从物理扇区到路径访问:Linux文件抽象的全景解析
一、理解“一切皆文件”
1. 理解
我们已经知道OS是一款软硬件资源管理的软件。那么它是怎么管理的呢?先描述,在组织。
对于进程,文件,都有其对应的PCB,file。那么对于硬件设备呢?OS通过驱动程序与硬件进行交互,计算机有各种各样的硬件设备,这些设备也是需要被管理的。
那么,在OS内一定也有对于硬件设备管理的数据结构。以键盘,显示器,网卡,鼠标,磁盘为例,这些硬件设备可以进行读取,也可以进行写入,其中有些硬件设备只需要读取,不需要写入(键盘),有些需要写入不需要读取(显示器),有些既需要读取又需要写入(磁盘)。
所以,计算机外设,有的只读,有的只写,有的读写。但是不同的设备,它们的访问方式一定是不同的。访问设备,都是谁在访问呢?我们在编写代码中,使用 scanf 函数获取键盘数据,printf 函数向显示器打印数据,本质都是进程通过OS访问硬件设备的。所以,接下来,我们就要聊聊进程与硬件之间的关系了。
我们已经知道,进程PCB里有一个 struct file-struct * files指针,该指针指向一个 struct file_struct 的结构体,该结构体里有一个 struct file* fd_array[]结构体指针数组,该数组里存放的就是一个个 struct file 结构体的地址。
OS大部分都是由C语言编写的,在C语言结构体中,无法定义函数的实现,但是可以有函数指针呀。
每个设备都有对应的 struct file,所以,对于每个硬件设备的读写,只需要有两个函数指针就可以解决了。而这两个函数指针都是在 struct file 文件结构体里的。
所以,在 linux 上怎么看待一切皆文件呢?是站在进程的视角,struct file 结构体之上,看待文件的视角。
当然了,管理硬件肯定不是只有这么一点,只需要两个指针就完成了。这里只是以读写为例。在底层肯定有许多函数指针管理硬件的使用。
在 linux 中,打开文件,要创建 struct file,三个核心:
1.文件属性
2.文件内核缓冲区
3.底层设备文件的操作表(struct file_operations)
2. 缓冲区
缓冲区的本质其实就是一段内存空间。
举个例子理解一下缓冲区。
你是张三,家在云南,有一个好朋友叫李四,在北京。李四即将过生日,你买了一个机械键盘作为礼物给李四,难道你要亲自从云南跑到北京去吗?当然不可能了。你直接跑到楼下面,将礼物给菜鸟驿站,让菜鸟驿站给你送过去就可以了。对于你而言,这样可以节省大量的人力,物力。但是菜鸟驿站拿到你的东西,会立即发送吗?当然也不会了。
所以,内存空间允许数据在缓冲区中积压,一次就可以发送多次数据,变相的减少IO的次数。
缓存的最大意义是:提高使用缓存的进程的效率。
老板什么时候发送快递就相当于使用什么样的刷新策略?
1.无缓冲,立即刷新。
2.有缓冲,行刷新。(显示器使用)
3.有缓冲,写满再刷新。(普通文件采用这种方式)
两种情况:
1.进程退出时,主动刷新缓存。
2.进程强制刷新(fflush)。
简单验证一下。


经过验证,可以看到在2秒内,显示器上是没有数据的。那么,期间数据在哪里呢?
是在语言级缓冲区上的。那么,这个缓冲区它在哪里呢?我们怎么从来没见过。
还记得 FILE 结构体吗?C语言访问文件都是通过 FILE访问的,包括 stdin, stdout, stderr。FILE 本质就是一个结构体。我们可以在 /usr/include/libio.h (每个系统可能会不一样)文件里查找,在这个结构体里就有缓冲区。
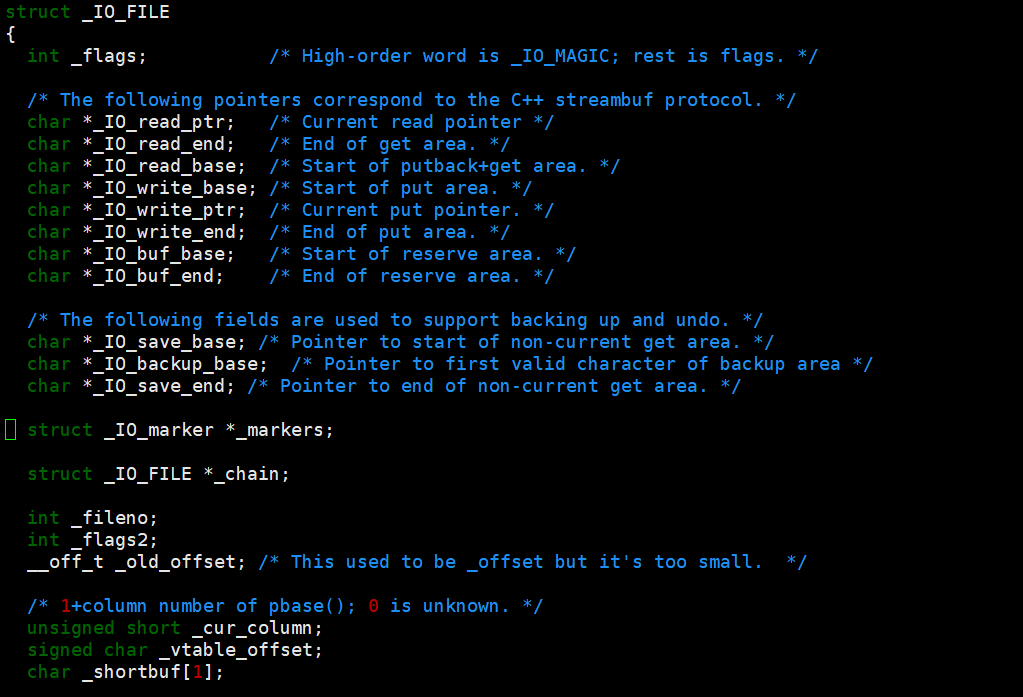
现在,我们重新理解 printf , scanf 的格式化过程。它们将数据进行格式化,那么格式化到哪里了呢?格式化结果写入 FILE 缓冲区中。所以,数据并没有写入内核缓冲区中,它还需要检测是否需要刷新?

所以,这段代码,log.txt 为什么没有数据呢? 这是因为,printf 在格式化数据的时候,结果是被写入到了语言级缓冲区,并没有刷新到内核缓冲区,普通文件是全缓冲。而此时我们已经关闭了 log.txt 文件,OS会释放该文件的资源。

调用 fflush 会强制刷新数据到内核缓冲区,然后再关闭该文件,此时数据已经刷新到了内核缓冲区中,文件里自然就有内容了。
或者进程退出自动刷新缓冲区,经过验证,在前两秒内,数据并没有写入到 log.txt ,两秒之后,进程退出,数据写入到该文件里。


相信大家已经理解了,是不是觉得自己又行了。那当我祭出如下代码的时候,阁下又要如何应对呢?
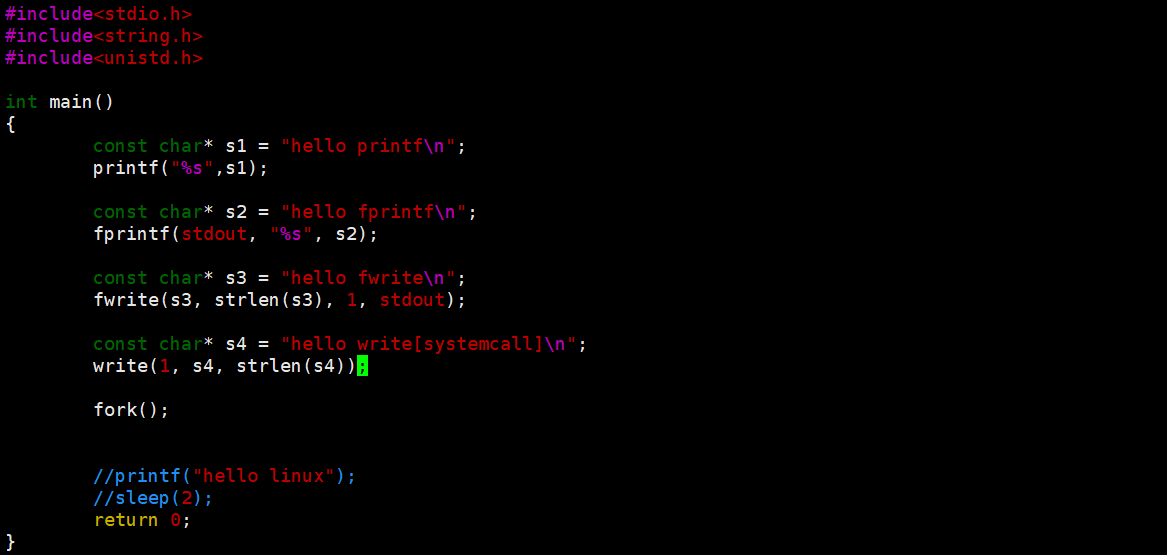
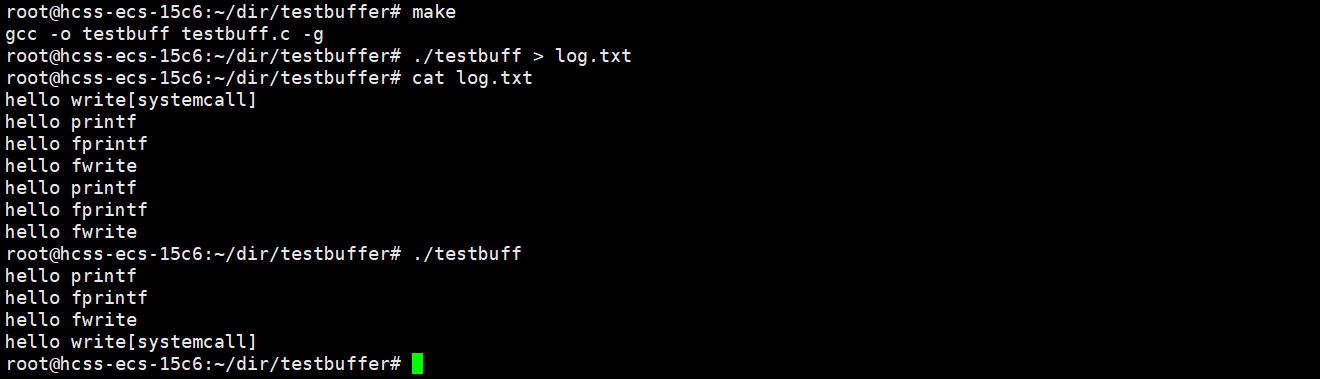
这是为什么呢?我想有不少小伙伴看懵了吧。
write 是系统调用,它会把数据直接拷贝到内核缓冲区中,所以 hello systemcall只有一份,而 printf, fprintf, fwrite 是C语言库函数,它们会把数据拷贝到用户缓冲区中,由于是重定向文件,所以是全缓冲刷新策略,数据会被积压在用户缓冲区中,fork 之后,子进程以父进程为模板,子进程用户缓冲区中也会有相同的数据积压在缓冲区里,进程退出时,父子进程各自刷新缓冲区,所以有两份数据。
而向显示器上打印数据,是行缓冲策略,所以,数据会按照代码的顺序依次打印在终端上。
在C,C++里除了标准输入输出流,还有标准错误流。我们来看下面的一段程序是怎么回事呢?
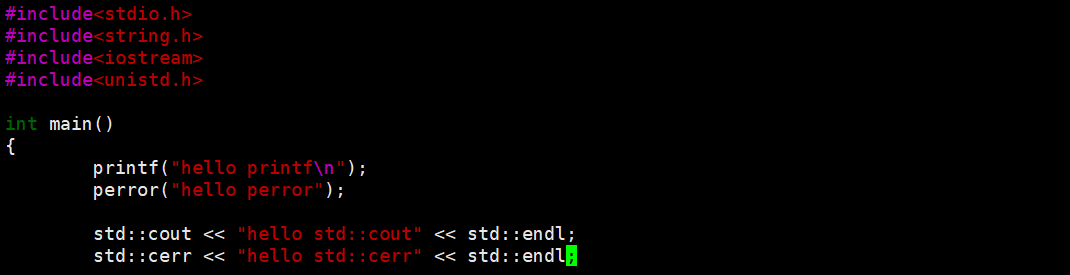
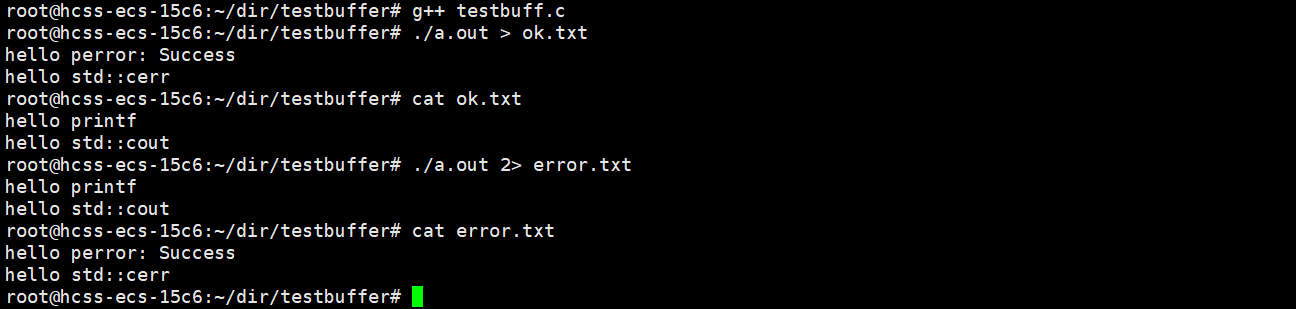
这是为什么呢?标准输出流,标准错误流都是向显示器打印的。而我们做了输出重定向,就默认向 1 号文件描述符指向的文件进行写入,而 2 号文件描述符不受影响,就打印在了显示器上。
同理,我们指定2号文件描述符输出重定向,perror, std::error 就打印到了2号文件描述符指定的文件里,而 printf, std::cout 就打印在了显示器上。
当然了,也是有办法可以将它们打印在一个文件里的。

二、简单设计libc库
. mystdio.h
#ifndef __MY__STDIO__H
#define __MY_STDIO__H#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>#define SIZE 4096#define FLUSH_NONE 1
#define FLUSH_LINE 2
#define FLUSH_FULL 4#define NORMAL 1
#define FORCE 2#define UMASK 0666typedef struct MY__IO__FILE
{int _fileno;int flag;//刷新策略char outbuffer[SIZE];//缓冲区int curr;//缓冲区当前的位置int cap;//缓冲区容量
}MYFILE;MYFILE* my_fopen(const char* filename, const char* mode);
void my_fclose(MYFILE* fp);
int my_fwrite(const char* s, int size, MYFILE* fp);
void my_fflush(MYFILE* fp);
#endif
. mystdio.c
#include"mystdio.h"MYFILE* my_fopen(const char* filename, const char* mode)
{int fd = -1;//文件描述符if(strcmp(mode, "w") == 0){fd = open(filename, O_CREAT | O_WRONLY | O_TRUNC, UMASK);}else if(strcmp(mode, "r") == 0){fd = open(filename, O_RDONLY);}else if(strcmp(mode, "a") == 0){fd = open(filename, O_CREAT | O_WRONLY | O_APPEND, UMASK);}else if(strcmp(mode, "a+") == 0){fd = open(filename, O_CREAT | O_RDWR | O_APPEND, UMASK);}else{}MYFILE* fp = (MYFILE*)malloc(sizeof(MYFILE));if(!fp)return NULL;fp->_fileno = fd;fp->flag = FLUSH_LINE;fp->outbuffer[0] = 0;fp->curr = 0;fp->cap = SIZE;return fp;}static void my_fflush_core(MYFILE* fp, int force)
{if(fp->curr <= 0)return;if(force == FORCE){write(fp->_fileno, fp->outbuffer, fp->curr);fp->curr = 0;}else{if((fp->flag & FLUSH_LINE) && fp->outbuffer[fp->curr - 1] == '\n'){write(fp->_fileno, fp->outbuffer, fp->curr);fp->curr = 0;}else if((fp->flag & FLUSH_FULL) && fp->curr == fp->cap){write(fp->_fileno, fp->outbuffer, fp->curr);fp->curr = 0;}else{}}
}int my_fwrite(const char* s, int size, MYFILE* fp)
{memcpy(fp->outbuffer+fp->curr, s, size);fp->curr += size;my_fflush_core(fp, NORMAL);return size;}void my_fflush(MYFILE* fp)
{my_fflush_core(fp, FORCE);
}void my_fclose(MYFILE* fp)
{if(fp->_fileno >= 0){my_fflush(fp);//用户->内核fsync(fp->_fileno);//内核->外设close(fp->_fileno);free(fp);}
}
. test.c
#include"mystdio.h"int main()
{MYFILE* fp = my_fopen("log.txt", "w");if(fp == NULL)return 1;const char* str = "hello linux";int cnt = 20;char data[128];while(cnt--){snprintf(data, sizeof(data), "%s:%d", str, cnt);//printf("%s\n",data);my_fwrite(data, strlen(data), fp);sleep(1);}my_fclose(fp);return 0;
}
. Makefile
mystdio:mystdio.c test.cgcc -o $@ $^
.PHONY:clean
clean:rm -f mystdio
三、理解硬件(磁盘)
1. 认识磁盘
我们用一张图来简单的认识一下磁盘。

主轴马达高速转动会带动盘片,磁头会上下摆动读取盘片上的数据。盘片分正反两面,一片两面,两片四面…。
我们把盘片的示意图看一下。
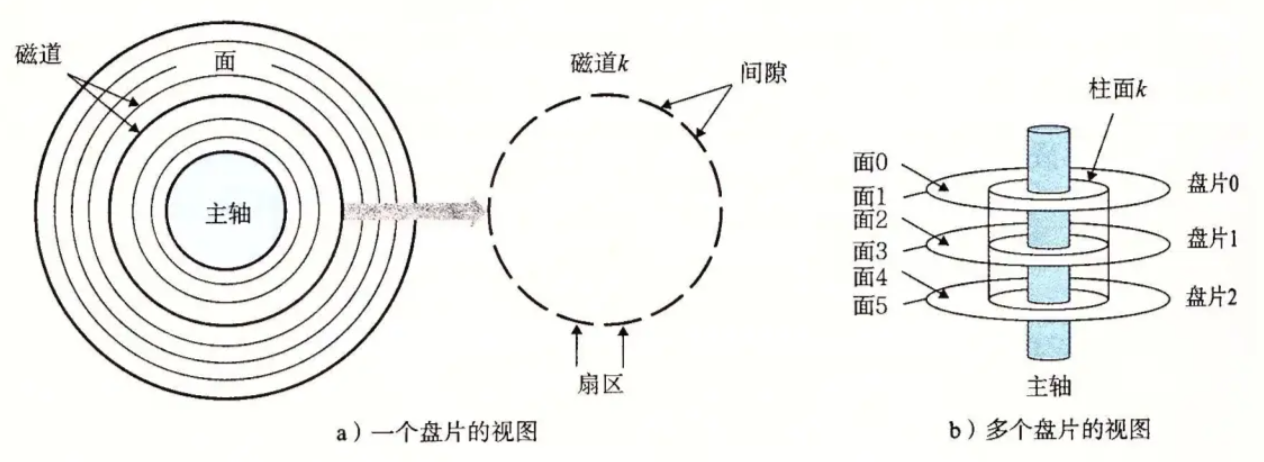
我们可以把盘片看成半径不同的同心圆,每一个同心圆就是一个个磁道,同心圆可以看成由一个个扇区组成,中间空白的部分就是没有数据,数据都在扇区上。
扇区是OS访问磁盘设备的基本单位:一般是512字节。
一个盘片两面,从面0开始进行编号,而磁头和盘面是一对一的,一面一磁头。
磁头是共进退的。也就是说,在同一时间,磁头在不同的盘面上指向的是同一个磁道,同一个扇区(这里我们认为每个面上的每个磁道的扇区数是相同的,所有盘面同一磁道的扇区严格对齐)。
所有盘面半径相同的磁道构成一个柱面。
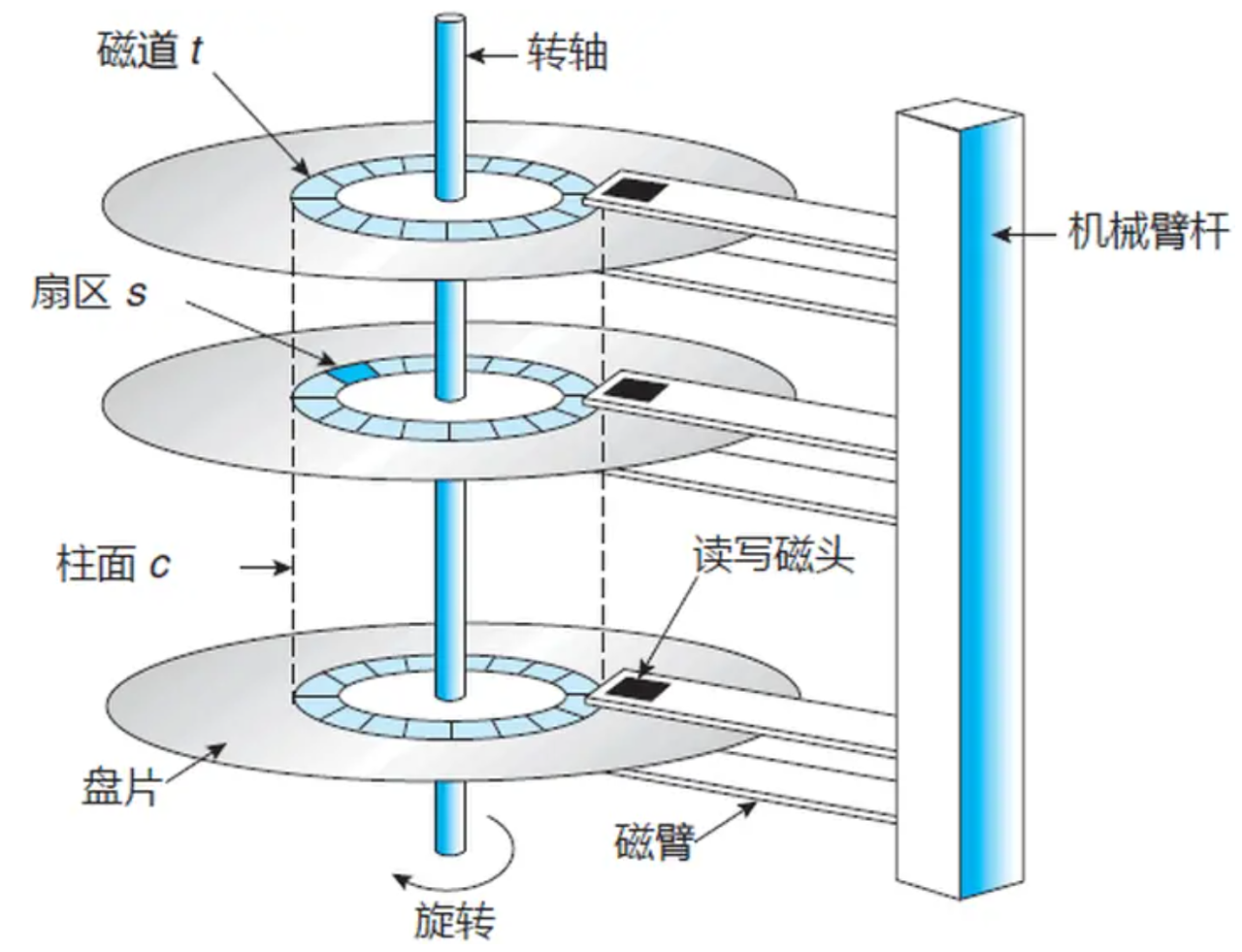
磁头左右摆动本质是在定位哪一个磁道(柱面)。
盘片旋转的本质:是确定哪一个磁道(柱面),定位该磁道(柱面)上的哪一个扇区。
磁头和盘片转动的本质:是对磁盘特定位置进行寻址。
2. 寻址方式
磁头,磁道编号都是从0开始的,扇区的编号是从1开始的。那么,我们怎么在一个磁盘里定位任意一个扇区呢?
1.选择磁道(cylinder)
2.选择磁头(header)
3.选择扇区(sector)
我们把这种寻址方式叫做CHS地址定位法。但这种技术太老了,现在已经不怎么用了。
大家小的时候应该都见过磁带吧。

通过轴转动,磁带可以从一边转到另一边。我们可以把磁带全部抽出来,它就变成了一条很长的磁带,而将它卷起来,不就类似于磁盘的示意图吗。
所以,我们可以将磁盘的存储结构抽象成一个一维数组。
盘片的每一面就类似于这样:

所以,现在如何定位一个扇区呢?一个数组下标:定位任意一个扇区,我们把这种地址定位法叫做LBA(logic block address)地址。
但是磁盘只认识CHS,所以,我们要如何把LBA转成CHS呢?
其实很简单,假设,一个磁盘有5个盘面,每个盘面100个磁道,每个磁道10个扇区,当LBA为124时,是哪一个盘面,那个磁道,那个扇区呢?
124 / 100 = 1(header),124 % 100 = 24,24 / 10 = 2(cylinder),24 % 10 = 4(sector)。
上面是我们基于磁盘物理层面的认识,我们以盘面为例进行展开。但是,磁盘实际并不是以盘面展开的,而是以柱面展开的。
某一盘面的某个磁道展开:

这不就是一维数组。
整个磁盘所有盘面的同一个磁道展开,即柱面展开:
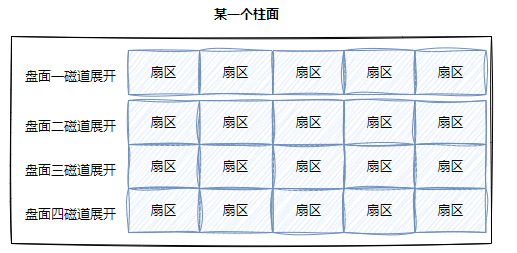
这不就是二维数组。
再将整个磁盘展开:
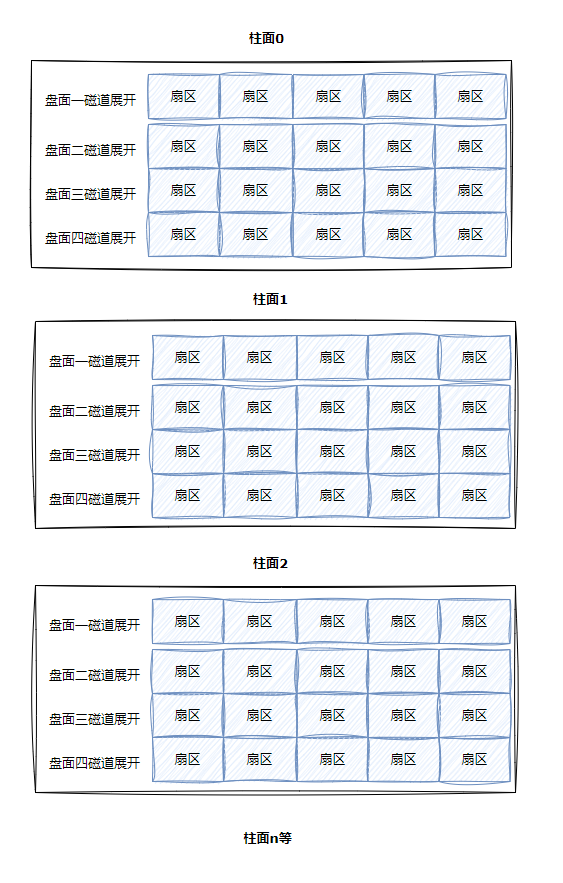
这不就是将每个柱面作为数组中的一个元素嘛。所以,整个磁盘其实就可以看成一个三维数组。寻址的时候,先找柱面,再找磁道,最后是扇区,不就刚好和CHS的顺序对应嘛。
在C/C++中,二维数组是不是也可以看做是一维数组呀,三维数组也是一样的。

所以,磁盘的存储结构可以被看做是一个线性结构,线性结构的地址就是LBA,它可以被转化为三维数组的三个下标。
LBA转化为CHS,本质就是一维数组的下标,转换成三个数字。
OS只需要使用LBA就可以了。LBA怎么转换CHS,CHS怎么转换成LBA?这是由磁盘来完成的。
现在,大家应该对磁盘有了一个比较深刻的理解了。磁盘就是一个以sector为单位的一维数组。
3. 管理磁盘
磁盘是一个典型的块设备,它是以512字节为单位的,但是OS读取磁盘数据的时候,并不是以磁盘的基本单位来读取的,而是以4KB为单位读取,也就是8个扇区,一个块,以块为单位读取的。
“块”是文件存取的最小单位。
总结:OS看待磁盘,就认为磁盘是一个块设备,每个块都有下标。
文件系统的角度:磁盘当做 block array[N]---->块设备。
假设有一个磁盘800GB,那么它有多少个块呢?应该有209715200个块,那么要怎么对这些块进行管理呢?
这就像我们国家有如此广阔的土地,要管理这些土地,要怎么管理呢?国家会设置各个省份,每个省内设置市,市下面设置县…,每个地方都是如此,省份集中归于中央管理。磁盘也是类似的。
磁盘也会进行划分,每个区划分多大空间,一共划分几个区,这个就叫做分区。
理解一下,OS是怎么把数据写给磁盘的。
寄存器,大家都听过吧。不止CPU内部有寄存器,外设内部也有寄存器。
举个例子:磁盘内部有各种各样的寄存器,以dir, addr, data三个寄存器为例,OS向磁盘写数据,就会通过IO总线向dir寄存器发送w,addr寄存器写入LBA地址,data寄存器写入数据,然后磁盘将LBA地址转化为CHS地址,寻址之后,磁盘中的控制电路会根据w指令将数据写入到CHS地址。
如果你要读数据,也是类似的。OS通过IO总线,向dir寄存器发送r,addr寄存器写入LBA地址,磁盘将LBA地址转化为CHS地址,控制电路根据 r 指令,在CHS地址处读取数据到data寄存器中,然后再被OS获得。
上面我们谈论到了,磁盘的空间很大,会被划分成很多的块,为了管理这么多的块,所以有了分区,但是分区的空间还是很大,也不方便管理,所以对分区进行了进一步的划分:组,只要管理好了组,每个组按照同样的方式去管理,就管好了分区,管理好了分区就管好了磁盘。每个分区的信息(分区的开始位置,结束位置)都被写在了磁盘的第一个扇区中,分区1【start, end】,分区2【start,end】,分区3【start,end】,我们把它叫做分区表。
所以现在,我们着重就要理解怎么管理好一个组了。
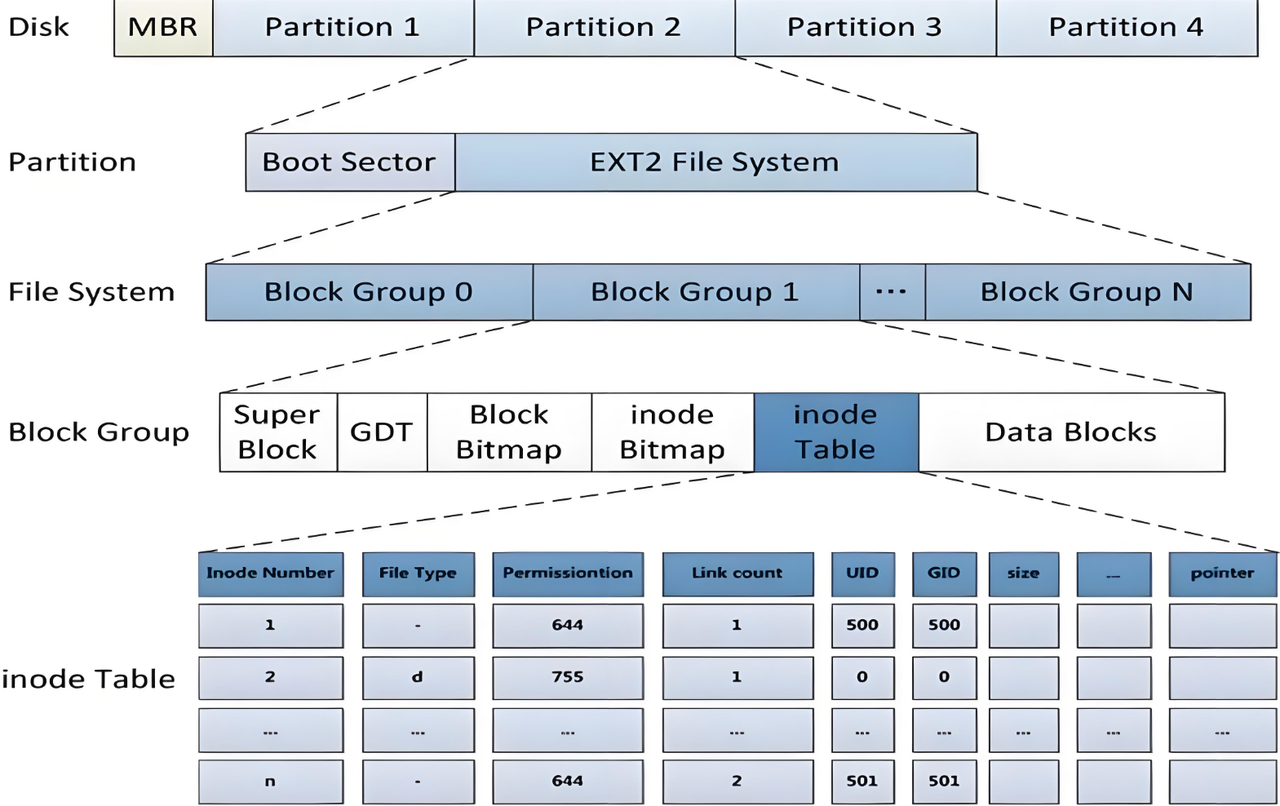
文件 = 文件内容 + 文件属性,这些都是文件的数据,都要被存储。
1.在linux中,文件的内容和属性是分开存储的。
2.OS和磁盘文件进行IO,是以4KB为单位的。
在Data Blocks中只保存文件的内容,以4KB为单位,绝大部分的磁盘分组空间,都被DataBlocks占据。
而DataBlocks是有空间大小的,一个数据块占4KB,那么DataBlocks中一定有大量的数据块,如果一个文件大小是16KB,它只需要4个数据块。
每一个数据块都是有编号的。那么,DataBlocks中也会有不同的文件内容占据数据块,那么如何判断哪些数据块是被哪些文件拥有的呢?这个问题稍后回答。
现在,我们还有一个问题,有些数据块是被使用了的,有些没有被使用。那么,要如何判断那些数据块是被使用了的呢?要根据数据块里面的内容吗?当然不是了,数据块里面都是二进制,我们也不认识。
不知道大家注意到了Block Bitmap,没错,就是根据它来判断的。
Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪些数据块没有被占用。
Block Bitmap是一个块位图,它是根据 bit 的位置和内容标记数据块的。
bit 的位置:表示对应哪一个数据块。
bit 的内容[0,1]:表示对应的数据块是否被占用。
假设,我们有100万个数据块,那么就需要31个数据块(Block Bitmap),100万个 bit 位来表示Data Blocks中数据块的占用情况。
现在,已经有了一个共识了。文件 = 文件内容 + 文件属性。文件内容聊的差不多了,现在,就来聊聊文件属性。
Linux中,表达文件属性,用结构体 struct inode表示文件的属性,既然是结构体,那么它的大小就是固定的。这个结构体大小一般是128字节或者256字节。
在磁盘上,文件不止有一个,那么文件的属性内容也会有很多,但是它们的属性内容虽然不一样,文件的属性是一样的。这就像街上有许多人,有很多人性别是男,有很多人性别是女。他们虽然性别不一样,但是性别这个属性是一样的,只是向这个属性中填写了不同的内容。
OS读取文件,读取 inode ,一次依旧4KB读取,如果按照 inode大小为128字节计算,那么一次可以读取32个文件的 inode,这也意味着,文件加载时,并不是一个一个文件加载到内存的,而是一次性读取多个文件的 inode。
一般而言,一个文件一个 inode,一个文件可能对应0个或者多个 data block。
注意两个问题:
1.磁盘当中有许多文件,为了标示文件的唯一性,struct inode中会存在一个 int inode_number。
2.Linux中,文件名不能也不再 inode 中保存。
而 struct inode是存储在 inode Table中的,inode Table是当前分组所有 inode属性的集合,inode编号以分区为单位,整体划分,不可跨分区。我们把 inode Table叫做 i 节点表。
inode Table也是以4KB为单位,假设一共16KB,那么 inode Table一共有128个 inode。那么,这么多的 inode,那些是被使用了的,哪些是未被使用的,怎么判断呢?
inode Bitmap是不是和 Block Bitmap很像呢?inode Bitmap就是用来判断 inode是否被使用了的。它也是用位图的方式来判断。
bit的位置:表示第几个 inode。
bit的内容[1/0]:表示对应的 inode是否被占用。
那么,现在有一个新的问题。文件 = 文件内容 + 文件属性,但是文件内容和文件属性是分开的呀,将来我们可以先拿到文件的 inode号,可是该文件的内容怎么找呢?
在 struct inode中是存在和 block 的映射关系表的,其实就是一个数组,这个数组里存着该文件的文件块块号。

只要通过 inode编号,就能找到文件对应的 inode属性,内部具有和数据块的对应关系,就能进一步找到文件的内容了。
现在,文件的内容和属性都已经了解了,还剩下两个GDT(Group Descriptor Table)和Super Block。
GDT,块组描述符表,描述块组属性信息,整个分区分成多少块组就对应多少个块组描述符,每个块组描述符存储一个块组的描述信息。比如:这个块组中从哪里开始是 inode Table,从哪里开始是Data Blocks,空闲的 inode和数据块还有多少个等等。
Super Block:存放文件系统本身的结构信息,描述整个分区的文件系统信息。那么,就有问题了?
问题1:Super Block既然是描述一个分区的所有分组的整体情况,为什么会在一个块组中,不应该在 File System中吗?
Super Block不仅仅在一个组里,可能会同时存在多个 block group中。不一定所有的组都有 super block,但是几乎多个组会同时存在同样的 super block。
如果 super block 放在了 file system中,那么一旦file system数据刮花了,整个分区都崩了,但是放在多个块组里,即便块组也坏了,那影响也非常小,而且多个块组里都有 super block,即便其中一个坏了,还可以用其它块组里的 super block来修复。这就是对数据的备份。
问题2:新建一个分区,super block 和 gdt 一定是有效数据。
磁盘上新建分区,OS就要给特定分区,写入管理信息,即写入文件系统和分区分组相关的管理数据,文件数据可以暂时不要。
问题3:访问一个文件,在分区内,标示该文件的唯一性:inode编号。
那么,描述一下,1.新建文件 2.删除文件 3.修改文件 4.查看文件。
新建文件:在 inode bitmap 中找 bit 为0,将它改为1,代表申请一个 inode,然后根据 bit的位置在 inode table相对应位置处的 inode中填写数据。文件有内容的话,就在 block bitmap中查找 bit 为0,改为1,申请数据块,然后再 data blocks中写入数据。
删除文件:拿着 inode编号,在inode中找到与数据块的映射表,在block bitmap中将数据块块号对应的 bit 改为0,再将 inode bitmap中对应的 bit 改为0。
所以,删除文件其实只是改了位图,并没有改动数据,有时候误删了数据,通过一些工具还能找回来。但是,不要做编辑操作,否则可能会覆盖数据。
剩下的也不用说了,也是可以理解的。
问题4:关于 inode编号和 datablock编号,是全分区统一分配的,不是只在分组内有效。
inode不能跨区域,一个分区,一个文件系统,互相独立。

问题5:上面所说的都是用 inode编号来查找文件内容和属性的,可是我们从来没使用过 inode,一直用的都是文件名啊?
Linux下一切皆文件,那么目录是文件吗?当然是了。
什么是目录呢?目录 = 目录的内容 + 目录的属性。
目录的属性就是 struct inode,只不过和普通文件(inode)存储中存储的内容不一样。
那目录的内容存的是什么呢?它也要有 data block,只不过它里面存的是文件名与 inode的映射关系。通过文件名就可以找到对应的 inode。

所以,同一个目录下,文件名不能重复。毕竟每个文件的 inode编号是唯一的。
在指定目录下新建文件的本质:是将文件名与 inode的映射关系,写入到当前目录的 data block里面。
这就是为什么在当前目录下新建文件,需要该目录具有 w 权限。
读取一个文件属性的话,需要当前目录具有 r 权限。
对目录设置 rw 权限,本质是约束用户,访问目录的 data block。
至于 x 权限,是允许是否打开目录的,就有点抽象了。
那么,大家有没有疑问呢?比如说,我们要打开一个文件就要打开该文件的目录,那么打开该目录也要打开它的上一级目录,以此类推,直到打开根目录。
而根目录是确定的。也就是说,要打开一个特定路径下的文件,我们需要对该文件所在的路径进行解析。
这就是 open文件的时候,必须要有路径的原因。
这就是Linux下访问任意文件,都需要路径访问。
这就是为什么进程PCB,要有 cwd 的根本原因。
4. 路径解析
但是,每一次访问文件都需要解析路径,难道不慢吗?
现在来看,目录和文件存储方式是没有区别的。但是,我们是可以看到有目录树的啊!并且,它这样不慢吗?
Linux中,当用户访问指定路径下的文件(目录,普通文件),在路径解析的过程中,在内核中形成目录树和路径缓存。
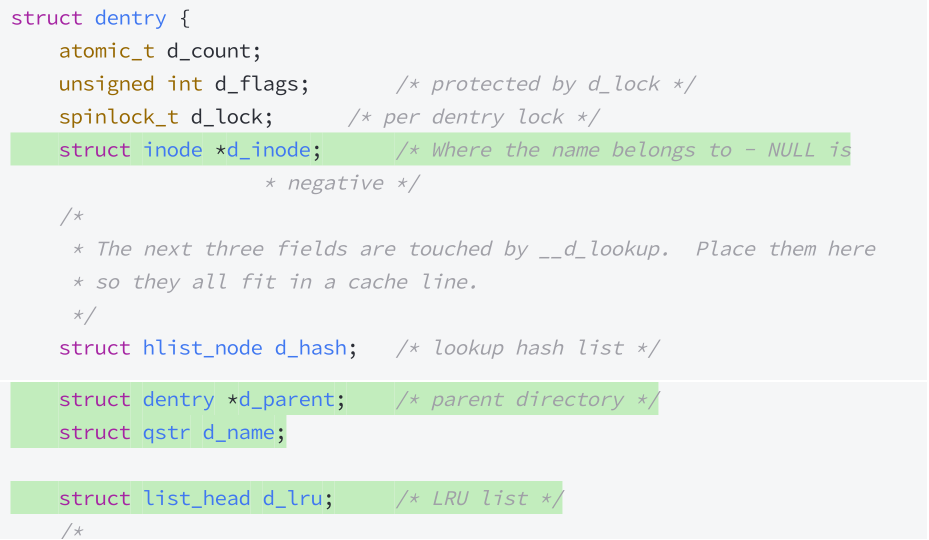
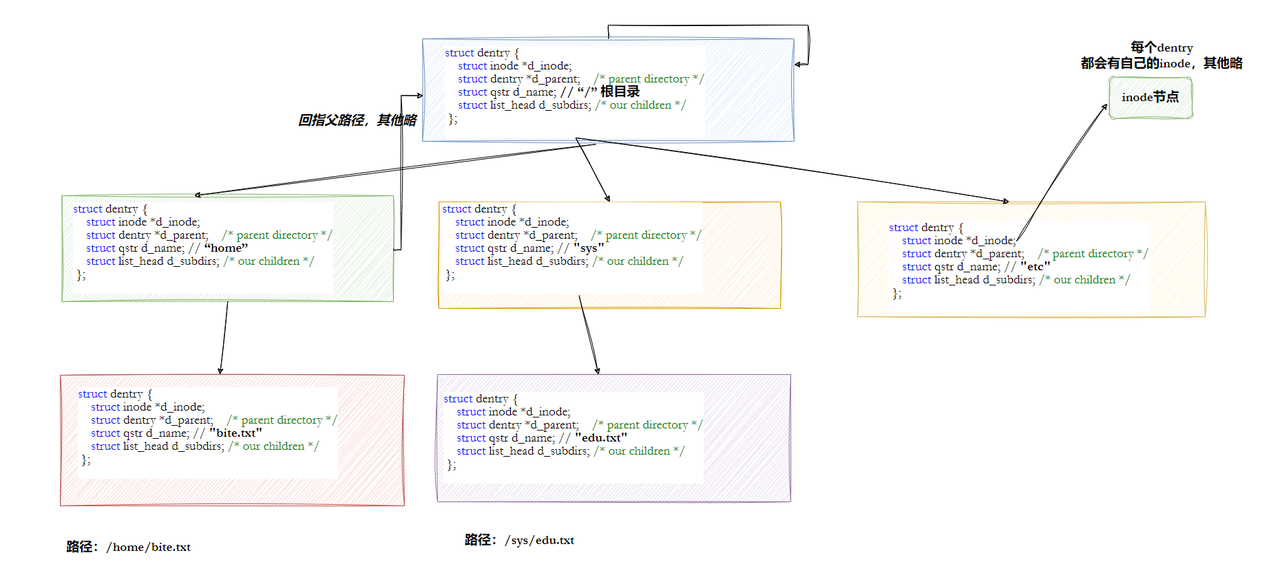
所以,路径解析的时候,只有第一次是慢的,第2次,第n次的时候,路径解析会优先从 dentry 树结构中进行解析。
5. inode table 与 data block的映射关系表
现在,我们把重点放在 inode table中的 inode 与 data block的映射关系表上。


可以看到,数组大小是15,那么一个块4KB,那也才60KB大小呀。可是,一个文件的大小有时候可是很大的,这怎么能够存的下呢?
其实,数组的前12个下标(0~11)直接用来存储块地址。剩下的三个,依次是一级间接块索引表指针,二级间接块索引表指针,三级间接块索引表指针。一个指针的大小也就是4/8字节。我们按照4字节来计算,一级索引表指针指向的块能够存储1024个块地址,也就是1024个块。
那如果是二级索引表指针呢?那不就是1024 * 1024个块了吗。三级索引表指针呢?就是1000000000个块了吗(大致算了一下)。这不就足够了吗。
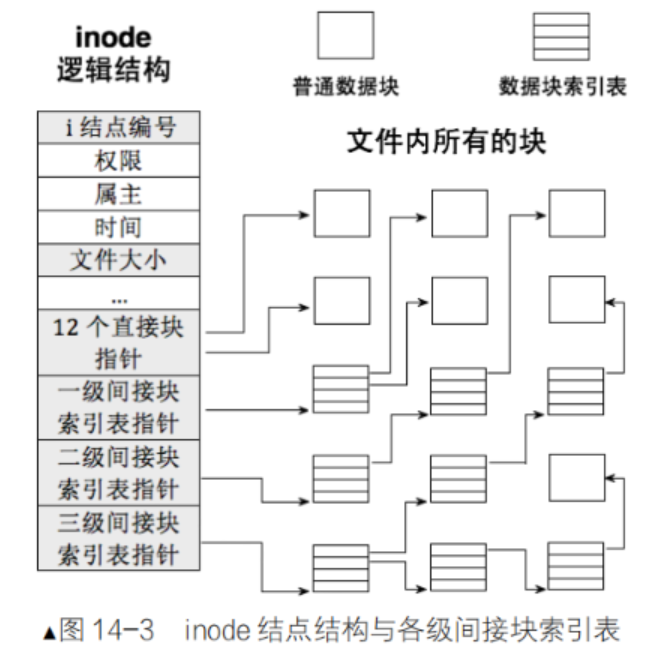
6. 挂载分区
我们已经能够根据 inode 号在指定分区内找文件了,也能根据目录文件内容,找指定的 inode 了,可是 inode 不是不能跨分区吗,Linux下有很多分区啊,我怎么直到我在哪一个分区?
这是因为每一个分区都会被挂在到一个指定的目录下,所以查找文件时,根据 inode 才能知道自己在哪一个分区下查找。
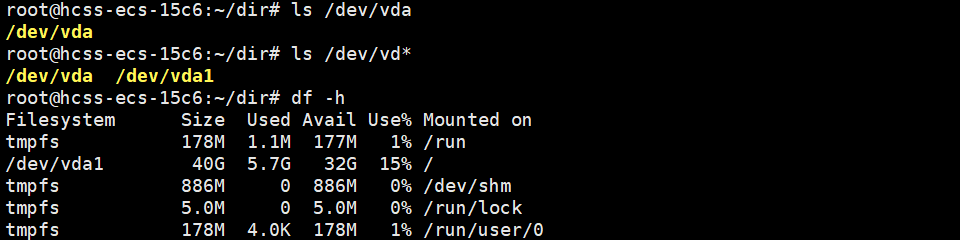
/dev/vda1就被挂在到了根目录下。这就是为什么要有路径的原因,根据路径就可以进行字符串的匹配,切换挂载分区,就可以根据 inode 找到对应的文件了。
今天的文章分享到此结束,觉得不错的小伙伴给个一键三连吧。