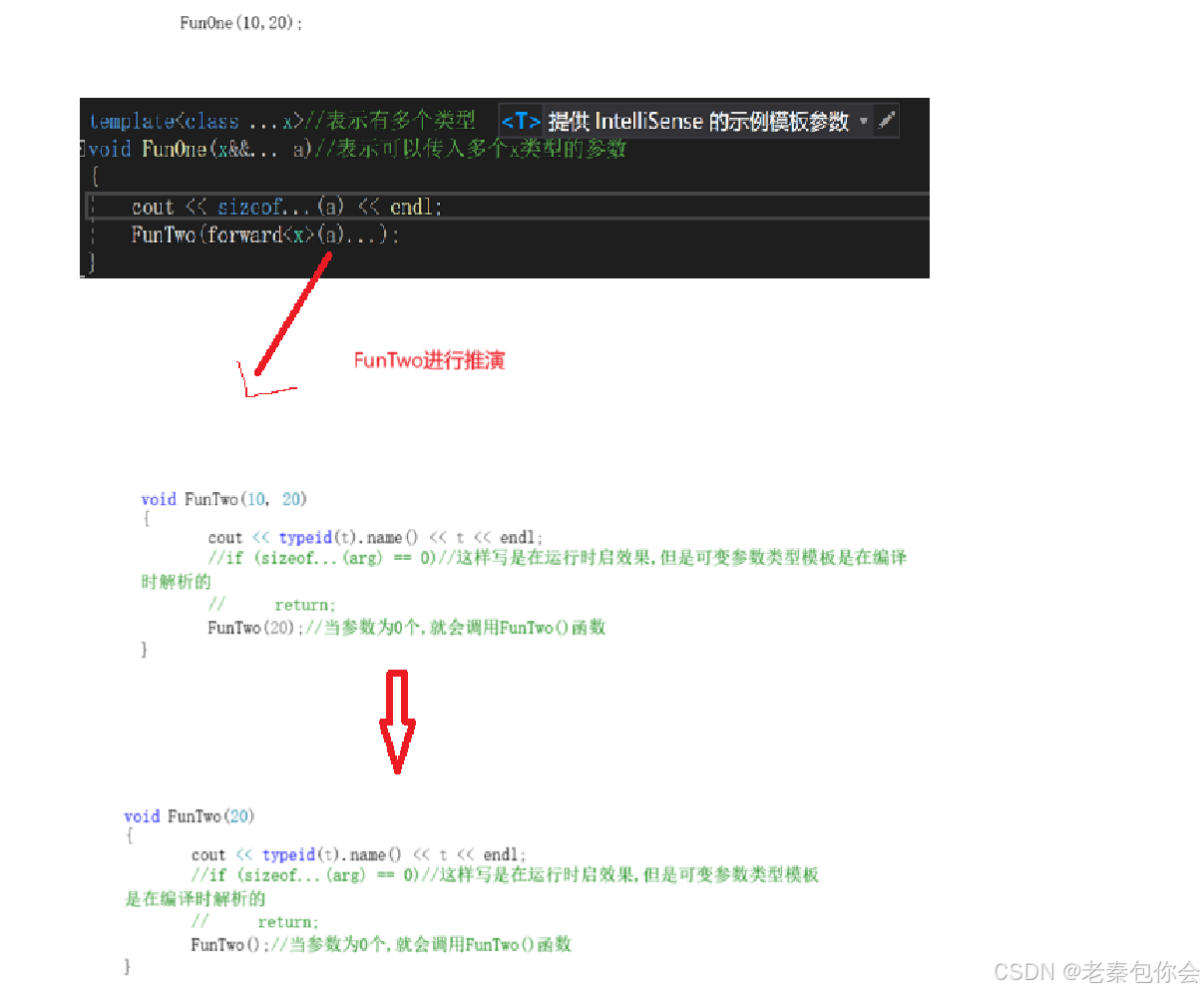
会把多个参数的第一个传给t形参,剩下的参数传入到arg中,不断循环,直到参数为0个
lambda表达式
在一些场合中,会因为要传入一些对应的的仿函数或者函数指针而去重新写一个出来,这个过程可能会因为某些命名规则很不方便,例如:
class Goods
{
public:Goods(const char* name, double price, int evaluate):_name(name),_price(price),_evaluate(evaluate){}std::string _name;double _price;int _evaluate;
};
struct ComparePriceLess//仿函数
{bool operator()(const Goods& g1, const Goods& g2){return g1._price < g2._price;}
};
struct ComparePriceRigth//仿函数
{bool operator()(const Goods& g1, const Goods& g2){return g1._price > g2._price;}
};
int main()
{std::vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };std::sort(v.begin(), v.end(), ComparePriceLess());//传入仿函数对象return 0;
}
这个例子就是写一个一个类和对应的类的某些成员进行比较的仿函数,使用std::sort函数进行对应的排序,可以看出每次为了实现一个algorithm算法,都要重新去写一个类,如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,这些都给编程者带来了极大的不便。为此引入lambda表达式。
lambda表达式的书写格式:
[capture-list] (parameters) mutable -> return-type
{statement
}
lambda表达式各部分说明
- [capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。简单的理解就是你需要这个函数使用啥变量或者对象,只需在【】中写入就行,在这里一般有几种捕获方式:
(1) 传值捕捉
只是这个捕获的值是一个拷贝过来的值,是一个const修饰的值,无法被改变,如果想要改变可以添加mutable
int main()
{int a = 10;int b = 30;int c = 40;auto Add = [a,b,c] (const int& ar1, const int& ar2)mutable -> int{a = 1000;return a + b;};cout << Add(20, 30) << endl;cout << "a = " << a;return 0;
}
如图:
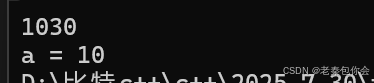
如果没有添加mutable是不能修改的
(2) 传引用捕捉
int main()
{int a = 10;int b = 30;int c = 40;auto Add = [&a,&b,&c] (const int& ar1, const int& ar2) -> int{a = 1000;return a + b;};cout << Add(20, 30) << endl;cout << "a = " << a;return 0;
}
效果:

可以看出,没有添加mutable也可以直接修改。
(3)捕捉当前作用域的全部变量
int main()
{int a = 10;int b = 30;int c = 40;auto Add = [=] (const int& ar1, const int& ar2)mutable -> int{a = 1000;return a + b;};cout << Add(20, 30) << endl;cout << "a = " << a;return 0;
}
写法是 [=]
(4)捕获当前作用域的所有对象引用
int main()
{int a = 10;int b = 30;int c = 40;auto Add = [&] (const int& ar1, const int& ar2)-> int{a = 1000;return a + b;};cout << Add(20, 30) << endl;cout << "a = " << a;return 0;
}
剩下的就是混合捕捉,比较好理解剩下就不写;
3. (parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略,简单的理解就是,这个就是函数的形参
-
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
-
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
-
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
lambda表达式我们可以理解为一个匿名函数对象,就像是匿名对象一个样子,我们可以看看lambda在编译器中是怎么样的,下面写一个代码进行验证:
template<typename T>
struct AddClass//仿函数
{
public:AddClass(const T& na):_a(na){}T operator()(const T& g1 , const T& g2){return g1 + g2;}
private:T _a;
};
int main()
{int a = 10;int b = 30;int c = 40;//lambda表达式auto Add = [=] (const int& ar1, const int& ar2) mutable-> int{a = 1000;return a + b;};Add(20, 30);//仿函数AddClass<int> r1(1);r1(20, 30);cout << "a = " << a;return 0;
}
效果如下:
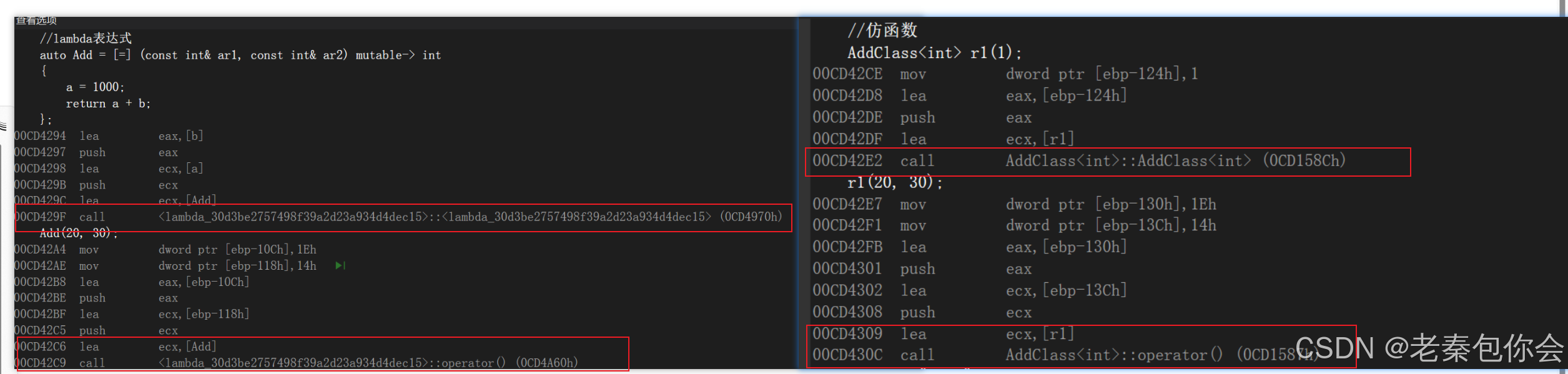
可以看出,在反汇编中,lambda表达式和仿函数是完全一样的,实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。lambda捕获的变量或者对象,变成这个类的成员变量,捕捉相当于就是拷贝了一份const成员变量。
包装器
function包装器
function包装器 也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。
前面我们总共学习三种可调用对象,函数指针、仿函数、lambda表达式
例如:
ret = func(x);
// 上面func可能是什么呢?那么func可能是函数名?函数指针?函数对象(仿函数对象)?也有可能
是lamber表达式对象?所以这些都是可调用的类型!
下面写一个代码进行感受一下:
template<typename T>
struct AddClass//仿函数
{
public:AddClass(const T& na):_a(na){}T operator()(const T& g1 , const T& g2){return g1 + g2;}
private:T _a;
};template<typename T, class F>
F User(T t, F f)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return t(std::forward<F>(f));
}template<class T>
T Funtion(T a)
{cout << "Funtion" << endl;return a;
}template<class T>
class FuntionClass
{
public:T operator()(T a){cout << " FuntionClass" << endl;return a;}
};
int main()
{int elemest = 2;//使用User函数进行三种调用User(Funtion<decltype(elemest)>, elemest);//传入函数指针User(FuntionClass<decltype(elemest)>(), elemest);//传入仿函数User([](decltype(elemest) a) {cout << "lambda" << endl;return a;}, elemest);//lambda表达式return 0;
}如图:
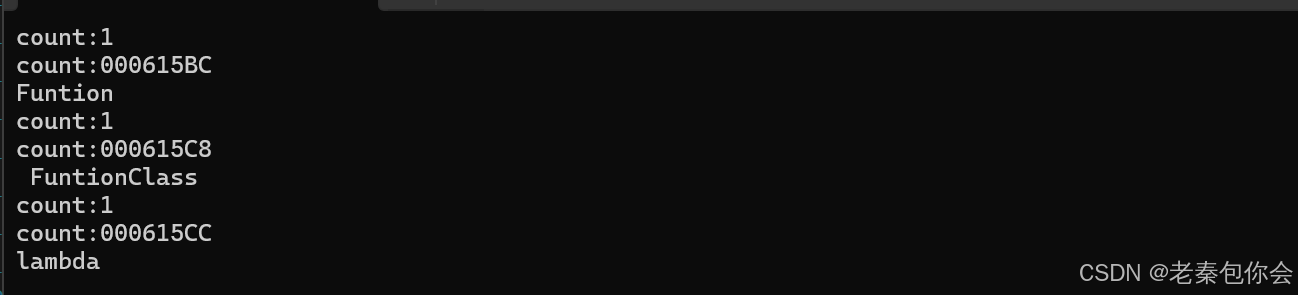
代码中,User函数模板实例化三份`,每次调用 User时,由于传入的参数类型不同,编译器会生成 三个独立的模板实例,每个实例都有自己的静态变量 count:为了解决这个问题
在C++11引入了包装器,以function为例,这个一个类模板
std::function在头文件<functional>
// 类模板原型如下
template <class T> function; // undefinedtemplate <class Ret, class... Args>
class function<Ret(Args...)>;
模板参数说明:
Ret: 被调用函数的返回类型
Args…:被调用函数的形参
这个不仅仅可以把函数进行包装,还可以把仿函数和lambda表达式进行包装,进行优化后,代码如下:
int main()
{int elemest = 2;//使用User函数进行三种调用function<decltype(elemest)(decltype(elemest))> df = Funtion<decltype(elemest)>;User(df, elemest);//传入函数指针function<decltype(elemest)(decltype(elemest))> df1 = FuntionClass<decltype(elemest)>();User(df1, elemest);//传入仿函数function<decltype(elemest)(decltype(elemest))> df2 = [](decltype(elemest) a) {cout << "lambda" << endl;return a;};User(df, elemest);//lambda表达式return 0;
}
如图:
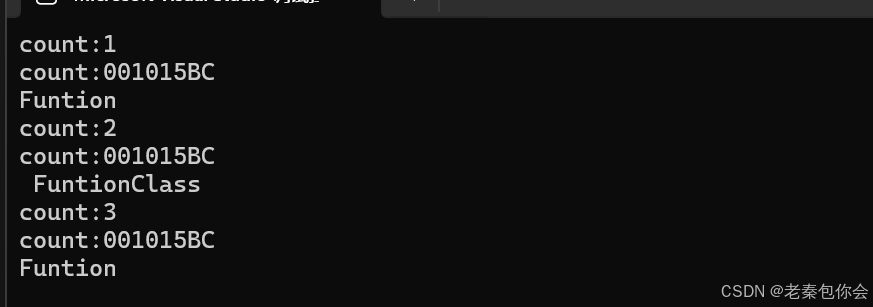
可以看到User调用的都是都是一个样子的模板。所以就会模板实例一次,所以说function就是封装并统一类型(意义),为啥这样说?因为函数指针写起来不方便,而仿函数的类型有不同的类型,lambda表达式在语法层是没有类型的,
除此之外,function还可以进行包装对应的类成员函数,
class Plus
{
public:static int FunctionOne(int a, int b){cout << a + b << endl;return a + b;}int FunctionTwo(int a, int b){return _parper;}private:int _parper = 20;};
int main()
{function<int(int, int)> f = &Plus::FunctionOne;//静态成员函数//非静态成员函数function<int(Plus, int, int)> ff = &Plus::FunctionTwo;//第一种方法cout << ff(Plus(), 20, 30) << endl;//传入对象function<int(Plus*, int, int)> ff1 = &Plus::FunctionTwo;//第二种方式Plus ss;ff1(&ss, 30,20);//传入对象的指针return 0;
}
上述代码就是包装类的成员函数的例子。可以大致猜到function是一个类似仿函数的类。
bing包装器
除了上面的function模板类,还有一个bind函数。
std::bind函数定义在头文件中,是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表。一般而言,我们用它可以把一个原本接收N个参数的函数fn,通过绑定一些参数,返回一个接收M个(M可以大于N,但这么做没什么意义)参数的新函数。同时,使用std::bind函数还可以实现参数顺序调整等操作。
/ 原型如下:
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
// with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
bing主要针对可调用对象进行参数的调整:
- 调整参数顺序
- 调整参数的个数
我们可以将bind函数看作是一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。
调用bind的一般形式:auto newCallable = bind(callable,arg_list);
int Sub(int x, int y)
{return x - y;
}int main()
{int a = 10; int b = 20;cout << Sub(a, b) << endl;auto fun = bind(Sub, std::placeholders::_2, std::placeholders::_1);//std::placeholders::_1表示Sub函数的第一个参数, std::placeholders::_2并表示Sub函数的第二个参数.cout << fun(a, b) << endl;//a传给std::placeholders::_1, b传给std::placeholders::_2,return 0;
}
效果如下:

调用fun给我们的表象就是fun(10,20),实际上就是Sub(20,10)
这里引入placeholders的命名空间,
使用bind的使用,涉及到参数一定要从std::placeholders::_1(始终表示第一个参数)开始写入,否则会报错。下面我们把function包装的类的成员函数进行改良一下,类的静态成员函数和类的成员函数,最大的区别就是静态成员函数没有this指针,所以使用function进行模板实例的时候,多写一个类型,
如下:
Plus ss;function<int(int, int)> ff1 = bind(&Plus::FunctionTwo, ss, 200,std::placeholders::_1);ff1(30,20);//30传给placeholders::_1